一种智能化印章识别方法与流程
1.本发明涉及图文处理技术领域,具体涉及一种智能化印章识别方法。
背景技术:
2.为了提高印章识别成效,预防与减少印章犯罪对社会、集体单位、个体的巨额损失,采用高科技视觉技术,从而准确、快速、高效识别印章已成为迫切需要解决的问题;如何快速、准确、高效辨别印章真伪对于个人、社会团体、单位具有重大的现实意义,也成为社会稳定发展的迫切需求。
3.目前,现有技术中已经存在一些利用光学字符识别技术(ocr)对印章识别的方法,但是现有的印章识别方法存在以下技术问题:一是现有的基于校正加识别的pipline方法,存在流程长、误差易累计的问题;二是现有技术中并没有为印章文本设置具有针对性的光学字符识别技术(ocr)识别器,从而导致识别效果会受到相似字体的影响(如:“在线”中“线”字易被误认为“钱”字)。
技术实现要素:
4.针对以上现有技术存在的问题,本发明的目的在于提供一种智能化印章识别方法,该方法不存在误差累积、识别判断准确度高,同时,该方法对公司名称中的相似字体具有较高的识别准确率,能够有效避免相似字体对印章识别结果的影响。
5.本发明的目的通过以下技术方案实现:
6.一种智能化印章识别方法,其特征在于:
7.包括:印章区域定位过程、印章图像预处理、模型预训练过程以及印章文本生成过程;
8.所述印章区域定位过程具体为获取待识别的印章图像,自动定位印章区域的位置;
9.所述印章图像预处理包括两次预处理,通过对印章图像进行第一次预处理,获得清晰、准确的印章图像;然后通过对印章图像进行第二次预处理,使其满足骨干网络的输入格式;
10.所述模型预训练过程为多模态网络训练,包括印章图像模型训练、印章文本模型训练以及训练模型匹配程度判断;具体为:
11.a、印章图像模型训练:采用骨干网络对预处理后的印章图像进行图片特征的提取,然后通过全连接层对提取的图片特征维度进行重映射,再对重映射后的向量个数进行随机重采样;
12.b、印章文本模型训练:
13.b1、mask predict训练:随机选取印章图像的印章文本20%~30%作为网络预测对象,对文本侧采用mask predict的方式进行训练;
14.b2、shift predict训练:
15.b
21
、采用seq
‑
to
‑
seq lm的模式、即左侧字符对右侧字符和网络信息不可见,从而对步骤b1中训练后的文本进行训练;
16.b
22
、在步骤b
21
训练过程中,同时在模型的输入过程加入少许噪声,从而确保训练过程中识别更多的字符;
17.b3、unilm训练:进行步骤b1与步骤b2的往复循环训练,直至完成最终的文本侧训练;
18.采用本发明的交替训练,即保留了shift predict快速的训练速度,又解决了单一shift predict训练的曝光偏执问题,增加了模型的鲁棒性。可避免印章因盖章环境温度湿度,纸张,油墨含量以及使用次数的影响,不能保证每个印章完全一样。通过mask predict与shift predict的往复训练,去除了不同环境造成的识别噪音,骨干网络能够更好的提取对识别有用的重点特征。能够达到印章识别的理想条件,从而使印章图像识别的准确性得到保证。
19.c、训练模型匹配程度判断:
20.模型融合:采用bert多模态模型融合步骤a中印章图像模型训练后的图片特征以及步骤b中印章文本模型训练的文本特征,设定分类函数loss,loss 值误差反向传播,更新权重参数,不断迭代训练分类网络,直至误差收敛、loss 值不再下降,完成学习;
21.所述印章文本生成过程具体为:将步骤b中编码后的图片特征输入到 bert多模态模型编码器,bert多模态模型解码器逐步输出识别的字符直到结束符号。
22.在印章文本模型训练过程中,采用mask predict训练对文本侧进行训练有助于学习文本结构信息、提高后续文本生成的准确度;采用shift predict训练有利于提高训练速度,同时,在shift predict训练引入噪声、解决了曝光偏置的问题,从而有利于识别更多字符、避免相似字符的影响;采用mask predict 训练与shift predict训练,保证印章文本识别的准确性以及高效性,从而避免识别时间长、误差大的问题。
23.作进一步优化,所述自动定位印章区域的步骤具体为:采用图像处理方法保证图片中的印章区域为整个印章的完整区域、且印章区域面积在图像面积的占比大于25%。
24.作进一步优化,所述第一次预处理为采用目标检测、裁剪、图像分割的方式,将图片边界定位到印章图像的边界,同时进行去噪处理;所述裁剪采用局部二值化处理的方法。
25.作进一步优化,所述第二次预处理采用缩放、填充的操作;所述缩放具体为将所有图像等长宽比例调整(resize)到同样的尺寸,多余的面积采用黑色进行填充。
26.作进一步优化,所述骨干网络采用resnet或vgg网络模型中的任一种。
27.作进一步优化,所述加入噪声步骤具体为引入所述印章文本的相似字,所述噪声的比例为0~20%。
28.作进一步优化,所述seq
‑
to
‑
seq lm的模式具体为:在语言模型lm中进行预训练,设定输入段为[cls,s1,sos,s2,eos];其中,s1为图像特征向量; s2为文本特征向量;则s2文本特征向量对应的左侧字符对右侧字符和网络信息不可见,通过transfer的注意力机制实现。
[0029]
作进一步优化,所述分类函数loss采用二分类交叉熵损失函数,其具体步骤为:所述bert模型输出2*1的向量,分别代表匹配与不匹配的置信度;采用softmax层将置信度归一化到0~1的范围内、并让置信度总和为1,输出归一化后匹配与不匹配的置信度;最后将
置信度采用二分类交叉熵损失函数来表示模型的损失。
[0030]
本发明具有如下技术效果:
[0031]
本发明提供了一种智能化印章识别方法,该方法通过以bert模型的多模态模型为基础,图像端输入骨干网络编码的图像特征,文本端用unilm生成网络模型;在多模态网络训练时,通过印章图像自动构建方法,生成训练数据作为补充,网络训练包括图像和文本匹配的预训练,以及mask predict与 shirt predict结合的训练方式,保证训练样本量大以及训练准确性高、耗时短;在方法测试时,通过输入编码后的印章图像,逐步输出识别的字符直到结束符号,保证识别率高、误差小。
[0032]
该方法相对目前主流的图像矫正+通用ocr识别方法,没有误差累积,同时多模态语言模型对公司名中的相似字有更高的识别准确率。在招投标、保险、工程设计等文件的场景中,通常在文件的每页都需要进行盖章确认。人工审核在大量的数据面前,通常会因为视觉疲劳而对印章的分辨能力下降。因此,在重要的文件中,通过本发明提供的方法,可以有效的保证文件中印章识别准确,消除了印章审核人为失误的风险并降低了在重要文件鉴定中必要的人力资源成本。
附图说明
[0033]
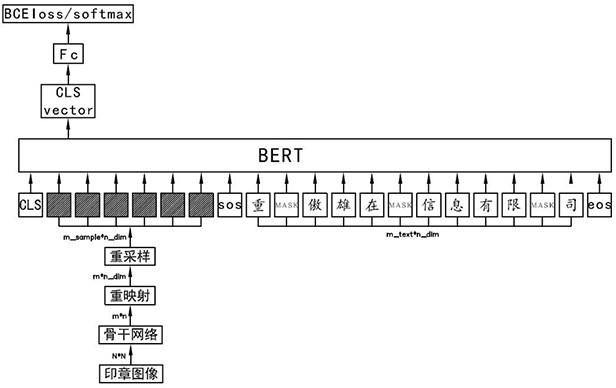
图1为本发明具体实施方式中印章文本模型训练(mask predict训练)示意图。
[0034]
图2为本发明具体实施方式中印章文本模型训练(shift predict训练)示意图。
[0035]
图3为本发明具体实施方式中印章方法测试过程的示意图。
具体实施方式
[0036]
下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0037]
实施例:
[0038]
如图1~3所示,一种智能化印章识别方法,其特征在于:
[0039]
包括:印章区域定位过程、印章图像预处理、模型预训练过程以及印章文本生成过程;
[0040]
印章区域定位过程具体为获取待识别的印章图像,自动定位印章区域的位置;自动定位印章区域的步骤具体为:采用图像处理方法保证图片中的印章区域为整个印章的完整区域、且印章区域面积在图像面积的占比大于25%。
[0041]
印章图像预处理包括两次预处理,通过对印章图像利用采用目标检测、裁剪、图像分割的方式进行第一次预处理,获得清晰、准确的印章图像,即将图片边界定位到印章图像的边界,同时进行去噪处理;然后通过对印章图像进行缩放、填充的第二次预处理,使其满足骨干网络的输入格式;即印章图像预处理后的输出向量大小为n*n;
[0042]
裁剪采用局部二值化处理的方法;缩放具体为将所有图像等长宽比例调整(resize)到同样的尺寸,多余的面积采用黑色进行填充;
[0043]
模型预训练过程为多模态网络训练,包括印章图像模型训练、印章文本模型训练
以及训练模型匹配程度判断;具体为:
[0044]
a、印章图像模型训练:采用骨干网络对预处理后的印章图像进行图片特征的提取,图像预处理后输出向量大小为n*n、则骨干网络输出的feature map 的向量大小为m*n;然后通过全连接层对提取的图片特征维度进行重映射、将n维的特征向量转换为m*n_dim,再对重映射后的向量个数进行随机重采样、得到m_sample*n_dim向量输入融合模型;
[0045]
骨干网络采用resnet或vgg网络模型中的任一种、例如vgg16;
[0046]
b、印章文本模型训练:(以公司名“重庆傲雄在线信息有限公司”为例)
[0047]
b1、mask predict训练:随机选取印章图像的印章文本20%~30%作为网络预测对象,对文本侧采用mask predict的方式进行训练;如图1所示,选取“庆”、“线”、“公”作为mask predict训练过程中的网络预测对象;
[0048]
b2、shift predict训练:
[0049]
b
21
、采用seq
‑
to
‑
seq lm的模式、即左侧字符对右侧字符和网络信息不可见,从而对步骤b1中训练后的文本进行训练;如图2所示,“庆”字能够看到“cls”倒“庆”字本身的网络信息,而“庆”字之后的“傲”字至结尾是不可见状态,从而有效提高训练速度;
[0050]
seq
‑
to
‑
seq lm的模式具体为:在语言模型lm中进行预训练,设定输入段为[cls,s1,sos,s2,eos];其中,s1为图像特征向量;s2为文本特征向量;则s2文本特征向量对应的左侧字符对右侧字符和网络信息不可见,通过 transfer的注意力机制实现。
[0051]
b
22
、在步骤b
21
训练过程中,同时在模型的输入过程加入少许噪声,从而确保训练过程中识别更多的字符;加入噪声步骤具体为:引入印章文本的相似字例如将输入的第二个字符“庆”修改为“大”进行输入,噪声的比例为0~ 20%,有利于训练模型识别更多的字符。
[0052]
b3、unilm训练:进行步骤b1与步骤b2的往复循环训练,直至完成最终的文本侧训练;
[0053]
c、训练模型匹配程度判断:
[0054]
模型融合:采用bert多模态模型融合步骤a中印章图像模型训练后的图片特征以及步骤b中印章文本模型训练的文本特征,设定分类函数loss,loss 值误差反向传播,更新权重参数,不断迭代训练分类网络,直至误差收敛、loss 值不再下降,完成学习;
[0055]
分类函数loss采用二分类交叉熵损失函数,其具体步骤为:bert多模态模型输出端(即图1中fc)输出2*1的向量,分别代表匹配与不匹配的置信度;采用softmax层将置信度归一化到0~1的范围内、并让置信度总和为1,输出归一化后匹配与不匹配的置信度;最后将置信度采用二分类交叉熵损失函数来表示模型的损失。
[0056]
二分类交叉熵损失函数表示为:
[0057][0058]
式中,y
i
表示真实的分类结果;a
i
表示softmax层的第i个输出值。
[0059]
印章文本生成过程具体为:将步骤b中编码后的图片特征输入到bert 多模态模型编码器,bert多模态模型解码器逐步输出识别的字符直到结束符号;如图3所示,输入图片特征m_sample*n_dim后,bert多模态模型解码器从输入“sos”开始,每一位都会预测得到一
个token,如图3“sos”预测得到“重”,“重”再作为下一位的输出预测“庆”,直到预测输出“eos”。
[0060]
在印章文本模型训练过程中,采用mask predict训练对文本侧进行训练有助于学习文本结构信息、提高后续文本生成的准确度;采用shift predict训练有利于提高训练速度,同时,在shift predict训练引入噪声、解决了曝光偏置的问题,从而有利于识别更多字符、避免相似字符的影响;采用mask predict 训练与shift predict训练,保证印章文本识别的准确性以及高效性,从而避免识别时间长、误差大的问题。
[0061]
为了示例和描述的目的已经给出了以上描述。此外,此描述不意图将本公开的实施例限制到在此公开的形式。尽管以上已经讨论了多个示例方面和实施例,但是本领域技术人员将认识到其某些变型、修改、改变、添加和组合。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1