一种安全且高效的联邦学习内容缓存方法
本发明属于无线通信技术领域,涉及一种安全且高效的联邦学习内容缓存方法。
背景技术:
当前,随着互联网和移动技术的高速发展,移动数据流量急剧增长,这给本已拥挤的移动网络带来了巨大的压力。一方面,巨大的数据流量导致回程流量负载高、延迟长,而另一方面,用户希望快速高效地获取高质量的内容。因此,在移动网络边缘部署缓存设备十分必要。缓存设备避免了重复的数据传输,使数据更加接近用户侧,从而可以减少用户与因特网之间的回程流量负载、减轻骨干网络的负载、减少移动用户的服务延迟,是一种很有前途的方法。然而,缓存设备的缓存能力是有限的,如何高效的利用设备的缓存能力成为了当前研究的热门领域,即设计高效的缓存决策方案。
从总体上看,缓存方案分为两种,一是反应式缓存,二是主动缓存。反应式缓存基于用户过去的访问请求决定缓存什么内容,例如先进先出(firstinputfirstoutput,fifo),最近最少使用(leastrecentlyused,lru),最不常用(leastfrequentlyused,lfu)。由于它们只是针对历史的访问请求做出反应,所以具有滞后性。虽然能很快地对流行内容的变化做出反应,但是没有考虑内容的流行趋势,导致缓存命中率较低。与此相反,主动缓存首先利用历史请求和上下文信息来预测内容的流行趋势,然后主动挑选将来可能流行的内容并缓存下来,这对缓存命中率的提高十分有帮助。目前,机器学习算法被广泛的应用于预测内容的流行趋势,融入到主动内容缓存之中。
在一般的机器学习算法中,数据运算是在中央处理器中完成的。换句话说,用户数据是高度受控的,即需要将全部数据收集到中央处理器统一训练。例如,使用强化学习的方法(参见文献:n.zhang,k.zhengandm.tao,"usinggroupedlinearpredictionandacceleratedreinforcementlearningforonlinecontentcaching,"in2018ieeeinternationalconferenceoncommunicationsworkshops(iccworkshops),pp.1-6,2018),协同过滤的方法(参见文献:e.bastug,m.bennis,andm.debbah,“livingontheedge:theroleofproactivecachingin5gwirelessnetworks,”ieeecommunicationsmagazine,vol.52,no.8,pp.82–89,2014.),线性回归的方法(参见文献:k.n.doan,t.vannguyen,t.q.s.quekandh.shin,"content-awareproactivecachingforbackhauloffloadingincellularnetwork,"inieeetransactionsonwirelesscommunications,vol.17,no.5,pp.3128-3140,may2018.)等来预测内容的流行趋势。然而,上述集中式机器学习方法需要收集用户的信息和行为数据来训练模型,而事实上用户并不愿意提供这些数据,因为它们通常会涉及用户的隐私和敏感信息。由此可见,这种需要上传数据的集中式机器学习方法因涉及隐私和安全问题而在实际中难以推行,因此需要探索既能够有效保护用户隐私又能够对内容的流行趋势进行有效预测的机器学习训练方法。
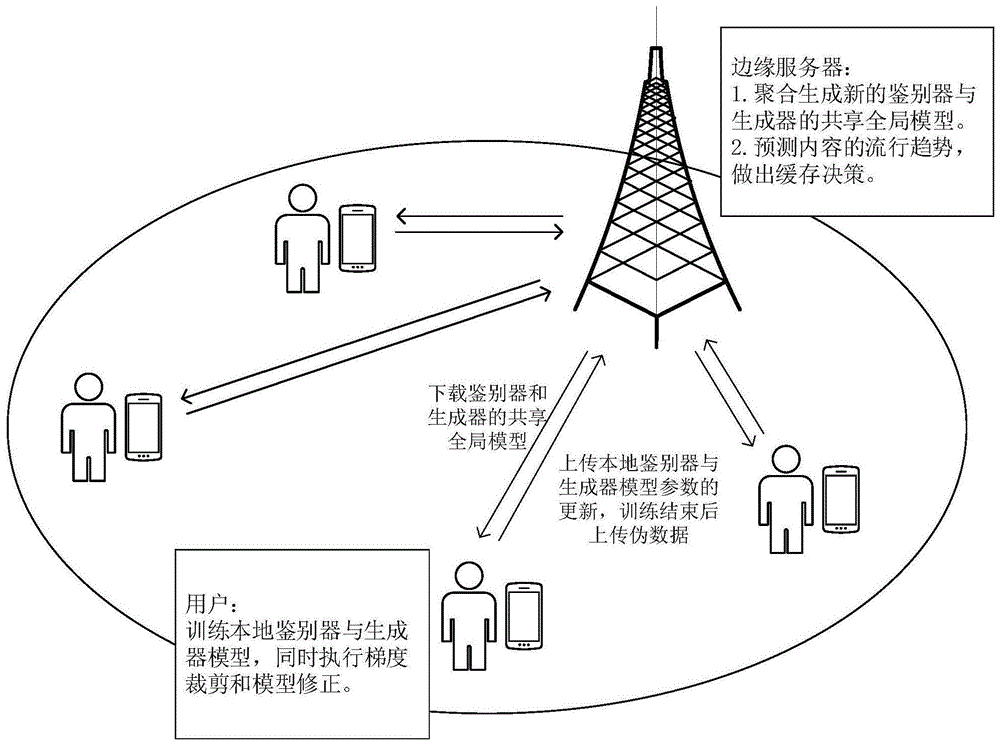
联邦学习是一种分布式框架,可以有效地保护参与者(即用户)私有数据的安全性。在联邦学习的训练过程中,边缘服务器负责维护共享的全局模型,每个参与者根据共享模型进行本地训练、生成本地模型。边缘服务器与参与者之间不进行私有数据的交换,而是交换共享全局模型与本地模型参数的更新。具体地,边缘服务器接收每一个参与者本地模型的更新,聚合为新的共享模型以供下次训练。参与者接收新的共享模型,利用本地数据进行模型训练,从而生成新的本地模型并把更新发送至边缘服务器。以此循环往复,完成训练过程。然而,现存的基于联邦学习的主动内容缓存方法,虽然保证了参与者私有数据的安全性,但仍然会泄露参与者的部分隐私。例如,将联邦学习应用在雾无线接入网中(参见文献:y.wu,y.jiang,m.bennis,f.zheng,x.gaoandx.you,"contentpopularitypredictioninfogradioaccessnetworks:afederatedlearningbasedapproach,"icc2020-2020ieeeinternationalconferenceoncommunications(icc),2020,pp.1-6.),该方法虽然结合了联邦学习的思想,但是需要用户将个人对内容的偏好发送到雾接入点中,这暴露了用户的隐私;将自动编码器和混合过滤结合在联邦学习中(参见文献:z.yu,j.hu,g.min,h.lu,z.zhao,h.wang,andn.georgalas,“federatedlearningbasedproactivecontentcachinginedgecomputing,”in2018ieeeglobalcommunicationsconference(globecom),2018,pp.1–6.),该方法虽然保证了用户的私有数据在本地训练,但仍需每个用户上传一个内容推荐列表,这暴露了单个用户对内容的偏好;使用神经网络来预测加权流行度(参见文献:k.qiandc.yang,"popularitypredictionwithfederatedlearningforproactivecachingatwirelessedge,"in2020ieeewirelesscommunicationsandnetworkingconference(wcnc),2020,pp.1-6.),该方法虽然不会暴露单个用户对内容的偏好,但仍暴露了用户对内容的访问请求总数,即活跃度水平。上述方法均在不同程度上导致了用户的隐私泄露,从而阻碍了基于联邦学习的主动内容缓存的进一步发展。
另外,上述方法均基于联邦学习假设模型梯度可以安全共享(边缘服务器与参与者之间交换模型参数的更新,本质是共享本地模型梯度),不会暴露参与者的私有训练数据,这在理想情况下是可行的。然而,在现实中模型梯度共享的安全性并不能完全保证,因为参与者的模型梯度仍然可以揭示私有训练数据的某些属性,例如属性分类器,甚至完全暴露参与者的私有训练数据,例如梯度的深度泄露(参见文献:l.zhu,z.liuands.han,“deepleakagefromgradients,”in2019conferenceandworkshoponneuralinformationprocessingsystems(neurips),2019.)。综上所述,从参与者的本地模型和梯度中获取私有的训练数据是完全有可能的,因此,有必要重新思考联邦学习中模型梯度的安全性,探索梯度级安全的联邦学习方法,寻找在高效预测内容流行趋势的前提下有效保护用户隐私的联邦学习主动内容缓存方法。
基于此,本发明提出了一种安全且高效的联邦学习内容缓存方法,它可以准确预测内容的流行趋势、实现接近理想的缓存命中率,还可以保证梯度级的隐私安全,从而很好的保护用户的私有数据。具体地,采用wasserstein生成对抗网络(wassersteingenerativeadversarialnetworks,wgan)作为预测内容流行趋势的训练框架,基于联邦学习,在边缘服务器中维护两个共享的全局模型:鉴别器共享模型和生成器共享模型。出于对用户私有数据安全的考虑,每个用户在本地基于共享模型使用私有数据训练wgan鉴别器模型和生成器模型。同时,出于对模型梯度安全的考虑,每个用户需要在本地进行梯度裁剪和模型修正,然后才能将其模型参数的更新发送至边缘服务器,以聚合生成新的共享模型供下次训练。在训练的过程中,通信成本是用户与边缘服务器之间发送和接收的每一个模型更新,本发明中的每个用户只发送修正且更新过的模型参数,这不仅保证了模型梯度和私有数据的安全性,还有效降低了边缘服务器与用户之间的通信成本。最后,每个用户将其本地生成器生成的伪数据发送到边缘服务器,由边缘服务器处理伪数据并对内容的流行趋势做出预测,从而缓存最热门的内容。在这个过程中,服务器收到的仅是伪数据,而伪数据不仅不会暴露用户对内容的偏好或活跃度水平,反而有效地反映了在整个用户组中内容的流行趋势,从而在不泄漏用户隐私的前提下,实现了一个高缓存命中率的高效算法。因此,本发明是一种既安全又高效的联邦学习内容缓存算法,在准确预测内容流行趋势并缓存的同时,有效地保护了每个用户的隐私,在实际通信系统中具有较高的可行性。本发明由国家自然科学基金资助项目(no.61701071)支持。
技术实现要素:
在内容缓存策略中,不仅需要实现高效的算法和高缓存命中率,而且需要保护用户的隐私,例如用户的私有数据、对内容的偏好、活跃度水平等。针对上述问题,本发明提出了一种安全且高效的联邦学习主动内容缓存方法,不但可以通过准确地预测内容的流行趋势来缓存热门内容,还可以有效地保护每个用户的隐私和模型梯度,同时降低边缘服务器与用户之间的通信成本。
为了达到上述目的,本发明采用的技术方案如下:
一种安全且高效的联邦学习内容缓存方法,包含以下四个内容:
第一,每个用户从边缘服务器下载鉴别器共享模型和生成器共享模型,基于共享模型利用私有数据在本地训练wgan鉴别器本地模型和wgan生成器本地模型。另外,用户在本地进行梯度裁剪与模型修正,以实现梯度级隐私保护并降低通信成本。
第二,每个用户将修正后的模型更新发送至边缘服务器,由边缘服务器聚合生成新的共享模型并发送给每个用户,以供下次训练。
第三,重复前两个内容中的训练方法,直到模型训练完毕。
第四,每个用户把本地生成器生成的伪数据发送到边缘服务器,由边缘服务器预测内容的流行趋势并对内容的流行程度评分,最后做出缓存决策。
下面将分步做详细说明。
步骤一:信息收集与模型建立
步骤1.1收集信息:根据来源不同,边缘服务器基站收集信息的过程主要包括两个方面:
1)边缘服务器基站通过网络侧获取的内容库信息,其中包括内容项目的总数、用来响应用户访问请求的内容、用于缓存的内容等。
2)边缘服务器通过用户侧获取的信息,其中包括已连接的用户列表、用户总数等。
步骤1.2模型建立
在边缘服务器基站中建立两个共享的全局模型:鉴别器共享模型和生成器共享模型。对于鉴别器共享模型,首先根据内容库的相关信息确定它的输入层,然后设计它的结构,其中包括模型层数、每层节点个数、模型的激活函数等,最后建立输出层完成回归任务,拟合wasserstein距离。对于生成器共享模型,根据输入噪声的维度确定它的输入层,然后设计它的结构,其中包括模型层数、每层节点个数、模型的激活函数等,最后根据内容库的相关信息确定它的输出层,以生成伪数据。共享模型建立以后,均匀初始化所有的模型参数,至此两个共享的全局模型被成功建立。
步骤二:本地模型的训练过程
步骤2.1下载共享模型
参与训练的用户首先在边缘服务器基站下载鉴别器共享模型和生成器共享模型,然后创建本地鉴别器模型和本地生成器模型,本地模型的结构与共享模型的结构相同。
步骤2.2训练本地鉴别器
生成对抗网络中鉴别器的目标是把生成器生成的伪数据与真实的数据分辨出来。在wgan中,wasserstein距离是平滑的,它的优越性在于可以反映两个没有重叠的分布的距离,因此可以提供有意义的梯度。为此,我们需要使用wgan中的鉴别器来拟合wasserstein距离,达到分辨真伪数据的目标,即最小化:
其中fw为用户的本地鉴别器,pr是真实的数据分布,pg是本地生成器生成的伪数据分布。为了最小化ld,采用有效的梯度更新方法均方根传递(rootmeansquareprop,rmsprop)。它对模型权重的梯度使用了微分平方加权平均数,从而加快了模型的收敛速度。具体地,在第t轮的训练过程中,积累的梯度动量mwt、mbt为:
mwt=β·mw(t-1)+(1-β)·dw2
mbt=β·mb(t-1)+(1-β)·db2
其中β表示梯度积累指数,dw2和db2表示模型参数w和b微分的平方。获得积累的梯度动量之后,就可以根据它来更新模型参数。
但是在更新模型参数之前,为了保证模型梯度的安全性,需要对梯度进行裁剪。为此,我们只选择贡献大的梯度进行更新,即梯度值的大小在当前层全部梯度的前a%才会被更新,其中a%∈(0,1)为预设的梯度裁剪系数。对于没有参与更新的小梯度,将它们保存起来,并在下次训练时加回对应的梯度中,而不是舍弃它们,目的是为了防止丢失大量的梯度信息。随着训练的进行,小梯度每次都被累加,直到成为前a%的梯度,然后更新至模型参数中。例如,若模型的层数为l1,l2,…,ln,对于第li层的来说,这一层中所有参数的梯度共有ni个,我们只取出最大的前ki=ni·a%个参数用于模型更新,其余的梯度在用户本地保存起来,下次训练时重新加到第li层的对应梯度上进行训练。若ki不是整数,则向上取整。这样用于更新的梯度就从100%下降到了a%,即梯度裁剪。
然后,用裁剪后的梯度来更新模型参数w,b,第t轮的更新过程为:
其中η为学习率,为了防止分母为0,加入了一个小常数ε进行平滑,用于数值稳定。
最后,为了满足wasserstein距离的lipschitz连续性条件,需要保证||fw||l≤k,其中k为常数,这就要限定模型的所有参数不超过某个范围[-c,c],其中c为常数,也可以说是限定模型梯度不超过某个范围。为此,我们将模型参数的范围修正到[-c,c],对于小于此范围的值直接取-c,对于大于此范围的值直接取c,以满足lipschitz连续性条件,即模型修正。
梯度裁剪与模型修正可以有效地保护用户私有数据,同时降低了用户与边缘服务器之间的通信成本。至此,完成了本地鉴别器的一轮训练。
步骤2.3训练本地生成器
生成对抗网络中生成器的目标是尽量生成真实的数据来欺骗鉴别器。在wgan中,由于wasserstein距离总是能提供有意义的梯度,因此生成器的梯度不会消失。考虑到生成器的输入与真实的数据分布无关,因此,若想生成真假难辨的数据,只需最小化:
其中fw为用户的本地鉴别器,pg是本地生成器生成的伪数据分布。为了最小化lg,同样采用rmsprop的梯度更新方法。它对模型权重的梯度使用了微分平方加权平均数,修正了梯度的摆动幅度,使模型快速收敛。具体地,在第t轮的训练过程中,积累的梯度动量mwt、mbt为:
mwt=β·mw(t-1)+(1-β)·dw2
mbt=β·mb(t-1)+(1-β)·db2
其中β表示梯度积累指数,dw2和db2表示模型参数w和b微分的平方。由此可以得到积累的梯度动量,然后根据它来更新模型参数。
但是在更新模型参数之前,为了保证较低的通信成本,同时抵御未知的风险,即使生成器的输入为随机噪声,也需要对梯度进行裁剪。为此,我们只选择贡献大的梯度进行更新,即梯度值的大小在当前层全部梯度的前a%才会被更新,其中a%∈(0,1)为预设的梯度裁剪系数。对于没有参与更新的小梯度,将它们保存起来,并在下次训练时加回对应的梯度中,而不是舍弃它们,目的是为了防止丢失大量的梯度信息。随着训练的进行,小梯度每次都被累加,直到成为前a%的梯度,然后更新至模型参数中。例如,若模型的层数为l1,l2,…,ln,对于第li层的来说,这一层中所有参数的梯度共有ni个,我们只取出最大的前ki=ni·a%个参数用于模型更新,其余的梯度在用户本地保存起来,下次训练时重新加到第li层的对应梯度上进行训练。若ki不是整数,则向上取整。这样用于更新的梯度就从100%下降到了a%,即梯度裁剪。
然后,用裁剪后的梯度来更新模型参数w,b,第t轮的更新过程为:
其中η为学习率,为了防止分母为0,加入了一个小常数ε进行平滑,用于数值稳定。
最后,为了满足wasserstein距离的lipschitz连续性条件,需要保证||fw||l≤k,其中k为常数,这就要限定模型的所有参数不超过某个范围[-c,c],其中c为常数,也可以说是限定模型梯度不超过某个范围。为此,我们将模型参数的范围修正到[-c,c],对于小于此范围的值直接取-c,对于大于此范围的值直接取c,以满足lipschitz连续性条件,即模型修正。
梯度裁剪与模型修正可以有效地保护用户私有数据,同时降低了用户与边缘服务器之间的通信成本。至此,完成了本地生成器的一轮训练。
步骤三:共享模型的聚合过程
步骤3.1上传模型更新
每个参与训练的用户首先上传本地鉴别器和本地生成器模型的更新,边缘服务器才能分别生成新的鉴别器共享模型和生成器共享模型。用户在第t轮的训练过程中,上传的本地模型更新为:
其中n为用户的索引,
步骤3.2生成共享模型
边缘服务器对获取到的所有本地模型更新进行处理,基于联邦平均,分别聚合生成两个新的共享模型,即鉴别器共享模型和生成器共享模型。首先,分别聚合两类本地模型更新,第t轮训练中聚合的共享模型更新为:
其中hdt为共享的鉴别器模型更新,hgt为共享的生成器模型更新,nt为参与训练的用户数量。然后,把模型更新分别累加到新的共享模型中,从而生成新的共享模型:
wd(t+1)=wdt+ηdthdt
wg(t+1)=wgt+ηgthgt
其中wd(t+1)为新的鉴别器共享模型,wg(t+1)为新的生成器共享模型,ηdt和ηgt分别为聚合鉴别器与生成器时使用的学习率。至此,就得到了新的鉴别器共享模型和生成器共享模型,可以将它们用于下一轮的训练过程。
步骤四:预测内容的流行趋势
步骤4.1完成模型训练
重复步骤二与步骤三中的本地模型训练过程和共享模型聚合过程,直到训练轮数达到预设值或模型精度趋于不变。
步骤4.2获取伪数据
在训练结束以后,每个用户将本地生成器生成的伪数据发送至边缘服务器,伪数据是与真实数据维度相同但内容不同的数据,即:
其中n为用户的索引,dn为第n个用户的本地生成器生成的伪数据,
步骤4.3内容流行趋势预测
边缘服务器根据伪数据dn,对内容的流行趋势做出预测,并按照流行度进行排序。
首先,把n个伪数据按维度对应相加,以得到反映内容全局流行趋势的总体得分d,公式如下:
其中n为提供伪数据的用户总数。然后根据d中内容得分的大小预测内容的流行趋势,得分越大则内容越可能流行,因此可以根据内容得分的高低对内容进行降序排序。
步骤4.4缓存流行内容
最后,考虑边缘服务器基站的缓存能力,选出d中得分最高的前m个内容名单,从因特网下载这些内容到边缘服务器基站的缓存实体中,以实现用户快速高效的访问请求。
本发明的有益效果为:本发明所提出的安全且高效的联邦学习主动内容缓存方法具有两个优点,即安全和高效。从安全的角度来看,本发明有效保护了用户的隐私,其中包括用户的私有数据、对内容的偏好、活跃度水平,训练过程中的模型梯度也被很好的保护,防止了用户的私有数据泄露。从高效的角度来看,本发明能准确预测内容的流行趋势,从而实现高缓存命中率。另外,在模型更新传输前进行梯度裁剪和模型修正,大大降低了服务器与用户之间的通信成本,从而实现高效的通信。因此,本发明是一种既安全又高效的联邦学习主动内容缓存方法。
附图说明
图1是本发明的系统结构示意图。
图2是本发明的用户侧工作流程图。
图3是本发明的边缘服务器侧工作流程图。
图4是本发明与其他参考算法在缓存命中率方面的比较。
具体实施方式
以下结合具体实施例对本发明作进一步说明。
以movielens100k数据集作为实例来说明本发明的具体实施方式,此数据集由grouplens团队创建,是经常被用于评价内容缓存方法的经典数据集。在数据集中由943个用户评价1682部电影,包含了10万条评分。我们用电影来代表用户请求的内容,用评分来代表用户对内容的偏好。这通常是合理的,因为用户总是看完电影才会进行评分。在此数据集中,本发明的目标是在保护用户隐私的前提下,预测电影的流行趋势,并提前把流行电影缓存到边缘服务器基站中。
一种安全且高效的联邦学习内容缓存方法,包含以下内容:
步骤一:信息收集与模型建立
步骤1.1收集信息:根据来源不同,边缘服务器基站收集信息的过程主要包括两个方面:
1)边缘服务器基站通过网络侧获取的内容库信息。在本例中内容库为movielens100k电影数据库,其中包括电影的总数、上下文信息、电影具体的内容等。
2)边缘服务器通过用户侧获取的信息,在本例中包括movielens100k中已观看电影的用户列表、已连接边缘服务器的用户总数等。
步骤1.2模型建立
基于本例的movielens100k数据集,在边缘服务器基站中建立两个共享的全局模型:鉴别器共享模型和生成器共享模型。对于鉴别器共享模型,首先根据电影库中电影的总数和评分范围确定它的输入层,在此电影的总数为1682,评分的范围为0-5。然后设计它的结构,其中包括模型层数、每层节点个数、模型的激活函数等,最后建立输出层完成回归任务,拟合wasserstein距离。对于生成器共享模型,根据输入噪声的维度确定它的输入层,然后设计它的结构,其中包括模型层数、每层节点个数、模型的激活函数等,最后根据电影库中电影的总数和评分范围确定它的输出层,以生成伪数据。共享模型建立以后,均匀初始化所有的模型参数,至此两个共享的全局模型被成功建立。
步骤二:本地模型的训练过程
步骤2.1下载共享模型
本例中参与训练的943个用户首先在边缘服务器基站下载鉴别器共享模型和生成器共享模型,然后创建本地鉴别器模型和本地生成器模型,本地模型的结构与共享模型的结构相同。
步骤2.2训练本地鉴别器
生成对抗网络中鉴别器的目标是把生成器生成的伪数据与真实的数据分辨出来。在本例中,每个用户都使用本地鉴别器来拟合wasserstein距离,达到分辨真伪数据的目标,即最小化:
其中,fw为用户的本地鉴别器,pr是真实的数据分布,pg是本地生成器生成的伪数据分布。为了最小化ld,采用有效的梯度更新方法均方根传递(rootmeansquareprop,rmsprop)。它对模型权重的梯度使用了微分平方加权平均数,从而加快了模型的收敛速度。具体地,在第t轮的训练过程中,积累的梯度动量mwt、mbt为:
mwt=β·mw(t-1)+(1-β)·dw2
mbt=β·mb(t-1)+(1-β)·db2
其中,β表示梯度积累指数,dw2和db2表示模型参数w和b微分的平方。获得积累的梯度动量之后,就可以根据它来更新模型参数。
但是在更新模型参数之前,为了保证模型梯度的安全性,需要对梯度进行裁剪。为此,我们只选择贡献大的梯度进行更新,即梯度值的大小在当前层全部梯度的前a%才会被更新,其中a%∈(0,1)为预设的梯度裁剪系数,在本例中把a%设为20%。对于没有参与更新的小梯度,将它们保存起来,并在下次训练时加回对应的梯度中,而不是舍弃它们,目的是为了防止丢失大量的梯度信息。随着训练的进行,小梯度每次都被累加,直到成为前20%的梯度,然后更新至模型参数中。这样用于更新的梯度就从100%下降到了20%,即梯度裁剪。
然后,用裁剪后的梯度来更新模型参数w,b,第t轮的更新过程为:
其中η为学习率,在本例中设为0.015,为了防止分母为0,加入了一个小常数ε进行平滑,用于数值稳定。
最后,为了满足wasserstein距离的lipschitz连续性条件,需要保证||fw||l≤k,其中k为常数,这就要限定模型的所有参数不超过某个范围[-c,c],其中c为常数,也可以说是限定模型梯度不超过某个范围。为此,在本例中我们将模型参数的范围修正到[-0.1,0.1],对于小于此范围的值直接取-0.1,对于大于此范围的值直接取0.1,以满足lipschitz连续性条件,即模型修正。
梯度裁剪与模型修正可以有效地保护用户私有数据,同时降低了用户与边缘服务器之间的通信成本。至此,完成了本地鉴别器的一轮训练。
步骤2.3训练本地生成器
生成对抗网络中生成器的目标是尽量生成真实的数据来欺骗鉴别器。在本例中,每个用户在其本地训练生成器模型,从而生成真假难辨的数据,在此只需最小化:
其中,fw为用户的本地鉴别器,pg是本地生成器生成的伪数据分布。为了最小化lg,同样采用rmsprop的梯度更新方法。它对模型权重的梯度使用了微分平方加权平均数,修正了梯度的摆动幅度,使模型快速收敛。具体地,在第t轮的训练过程中,积累的梯度动量mwt、mbt为:
mwt=β·mw(t-1)+(1-β)·dw2
mbt=β·mb(t-1)+(1-β)·db2
其中β表示梯度积累指数,dw2和db2表示模型参数w和b微分的平方。由此可以得到积累的梯度动量,然后根据它来更新模型参数。
但是在更新模型参数之前,为了保证较低的通信成本,同时抵御未知的风险,即使生成器的输入为随机噪声,也需要对梯度进行裁剪。为此,我们只选择贡献大的梯度进行更新,即梯度值的大小在当前层全部梯度的前a%才会被更新,其中a%∈(0,1)为预设的梯度裁剪系数,在本例中把a%设为20%。对于没有参与更新的小梯度,将它们保存起来,并在下次训练时加回对应的梯度中,而不是舍弃它们,目的是为了防止丢失大量的梯度信息。随着训练的进行,小梯度每次都被累加,直到成为前20%的梯度,然后更新至模型参数中。这样用于更新的梯度就从100%下降到了20%,即梯度裁剪。
然后,用裁剪后的梯度来更新模型参数w,b,第t轮的更新过程为:
其中η为学习率,在本例中设为0.03,为了防止分母为0,加入了一个小常数ε进行平滑,用于数值稳定。
最后,为了满足wasserstein距离的lipschitz连续性条件,需要保证||fw||l≤k,其中k为常数,这就要限定模型的所有参数不超过某个范围[-c,c],其中c为常数,也可以说是限定模型梯度不超过某个范围。为此,在本例中我们将模型参数的范围修正到[-0.1,0.1],对于小于此范围的值直接取-0.1,对于大于此范围的值直接取0.1,以满足lipschitz连续性条件,即模型修正。
梯度裁剪与模型修正可以有效地保护用户私有数据,同时降低了用户与边缘服务器之间的通信成本。至此,完成了本地生成器的一轮训练。
步骤三:共享模型的聚合过程
步骤3.1上传模型更新
在本例中每个参与训练的用户首先上传本地鉴别器和本地生成器模型的更新,边缘服务器才能分别生成新的鉴别器共享模型和生成器共享模型。用户在第t轮的训练过程中,上传的本地模型更新为:
其中n为用户的索引,
步骤3.2生成共享模型
边缘服务器对获取到的所有本地模型更新进行处理,基于联邦平均,分别聚合生成两个新的共享模型,即鉴别器共享模型和生成器共享模型。首先,分别聚合两类本地模型更新,第t轮训练中聚合的共享模型更新为:
其中hdt为共享的鉴别器模型更新,hgt为共享的生成器模型更新,nt为参与训练的用户数量。然后,把模型更新分别累加到新的共享模型中,从而生成新的共享模型:
wd(t+1)=wdt+ηdthdt
wg(t+1)=wgt+ηgthgt
其中wd(t+1)为新的鉴别器共享模型,wg(t+1)为新的生成器共享模型,ηdt和ηgt分别为聚合鉴别器与生成器时使用的学习率,在本例中均使用1作为它们的值。至此,就得到了新的鉴别器共享模型和生成器共享模型,可以将它们用于下一轮的训练过程。
步骤四:预测内容的流行趋势
步骤4.1完成模型训练
重复步骤二与步骤三中的本地模型训练过程和共享模型聚合过程,直到训练轮数达到预设值或模型精度趋于不变。在本例中,训练轮数被预设为50次。
步骤4.2获取伪数据
在训练结束以后,每个用户将本地生成器生成的伪数据发送至边缘服务器。在本例中每个用户都生成一条伪数据,共有943条伪数据。伪数据是与真实数据维度相同但内容不同的数据,即:
其中n为用户的索引,dn为第n个用户的本地生成器生成的伪数据,
步骤4.3内容流行趋势预测
在本例中,边缘服务器根据943条伪数据dn,对内容的流行趋势做出预测,并按照流行度进行排序。
首先,把943条伪数据按维度对应相加,以得到反映内容全局流行趋势的总体得分d,公式如下:
其中n为提供伪数据的用户总数,在本例中为943。然后根据d中内容得分的大小预测内容的流行趋势,得分越大则内容越可能流行,因此可以根据内容得分的高低对内容的流行趋势进行降序排序。
步骤4.4缓存流行内容
最后,考虑边缘服务器基站的缓存能力,选出d中得分最高的前m个电影名单,从因特网电影库中下载这些电影到边缘服务器基站的缓存实体中,以实现用户快速高效的访问请求。在本例中考虑到movielens100k数据集的电影库大小,把m的取值设定在50至400之间,这是一个通常且合理的范围。
在本例中使用缓存命中率来度量模型的缓存性能,对模型进行2万次访问请求测试。当用户发出访问请求时,如果边缘服务器基站的缓存实体中存在用户想要访问的电影,则将它从基站中直接发送给用户,称为缓存成功。否则,如果边缘服务器基站的缓存实体中不存在用户想要访问的电影,则将会通过互联网下载该电影,称为缓存失败。缓存命中率是缓存成功的数量占总访问数量的比值,即:
其中,ns是缓存成功的次数,nf是缓存失败的次数。在本例中梯度裁剪率a%设置为20%,即每次训练只更新20%的梯度。
我们比较了本发明与其他算法的缓存命中率:例如理想算法oracle作为缓存命中率的上界、m-∈-greedy算法、随机算法、以及基于联邦学习和混合过滤的算法fpcc(参见文献:z.yu,j.hu,g.min,h.lu,z.zhao,h.wang,andn.georgalas,“federatedlearningbasedproactivecontentcachinginedgecomputing,”in2018ieeeglobalcommunicationsconference(globecom),2018,pp.1–6.)。各个算法的缓存命中率如图4所示,可以看出本发明提出的算法与理想算法oracle十分接近,优于其他全部参考算法。这说明本发明提出的算法可以实现高缓存命中率,能有效利用边缘服务器的缓存能力,是一种高效的主动内容缓存算法。
另外,在本例中将本发明对用户隐私的安全保护与其他算法做比较:
1)与使用强化学习的方法(参见文献:n.zhang,k.zhengandm.tao,"usinggroupedlinearpredictionandacceleratedreinforcementlearningforonlinecontentcaching,"in2018ieeeinternationalconferenceoncommunicationsworkshops(iccworkshops),pp.1-6,2018),协同过滤的方法(参见文献:e.bastug,m.bennis,andm.debbah,“livingontheedge:theroleofproactivecachingin5gwirelessnetworks,”ieeecommunicationsmagazine,vol.52,no.8,pp.82–89,2014.),线性回归的方法(参见文献:k.n.doan,t.vannguyen,t.q.s.quekandh.shin,"content-awareproactivecachingforbackhauloffloadingincellularnetwork,"inieeetransactionsonwirelesscommunications,vol.17,no.5,pp.3128-3140,may2018.)相比,本发明保证了用户的私有数据只保存在本地进行训练。
2)更进一步,与雾无线接入网中的联邦学习方法(参见文献:y.wu,y.jiang,m.bennis,f.zheng,x.gaoandx.you,"contentpopularitypredictioninfogradioaccessnetworks:afederatedlearningbasedapproach,"icc2020-2020ieeeinternationalconferenceoncommunications(icc),2020,pp.1-6.)、自动编码器与混合过滤的方法(参见文献:z.yu,j.hu,g.min,h.lu,z.zhao,h.wang,andn.georgalas,“federatedlearningbasedproactivecontentcachinginedgecomputing,”in2018ieeeglobalcommunicationsconference(globecom),2018,pp.1–6.)、神经网络来预测加权流行度的方法(参见文献:k.qiandc.yang,"popularitypredictionwithfederatedlearningforproactivecachingatwirelessedge,"in2020ieeewirelesscommunicationsandnetworkingconference(wcnc),2020,pp.1-6.)相比,本发明保证了单个用户对内容的偏好以及活跃度水平不会泄露。
3)最后,本发明每次训练时在用户本地进行梯度裁剪和模型压缩,实现了用户梯度级的隐私保护,即用户本地模型参数和梯度中不会暴露用户的私有数据。
基于以上三点,本发明是一种安全的主动内容缓存方法,可以有效地保护用户隐私,防止数据泄露。
综上所述,本发明所提出的算法是一种既高效又安全的联邦学习主动内容缓存方法。所提出的方法可以准确地预测内容的流行趋势,并在边缘服务器中缓存流行内容达到高缓存命中率,同时,梯度裁剪和模型修正降低了传输时的通信成本,这均体现了方法的高效性。另外,所提出的方法可以有效保护每个用户的隐私,在防止私有数据和行为数据泄露的同时达到了梯度级的隐私保护,体现了方法的安全性。
以上所述实施例仅表达本发明的实施方式,但并不能因此而理解为对本发明专利的范围的限制,应当指出,对于本领域的技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些均属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!