一种基于深度卷积逆向图网络的非视域成像方法
1.本发明公开了一种基于深度卷积逆向图网络的非视域成像方法,属于计算成像领域。
背景技术:
2.非视域成像目前主流的成像方法包括主动式和被动式成像,主动式成像是目前研究较早方法较广的领域,其成像设备主要包括调制脉冲激光器和高速成像设备如条纹相机等,高速相机的时间分辨率一般能达到皮秒甚至飞秒级别,相对于光的传播速度而言,可以实现瞬态光传输下的光信息的获取。主动式成像设备虽然设备先进,但设备价格以及成像的复杂度都较高,对于实验室外的应用产生了一定的限制。
3.被动式非视域成像无需借助主动光源,只需成像场景自发光或者借助物体反射环境光,但此种方法成像时,成像受制于环境光的干扰,会导致成像时信噪比下降。目前被动式非视域成像的方法包括了使用光强度信息、偏振信息以及相干性信息等。传统的被动式非视域成像设备虽然没有主动式成像设备复杂,但依赖于先进的算法会导致成像的速度下降。本发明基于深度学习原理,对于某些固定视角下的场景如监控安防场景,使用非视域场景(如监控死角)和视域内的场景(如监控场景)预先对于神经网络进行训练,后续使用时只需向网络中输入视域场景图像,网络可输出非视域场景图像,具有成像速度快、设备简单等优点。
技术实现要素:
4.技术问题:本发明的目的是针对上述现有技术存在的问题和不足,提出了一种基于深度卷积逆向图网络的非视域成像方法,成像硬件设备只需普通相机即可,软件借助深度卷积逆向图网络,从而实现了某些固定视角场景下的快速非视域成像。
5.技术方案:本发明的一种基于深度卷积逆向图网络的非视域成像方法,该方法基于两台固定视角的相机、一台控制两台相机拍摄和训练神经网络的上位机;该方法包括以下步骤:
6.步骤1:使用相机1获取非视域场景图像,相机2获取非视域场景所产生的反射图像;
7.步骤2:根据使用场景搭建深度卷积逆向图网络;
8.步骤3:对步骤1获取的非视域场景图像及其所产生的反射图像及进行预处理后,以反射图像为输入,对应的场景图像为输出,作为训练网络的数据集;
9.步骤4:使用步骤3得到的数据集对步骤2建立的深度卷积逆向图网络进行训练,并保存训练得到的包含网络参数供后续使用;
10.步骤5:使用相机2获取非视域场景所产生的反射图像,经过预处理后送入步骤4中训练完成的神经网络,输出对应的非视域场景图像;
11.其中:
12.执行步骤1时,需要所述的上位机控制相机1与相机2同时拍摄,确保获取的非视域场景图像与非视域场景所产生的反射图像对应。
13.所述深度卷积逆向图网络,其编码器部分基于卷积层,解码器基于转置卷积层,网络层数根据场景的复杂度调整。
14.步骤3和步骤5中所述预处理包括对图像进行roi(regionofinterest,感兴趣区域)提取、根据网络的输入维度对图像进行重采样即上采样或者下采样、对图像进行背景消除。
15.所述对图像进行roi提取和重采样时使用逆透视变换,背景消除时使用图像差分即使用反射图像与背景图像在非视域场景中无内容时进行差分。
16.所述深度卷积逆向图网络,其输入维度需要与非视域场景产生的反射图像通道数匹配,即非视域场景产生的反射图像是彩色、灰度时对应的网络输入维度不相同。
17.所述步骤4训练深度卷积逆向图网络使用的损失函数为
18.l(θ,φ)=d
kl
(q
φ
(z|x)|p(z))
‑
e
z~q
[logp
θ
(y|z)]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(1)
[0019]
其中,θ和φ分别表示解码器和编码器的网络参数,x表示输入图像,z表示潜变量,d
kl
(q
φ
(z|x)|p(z))表示解码器输出分布q
φ
(z|x)与先验分布p(z)之间的kl散度,e
z~q
[log p
θ
(y|z)]表示解码器的似然概率,训练网络的过程中,通过最小化损失函数进行训练,通过测试集图像的输出来查看网络的训练情况,网络参数的保存设置为每训练10次保存一次参数。
[0020]
所述步骤5获取的非视域场景所产生的反射图像需要经过与步骤3相同的预处理后送入训练完成的网络。
[0021]
有益效果:本发明的基于深度卷积逆向图网络的非视域成像方法,对于固定视角下的非视域成像具有速度快、成像设备简单等特点。对于固定视角下如监控安防场景适用,只需预先针对场景训练好网络,对于不同的场景,网络结构更改简单,具有较好的普适性。
附图说明
[0022]
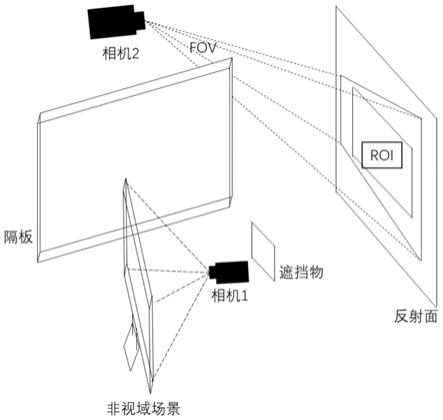
图1为根据本发明实施例的非视域场景立体图;
[0023]
图2为根据本发明实施例的非视域场景俯视图;
[0024]
图3为非视域场景变化示意图;
[0025]
图4为深度卷积逆向图网络模型图;
[0026]
图5为深度卷积逆向图网络结构图。其中,i为卷积层,ii为bn层,iii为relu层,iv为池化层,v为全连接层,vi为转置卷积层。
具体实施方式
[0027]
现结合附图和实施例进一步阐述本发明的技术方案。
[0028]
本发明的基本思想为:非视域成像为根据相机获取的非视域场景在某处产生的反射图像来获取其中来自非视域场景的信息,并推断非视域场景的图像。而深度卷积逆向图网络的一般结构为输入一副图像,经过网络计算后生成另一幅图像,该结构适用于非视域成像的场景。对于某些固定视角的场景,如监控安防场景,相机所拍摄的位置固定,故其所拍摄的信息出处固定,对于某些监控死角区域,可被视为非视域场景,但其所产生的反射信
息可被监控获取。由此,若使用大量的非视域场景图像及其所对应的反射图像训练深度卷积逆向图网络,那么当网络训练完成后,当向网络中输入非视域场景所产生的反射信息时,网络即可根据预先训练的网络模型,计算得到相关的非视域场景图像,具体的操作据原理如下所述。
[0029]
如图1所示的非视域场景中,非视域场景的信息是不断变动的,那么其在反射面上所产生的反射图像也是随之而变化的,场景中之所以出现遮挡物,是因为遮挡物的存在会对非视域场景的信息进行一定程度的编码,此时在反射面上产生的反射信息被称为半影信息,该半影信息对于当反射面为漫反射面时尤为重要,若不存在遮挡物的情况下,由于反射面上每点的信息均来自非视域场景上所有点,此时会导致反射信息过于冗余而保留很少的有用信息。当反射面为高光材质或其他材质时,该遮挡物的作用会被削弱。由于对于监控安防等领域,其相机所拍摄的图像背景基本都是固定的,场景中有任何物体的移动都会直接或间接影响相机所拍摄的图像,而在非视域成像中,正是利用间接影响。如图3所示,非视域场景中物体位置的变化,虽然不会直接影响相机2所拍摄的画面,但由于物体位置的移动会对空间中光的分布产生影响,对应在反射面上产生的反射信息也会受到影响,这种影响即可被网络提取出相应的特征用于生成非视域场景的图像。
[0030]
基于深度卷积逆向图网络的非视域成像方法,首先需要制作用于训练网络的数据集,数据集主要由非视域场景图像和非视域场景在反射面上所产生的反射图像组成,其中非视域场景在反射面上产生的反射图像作为深度卷积逆向图网络的输入,而非视域场景图像作为网络的输出。数据集的获取由上位机控制的两台相机分别获取,并且需要两台相机同时进行拍摄,以确保非视域场景与其所产生的反射图像对应。拍摄时,非视域场景中的物体一般是不断变化的,但背景一般固定不变,训练网络一般需要上万级别的数据集。
[0031]
获取上述的数据集后,不能直接用于神经网络的训练。对于反射图像,相机拍摄时角度有一定的偏移,由于透视效应会导致图像产生一定的形变,如图1所示的roi区域需要经过逆透视变换后才能变为矩形图像。并且由于神经网络的输入一般不适宜使用较大维度的数据,故经过逆透视变换后的图像一般还需要进行重采样以符合神经网络的输入维度。对于场景中存在环境光干扰的情况下,还需对反射图像进行背景消除。这一步可提前拍摄背景图像,在对反射图像进行预处理时,可直接使用反射图像与背景图像进行差分的操作。对于非视域场景图像,由于只在训练阶段获取图像,相机的位置对准非视域场景即可,一般只需重采样而无需进行其他变换。
[0032]
在对数据集元数据进行基本的预处理后,需要对数据集进行划分,分为训练集、测试集和验证集,划分比例一般使用60:20:20,如果所用的数据集数量较大,可使用98:1:1的比例。由于目前神经网络的训练一般借助于深度学习框架如tensorflow等,故数据集还需转换成tensorflow能读取的张量,这一步可以预先将所有数据集打包为张量,但考虑到图像占用的内存较大,可采用分批读取的方法。
[0033]
搭建深度卷积逆向图网络可根据非视域场景图像的复杂度来调整网络的层数即结构,但网络的基本结构不变,如图4所示,网络由编码器和解码器构成。编码器负责将预处理过的非视域场景产生的反射图像读入,并负责将图像进行降维和概率分布的提取。而解码器负责采样概率分布,并将图像维度进一步提升以根据采样的特征绘制非视域场景图像。网络的详细结构如图5所示,解码器主要由卷积层、batchnormalization层(bn层)、relu
层和池化层堆叠而成,降维的同时提取特征,堆叠层数可根据成像场景的复杂度做相应的调整。编码器的最后一层为全连接层,用于概率分布的输出,而潜变量z则通过重采样来获取。解码器则通过读入潜变量,通过堆叠转置卷积层实现对图像维度提升的同时绘制非视域场景图像,转置卷积层的数量也可根据成像需要调整,最终输出非视域场景图像。训练网络时所使用的损失函数为
[0034]
l(θ,φ)=d
kl
(q
φ
(z|x)|p(z))
‑
e
z~q
[logp
θ
(y|z)]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(2)
[0035]
其中,θ和φ分别表示解码器和编码器的网络参数,x表示输入图像,z表示潜变量,d
kl
(q
φ
(z|x)|p(z))表示解码器输出分布q
φ
(z|x)与先验分布p(z)之间的kl散度,先验分布p(z)一般为标准正态分布,表示解码器的似然概率,一般用网络输出与训练集中参考值的交叉熵损失函数表示。实际训练网络时,一般假设解码器输出分布q
φ
(z|x)与先验分布p(z)均为正态分布,其中p(z)为标准正态分布q
φ
(z|x)为则
[0036][0037]
而解码器的似然概率则使用交叉熵损失函数表示,即
[0038][0039]
其中x和y分别表示网络的输入和输出,f代表网络所表示的非线性关系。
[0040]
按照上述损失函数采取有监督学习的方式训练网络完成后,即可将验证集用于验证网络的实际效果,并可将后续相机1拍摄的反射图像预处理后作为输入,用于输出非视域场景图像。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1