一种面向不平衡财务文本数据的风险预警方法及系统
1.本公开涉及文本数据处理技术领域,特别涉及一种面向不平衡财务文本数据的风险预警方法及系统。
背景技术:
2.本部分的陈述仅仅是提供了与本公开相关的背景技术,并不必然构成现有技术。
3.不同行业、不同规模的上市公司数量不断增加,然而近年来屡屡出现上市公司的财务数据造假和暴雷,甚至还出现了流动性危机及信用债违约等问题。面对上市公司多年的财务数据报告,专业投资者的任务就是考虑诸多相关因素,对数据指标进行筛选跟踪分析研究,判断上市公司财务数据是否稳定,识别真实性,避免投资踩雷。
4.发明人发现,现今普遍流行的财务数据风险预警方法是聘用经验丰富的会计对财务文本数据进行人工分析,但这种方法需要耗费大量的人力、物力、财力,准确性较差,且有一定滞后性;而且,针对财务系统的文本数据除表述方式存在差异性,在进行相应的大数据分析和处理时存在较大的误差。
技术实现要素:
5.为了解决现有技术的不足,本公开提供了一种面向不平衡财务文本数据的风险预警方法及系统,直接对获取的财务文本数据进行处理,实现了高效和准确的财务风险预警。
6.为了实现上述目的,本公开采用如下技术方案:
7.本公开第一方面提供了一种面向不平衡财务文本数据的风险预警方法。
8.一种面向不平衡财务文本数据的风险预警方法,包括以下过程:
9.获取待处理的财务文本数据;
10.根据获取的财务文本数据和预设评估模型,财务文本数据真实性评估结果;
11.根据真实性评估结果与预设阈值的对比,进行财务数据的风险预警;
12.其中,预设预测模型的训练过程中,对不平衡财务文本数据进行插值处理以使得正负样本数据的差异在预设范围内。
13.进一步的,预设预测模型的训练过程中,对不平衡财务文本数据进行筛选,包括以下过程:
14.根据获取的财务文本数据得到财务文本数据中的特征数据,当某个特征缺失的样本数量占比大于第一阈值时,将该特征舍弃;当某个特征缺失的样本数量占比在第二阈值与第一阈值之间时,将该特征对应的数据全部用均值填补;当某个特征数据缺失的样本数量占比小于第二阈值时,将该特征对应的数据用随机森林算法填补。
15.进一步的,用随机森林算法填补,包括以下过程:
16.选择数据的中位数或众数作为当前的估计值;
17.使用填补后的数据集训练随机森林模型,记录每一组数据在决策树中的分类路径;
18.建立一个相似度矩阵,根据分类路径计算数据之间的相似度,用相似度矩阵加权求均值作为新的估计值;
19.迭代预设次数后,得到最后的估计值。
20.进一步的,对不平衡财务文本数据进行插值处理,包括以下过程:
21.对于少数类中一个样本a,以欧氏距离为标准,计算它到少数类样本集中所有样本的距离,得到它的k个近邻;
22.对于少数类样本a,从其k近邻中随机选择一个样本b;
23.对于选出的近邻b,生成一个0到1之间的随机数ζ,合成一个新样本c;其中,合成公式为:c=a+ζ
·
|b
‑
a|;
24.重复进行上述步骤,直到正负样本数量差异在预设范围内。
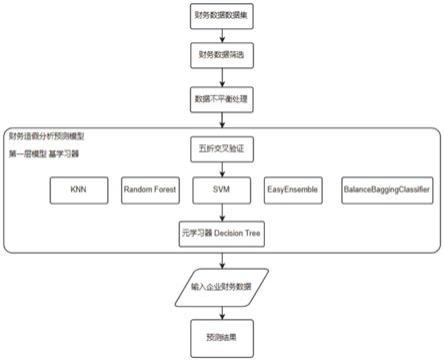
25.进一步的,预设预测模型,包括两层,第一层选择k近邻算法、随机森林、支持向量机、easy ensemble和balanced bagging classifier这5个基本分类器作为基学习器,第二层采用简单模型决策树作为元学习器。
26.更进一步的,对每个基学习器进行五折交叉验证,每次交叉验证对训练集测试数据进行预测得到结果a,对测试集数据进行预测得到结果b,将a按行合并得到该基学习器对训练集的预测结果a,将b按列相加取平均得到该基学习器对测试集的预测结果b,按列合并所有的a作为第二层模型的训练集数据,按列合并所有的b作为第二层模型的测试集数据,并以原始集的标签作为新生成数据集的标签。
27.进一步的,预设预测模型的训练过程,包括:
28.将筛选后的文本数据按预设比例划分为训练集和测试集;
29.将训练集不重复抽样随机分为多份;
30.挑选其中一份作为测试数据,剩余作为训练数据用于训练第一层模型的基学习器;
31.对于第一层模型中的基学习器,k近邻算法和随机森林模型在训练前进行不平衡数据处理,支持向量机、easy ensemble和balanced bagging classifier通过设置相应参数自适应样本不平衡;
32.重复上述步骤,使得每个子集都有一次循环作为测试数据,其余循环作为训练数据;
33.将每个循环中每个训练好的基学习器对测试数据的测试结果合并,得到该基学习器对整个训练集的预测值,再将各个基学习器得到的预测值按列合并,作为第二层模型的训练集,其真实值仍为原训练集的真实值;
34.将每个循环中每个训练好的基学习器对测试集的测试结果按列相加取均值,得到该基学习器对测试集的预测值,再将各个基学习器得到的预测值按列合并,作为第二层模型的测试集,其真实值仍为原测试集的真实值;
35.用得到的训练集对第二层模型进行训练,用得到的测试集进行测试。
36.本公开第二方面提供了一种面向不平衡财务文本数据的风险预警系统。
37.一种面向不平衡财务文本数据的风险预警系统,包括:
38.数据获取模块,被配置为:获取待处理的财务文本数据;
39.真实性评估模块,被配置为:根据获取的财务文本数据和预设评估模型,财务文本
数据真实性评估结果;
40.风险预警模块,被配置为:根据真实性评估结果与预设阈值的对比,进行财务数据的风险预警;
41.其中,预设预测模型的训练过程中,对不平衡财务文本数据进行插值处理以使得正负样本数据的差异在预设范围内。
42.本公开第三方面提供了一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时实现如本公开第一方面所述的面向不平衡财务文本数据的风险预警方法中的步骤。
43.本公开第四方面提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的程序,所述处理器执行所述程序时实现如本公开第一方面所述的面向不平衡财务文本数据的风险预警方法中的步骤。
44.与现有技术相比,本公开的有益效果是:
45.本公开所述的方法、系统、介质或电子设备,采用大量企业财务文本数据,通过财务数据筛选、数据不平衡处理和预测模型融合,得到评估模型,再将待检测的财务文本数据输入到评估模型中,根据评估结果与预设阈值的对比,进行财务数据的风险预警,实现了财务数据造假高效、专业、自动化的分析判断。
46.本公开附加方面的优点将在下面的描述中部分给出,部分将从下面的描述中变得明显,或通过本公开的实践了解到。
附图说明
47.构成本公开的一部分的说明书附图用来提供对本公开的进一步理解,本公开的示意性实施例及其说明用于解释本公开,并不构成对本公开的不当限定。
48.图1为本公开实施例1提供的财务文本数据风险预警模型的roc曲线。
49.图2为本公开实施例1提供的stacking中五折交叉验证过程示意图。
50.图3为本公开实施例1提供的基于stacking集成学习的财务文本数据风险预警模型构造过程示意图。
具体实施方式
51.下面结合附图与实施例对本公开作进一步说明。
52.应该指出,以下详细说明都是示例性的,旨在对本公开提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本公开所属技术领域的普通技术人员通常理解的相同含义。
53.需要注意的是,这里所使用的术语仅是为了描述具体实施方式,而非意图限制根据本公开的示例性实施方式。如在这里所使用的,除非上下文另外明确指出,否则单数形式也意图包括复数形式,此外,还应当理解的是,当在本说明书中使用术语“包含”和/或“包括”时,其指明存在特征、步骤、操作、器件、组件和/或它们的组合。
54.在不冲突的情况下,本公开中的实施例及实施例中的特征可以相互组合。
55.实施例1:
56.如图1
‑
3所示,本公开实施例1提供了一种面向不平衡财务文本数据的风险预警方
法,包括以下过程:
57.获取待处理的财务文本数据;
58.根据获取的财务文本数据和预设评估模型,财务文本数据真实性评估结果;
59.根据真实性评估结果与预设阈值的对比,进行财务数据的风险预警。
60.预设评估模型的训练,包括以下过程:
61.s1:财务文本数据筛选;
62.s2:数据不平衡处理;
63.s3:预测模型融合。
64.s1中,对于获得的企业财务数据,进行特征提取,得到各项指标数据特征因子,当特征数据缺失的企业样本数量占比大于50%时,将该特征因子舍弃;当特征数据缺失的企业样本数量占比在25%至50%时,将该特征因子对应的企业数据全部用均值填补;当特征数据缺失的企业样本数量占比小于25%时,将该特征因子对应的企业数据用随机森林算法填补。
65.其中,随机森林算法(random forest)是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,对于分类问题来说,每棵决策树都是一个分类器,对一个输入样本,n棵树会有n个分类结果,而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,是一种简单的bagging思想。
66.用随机森林算法填补缺失值的基本步骤为:
67.1)选择其余数据的中位数或众数作为当前的估计值;
68.2)使用填补后的数据集训练随机森林模型,记录每一组数据在决策树中的分类路径;
69.3)建立一个相似度矩阵,根据分类路径计算数据之间的相似度,用相似度矩阵加权求均值作为新的估计值;
70.4)迭代4~6次,得到稳定的估计值。
71.s2中,规定财务文本数据存在风险的样本为正样本,因财务文本数据存在风险的企业数量远远小于不存在风险的企业数量,故正样本为少数类,且正负样本比例悬殊,所以我们要对数据进行插值处理,使正负样本数据维持在合理的比例。
72.处理的具体步骤为:
73.1)对于少数类中一个样本a,以欧氏距离为标准,计算它到少数类样本集中所有样本的距离,得到它的k个近邻;其中,欧氏距离计算公式为:
[0074][0075]
2)对于少数类样本a,从其k近邻中随机选择一个样本b;
[0076]
3)对于选出的近邻b,再生成一个0到1之间的随机数ζ,从而合成一个新样本c;其中,合成公式为:
[0077]
c=a+ζ
·
|b
‑
a|。
[0078]
4)重复进行上述步骤,直到正负样本数量相近。
[0079]
s3中,使用stacking树行计算方法进行集成学习构造财务文本数据风险预警模型,模型分为两层,第一层选择k近邻算法(knn)、随机森林(random forest)、支持向量机
(svm)、easyensemble、balancedbaggingclassifier作为基学习器,第二层采用简单模型决策树(decision tree)作为元学习器。通过融合多个预测模型,增强系统的泛化能力,提高预测的准确性。
[0080]
具体步骤为:
[0081]
1)将经过财务数据筛选处理的数据集按7:3划分为训练集和测试集;
[0082]
2)将训练集不重复抽样随机分为5份;
[0083]
3)挑选其中一份作为测试数据,剩余4分作为训练数据用于训练第一层模型的基学习器;
[0084]
4)对于第一层模型中的基学习器,其中k近邻算法(knn)、随机森林(random forest)模型在训练前要通过数据不平衡处理对训练数据进行处理,支持向量机(svm)、easyensemble、balancedbaggingclassifier则通过设置相应参数自适应处理样本不平衡问题;
[0085]
5)重复第3
‑
4步5次,使得每个子集都有一次循环作为测试数据,其余循环作为训练数据;
[0086]
6)将每个循环中每个训练好的基学习器对测试数据的测试结果a按行合并,得到该基学习器对整个训练集的预测值a,再将各个基学习器得到的预测值a按列合并,作为第二层模型的训练集,其真实值仍为原训练集的真实值;
[0087]
7)将每个循环中每个训练好的基学习器对测试集的测试结果b按列相加取均值,得到该基学习器对测试集的预测值b,再将各个基学习器得到的预测值b按列合并,作为第二层模型的测试集,其真实值仍为原测试集的真实值;
[0088]
8)用第6步得到的训练集对第二层模型进行训练,并测试第7步得到的测试集,对构造好的财务文本数据风险预警模型进行评估。
[0089]
其中,k近邻算法(knn)是通过测量不同特征值之间的距离进行分类,思路是:如果一个样本在特征空间中的k个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中k通常是不大于20的整数。
[0090]
随机森林算法(random forest)是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,对于分类问题来说,每棵决策树都是一个分类器,对一个输入样本,n棵树会有n个分类结果,而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,是一种简单的bagging思想。
[0091]
支持向量机(svm)一种二分类模型,它的基本类型是定义在特征空间上的间隔最大的线性分类器,学习策略是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。
[0092]
easy ensemble是一种有效的不均衡数据分类方法,将多数类样本随机分成多个子集,每个子集分别与少数类合并,得到多个新的训练子集,并利用每个训练子集训练一个adaboost基分类器,最后集成所有基分类器,得到最终的分类器。
[0093]
balanced bagging classifier允许在训练每个基学习器之前对每个子集进行重抽样,结合了easy ensemble采样器与分类器(bagging classifier)。
[0094]
决策树(decision tree)是一种树形结构,常用于数据领域的分类和回归,在机器学习中,属于监督学习,是一种流行预测模型。对于复杂的预测问题,通过建立树模型产生
forest)模型在训练前要通过数据不平衡处理对训练数据进行处理,支持向量机(svm)、easy ensemble、balanced bagging classifier则通过设置相应参数自适应处理样本不平衡问题;
[0112]
5)重复第3
‑
4步5次,使得每个子集都有一次循环作为测试数据,其余循环作为训练数据;
[0113]
6)将每个循环中每个训练好的基学习器对测试数据的测试结果合并,得到该基学习器对整个训练集的预测值,再将各个基学习器得到的预测值按列合并,作为第二层模型的训练集,其真实值仍为原训练集的真实值;
[0114]
7)将每个循环中每个训练好的基学习器对测试集的测试结果按列相加取均值,得到该基学习器对测试集的预测值,再将各个基学习器得到的预测值按列合并,作为第二层模型的测试集,其真实值仍为原测试集的真实值;
[0115]
8)用步骤6)得到的训练集对第二层模型进行训练,并测试步骤7)得到的测试集,对构造好的财务文本数据风险预警模型进行评估。
[0116]
评估结果为:
[0117][0118]
实施例2:
[0119]
本公开实施例2提供了一种面向不平衡财务文本数据的风险预警系统,包括:
[0120]
数据获取模块,被配置为:获取待处理的财务文本数据;
[0121]
真实性评估模块,被配置为:根据获取的财务文本数据和预设评估模型,财务文本数据真实性评估结果;
[0122]
风险预警模块,被配置为:根据真实性评估结果与预设阈值的对比,进行财务数据的风险预警;
[0123]
其中,预设预测模型的训练过程中,对不平衡财务文本数据进行插值处理以使得正负样本数据的差异在预设范围内。
[0124]
实施例3:
[0125]
本公开实施例3提供了一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时实现如本公开实施例1所述的面向不平衡财务文本数据的风险预警方法中的步骤。
[0126]
实施例4:
[0127]
本公开实施例4提供了一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的程序,所述处理器执行所述程序时实现如本公开实施例1所述的面向不平衡财务文本数据的风险预警方法中的步骤。
[0128]
本领域内的技术人员应明白,本公开的实施例可提供为方法、系统、或计算机程序产品。因此,本公开可采用硬件实施例、软件实施例、或结合软件和硬件方面的实施例的形
式。而且,本公开可采用在一个或多个其中包含有计算机可用程序代码的计算机可用存储介质(包括但不限于磁盘存储器和光学存储器等)上实施的计算机程序产品的形式。
[0129]
本公开是参照根据本公开实施例的方法、设备(系统)、和计算机程序产品的流程图和/或方框图来描述的。应理解可由计算机程序指令实现流程图和/或方框图中的每一流程和/或方框、以及流程图和/或方框图中的流程和/或方框的结合。可提供这些计算机程序指令到通用计算机、专用计算机、嵌入式处理机或其他可编程数据处理设备的处理器以产生一个机器,使得通过计算机或其他可编程数据处理设备的处理器执行的指令产生用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的装置。
[0130]
这些计算机程序指令也可存储在能引导计算机或其他可编程数据处理设备以特定方式工作的计算机可读存储器中,使得存储在该计算机可读存储器中的指令产生包括指令装置的制造品,该指令装置实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能。
[0131]
这些计算机程序指令也可装载到计算机或其他可编程数据处理设备上,使得在计算机或其他可编程设备上执行一系列操作步骤以产生计算机实现的处理,从而在计算机或其他可编程设备上执行的指令提供用于实现在流程图一个流程或多个流程和/或方框图一个方框或多个方框中指定的功能的步骤。
[0132]
本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的程序可存储于一计算机可读取存储介质中,该程序在执行时,可包括如上述各方法的实施例的流程。其中,所述的存储介质可为磁碟、光盘、只读存储记忆体(read
‑
only memory,rom)或随机存储记忆体(random accessmemory,ram)等。
[0133]
以上所述仅为本公开的优选实施例而已,并不用于限制本公开,对于本领域的技术人员来说,本公开可以有各种更改和变化。凡在本公开的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本公开的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1