一种端到端的红外与可见光图像融合方法
本发明涉及一种端到端的红外与可见光图像融合方法,属于图像融合技术领域。
背景技术:
图像融合已广泛应用于遥感、医疗诊断到安全和监控的各种应用。图像融合是通过整合来自不同传感器的多源图像获取信息。例如,热红外和可见光成像系统被广泛应用于军事和民用监控领域。由于每种成像方式都有其自身的局限性,单个传感器无法提供场景的完整信息。因此,对多传感器数据进行融合以生成含有更多信息量的图像,最终为用户提供更全面的信息是非常必要的。然而,现有的图像融合方法大多是像素级的,存在两个关键问题,即计算时间复杂度较高和融合的冗余信息会产生块伪影。
中国专利公开号为“cn112288668a”,名称为“基于深度无监督密集卷积网络的红外和可见光图像融合方法”,该方法首先输入待融合的红外图像与可见光图像;接着,通过密集卷积操作提取输入图像的特征;然后,采用l1范数加法策略来融合不同输入图像的特征,用以获得最终的融合特征;最后,经过重构融合特征输出得到融合图像。该方法得到的融合图像质量差,不符合人眼视觉效果,同时实现过程复杂和效率低下。
技术实现要素:
本发明为了解决现有的融合方法得到的图像质量差的问题,提供了一种端到端的红外与可见光图像融合方法。使融合得到的图像具有更好的融合效果,更符合人眼视觉观察,同时本发明提出的方法实现过程简单,图像融合效率更高。
本发明解决技术问题的方案是:
一种端到端的红外与可见光图像融合方法,包括如下步骤:
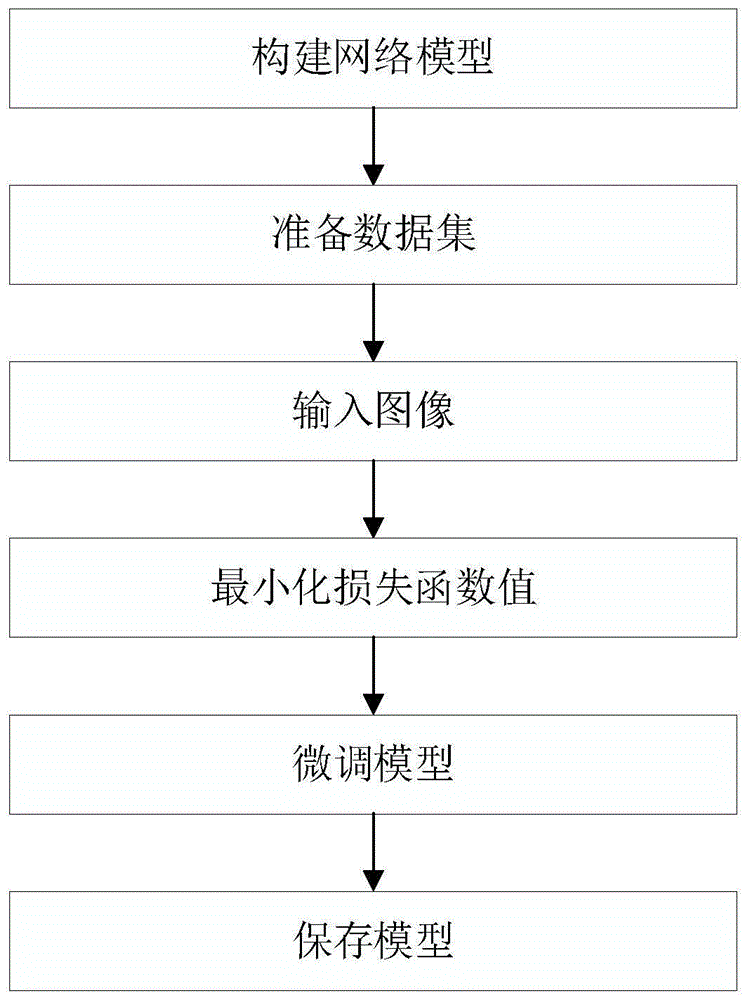
步骤1,构建网络模型:整个网络由七个卷积块组成的卷积网络,其中每个卷积块由跳跃连接、拼接操作、卷积层和激活函数组成;第一个卷积块对输入图片进行初级特征提取,第二到六个卷积块对图像中高级特征进行提取并重组,去除冗余信息,组合并保留有用信息,第七个卷积块对两条支路输出的信息进行融合,得到最终的融合图像;
步骤2,准备数据集:对整个卷积网络先用可见光数据集进行训练;
步骤3,输入图像:将步骤2中准备好的数据集输入到步骤1中构建好的网络模型中进行训练;
步骤4,最小化损失函数值:通过最小化网络输出图像与标签的损失函数,直到训练次数达到设定阈值或损失函数的值到达设定范围内即可认为模型参数已预训练完成,保存模型参数;
步骤5,微调模型:用红外与可见光图像对模型进行训练和微调,得到稳定可用的模型参数。最终使得模型对融合的效果更好;
步骤6,保存模型:将最终确定的模型参数进行固化,之后需要进行红外与可见光图像融合操作时,直接将图像输入到网络中即可得到最终的融合图像。
所述步骤1中第一个卷积块激活函数使用线性整流函数,第二到六个卷积块激活函数使用s型函数,最后一个卷积块不使用激活函数;所有卷积块中卷积核的大小统一为n×n;所有特征图的大小与输入图像大小保持一致。
所述步骤3中在预训练过程中可见光数据集使用flickr2k;通过对数据集中可见光彩色图像转为灰度图像进行有监督的训练;将同一张图片中加入随机大小和位置的高斯模糊高斯噪声得到两张图片,作为整个网络的输入,将原始图像作为标签,解决在图像融合领域只能进行无监督训练的问题。
所述步骤4中在训练过程中损失函数选择使用结构相似性和像素损失的组合;得到的融合图像既要与红外与可见光图像在结构上保持一致,而且还需要突出红外与可见光图像中细节部分,提升人眼视觉效果。
所述步骤5中在微调模型参数过程中使用tno数据集。
本发明的有益效果如下:
1、使用经过处理后的可见光图像的灰度图作为网络训练的输入,由于可见图像中细节信息较多,明暗变化丰富,可以大大提高网络的特征提取和表达能力,将网络训练完成后再处理真实的红外和可见光图像,融合得到的图像质量效果会更好。
2、在骨干网络中使用s型激活函数,可以使得网络输出的图像更符合人眼视觉观察,不会导致融合图像过曝和出现光晕等现象。
3、整个训练网络在两条支路上使用拼接操作可以将图像的低级特征和高级特征进行混合,使得网络对于两种不同图像的特征提取能力更强;在网络中通过添加跳跃连接有助于减少网络参数,使得网络的深度变浅,网络的参数数量较少,最终使得整个网络实现结构简单,融合效率高。
附图说明
图1为本发明一种端到端的红外与可见光图像融合方法流程图。
图2为本发明一种端到端的红外与可见光图像融合方法网络结构图。
图3为卷积块二到卷积块六中每一个卷积块的具体组成。
具体实施方式
下面结合附图对本发明做进一步详细说明。
如图1所示,一种端到端的红外与可见光图像融合方法,该方法具体包括如下步骤:
步骤1,构建网络模型。整个网络由七个卷积块组成的卷积网络,其中每个卷积块由跳跃连接、拼接操作、卷积层和激活函数组成;第一个卷积块对输入图片进行初级特征提取,第二到六个卷积块对图像中高级特征进行提取并重组,去除冗余信息,组合并保留有用信息,第七个卷积块对两条支路输出的信息进行融合,得到最终的融合图像。其中第一个卷积块由一层卷积和线性整流函数组成,第二到六个卷积块激活函数使用s型函数,最后一个卷积块不使用激活函数。所有卷积块中卷积核的大小统一为n×n。所有特征图大小与输入图像大小保持一致。
步骤2,准备数据集。对整个卷积网络先用可见光数据集进行训练。在预训练过程中可见光数据集使用flickr2k。通过对数据集中可见光彩色图像转为灰度图像进行有监督的训练。将同一张图片中加入随机大小和位置的高斯模糊高斯噪声得到两张图片,作为整个网络的输入,将原始图像作为标签,解决了在图像融合领域只能进行无监督训练的问题。
步骤3,输入图像。将步骤2中准备好的数据集输入到步骤1构建好的网络模型中进行训练。
步骤4,最小化损失函数值。通过最小化网络输出图像与标签的损失函数,直到训练次数达到设定阈值或损失函数的值到达设定范围内即可认为模型参数已训练完成,保存模型参数。在训练过程中损失函数选择使用结构相似性和像素损失的组合。其目的在于得到的融合图像既要与红外与可见光图像在结构上保持一致而且还需要突出红外与可见光图像中细节部分,提升人眼视觉效果。
步骤5,微调模型。用红外与可见光图像对模型进行训练和微调,使得模型对融合的效果更好。在微调模型参数过程中使用tno数据集。
步骤6,保存模型。将最终确定的模型参数进行固化,之后需要进行红外与可见光图像融合操作时,直接将图像输入到网络中即可得到最终的融合图像。
实施例:
所述步骤1中网络模型结构如图2所示,网络模型总共包括7个卷积块,第一个卷积块由一层卷积和线性整流函数组成,卷积核大小为3×3,步长和填充均为1。第二到六个卷积块每个的组成都相同,每一个卷积块的具体构成如图3所示,其中包含两层卷积和两次激活,卷积核大小为3×3,步长和填充均为1,激活函数选择sigmoid函数,因为sigmoid函数可以将特征图的输出限制在[0,1]之间,会让网络的边缘和内容重构能力变强,融合出质量更高的图像。第七个卷积块只有一层卷积,卷积核大小为3×3,步长和填充均为1。线性整流函数和s型函数定义如下所示:
所述步骤2中可见光图像数据集使用flickr2k。数据集中包含2650张高分辨率图像,将每一张原图通过裁剪得到8张大小为512×512的图,共计21200张训练图片。
所述步骤3中对每一张训练图片加入随机大小和位置的高斯模糊和噪声得到两张图片,作为整个网络的输入,将原始图像作为标签。其中随机大小和位置的高斯模糊和噪声通过软件算法可以实现。其中使用原图像添加随机大小高斯噪声是为了模拟可见光和红外相机系统输出图像的噪声,两个不同波段相机捕获信息能力不同,添加不同区域大小的高斯模糊,目的是让网络学习更好的特征提取能力,最终达到更好的融合效果。
所述步骤4中网络的输出与标签计算损失函数,通过最小化损失函数达到更好的融合效果。损失函数选择结构相似性和像素损失。结构相似性计算公式如下所示:
ssim(x,y)=[l(x,y)]α·[c(x,y)]β·[s(x,y)]γ
其中,l(x,y)表示亮度对比函数,c(x,y)表示对比度对比函数,s(x,y)表示结构对比函数,三个函数的定义如下所示:
在实际应用中,α、β和γ均取值为1,c3为0.5c2,因此结构相似性公式可以表示为:
x和y分别表示两张图像中大小为n×n的窗口的像素点,μx和μy分别表示x和y的均值,可作为亮度估计;σx和σy分别表示x和y的方差,可作为对比度估计;σxy表示x和y的协方差,可作为结构相似性度量。c1和c2为极小值参数,可避免分母为0,通常分别取0.01和0.03。所以根据定义,整个图像的结构相似性计算方式如下所示:
x和y分别表示待比较的两张图像,mn为窗口总数量,xij和yij为两张图片中各局部窗口。结构相似性具有对称性,其数值范围在[0,1]之间,数值越接近于1,结构相似性越大,两图像的差异越小。一般情况下,通过网络优化直接缩小其与1之间的差值即可,结构相似性损失如下所示:
ssimloss=1-mssim(l,o)
l和o分别表示标签和网络的输出。通过优化结构相似性损失,可逐步缩小输出图像与输入图像结构上的差异,使得图像在亮度、对比度上更相近,直觉感知上也更相近,生成图像质量较高。
像素损失损失定义如下所示:
out和label代表网络的输出和标签。
总的损失函数定义为:
tloss=ploss+ssimloss
设定训练次数为100,每次输入到网络图片数量大小为8-16左右,每次输入到网络图片数量大小的上限主要是根据计算机图形处理器性能决定,一般每次输入到网络图片数量越大越好,使网络更加稳定。训练过程的学习率设置为0.0001,既能保证网络快速拟合,而不会导致网络过拟合。网络参数优化器选择自适应矩估计算法。的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。损失函数函数值阈值设定为0.0003左右,小于0.0003就可以认为整个网络的训练已基本完成。
所述步骤5中使用可见光与红外图像数据集对整个网络模型参数进行微调,其中数据集为tno数据集。
所述步骤6中将网络训练完成后,需要将网络中所有参数保存,之后用配准好的红外和可见光图像输入到网络中就可以得到融合好的图像。该网络对两张输入图像大小没有要求,任意尺寸均可,但是必须保证两张图像的尺寸一致。
其中,卷积、激活函数、拼接操作、高斯滤波和高斯模糊的实现是本领域技术人员公知的算法,具体流程和方法可在相应的教科书或者技术文献中查阅到。
本发明通过构建一种端到端的红外与可见光图像融合网络,可以将源图像直接生成融合图像,不再经过中间其他步骤,避免了人工手动设计相关融合规则。通过计算与现有方法得到图像的相关指标,进一步验证了该方法的可行性和优越性。现有技术和本发明提出方法的相关指标对比如表1所示:
表1
从表中可知,本发明提出的方法拥有更高的图像对比度、边缘强度、空间频率、信息熵、平均梯度和标准差,这些指标也进一步说明了本发明提出的方法具有更好的融合图像质量。
现有技术和本发明提出方法的运行时间如表2所示:
表2
从表中可知,本发明提出方法的运行时间比现有技术缩短了10倍。这也进一步说明了本发明提出的方法具有更高的融合效率。
- 还没有人留言评论。精彩留言会获得点赞!