一种基于预训练的长文本新闻自动标注方法
本发明是属于自然语言处理领域,是基于预训练对长文本新闻进行自动标注的方法。
背景技术:
随着互联网、机器学习、大数据等技术的飞速发展,各种信息数据以指数级的速度在持续增长,目前人工智能所依托的机器学习和深度学习算法多数是数据依赖的,需要大量的数据采用监督或半监督的方式训练算法,进行定制化部署。由于我国大数据体量庞大,尤其是新闻文本没有固定的格式,且种类多样,更新速度快,给数据标注任务提出了巨大的挑战。
最常见的新闻类别标注是通过人工方式对全量数据进行标注,该方式的人工成本很高,数据质量难以保证,不可避免地存在标注人员主观疲劳,数据审核环节质量难以把控等问题。在机器学习方面,knn算法,朴素贝叶斯算法,决策树算法等,这些算法在文本分类上取得了不错的分类效果,但面对长文本,还是有些力不从心,而基于长文本的经典算法有textcnn、fasttext、textrnn等,这些算法针对文本分类的高维数据、文本语序和减少时间等方面进行优化,但因为中文语法和字的差异,相对于英文,中文的文本分类需要进行大量的处理和分析工作,在中文长文本标注的效果上,效果并不是特别理想。
技术实现要素:
针对传统人工和传统算法在长文本数据标注中存在的不足,本发明的目的是提供一种更加快速准确的长文本新闻标注方法。
本发明提供一种基于迁移学习的长文本新闻标注方法,所述方法步骤如下:
步骤s1:数据预处理
将爬取的新闻进行数据清洗,去除特殊字符,并将短于200长度的新闻过滤掉;
步骤s2:数据集划分
将每类新闻数量保持稳定,按照训练集80%,验证集10%,测试集10%的比例来划分;
步骤s3:加载模型
将预训练模型加载,设置模型参数;
步骤s4:训练模型
将训练集和验证集进行训练,并在每100轮显示当前loss,accuracy等信息;
步骤s5:文本标注
将待标注新闻输入模型进行标注。
附图说明
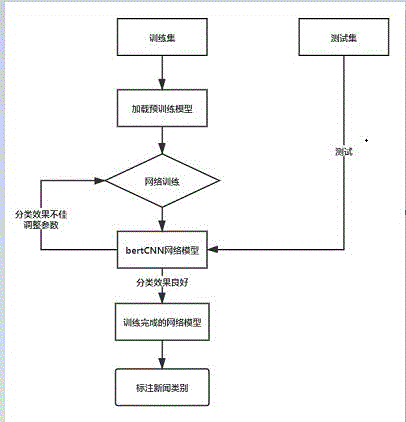
图1为本发明的流程图;
图2为本发明与其他算法的互信息(ami),兰德指数(mi),完整性的对比图。
具体实施方式
以下实施例用于说明本发明,但不用来限制本发明的范围。现通过附图和实施例对本发明作进一步的详细描述。
本发明实施例的前提是数据集是作者收集到的新闻长文本数据集。
图1为本发明实施例提供基于预训练的长文本分类模型流程示意图。如图1所示,本实施例主要包含以下步骤:
步骤s1:数据预处理
将爬取的新闻进行数据清洗,去除特殊字符,并将短于200长度的新闻过滤掉。最终将处理好的数据保存成类别+内容的格式;
步骤s2:数据集划分
将每类新闻处理成10000条的大小,按照训练集80%,验证集10%,测试集10%的比例来划分;
步骤s3:加载模型
将bert预训练模型加载,并设置参数,epoch为4,minipatch为32,学习率为0.0005,drropout为0.1;
步骤s4:训练模型
将训练集和测试集的数据构建词向量,并进行mask,将生成的词向量传入bert模型,将得到的向量增加维度,进行卷积和池化操作,在进行dropout随机掩盖,最后通过全连接层降维,得到最终的表示。在每100轮的时候。计算当前loss,acc等信息,进行反向传播;
步骤s5:文本标注
用无标签的长新闻文本,放进模型中,得到预测的类别,并进行文本类别标注。然后用kmeans聚类,将聚类标签与预测标签进行对比,得到mi,ami,完整性等指标,判断标注效果。
例1本发明通过自己收集的长文本新闻进行测试
该数据集是由来自90000条新闻长文本所构成的一个数据集,是用于中文新闻分类的数据集,包括财经、房产、教育、科技、军事、汽车、体育、游戏、娱乐9类数据。
本发明选取bert_cnn模型作为文本表示模型的基本模型,使用3个指标来评价其性能,分别是完整性(completeness)兰德指数mi(mrandindex),互信息ami(mutualinformationbasedscores),同时与3个现有的方式进行了对比,分别是bertrcnn,bertrnn,bert.现有的3个方法都运行在各自最优的参数下。本发明方法的相关参数设置如下:epoch数为5,mini-batch大小为128,学习率为0.00005,dropout为0.1,我们分别选用测试集和验证集为10%和10%。
表1实验对比:
表1和图2为本发明在数据集上与其他三个算法的比较的各项指数,完整性,mi,ami为无监督学习在算法是否精确的一个指标,取值区间为[-1,1],数值越接近1,表明聚类效果与本发明的标注效果越接近,在这三项指标下,本发明方法在长文本新闻类别标注上,相比于其他算法是最好的。
技术特征:
1.一种基于预训练的长文本新闻标注方法,其特点在于,包括如下步骤:
步骤s1:数据预处理
将爬取的新闻进行数据清洗,去除特殊字符,并将短于200字长度的新闻过滤掉;
步骤s2:数据集划分
将每类新闻数量保持稳定,按照训练集80%,验证集10%,测试集10%的比例来划分;
步骤s3:加载模型
将预训练模型加载,设置模型参数;
步骤s4:训练模型
将训练集和验证集进行训练,并在每100轮显示当前loss、accuracy等信息;
步骤s5:文本标注
用训练好的模型,对无标签的新闻进行文本标注,并用kmeans聚类,得到mi、ami、完整性等指标,判断标注效果。
2.如权利要求1所述的基于预训练的长文本新闻标注方法,其特征在于:步骤s1中数据集是本发明自建新闻长文本数据集,其中文本长度均大于200字,分为财经、房产、教育、科技、军事、汽车、体育、游戏、娱乐9类。
3.如权利要求1所述的基于预训练的长文本新闻标注方法,其特征在于:步骤s4将训练集和测试集的数据构建词向量,并进行mask,将生成的词向量传入bert模型,将得到的向量增加维度,进行卷积和池化操作,在进行dropout随机掩盖,最后通过全连接层降维,得到最终的表示,在每100轮的时候,计算当前loss,acc等信息,进行反向传播。
4.如权利要求1所述的基于预训练的长文本新闻标注方法,其特征在于:步骤s5用无标签的长新闻文本,放进模型中,得到预测的类别,并进行文本类别标注,然后用kmeans聚类,将聚类标签与预测标签进行对比,得到mi、ami、完整性等指标,判断标注效果。
技术总结
本发明公开了基于预训练的长文本新闻自动标注方法,该方法的目的是为了给新闻自动标注类别,该模型的主要步骤是:数据预处理,数据集划分,加载模型,训练模型,进行文本标注。传统的人工标注成本高,并且费事费力,而传统机器学习在长文本的分类方面表现,有些力不从心,经典的长文本模型算法,因为中文的语法差异,效果也不是特别好,基于以上考虑,本发明提出了基于预训练的长文本新闻自动标注方法,可以对长文本的新闻类别进行自动标注。
技术研发人员:王红梅;郭放;张丽杰;党源源
受保护的技术使用者:长春工业大学
技术研发日:2021.06.09
技术公布日:2021.08.06
- 还没有人留言评论。精彩留言会获得点赞!