基于生成对抗网络和注意力机制的视频行人重识别方法
本发明涉及计算机视觉领域,尤其涉及一种基于生成对抗网络和注意力机制的视频行人重识别方法。
背景技术:
随着社会对公共安全的日益重视,视频监控系统无处不在,在计算机视觉领域,行人重识别逐渐成为研究热点。虽然深度学习目前在人脸识别技术非常成熟,但在实际的场景中,我们很难提取到摄像头下行人的脸部特征信息,通过提取行人全身特征进行行人查找成为一种主要的研究方法。
行人重识别是指在非重叠视域的监控系统中,检索和匹配不同摄像头下的两个行人是否为同一个行人的技术。目前大多数针对行人重识别的研究都是基于图像,通过提取单帧图片的空间特征完成识别任务。由于摄像机之间的分辨率差异、光照、行人遮挡等因素的影响,导致同一行人在不同摄像机下的外观特征存在很大的差异,给重识别任务带来很大的挑战。连续的视频序列包含有时域信息,通过融合时域和空间特征能够有效避免上述因素带来的问题,能够提高重识别精度。
现有基于视频行人重识别依靠卷积神经网络和循环神经网络构建识别模型,通过卷积神经网络自动学习出高维、复杂的行人全局特征和局部特征,利用循环神经网络捕获相邻视频帧上下文之间的联系,获得一个视频层次的特征表示。由于图像的特征具有很强的表征能力,利用简单的距离算法进行特征之间的相似性度量,因此,目前大多数行人重识别算法都是基于改进神经网络的结构,优化特征提取方法,以获取更高的识别精度。行人重识别模型的训练需要依赖大量的训练数据,现有公开的视频行人重识别的数据集中,由于有些行人在摄像头下出现的时间很短,往往造成训练数据不足,使得模型很难广泛适用于复杂的视频监控系统。
技术实现要素:
本发明的目的是为了弥补行人重识别数据不足的缺陷,克服行人遮挡、光照变化等噪声信息的影响,提供一种基于生成对抗网络和注意力机制的视频行人重识别方法。
为达到上述目的,本发明是按照以下技术方案实施的:
本发明提供一种基于生成对抗网络和注意力机制视频行人重识别方法,包括如下步骤:
步骤1:生成对抗网络结合图像多尺度结构构建视频帧预测模型,不同尺度采用双线性插值算法进行转换;
步骤2:利用现有连续5帧图像作为生成器的输入,将下一帧真实图像和生成器生成的图像输入到判别器,损失函数使用二元交叉熵,采用随机梯度下降法进行参数优化,通过不断迭代训练,最终使得判别器无法区分真实图像和生成图像;
步骤3:使用训练好的生成器,通过输入每个行人图像序列最后5帧图像,循环生成预测的5帧图像,并且对生成的行人图像进行标签平滑;
步骤4:使用预训练的resnet50网络,增加一层具有2通道输入,64通道输出,卷积核大小为3×3的卷积层,删除最后全连接层和平均池化层,增加一层批归一化层;
步骤5:将数据集中每个行人的图像序列按照采样步长为4,采样长度为8方式进行序列分割;
步骤6:利用门循环单元捕捉每个图像片段序列输出的特征之间的依赖关系,通过自注意力机制提取整个片段序列的特征表示;
步骤7:将步骤4和步骤6的网络进行复制,将两个网络并行连接组合成一个的孪生网络;
步骤8:将孪生网络两个分支提取的特征输入到一个平方差层,平方差层后是一个2048×2的全连接层和一个sigmoid层,构建一个完整的孪生网络模型;
步骤9:使用步骤5分割的片段序列,选取50%的数据进行训练,剩下的50%用于测试;
步骤10:训练行人重识别网络,利用随机梯度下降法优化损失函数,对网络中参数进行优化;
步骤11:使用训练好的重识别模型,将一个待查片段序列作为孪生网络的一个输入,将候选片段序列集中片段序列作为孪生网络的另一个输入,得到孪生网络对两个序列的判别和分类结果;
步骤12:将两个行人片段序列的分类结果和两序列是否一致作为判别条件,判别两个输入序列是否属于同一行人。
进一步的,所述生成对抗网络结合图像多尺度结构构建视频预测模型,采用4个尺度进行训练,具体步骤如下:
步骤1:图像多尺度结构采用拉普拉斯金字塔结构,通过双线性插值的方式不断进行上采样。通过真实的图像序列和上一尺度经过上采样得到的预测图像进行融合生成当前尺度的预测图像。
步骤2:判别模型用来判别输入序列最后一帧是生成的还是真实的图像,同时满足不同图像尺度的变化,输出单个标量。
步骤3:生成器和判别器的训练采用对抗策略,模型采用二分类交叉熵作为损失函数,使用随机梯度下降法优化模型参数。训练过程中将真实数据样本判别为1类,将生成器生成的预测图像判别为0类。生成器损失函数采用和判别模型损失函数对抗的形式进行设计,将生成器生成的预测图像设定为1类。
步骤4:生成器和判别器都是通过最小化损失函数来达到模型训练效果,使得生成模型生成的图片取迷惑判别模型,使得判别器最终分辨不出真实图像和生成图像。通过增加附加的损失函数减少对抗损失在生成模型中所占权重来提高模型训练的稳定性。因此,设计生成模型联合损失函数,在对抗损失的基础上加入图像梯度差分损失和图像距离损失。
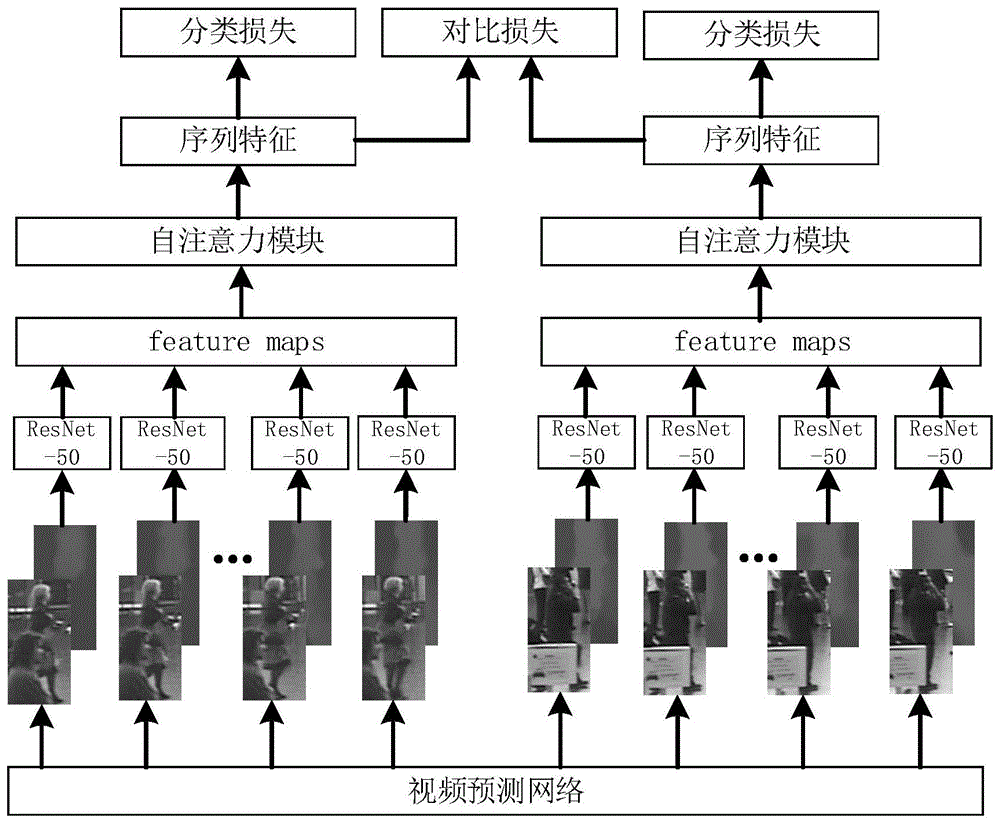
进一步的,所述视频行人重识别网络采用孪生网络融合自注意力机制构建,具体步骤如下:
步骤1:使用预训练resnet50提取每一帧图像的特征,在预训练的resnet50的基础上将最后的全连接层和平均池化层替换成批归一化层,添加一层输入通道为2,输出通道为64,卷积核大小为3×3的卷积层,来满足3通道的rgb图像和2通道的光流图的同时输入。
步骤2:为了充分利用时间序列信息,使用门控循环单元(gru)在连续视频帧之间获取上下文特征信息,通过加入注意力机制获得序列的整体特征信息。注意力机制采用点积自注意力,使用一个查询向量(query)和一对键值对(key-value),利用gru生成查询向量,将视频序列中的每帧图像特征乘以相应的权重矩阵生成键和值。
步骤3:在训练阶段网络中输入一对序列,利用二分类交叉熵函数作为损失函数来监督片段之间相似性估计学习,同时联合在线匹配损失函数来监督行人id,对两个输入序列进行分类和相似性度量操作,判别输入的两个行人序列是否属于同一行人。
上述技术方案可以看出,由于本发明实施例采用生成对抗网络结合图像多尺度结构实现数据增强,采用自注意力机制对图像序列整体特征进行提取,实验结果表明在两个公开的数据集(ilids-vid,prid2011)上的识别精度均有明显提高,rank-1的精度分别为88%,95.5%。
本发明的有益效果是:
本发明是一种基于生成对抗网络和注意力机制的视频行人重识别方法,与现有技术相比,本发明利用生成对抗网络结合图像多尺度结构构建生成模型,通过已有的连续视频帧训练生成预测视频帧序列来增加训练样本的数量,提高识别精度。为提高视频行人重识别模型在不同实际应用中的泛化能力,使用孪生网络构建重识别模型,通过门控循环单元(gru)捕捉连续图像序列信息,一定程度上克服遮挡、光照变化等问题。为了克服图像帧的遮挡和减少冗余信息的学习,充分利用图像特征中具有判别力的信息,通过注意力机制融合获得连续视频序列的信息表征来完成重识别任务。
附图说明
图1融合生成对抗网络的视频行人重识别系统;
图2是生成对抗网络构建图像生成模型;
图3是生成对抗网络结合图像多尺度结构视频预测模型;
图4是视频行人重识别网络;
图5是视频预测结果图;
图(a)是ilids-vid数据集结果(前5帧是真实图像,后5帧是生成预测图像);
图(b)是prid2011数据集结果(前5帧是真实图像,后5帧是生成预测图像);
图6是融合生成对抗网络前后和光流对累计匹配精度的影响对比图;
图(a)是ilids-vid数据集的累计匹配精度对比图;
图(b)是prid2011数据集的累计匹配精度对比图。
具体实施方式
下面结合附图以及具体实施例对本发明作进一步描述,在此发明的示意性实施例以及说明用来解释本发明,但并不作为对本发明的限定。
1生成对抗网络结合图像多尺度结构构建视频预测模型
图2是构建视频预测基础网络结构,采用拉普拉斯金字塔结构构建视频预测模型,通过双线性插值的方式不断进行上采样。网络中各尺度生成网络生成预测图像可以表示成:
其中,k(1,2,3,4)表示对应尺度的图像尺寸,分别代表输入尺寸为4×4,8×8,16×16,32×32;l表示输入图片序列长度;uk表示通过双线性插值进行图像上采样,gk中通过真实的图像序列和上一尺度经过上采样得到的预测图像进行融合生成当前尺度的预测图像。
图3是视频预测网络,判别模型用来判别输入序列最后一帧是生成的还是真实的图像,同时满足不同图像尺度的变化,输出单个标量。生成器和判别器进行对抗训练,模型采用二分类交叉熵函数作为损失函数使用随机梯度下降算法优化损失函数。对生成的图像进行标签平滑处理,对于标签平滑的公式为:
其中ε(ε∈[0,1])是平滑因子,k是批量处理数据中的行人数。交叉熵损失函数可以表示为:
判别器损失函数的损失函数为:
训练过程中,将真实数据样本判别为1类,将生成器生成的预测图像判别为0类,(z,x)是来自于数据集中的样本,z表示连续的输入视频序列,x表示z的下一帧图像,
生成器损失函数采用和判别模型损失函数对抗的形式进行设计,将生成器生成的预测图像设定为1类,损失函数为:
生成器和判别器都是通过最小化损失函数来达到模型训练效果,使得生成模型生成的图片取迷惑判别模型,使得判别器最终分辨不出真实图像和生成图像。在训练过程中这种对抗损失函数会导致模型训练很不稳定。通过增加额外的损失函数减少对抗损失在生成模型中所占权重来提高模型训练队的稳定性。因此,设计生成模型联合损失函数,在对抗损失的基础上加入图像梯度差分损失和图像距离损失,联合损失函数表示为:
图像距离差损失通过最小化真实图像和生成图像之间的距离来优化模型,距离差损失函数如下,其中p可以取1或2,本发明模型训练采用2,
为了使生成的图像更加锐化,在重识别模型中具有更强的表征能力,加入图像梯度差损失函数作为惩罚项,利用生成预测图像和真实图像相邻像素的梯度差分和对角像素的梯度差分的差值构建损失函数,其中a的值是大于等于1的整数,模型训练过程中a的取值为4:
2视频行人重识别网络模型
图4是视频行人重识别网络,使用预训练resnet50提取每一帧图像的特征,在预训练的resnet50的基础上将最后的全连接层和平均池化层替换成一层批归一化层,添加一层输入通道为2,输出通道为64,卷积核大小为3×3的卷积层,来满足3通道的rgb图像和2通道的光流图的同时输入。对于给定的连续的图像序列c,其中包含l帧图像,第i帧图像的特征表示为
为了充分利用时间序列信息,使用门控循环单元(gru)在连续视频帧之间获取上下文特征信息,通过加入注意力机制获得序列的整体特征信息。注意力机制采用点积自注意力,使用一个查询向量query和一对键值对(key-value),利用gru生成query向量,将视频序列中的每帧图像特征乘以相应的权重矩阵生成键和值,具体计算方式如下:
利用查询向量query和每个键做点积运算得到注意力权重为
f(q,ki)=qτki
其中,ki=ki(c)表示第i帧生成的键。利用softmax函数将得到的权重归一化成概率和为1的分布,由此获得每帧图像对应的注意力权重为:
将注意力权重和对应的值进行加权求和得到注意力为:
其中,c表示矩阵中对应元素的乘积,vi=vi(c)表示第i帧生成的值。
在训练阶段网络中输入一对序列(sn,sm),利用二分类交叉熵损失函数来进行片段之间相似性学习,相似性可以表示为:
d(sn,sm)=σ[ffc((f(sn)-f(sm))2)]
上式中f(sn)和f(sm)表示视频序列sn,sm的特征向量,n,m表示对应行人的身份标签,函数ffc((f(sn)-f(sm))2)表示全连接层,将一个特征向量转换成一个标量形式,函数σ表示sigmoid激活函数,损失函数定义为:
利用resnet50的输出特征,构建行人分类损失函数来监督预测行人id,具体为
其中,xi表示第i张图像的特征,训练数据集中总共有t个行人共包含n张图像,如果第i张图片在第j个行人图像序列中,则yi,j=1,否则yi,j=0,w是特征权重参数。因此,联合损失函数为:
l=lver+lid
对两图像输入序列分类,度量两者的相似度;如果两序列的分类结果同属一类,那么就判断为同一个行人;否则不是同一个行人。
以上对本发明实施例所提供的一种融合生成对抗网络和注意力机制视频行人重识别方法,进行了详细的介绍,本文中应用了具体个例对本发明的原理及实施方式进行了阐述,以上实施例的说明只是用于帮助理解本发明的方法及其核心思想;同时,对于本领域的一般技术人员,依据本发明的思想,在具体实施方式及应用范围上均有改变之处,综上所述,本说明数内容不应当理解为本发明的限制。
- 还没有人留言评论。精彩留言会获得点赞!