一种自适应的主机入侵检测序列特征提取方法及系统
1.本发明涉及主机入侵检测技术领域,具体的说,是一种自适应的主机入侵检测序列特征提取方法及系统。
背景技术:
2.主机入侵检测技术是一种通过事后分析从而防止进一步攻击的入侵检测技术,具备检测性价比高、检测视野集中、易于用户剪裁、无需另设硬件平台等优点。系统调用序列代表了主机中运行进程的行为特征,是主机入侵检测系统重要的数据来源。系统调用序列通常被抽象为代表调用函数的数字向量,各个系统调用之间的组合顺序代表了进程潜在的行动目标。传统的主机入侵检测特征提取方法有基于窗口的特征提取方法,主要利用定长窗口对系统调用序列进行划分得到子序列,并直接统计子序列在进程系统调用过程中出现的频率作为检测模型的输入特征,存在窗口长度难以自适应选择,以及如何从窗口序列中选取有效的分类特征的困难。尤其在处理海量系统调用序列集时,不恰当的窗口长度划分会导致系统调用子序列数量爆炸式增长,从而造成计算成本增加。并且子序列对窗口长度敏感,过短的子序列容易被攻击者绕过,而长子序列的长度与所用数据相关性较高,利用长序列进行训练容易造成分类模型的过拟合。
技术实现要素:
3.本发明的目的在于提供一种自适应的主机入侵检测序列特征提取方法及系统,用于解决现有技术中基于定长窗口的特征提取方法不容易选择合适的窗口长度导致系统调用子序列数量爆炸式增长、计算成本增加以及过短的子序列容易被攻击者绕过,而长子序列的长度与所用数据相关性较高,利用长序列进行训练容易造成分类模型的过拟合的问题。
4.本发明通过下述技术方案解决上述问题:一种自适应的主机入侵检测序列特征提取方法,包括:步骤s100:从正常系统调用序列数据集提取定长特征子序列,包括:步骤s110:利用n
‑
gram(n元模型)以设定的滑动窗口值将输入的系统调用序列切分成定长子序列;步骤s120:利用tf
‑
idf(词频
‑
逆文本频率)对各个定长子序列进行加权,tf是词频(term frequency),idf是逆文本频率指数(inverse document frequency),tf
‑
idf是一种用于信息检索与数据挖掘的常用加权技术。然后根据权重的大小对定长子序列进行筛选得到定长特征子序列的集合即为定长语料库;步骤s200:从正常系统调用序列数据集提取变长特征子序列,包括:步骤s210:判断输入的系统调用序列的长度是否大于指定单位长度d,若是,进入步骤s220;否则进入步骤s230;步骤s220:将系统调用序列进行切分,得到系统调用子序列,进入下一步;
步骤s230:对每个系统调用序列或系统调用子序列分别建立后缀树,并筛选出每个系统调用序列或系统调用子序列的最长重复子串作为变长特征子序列,变长特征子序列的集合为变长语料库;步骤s300:将得到的定长语料库与变长语料库取并集得到特征语料库,统计特征语料库中的子序列在待测试系统调用序列出现的频率得到特征向量,利用自动编码机对特征向量进行降维,将降维后的特征向量输入分类器进行分类,并得到分类结果。
5.本发明结合了定长特征和变长特征对主机程序行为进行描述,较传统的方法的完全定长窗口划分法具有更好的自适应性,通过变长特征提取能够更好的刻画给定程序行为,而基于tf
‑
idf的定长特征选取方法,能够进一步提取出对分类贡献较高的特征,从而使入侵检测的特征描述更全面、客观。
6.所述步骤s120具体包括:步骤s121:统计定长子序列t
i
出现在所有系统调用序列中的频数,计算序列频数反比:其中,n为系统调用序列数据集中系统调用序列的总数,为系统调用序列数据集中的系统调用序列中出现过定长子序列t
i
的序列数;步骤s122:计算定长子序列t
i
在系统调用序列中出现的频数fre
i
:得到所有定长子序列t={t1,t2,
…
,t
m
}出现在系统调用序列的频率向量fre:fre=[fre1,fre2,
…
,fre
m
]步骤s123:计算进程行为权重:变换得到:;步骤s124:选取每个进程系统调用序列中进程行为权重前b位的定长子序列收录进定长子序列语料库:其中,t
jb
代表第j个系统调用序列中的第b个定长子序列,t
1b
代表第1个系统调用序列中的第b个定长子序列,t
nb
代表第n个系统调用序列中的第b个定长子序列,0<j≤n,n表示进程的数量。
[0007]
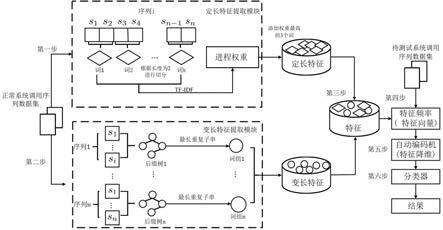
一种自适应的主机入侵检测序列特征提取系统,包括定长特征提取模块、变长特
征提取模块、特征融合模块、自动编码机模块和分类器模块,其中:定长特征提取模块,用于将正常的系统调用序列利用n
‑
gram切分成定长特征子序列,并利用tf
‑
idf对各个定长特征子序列进行加权,再根据权重的大小对定长特征子序列进行筛选得到定长特征子序列集即定长子序列语料库;变长特征提取模块,用于分别对正常的系统调用序列建立后缀树,并筛选出最长重复子串作为变长特征子序列,变长特征子序列集即为变长子序列语料库;特征融合模块,用于整合定长特征提取模块和变长特征提取模块的提取结果,分别统计定长子序列语料库与变长子序列语料库中的子序列在待测试系统调用序列出现的频率得到特征向量;自动编码机模块,用于对特征向量进行降维处理;分类器模块,用于对降维后的特征向量进行分类。
[0008]
本发明与现有技术相比,具有以下优点及有益效果:本发明结合了定长和变长特征对主机程序行为进行描述,较传统的方法的完全定长窗口划分法具有更好的自适应性,通过变长特征提取能够更好的刻画给定程序行为,而基于tf
‑
idf的定长特征选取方法,能够进一步提取出对分类贡献较高的特征,从而使入侵检测的特征描述更全面、客观。
附图说明
[0009]
图1为本发明的系统框图;图2为本发明中的定长特征提取流程图;图3为本发明中的变长特征提取流程图;图4为后缀树建立过程示意图;图5为后缀树建立结果示意图;图6为adfa
‑
ld数据集在支持向量机、朴素贝叶斯、逻辑回归、随机森林以及梯度下降树的roc曲线;图7为unm数据集在支持向量机、朴素贝叶斯、逻辑回归、随机森林以及梯度下降树的roc曲线。
具体实施方式
[0010]
下面结合实施例对本发明作进一步地详细说明,但本发明的实施方式不限于此。
[0011]
实施例1:一种自适应的主机入侵检测序列特征提取方法,包括:s1:提取定长特征:将正常系统调用训练数据集的系统调用序列(即训练数据)利用n
‑
gram(n元模型)滑动窗口值将每个系统调用序列切分成定长子序列,并利用tf
‑
idf对各个子序列进行加权,然后根据权重的大小对子序列进行筛选得到定长子序列,定长子序列集即为定长语料库,如图2所示。
[0012]
上述步骤s1中利用tf
‑
idf对各个子序列进行加权的计算方法如下::计算序列频数反比,首先利用n
‑
gram将系统调用序列划分为长度为2的等长子
序列,即长度为2的子序列为一个定长子序列。然后统计各个定长子序列t
i
出现在不同系统调用序列中的频数。即tf
‑
idf方法中的idf逆向文件频率概念,其中n为训练序列的总数,为系统调用序列数据集中的系统调用序列中出现过定长子序列t
i
的序列数。
[0013]
:计算单个序列词汇频数,统计各个定长子序列t
i
在单个系统调用序列中出现的频数fre
i
。即tf
‑
idf方法中的tf词频概念。fre代表系统调用序列中所有定长子序列t={t1,t2,...,t
m
}分别出现的频率向量。
[0014]
fre=[fre1,fre2,
…
,fre
m
]:计算进程行为权重,通过计算出的单个序列词汇频数与序列频数反比可得进程行为权重。为了防止序列频数反比的分母为0,所以将公式进行了转换。。为了防止序列频数反比的分母为0,所以将公式进行了转换。
[0015]
:系统调用序列定长语料库,因为进程行为权重表示了定长子序列t
i 的重要性,从而说明了该定长子序列对异常检测的分类贡献。根据每个系统调用序列进程行为权重的大小进行筛选,选取单个进程中进程行为权重前三位收录进定长序列语料库。但是因为从不同进程的系统调用序列所筛选出的定长子序列可能相同,而相同定长序列不重复收录,所以语料库的长度不会呈线性增长。t
ji 代表系统调用序列中的第i个定长子序列。
[0016]
s2:分别对每个正常的系统调用序列建立后缀树,并筛选出最长重复子串作为变长特征子序列,变长特征子序列集即为变长子序列语料库。提取变长子序列模块整体流程如图3。
[0017]
如图3所示,s2步骤中系统调用序列建立后缀树的过程如下:判断系统调用序列的长度。若系统调用序列长度大于500,则进行第步,否则进行第步。
[0018]
切分长度过长的系统调用序列。长度为len>500的系统调用序列seq
i
={s1,s2,...,s
500
,...,s
len
},将序列以d为单位切分成子序列{seq
i1
,seq
i2
,...,seq
ij
}。然后进行第、步。
[0019]
构建后缀树。ukkonen算法是一个经典的后缀树算法,其利用了路径压缩和后缀链的概念。ukkonen算法的基本思路是假设现有一非空字符串s,将字符c添加到非空字符串s的所有后缀上,即可得到s+c字符串的所有后缀。此处利用ukkonen算法将单个系统调用序列构建后缀树,例如序列seq=”6414143”,第一步,s=”6
”ꢀ
, s字符串的后缀树建树结果如图4中(1)所示,第二步,s=”6”,c=
’4’
,所以s+c字符串的所有后缀为seq1=”4”,seq2=”64”,s+c字符串的后缀树建树结果如图4中(2)所示,第三步,s=”64”, c=
’1’
,所以s+c字符串的所有后缀为seq1=”1”,seq2=”41
”ꢀ
,seq3=”641”,s+c字符串的后缀树建树结果如图4中(3)所示,以此类推,seq=”6414143”最终的建树结果如图5所示,图5中$为字符串的结束符号,字符串没有结束的时候没有$,字符串结束时才有$。
[0020]
搜索最长重复子串。为单个系统调用序列建立后缀树之后,搜索系统调用序列的最长重复子串p
k
,即搜索后缀树的最深非叶子结点。
[0021]
将从所有正常系统调用序列中提取出的最长重复子串进行整合得到变长子序列语料库。
[0022]
s3:将得到的定长子序列语料库与变长子序列语料库取并集得到特征语料库。其中代表定长子序列语料库,即各个提取出的定长特征子序列的集合,代表变长子序列语料库,即各个提取出的变长特征子序列的集合。
[0023]
s4:统计特征语料库中的子序列在待测试系统调用序列出现的频率作为特征向量。
[0024]
s5:为了避免步骤s4中得到的特征向量维度过高,利用自动编码机对步骤s4得到的特征向量进行降维。
[0025]
s6:将步骤s5的特征向量输入分类器进行分类,并得到分类结果。
[0026]
实施例2:结合附图1所示,一种自适应的主机入侵检测序列特征提取系统,包括定长特征提取模块、变长特征提取模块、特征融合模块、自动编码机模块和分类器模块,其中:定长特征提取模块:将输入的正常系统调用序列利用n
‑
gram技术以窗口值对系统调用序列进行切分。统计各个定长子序列出现在不同系统调用序列中的频数。然后,计算进程行为权重,通过计算出的单个定长子序列频数与所有序列频数反比可得进程行为权重。因为进程行为权重表示了定长子序列t
i
的重要性,从而说明了该定长子序列对异常检测的分类贡献。最后,根据每个系统调用序列进程行为权重的大小进行筛选,选取单个进程中进程行为权重前三位收录进定长序列语料库。
[0027]
变长特征提取模块:首先判断输入的正常系统调用序列的长度。若系统调用序列长度大于指定长度d,则切分长度过长的系统调用序列。长度len>d的系统调用序列,将序列
以d为单位切分成子序列,然后,将每一个子序列构建为后缀树。为单个系统调用序列建立后缀树之后,搜索系统调用序列的最长重复子串p
k
,即搜索后缀树的最深非叶子结点。最后,将从所有正常系统调用序列中提取出的最长重复子串进行整合得到变长子序列语料库。
[0028]
特征融合模块:整合定长和变长特征提取模块的结果,分别对所述的定长与变长子序列语料库中的子序列进行频率计数,并将计数结果作为初始特征向量;随后将初始特征向量利用自编码器进行降维,将降维后的特征向量作为主机入侵检测模型的特征向量。
[0029]
自动编码机模块:用于特征向量降维。利用自动编码机对特征向量进行降维。
[0030]
分类器模块:利用支持向量机对所产生的特征向量进行分类。
[0031]
为了证明本发明的有效性,本发明分别在由澳大利亚国防学院于2013年发布adfa
‑
ld数据集与来自新墨西哥大学免疫系统网站的unm数据集上进行了准确率实验与监测时间实验。
[0032]
为了验证所选特征在不同模型的效果,将从adfa
‑
ld数据集中提取的特征向量,分别使用支持向量机、朴素贝叶斯、逻辑回归、随机森林以及梯度下降树等模型进行计算,roc曲线如图6。从实验结果可以看出,利用本发明提取出的特征能够对系统调用序列进行有效分类。以及将从unm数据集中提取的特征向量,分别使用支持向量机、朴素贝叶斯、逻辑回归、随机森林以及梯度下降树等模型进行计算,roc曲线如图7。由结果可知,本算法在unm数据集上表现依旧良好,支持向量机、逻辑回归、随机森林以及梯度下降决策树效果与adfa
‑
ld数据集上的精确率结果相近,但误报率却下降至0%。从而说明了本算法并不依赖于特定数据,且分类效果稳定。
[0033]
尽管这里参照本发明的解释性实施例对本发明进行了描述,上述实施例仅为本发明较佳的实施方式,本发明的实施方式并不受上述实施例的限制,应该理解,本领域技术人员可以设计出很多其他的修改和实施方式,这些修改和实施方式将落在本申请公开的原则范围和精神之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1