一种基于数据挖掘技术的负荷预测方法与流程
1.本发明属于电力技术领域,具体来说,涉及一种基于数据挖掘技术的负荷预测方法。
背景技术:
2.电力负荷的预测对于电网运行规划管理、制定电力调度计划意义重大,精确的电力负荷预测方法能够实现电力能源的精准规划,是用户稳定用电、电网稳定运行、经济稳定发展的重要保障。过去常用的负荷预测方法如时间序列法、趋势外推法、回归分析法、灰色模型法等,但是需要建立精准且复杂的模型。大数据技术及数据挖掘技术的发展为海量负荷数据的高效处理提供了可行方式,常见的可用于负荷预测的数据挖掘技术有支持向量机、神经网络、聚类分析。
3.由于系统负荷由多个用电负荷构成,用电负荷的变化千差万别,不同类型的用电负荷具有自身的负荷特性与负荷发展规律,用电负荷在叠加时会削弱甚至抵消某些用电负荷的变化规律,使得系统负荷的规律性变得模糊,难以精确定位负荷波动真正原因;同时由于负荷的影响因素众多,且他们之间的非线性、复杂性和滞后性等特点,在实际应用中建立系统负荷与众多影响因素之间的关系模型存在很大困难。因此现有的负荷预测精度不高。
技术实现要素:
4.本发明的目的在于克服上述现有负荷预测技术的缺点,针对海量的电网运行数据,提供一种基于数据挖掘技术的电力负荷预测方法。
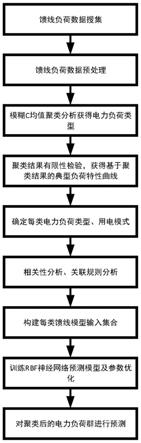
5.本发明具体为一种基于数据挖掘技术的负荷预测方法,包含以下步骤:
6.(1)获取馈线数据并进行预处理;
7.(2)使用数据挖掘技术中的聚类方法分析各类馈线的负荷特征,对获得的每类馈线负荷进行分析;
8.(3)根据各馈线簇的负荷水平和负荷曲线形状定性每类馈线负荷所属行业用电特性;
9.(4)构建影响因素集合;
10.(5)运用相关性分析和关联规则分析对影响负荷特性的诸多因素与每类馈线负荷进行分析,挖掘出馈线负荷特性与其影响因子间的关联特性;
11.(6)使用rbf神经网络对各馈线簇进行预测,根据各馈线簇在待预测时间的负荷预测值,得到系统在待预测时间的总用电负荷预测值,完成基于数据挖掘技术的负荷预测。
12.进一步的,所述步骤(2)具体包括以下步骤:
13.21)初始化聚类中心:随机选取c个聚类中心;
14.22)计算质心:不断迭代计算隶属度μ
ij
和簇中心c
j
的过程,直到他们达到最优;
15.其中隶属度
16.将每一个样本数据x
i
指派到最近的聚类中心,形成c个簇,目标函数如下:
[0017][0018]
其中:m为聚类的簇数;c为事先指定的聚类中心个数;x
i
为第i个样本;c
j
是j簇的中心;μ
ij
为样本x
i
相对于第j簇聚类中心的隶属度;
[0019]
23)通过迭代方法不断修正聚类中心,直到满足预先设置的目标函数精度,即当||μ
ij(k+1)
‑
μ
ij(k)
||<ε,停止迭代,否则返回步骤2);
[0020]
24)对分类好的馈线数据进行无量纲归一化,根据其负荷曲线可以分析出其用电特征。
[0021]
进一步的,所述步骤(4)中馈线负荷的影响因素集合中包括经济发展类指标、社会居民发展类指标和气候类指标,所述经济发展类指标包括gdp、第一产业生产总值、第二产业生产总值、第三产业生产总值、规模以上工业生产总值,所述社会居民发展类指标包括地区总人数、人均国内生产总值、居民消费价格指数、城镇化率。
[0022]
进一步的,所述步骤(5)具体包括以下步骤:
[0023]
51)在构建影响因素集合后,采用皮尔逊相关系数分析法判断每个影响因素与聚类后的馈线负荷数据的相关性;
[0024]
52)采用灰色关联分析法对强相关因素进行关联规则分析;
[0025]
53)获得关联性较强的因素,与聚类后的各类馈线负荷作为输入训练神经网络。
[0026]
进一步的,所述步骤51)具体包括以下内容:
[0027]
1)以聚类后的馈线负荷数据为参考序列x0,各个影响因素序列为比较序列x
i
;
[0028]
2)无量纲化处理:通过归一化处理将各数据处理为同一量纲下的数据;
[0029]
3)计算相关性,皮尔逊相关系数计算公式如下:
[0030][0031]
通过皮尔逊相关系数计算得出各影响因素与馈线数据的相关性强度,然后保留强相关以上的影响因素。
[0032]
进一步的,所述步骤52)具体包括以下内容:
[0033]
1)选取参考序列,即为馈线数据,比较序列,即为相关性分析筛选后的强相关性因素;
[0034]
2)数据变换:对数据进行处理变换,保证灰色关联分析在同一量纲下进行;
[0035]
3)计算关联度:采用典型灰色关联模型的邓氏模型,关联度计算公式如下:
[0036][0037]
其中:ξ(x0(k),x
i
(k))称为参考序列与比较序列的关联系数
[0038][0039]
进一步的,所述步骤(6)中:
[0040]
rbf神经网络的数据流向为:训练样本
‑
rbf隐藏层
‑
权重矩阵
‑
输出层,输入层到输出层为非线性映射,隐藏层的激活函数为径向基rbf函数;
[0041]
假设隐含层节点个数为s,第p个训练样本x
p
从隐含层的第i个节点(i=1,2,
…
,s)的输出为:
[0042][0043]
其中c
i
为第i个基函数的中心值,与输入向量同维数;x
p
‑
c
i
为核函数中心,σ为函数的宽度参数;||x
p
‑
c
i
||2为x
p
和c
i
的距离。
[0044]
进一步的,所述步骤(6)中:rbf神经网络算法流程主要包括以下步骤:
[0045]
1)网络初始化,随机选取h个训练样本作为聚类中心c
i
;
[0046]
2)使用k
‑
means算法将输入的训练样本集合聚类;
[0047]
3)重新调整聚类中心,直到新的聚类中心不再发生变化;
[0048]
4)求解方差
[0049]
式中c
max
为选取中心的最大距离;
[0050]
5)计算隐藏层和输出层的权值
[0051][0052]
6)输出
[0053]
将馈线负荷历史数据与影响因素作为输入集合训练神经网络,得到各馈线簇的预测值;各馈线簇的预测值之和即为整个馈线负荷的总用电负荷预测值。
[0054]
与现有技术相比,本发明提供的技术方案具有以下有益效果:
[0055]
本发明不受数据大小的限制,可以应用在不同地区的应用场景,对于实施例的描述,不应成为本发明的限制。本发明采用的模糊c均值聚类方法更科学有效的划分得到馈线簇类,能够准确得到各馈线的用电特征,从而获得更加精细化的负荷划分。使用相关性分析和关联规则分析二次筛选,得到的影响因素更加精确、科学,从而使得负荷预测的结果更加准确。
附图说明
[0056]
图1是本发明一种基于数据挖掘技术的负荷预测方法的流程图。
具体实施方式
[0057]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施案例对本发明进行深入地详细说明。应当理解,此处所描述的具体实施案例仅仅用以解释本发明,并不用于限定发明。
[0058]
获取系统中各馈线的历史负荷数据,在具体获取过程中,根据具体需求进行采集,采样点为采集时间96点负荷数据,采集时间为典型日(如每月最大负荷发生日);在采集到数据之后对异常值、空值进行处理,当数据量很大时可做行删除处理,另外在做模糊c均值聚类之前,需要对数据做归一化处理。
[0059]
在本发明中的用电行为分析步骤,借助聚类分析技术,即模糊c均值算法,聚类算法的流程主要包括以下步骤:
[0060]
1}初始化聚类中心:随机选取c个聚类中心;
[0061]
2)计算质心:不断迭代计算隶属度μ
ij
和簇中心c
j
的过程,直到他们达到最优。
[0062]
其中隶属度
[0063]
将每一个样本数据x
i
指派到最近的聚类中心,形成c个簇,目标函数如下:
[0064][0065]
其中:m为聚类的簇数;c为事先指定的聚类中心个数;x
i
为第i个馈线的负荷曲线,以向量表示;c
j
是j簇的中心;μ
ij
为第j个样本相对于第i类负荷曲线中心的隶属度。
[0066]
3)通过迭代方法不断修正聚类中心,直到满足预先设置的目标函数精度,即当||μ
ij(k+1)
‑
μ
ij(k)
||<ε,停止迭代,否则返回步骤(2)。其中第2)步决定了最终生成几个聚类簇,即几个行业,根据行业精细划分,聚类中心应在8个以上。
[0067]
构建影响因素集合:通过本地年鉴信息,搜集本地生产总值,人均生产总值等经济指标,搜集月最高气温、最低气温、降水量等气候指标,搜集城市化率,人均消费水平等社会发展指标。通过这些指标构建完整的影响因素集合;利用各主导因素构建每个簇类预测模型的输入集合。
[0068]
首先通过相关性分析,找出每个馈线簇中对馈线数据相关性较强的因素,以皮尔逊相关系数作为计算标准。再对这些相关性较强的因素与馈线负荷使用灰色关联模型进行关联规则分析,找出关联性较强的因素,作为主导因素构建每个簇类预测模型的输入集合。技术步骤如下:
[0069]
1)以聚类后的馈线负荷数据为参考序列x0,各个影响因素序列为比较序列x
i
。
[0070]
2)无量纲化处理。通过归一化处理将各数据处理为同一量纲下进性下一步的操作。
[0071]
3)计算相关性。皮尔逊相关系数计算公式如下:
modeler数据挖掘软件完成此步,自动完成神经网络的训练。
[0093]
下面列举一个实例。
[0094]
以某地区的馈线负荷为例,采样时间范围为2017
‑
01——2020
‑
07中每个月的典型日负荷数据,采样间隔为15min,每个馈线每天采样96点数据。使用模糊c均值将其聚类,最终获得18个聚类簇。以聚类1和聚类6为例,进行相关性分析,结果如下:
[0095][0096]
对相关性为强的进行灰色关联分析,结果如下:
[0097][0098]
可以得出聚类1关联度最高的因素gdp和人均gdp,聚类6关联度最高的因素gdp和人均可支配收入。
[0099]
将关联因素和各类聚类簇一起作为输入分别进行rbf神经网络训练,最终得到预测结果——2020年8月最大负荷。下面为与传统的预测方法线性回归模型及不考虑聚类的rbf神经网络预测模型方法的对比:
[0100][0101]
最后应该说明的是,结合上述实施例仅说明本发明的技术方案而非对其限制。所属领域的普通技术人员应当理解到,本领域技术人员可以对本发明的具体实施方式进行修改或者等同替换,但这些修改或变更均在申请待批的权利要求保护范围之中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1