软件产品线配置空间近似均匀采样方法
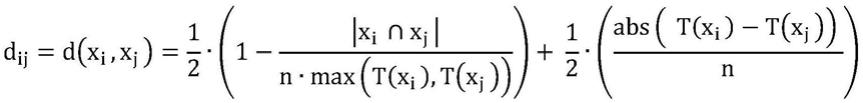
1.本发明涉及计算机软件产品线工程技术领域,尤其涉及软件产品线配置空间近似均匀采样方法。
背景技术:
2.软件产品线(software product lines,spls)是一种有效的软件开发方法,它在满足软件产品共性的基础上,可根据用户需求灵活地实现软件定制。采用软件产品线有助于节约开发成本、降低维护工作量以及缩短产品上市周期。著名的linux操作系统、eclipse开发环境和drupal网站内容管理系统等就是采用产品线技术开发的软件产品。
3.事实上,软件产品线采用可复用的模块化软件部件实现软件产品集的开发,该软件产品集通常由特征模型(feature model)表示。其中,一个特征指系统的某个特定软件部件,而产品则是特征的集合。特征模型明确了特征之间的约束关系,进而定义构成可行或有效软件产品(又称为软件配置)的所有特征组合。显然,随着特征数的增加,可行的软件配置呈指数式增长。所有可行软件产品构成的集合称为软件产品线配置空间,或简称配置空间。
4.在软件产品线工程众多任务中,认识配置空间的有关性质是非常重要的。这些任务包括,但不限于,根据目标和约束函数找到最优软件配置;通过训练的模型预测某个软件配置的性能;定位由特征之间的交互引起的错误等。最理想的情形是探索或访问每个可行软件配置,但这在实际中几乎不可行。主要原因在于配置空间的规模极大。例如,大规模的真实spls可包含成百上千个特征,相应的可行软件配置数量惊人,远远大于10
10
。显然,枚举所有软件配置是完全行不通的。
5.一种直观的解决方案是从配置空间选择一个小规模的、有效的且具有代表性的样本集。该样本集需仔细选择,能够从统计学意义上很好地代表整个配置空间。理想情况下,若无领域知识,样本应广泛且均匀地分布在整个空间。现有的采样策略包括:1)随机采样方法以随机的方式选择特征或软件配置。这种采样方法虽然简单,但是易于产生无效样本;2)基于求解器的采样方法借助现成的约束求解器,如sat4j等,生成样本。这种方法可扩展到大规模的真实软件产品线,但是无法确保随机性及覆盖率;3)覆盖率导向的采样方法,如著名的t
‑
wise采样,根据一定的覆盖准侧生成样本。然而,该方法生成的样本仅位于配置空间的特定区域,在某些情况下不具有很好的代表性;4)均匀采样方法要求每个软件配置被选择的机会均等。该方法能确保均匀性,但是计算代价大,无法有效扩展到大规模软件产品线。例如,对linux内核软件产品线,采用7个处理器并行运行均匀采样算法smarch,也无法在1个小时内生成12个样本。
6.由此可见,现有采样方法或者可扩展到大规模的真实软件产品线,但是无法确保均匀性;或者实现了均匀性,但是可拓展性差。如何折衷均匀性和可拓展性是当前待解决的一个重要问题。
技术实现要素:
7.为解决现有技术所存在的技术问题,本发明提供软件产品线配置空间近似均匀采样方法,通过利用sat求解器生成一组随机样本,然后运用搜索算法不断提升样本的多样性和均匀性;为度量样本间的距离,设计了一种新的距离计算公式,可有效地迫使样本在空间内尽可能分布均匀。
8.本发明采用以下技术方案来实现:软件产品线配置空间近似均匀采样方法,主要包括以下步骤:
9.s1、输入特征模型
10.s2、采用sat求解器随机生成特征模型的n个解,完成样本集a的初始化;
11.s3、计算样本集a中任两个解的距离,完成距离矩阵d的初始化;
12.s4、计算样本集a中所有个体的新颖得分;
13.s5、运用选择、交叉和变异算子生成一个新个体c,即新配置;
14.s6、采用新个体c更新样本集a;
15.s7、若允许的运行时间耗尽,则进入步骤s8,否则返回步骤s5;
16.s8、输出样本集a。
17.本发明与现有技术相比,具有如下优点和有益效果:
18.1、本发明采用sat求解器生成一组随机样本,然后运用搜索算法不断提升样本的多样性和均匀性;为度量样本间的距离,设计了一种新的距离计算公式,可有效地迫使样本在空间内尽可能分布均匀。
19.2、本发明克服了均匀采样方法耗时长、可扩展性差,非均匀采样方法无法保证均匀性等缺陷,允许用户根据自身需求灵活地设置算法的运行时间,以折衷均匀性和可扩展性,为实现软件产品线配置空间的近似均匀采样提供了有效的解决方案。
20.3、本发明综合运用可满足性求解器、搜索算法等多项数学及计算机领域的方法与技术,使得本发明在保证一定性能的同时,能够高效地处理大规模软件产品线配置空间的采样问题。
附图说明
21.图1是本发明的方法流程图。
具体实施方式
22.下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
23.实施例
24.如图1所示,本实施例软件产品线配置空间近似均匀采样方法,主要包括以下步骤:
25.s1、输入特征模型
26.s2、采用sat求解器随机生成特征模型的n个解,完成样本集a的初始化;
27.s3、计算样本集a中任两个解的距离,完成距离矩阵d的初始化;
28.s4、计算样本集a中所有个体的新颖得分;
29.s5、运用选择、交叉和变异算子生成一个新个体c,即新配置;
30.s6、采用新个体c更新样本集a;
31.s7、若允许的运行时间耗尽,则进入步骤s8,否则返回步骤s5;
32.s8、输出样本集a。
33.本实施例中,步骤s1中的特征模型以dimacs的格式存储在文件example.dimacs中,并读取该文件到计算机内存中。
34.本实施例中,步骤s2中每次产生特征模型的解时采用sat4j求解器,并随机化该求解器的参数;具体地,分别采用了三种参数随机化策略,即negativeliteralselectionstrategy,positiveliteralselectionstrategy和randomliteralselectionstrategy;执行每种策略的概率均为1/3;以生成多样化的软件配置。
35.本实施例中,步骤s2中,若n=2,则样本集a可初始化为:a={x1,x2},其中,x1={1,1,1,1,1,0,1,0,1},x2={1,1,1,1,1,1,0,0,1}。
36.本实施例中,步骤s3中距离矩阵d初始化为:
[0037][0038]
将距离矩阵d记为(d
ij
)
(n+1)
×
(n+1)
,其中,d
ij
表示样本集a中第i个解与第j个解之间的距离,其具体定义如下:
[0039][0040]
其中,x
i
∩x
j
表示两个解(本质上是集合)的交集,|x
i
∩x
j
|表示该交集的势;n表示特征总数;t(x
i
)表示解x
i
中被选特征总数;t(x
j
)表示解x
j
中被选特征总数;abs(
·
)表示返回某个数的绝对值。若x
i
=x
j
,则强制令d(x
i
,x
j
)=0。通过计算任意两个解之间的距离,即可完成距离矩阵d的初始化。此处,距离矩阵d的规模为(n+1)
×
(n+1)而非n
×
n,为后续保存新个体与现有个体之间的距离预留空间。
[0041]
本实施例中,步骤s4中个体的新颖得分定义公式如下:
[0042][0043]
其中,k为控制参数,表示与个体x
i
第j近的个体。由上式知,个体的新颖得分定义为与其最近的k个解的距离的平均值;若k=2,则ρ(x1)=ρ(x2)=0.444/2;由于这里仅有两个个体,故它们的新颖得分相等;一般地,个体的新颖得分未必相等。
[0044]
本实施例中,步骤s5中的选择算子包含以下步骤:
[0045]
s51、随机产生两个随机整数,s1,s2∈{1,2,
…
,|a|}且s1≠s2;
[0046]
s52、若成立,则将r1赋值为s1;若成立,则将r1赋值为s2;若成立,则将r1随机赋值为s1或s2;其中,r1为第一个父代的下标;
[0047]
s53、重复步骤s51和s52,确定另一个父代的下标r2;
[0048]
s54、若r1=r2,则返回步骤s53;否则进入步骤s55;
[0049]
s55、将和分别赋值给p1和p2,并将它们返回。
[0050]
本实施例中,步骤s5中由选择算子确定父代个体p1和p2后,执行均匀交叉和位变异算子生成新个体c1和c2。
[0051]
具体地,均匀交叉算子的执行过程如下:对每个下标j∈{1,2,
…
,n},产生一个随机数rand,若rand小于0.5,则将c1(j)和c2(j)分别取值为p1(j)和p2(j);否则分别取值为p2(j)和p1(j);其中,c1(j)表示子代个体c1第j个变量的取值。
[0052]
位变异算子的执行过程如下:对每个二进制位,若产生的随机数小于p
u
,则执行位变异,即将1翻转为0,或将0翻转为1;由于经交叉和变异操作产生的新个体有可能是无效的,因此,需利用probsat求解器修复无效的新个体。
[0053]
本实施例中,经选择、交叉和变异后,可能产生新个体c={1,1,1,1,1,1,1,0,1}。
[0054]
本实施例中,步骤s6包含以下步骤:
[0055]
s61、若样本集a中已存在与个体c相同的个体,则直接返回样本集a;
[0056]
s62、利用距离矩阵d,计算个体c与样本集a中所有个体的距离,置d
i,(n+1)
和d
(n+1),i
均为d(x
i
,c),置d
(n+1),(n+1)
为0;
[0057]
具体地,经计算后,距离矩阵d更新为:
[0058][0059]
s63、根据新颖得分定义公式,对任意个体x∈a∪c,计算其新颖得分ρ(x
i
);
[0060]
具体地,经计算后,各个体的新颖得分分别为:ρ(x1)=0.222,ρ(x2)=0.222,ρ(c)=0.25;
[0061]
s64、找出样本集a中新颖得分最小的个体,记为x
worst
;
[0062]
s65、若ρ(c)>ρ(x
worst
)成立,则用c替换x
worst
;并更新距离矩阵d,对每个j∈{1,2,
…
,n},置d
j,worst
和d
worst,j
分别为d
j,(n+1)
和d
(n+1),j
,置d
worst,worst
为0。
[0063]
本实施例中,个体c的新颖得分大于最差新颖得分,故将个体c加入样本集a。由于x1和x2的新颖得分相等,用个体c替换任意之一均可,如用c替换x1,替换后,矩阵d更新为:
[0064][0065]
本实施例中,样本集a的更新过程持续不断地强调新颖个体,有利于提升样本的多样性。
[0066]
本实施例中,步骤s7中,若未超过最大运行时间,则继续执行步骤s5和s6;生成另外一个新个体c={1,1,1,0,1,1,0,1,0};接着距离矩阵d更新为:
[0067][0068]
样本集a更新为:a={x1,x2},其中x1={1,1,1,1,1,1,1,0,1},x2={1,1,1,1,1,1,0,0,1};
[0069]
进一步地,新颖得分为:ρ(x1)=0.25,ρ(x2)=0.25,ρ(c)=0.254;个体c的新颖得
分大于最差新颖得分,用c替换x2或x1。
[0070]
本实施例中,输出的样本集可为a={{1,1,1,1,1,1,1,0,1},{1,1,1,0,1,1,0,1,0}}。
[0071]
本实施例首先采用sat求解器生成一组随机样本,然后运用搜索算法(即掘新搜索)不断提升样本的多样性和均匀性;为度量样本间的距离,设计了一种新的距离计算公式,可有效地迫使样本在空间内尽可能分布均匀。
[0072]
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1