一种滑坡易发性评估方法、装置、设备及可读存储介质
1.本发明涉及地质灾害防治技术领域,尤其涉及一种滑坡易发性评估方法、装置、设备及可读存储介质。
背景技术:
2.滑坡易发性是指综合分析研究区地质和环境条件评估滑坡发生的可能性,滑坡易发性评估研究是地质灾害风险评价的首要环节,其成果可以为科学、经济地组织实施防灾减灾措施提供应用服务,
3.也可以为受地质灾害威胁的地区应急方案的制定提供科技支撑,还为基础设施等建设工程选址的适宜性及其空间布局的合理性评估提供决策参考,以及,为区域的中长期的建设规划提供科学依据。
4.滑坡易发性评估模型是揭示滑坡易发性致灾因子与样本之间潜在复杂联系的重要枢纽,根据具体区域特点考虑模型适用性也决定了模型的预测能力,因此滑坡易发性评估模型的选择是滑坡易发性评估流程中至关重要的环节。
5.在现有的模型方法中,基于物理的滑坡易发性评估模型需要大量详细的数据,然而对于大范围监测则难以收集数据,并且费事费力。启发式驱动模型是基于有限信息构建,通过专家意见和专业知识对滑坡致灾因子进行排序或加权来对其进行参数化,这种方法很难客观的量化或评估结果。而对于传统的浅层机器学习模型只有一个或零个隐藏层的浅层结构,存在训练时间有限、易陷入局部最优、收敛不稳定等缺点。
6.因此,挖掘到数据之间更深层的联系,以有效解决过拟合、收敛困难与过慢等问题的滑坡易发性评估方法是目前业界亟待解决的重要课题。
技术实现要素:
7.本发明提供一种滑坡易发性评估方法、装置、设备及可读存储介质,用以解决现有技术中滑坡易发性评估方法存在过拟合、收敛困难与过慢等问题的缺陷,实现深度学习模型在滑坡易发性等防灾减灾应用中的更多价值。
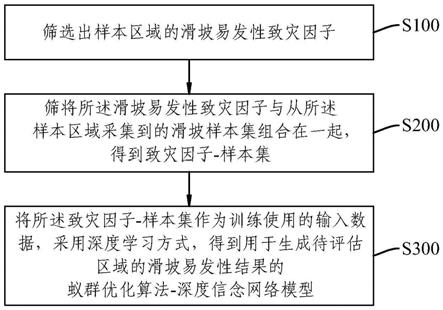
8.本发明提供一种滑坡易发性评估方法,包括以下步骤:
9.筛选出样本区域的滑坡易发性致灾因子;
10.将所述滑坡易发性致灾因子与从所述样本区域采集到的滑坡样本集组合在一起,得到致灾因子
‑
样本集;
11.将所述致灾因子
‑
样本集作为训练使用的输入数据,采用深度学习方式,得到用于生成待评估区域的滑坡易发性结果的蚁群优化算法
ꢀ‑
深度信念网络模型。
12.根据本发明提供的滑坡易发性评估方法,筛选出滑坡易发性致灾因子,具体包括以下步骤:
13.采集样本区域的滑坡信息;其中,所述滑坡信息包括遥感影像、卫星图像、基础地理、地质、地形地貌、气象水文、林地类型、土壤类型、历史滑坡灾害记录以及滑坡研究文献
资料;
14.利用皮尔逊相关系数和随机森林特征重要性排序,从所述滑坡信息筛选出滑坡信息对应的所述滑坡易发性致灾因子。
15.根据本发明提供的滑坡易发性评估方法,从所述样本区域采集到的滑坡样本集,具体包括以下步骤:
16.利用区域滑坡调查、基于卫星图像的目视解译以及基于遥感影像的智能识别,采集样本区域的滑坡样本集。
17.根据本发明提供的滑坡易发性评估方法,利用区域滑坡调查、基于卫星图像的目视解译以及基于遥感影像的智能识别,采集样本区域采集到的滑坡样本中将面状数据转化为点数据。
18.根据本发明提供的滑坡易发性评估方法,在蚁群优化算法
‑
深度信念网络模型的训练过程中使用启发式蚁群算法寻找最佳路径并不断迭代,以寻找蚁群优化算法
‑
深度信念网络模型的最佳组合以及最佳参数,直至迭代次数最大,得到组合以及参数最优的蚁群优化算法
ꢀ‑
深度信念网络模型。
19.根据本发明提供的滑坡易发性评估方法,蚁群优化算法
‑
深度信念网络模型的参数中,激活函数采用双曲正切函数,优化器采用自适应矩估计优化器,优化策略采用批标准化优化策略,使用岭回归权值衰减项正则化和早停法,损失函数采用交叉熵以及岭回归调整项。
20.根据本发明提供的滑坡易发性评估方法,蚁群优化算法
‑
深度信念网络模型的架构包括输入层、输出层以及位于所述所述输入层和所述输出层之间的四层受限玻尔兹曼机层,四层所述受限玻尔兹曼机层中的神经元个数自输入层向输出层逐级减小。
21.本发明还提供一种滑坡易发性评估装置,包括:
22.致灾因子筛选模块,用于筛选出样本区域的滑坡易发性致灾因子;
23.样本集建立模块,用于将所述滑坡易发性致灾因子与从所述样本区域采集到的滑坡样本集组合在一起,得到致灾因子
‑
样本集;
24.易发性评估模块,用于将所述致灾因子
‑
样本集作为训练使用的输入数据,采用深度学习方式,得到用于生成待评估区域的滑坡易发性结果的蚁群优化算法
‑
深度信念网络模型。
25.本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现如上述任一种所述滑坡易发性评估方法的步骤。
26.本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现如上述任一种所述滑坡易发性评估方法的步骤。
27.本发明提供的滑坡易发性评估方法、装置、设备及可读存储介质,通过将深度信念网络模型与蚁群优化算法相结合运用到滑坡易发性评估中,并通过蚁群优化算法优化深度信念网络模型的优化策略中组合以及参数来解决模型过拟合与收敛缓慢等问题,通过筛选出样本区域的滑坡易发性致灾因子,优选出弱相关特征的滑坡易发性致灾因子,以此来实现滑坡易发性致灾因子与样本之间更深层的联系,最终实现了深度学习模型在滑坡易发性等防灾减灾应用中的更多价值。
附图说明
28.为了更清楚地说明本发明或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作一简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
29.图1是本发明提供的滑坡易发性评估方法的流程示意图;
30.图2是本发明提供的滑坡易发性评估方法构建aco
‑
dbn模型时的流程示意图;
31.图3为本发明提供的滑坡易发性评估方法构建aco
‑
dbn模型时的时训练集和验证集准确率和损失随迭代轮数的变化趋势图;
32.图4是本发明提供的滑坡易发性评估方法中绘制的九寨沟滑坡地区易发性制图结果;
33.图5是本发明提供的滑坡易发性评估方法中aco
‑
dbn模型的构架图;
34.图6是本发明提供的滑坡易发性评估方法在验证阶段四种模型的roc曲线以及对应的auc值的曲线图;
35.图7是本发明提供的滑坡易发性评估方法中步骤s100具体的流程示意图;
36.图8是本发明提供的滑坡易发性评估装置的结构示意图;
37.图9是本发明提供的滑坡易发性评估装置中致灾因子筛选模块具体的结构示意图
38.图10是本发明提供的电子设备的结构示意图。
具体实施方式
39.为使本发明的目的、技术方案和优点更加清楚,下面将结合本发明中的附图,对本发明中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
40.滑坡易发性评估模型是揭示滑坡易发性致灾因子与样本之间潜在复杂联系的重要枢纽,根据具体区域特点考虑模型适用性也决定了模型的预测能力,因此滑坡易发性评估模型的选择是滑坡易发性评估流程中至关重要的环节。随着越来越多的滑坡易发性评估算法、模型、方法在滑坡易发性研究中得到成功运用,目前将滑坡易发性评估算法、模型、方法归为确定性和非确定性这两大类。其中属于确定性类别的通常基于滑坡发生的物理过程,如以浅层滑坡地形控制的物理模型、分布式斜坡稳定性模型(sinmap模型)、有限滑动位移法模型 (newmark模型)等,属于确定性类别的模型具有物理意义明确、预测精度高和反馈及时等优点,但对于大范围监测数据往往难以获取或成本过高。其中属于非确定性类别的可分为启发式方法如模糊逻辑法、层次分析法等,该类方法往往依赖于专家的经验知识,因此具有主观性和不确定性,另一类则是基于数据驱动的可细分为统计模型和机器学习模型,如频率比模型(frequency ratio,fr)、支持向量机 (support vector machine,svm)、随机森林(random forest,rf)、反向传播神经网络(backpropagation neural network,bpnn)等,统计建模是通过数学方程揭示数据中变量之间的关系,机器学习则是通过数据进行学习不依赖规则函数,而逻辑回归、bootstrap均将统计模型借鉴到机器学习模型中来。
41.在现有的模型方法中,基于物理的滑坡易发性评估模型需要大量详细的数据,然
而对于大范围监测则难以收集数据,并且费事费力。启发式驱动模型是基于有限信息构建,通过专家意见和专业知识对滑坡致灾因子进行排序或加权来对其进行参数化,这种方法很难客观的量化或评估结果。而对于传统的浅层机器学习模型,如svm、rf等只有一个或零个隐藏层的浅层结构,存在训练时间有限、易陷入局部最优、收敛不稳定等缺点。随着深度学习成果的不断涌现,为滑坡易发性评估研究提供了新的思路和方法。深度学习通过对特征分层分析以学习到更复杂、更高级的隐藏特征。因此针对滑坡易发性研究中致灾因子与样本之间复杂的非线性关系,深度学习方法有助于挖掘到数据之间更深层的联系,并通过一系列优化策略,如激活部分神经元 (dropout)、批标准化(batch normalization,bn)、自适应矩估计 (adaptive moment estimation,adam)优化器、早停法(early stopping) 等,以有效解决过拟合、收敛困难与过慢等问题,但在参数的选择与优化上则没有一套完整的理论和标准,常常采用实验试错法、网格搜索法,这些方法受主观因素影响大,并且对于多参数情况往往难以同时优化。虽然在相关领域已开展深度学习研究,但针对不同地理环境的致灾因子适用性、深度学习优化策略以及多参数优化上则很少有研究,导致目前基于深度学习的滑坡滑坡易发性评估方法仍需要改善。
42.综合上述内容,挖掘到数据之间更深层的联系,以有效解决过拟合、收敛困难与过慢等问题的滑坡易发性评估方法是目前业界亟待解决的重要课题。
43.下面结合图1描述本发明的滑坡易发性评估方法,该方法包括以下步骤:
44.s100、筛选出样本区域的滑坡易发性致灾因子。由于针对不同地理环境下,滑坡易发性致灾因子的选择缺乏理论依据,以及滑坡易发性致灾因子本身可能具有强相关性,同时在深度学习模型中,特征维度过大易造成模型过拟合与执行效率下降,学习过多样本的异常噪声特征,也会使模型的泛化能力降低,因此需要对滑坡易发性致灾因子进行相应的筛选。经过步骤s100的处理后,得到的滑坡易发性致灾因子均为弱相关的地理—环境因子,即弱相关特征,可以排除强相关特征,同时对于模型训练贡献小的特征进行排除,使得后续生成的模型效率与精度都得到提高。
45.s200、将滑坡易发性致灾因子与从样本区域采集到的滑坡样本集组合在一起,得到致灾因子
‑
样本集。
46.s300、将致灾因子
‑
样本集作为训练使用的输入数据,采用深度学习方式,得到用于生成待评估区域的滑坡易发性结果的蚁群优化算法
‑
深度信念网络模型。
47.目前,虽然在滑坡易发性评估领域已开展深度学习研究,但针对不同地理环境的致灾因子适用性、深度学习优化策略以及多参数优化上则很少有研究。同时,深度学习本身存在譬如模型的结构、模型的泛化性与鲁棒性、过拟合与收敛困难等问题,在滑坡易发性评估研究对于模型的优化尚未重视。
48.在步骤s300中,采用的是蚁群优化算法(ant colony optimization, aco)
‑
深度信念网络(deep belief net,dbn)模型,本发明的滑坡易发性评估方法中首次将dbn模型结合aco运用到滑坡易发性评估中。
49.针对深度信念网络,aco
‑
dbn模型的参数中,激活函数采用双曲正切(tanh)函数,优化器采用adam优化器,优化策略采用bn 优化策略,使用l2权值衰减项正则化、早停法以及dropout等,损失函数采用交叉熵以及l2调整项,并通过蚁群算法同时优化dropout 和bn参数,使得在解决过拟合与收敛过慢的基础上保证更高的精度。aco是近年来提出的一种基
于种群的进化算法,一种基于种群寻优的启发式搜索群体智能算法,在迭代搜索过程中蚂蚁之间通过信息素交流,形成正反馈机制,在求解性能上,具有很强的鲁棒性和全局搜索能力,本质上具有并行性且对初始值选取不敏感。累积信息素作为蚁群算法更新的核心,aco的计算公式如下:
50.t
ij
(t+1)=(1
‑
ρ)
·
τ
ij
(t)+δτ
51.其中,τij表示在t时刻节点i到节点j之间的信息素浓度,ρ为搜寻k次的蚂蚁从节点i运动到j的概率,δτ的更新选择蚁周模型。
52.请参阅图2,在aco
‑
dbn模型的训练过程中使用启发式蚁群算法寻找最佳路径并不断迭代,以寻找aco
‑
dbn模型的最佳组合以及最佳参数,包括学习率和bn中最小批次大小,直到迭代次数最大。选出最优参数组合,最终经过约180迭代轮数,aco
‑
dbn模型收敛。请参阅图3,aco
‑
dbn模型训练过程中,训练集和验证集的准确率差值保持在0.02左右,这说明aco
‑
dbn模型没有明显的过拟合现象。请参阅图4,以应用于九寨沟地震引发的滑坡,进行滑坡易发性评估为例进行说明,图4为九寨沟震区滑坡易发性制图结果,此时迭代次数最大,得到的是组合以及参数最优的aco
‑
dbn模型,并以此组合以及参数最优的aco
‑
dbn模型进行相应的易发性制图。
53.请参阅图5,aco
‑
dbn模型的架构包括输入层、输出层以及位于输入层和输出层之间的四层受限玻尔兹曼机(restricted boltzmannmachine,rbm)层,四层rbm层中的神经元个数自输入层向输出层逐级减小。其中,输出层也被称为softmax回归层,softmax回归是 logistic回归在多分类问题上的推广,一般用于神经网络的输出层。
54.在本实施例中,这六层构架的层与层之间的连接为 9
‑
400
‑
200
‑
100
‑
50
‑
2,其中9为滑坡易发性致灾因子个数,400、200、 100以及50分别为四层rbm分别对应的神经元个数,2为最终经过 softmax回归层预测滑坡与非滑坡发生的概率。
55.本发明提供的滑坡易发性评估方法,通过将dbn模型与aco 相结合运用到滑坡易发性评估中,并通过aco优化dbn模型的优化策略中组合以及参数来解决模型过拟合与收敛缓慢等问题,通过筛选出样本区域的滑坡易发性致灾因子,优选出弱相关特征的滑坡易发性致灾因子,以此来实现滑坡易发性致灾因子与样本之间更深层的联系,最终实现了深度学习模型在滑坡易发性等防灾减灾应用中的更多价值。
56.下面结合图7描述本发明的滑坡易发性评估方法,步骤s100具体包括以下步骤:
57.s110、采集样本区域的滑坡信息。其中,滑坡信息包括遥感影像、卫星图像、基础地理、地质、地形地貌、气象水文、林地类型、土壤类型、历史滑坡灾害记录以及滑坡研究文献资料,遥感影像、卫星图像、基础地理、地质、地形地貌、气象水文、林地类型、土壤类型为基础数据。
58.s120、利用皮尔逊相关系数和随机森林特征重要性排序,从滑坡信息筛选出滑坡信息对应的滑坡易发性致灾因子。
59.在步骤s120中,针对不同地理环境下,滑坡易发性致灾因子的选择缺乏理论依据,以及致灾因子本身可能具有强相关性,同时在深度学习模型中,特征维度过大易造成模型过拟合与执行效率下降,学习过多样本的异常噪声特征,也会使模型的泛化能力降低,因此需要对滑坡易发性致灾因子进行筛选。通过皮尔逊相关系数和随机森林特征重要性排序来对致灾因子进行筛选以提高模型运行效率和保证精度。皮尔逊相关系数是以介于
‑
1至1之
间的具体数值来表征两个评估因子之间的相关性程度。当两个评估因子之间相互独立、无任何相关性时,其对应的相关系数值为0;当两个评估因子之间符合线性正相关关系时,两者之间的相关系数值为1;当两个评估因子的相关系数值为
‑
1时,表示因子之间满足线性负相关关系。随机森林特征重要性排序是根据随机森林直接测量每种特征对模型预测准确率的影响,基本思想是重新排列某一列特征值的顺序,观测降低了多少模型的准确率。通过这两种方法方式不仅可以排除强相关特征,得到的滑坡易发性致灾因子均为弱相关的地理—环境因子,即弱相关特征,同时对于模型训练贡献小的特征进行排除,使得aco
‑
dbn模型效率与精度都得到提高。
60.经过步骤s110以及步骤s120的处理后,最终在本发明的滑坡易发性评估方法中,筛选的到的滑坡易发性致灾因子一共有9个,分别为岩性、坡度、距道路距离、归一化植被指数(normalized differencevegetation index,ndvi)、坡位、距水系距离、土地利用、曲率和坡向,可以理解的是,以上9个滑坡易发性致灾因子会参与到aco
‑
dbn 模型的构建过程。
61.步骤s200具体包括以下步骤:
62.利用区域滑坡调查、基于卫星图像的目视解译以及基于遥感影像的智能识别,采集样本区域的滑坡样本集,这三种方法之间会相互补充与验证。
63.在本实施例中,步骤s200中还会通过地理信息系统(geographicinformation system或geo-information system,gis)软件等方式将部分面状滑坡数据均转化为统一的点数据(要素)。
64.以应用于九寨沟地震引发的滑坡,进行滑坡易发性评估为例进行说明,本发明的滑坡易发性评估方法构建的aco
‑
dbn模型最终共选取7184个样本点,正负样本比例为1:1,其中60%样本数据作为训练集,40%样本数据作为测试集
65.在aco
‑
dbn模型性能的验证阶段,利用rf模型、svm模型以及dbn模型与aco
‑
dbn模型进行精度评价,其中rf模型、svm 模型在进行滑坡易发性模型搭建时均基于rapidminer studio,数据结构与建模流程与dbn模型保持一致以利于对比分析。采用准确率优先准则,参数采用自动优化策略,最终通过训练调整,rf的主要参数选择为:决策树个数为9,最大深度为4,最小叶子节点大小为3,最小增益系数为0.01;svm核函数选择径向基,径向基函数的gamma 值为0.1,惩罚因数c为1.2。
66.为了验证aco
‑
dbn模型的性能和稳定性,本发明的滑坡易发性评估方法在验证阶段采用2874个测试样本(正负样本比例1:1)分别对四种模型进行精度评价,选取准确率、精确率、特异性、灵敏度与 f1值(f1 score)这5个单阈值统计指标以及roc曲线和auc值多阈值指标来综合评价模型的预测能力即模型的精度,四种模型的预测能力如表1所示。
67.表1验证阶段四种模型的预测能力对比表
[0068][0069][0070]
请参阅表1和图6所示,aco
‑
dbn模型测试准确率为92.97%, dbn、svm模型次之,rf最低,表示aco
‑
dbn模型分类器总体性能较好。精确率则反映的是预测为正样本即滑坡单位被正确分类的概率,在滑坡易发性分析中,预测期望是更多的滑坡单位被正确预测, rf模型的精确率高于svm模型,这与准确率相比表现不一致,很难优选模型;而aco
‑
dbn模型在这两方面均优于对比模型,表现出更好的一致性。另一方面,特异性与灵敏度指标则反映了对于真实正负样本中被正确预测的概率,可以看出svm模型预测正样本的性能优于rf,而f1值为特异性和灵敏度的整体评价,因此aco
‑
dbn模型在二者都表现优异的情况下,f1值最大,对于正负真实样本的正确预测能力最强。再由图6可知aco
‑
dbn模型曲线位于rf与svm 之上,对应的auc值最大,为0.973。综合以上分析,aco
‑
dbn模型对于滑坡易发性评估表现出较好的预测性能与稳定性,可知 aco
‑
dbn模型对于处理复杂的非线性因子具有很大优势与研究价值。
[0071]
下面对本发明提供的滑坡易发性评估装置进行描述,下文描述的滑坡易发性评估装置与上文描述的滑坡易发性评估方法可相互对应参照。
[0072]
下面结合图8描述本发明的滑坡易发性评估装置,该装置包括:
[0073]
致灾因子筛选模块100,用于筛选出样本区域的滑坡易发性致灾因子。由于针对不同地理环境下,滑坡易发性致灾因子的选择缺乏理论依据,以及滑坡易发性致灾因子本身可能具有强相关性,同时在深度学习模型中,特征维度过大易造成模型过拟合与执行效率下降,学习过多样本的异常噪声特征,也会使模型的泛化能力降低,因此需要对滑坡易发性致灾因子进行相应的筛选。经过步骤s100的处理后,得到的滑坡易发性致灾因子均为弱相关的地理—环境因子,即弱相关特征,可以排除强相关特征,同时对于模型训练贡献小的特征进行排除,使得后续生成的模型效率与精度都得到提高。
[0074]
样本集建立模块200用于将滑坡易发性致灾因子与从样本区域采集到的滑坡样本集组合在一起,得到致灾因子
‑
样本集。
[0075]
其中,样本集建立模块200具体包括利用区域滑坡调查、基于卫星图像的目视解译以及基于遥感影像的智能识别,采集样本区域的滑坡样本集,这三种装置之间会相互补充与验证。在本实施例中,样本集建立模块200中还会通过地理信息系统(geographic informationsystem或geo-information system,gis)软件等方式将部分面状滑坡数据
均转化为统一的点数据(要素)。
[0076]
易发性评估模块300,用于将致灾因子
‑
样本集作为训练使用的输入数据,采用深度学习方式,得到用于生成待评估区域的滑坡易发性结果的蚁群优化算法
‑
深度信念网络模型。
[0077]
在易发性评估模块300中,采用的是蚁群优化算法(ant colonyoptimization,aco)
‑
深度信念网络(deep belief net,dbn)模型,本发明的滑坡易发性评估装置中首次将dbn模型结合aco运用到滑坡易发性评估中。
[0078]
本发明提供的滑坡易发性评估装置,通过易发性评估模块300,将dbn模型与aco相结合运用到滑坡易发性评估中,并通过aco 优化dbn模型的优化策略中组合以及参数来解决模型过拟合与收敛缓慢等问题,通过致灾因子筛选模块100,优选出弱相关特征的滑坡易发性致灾因子,以此来实现滑坡易发性致灾因子与样本之间更深层的联系,最终实现了深度学习模型在滑坡易发性等防灾减灾应用中的更多价值。
[0079]
下面结合图9描述本发明的滑坡易发性评估装置,致灾因子筛选模块100具体包括:
[0080]
采集单元110,用于采集样本区域的滑坡信息。其中,滑坡信息包括遥感影像、卫星图像、基础地理、地质、地形地貌、气象水文、林地类型、土壤类型、历史滑坡灾害记录以及滑坡研究文献资料,遥感影像、卫星图像、基础地理、地质、地形地貌、气象水文、林地类型、土壤类型为基础数据。
[0081]
筛选单元120,用于利用皮尔逊相关系数和随机森林特征重要性排序,从滑坡信息筛选出滑坡信息对应的滑坡易发性致灾因子。
[0082]
在筛选单元120中,针对不同地理环境下,滑坡易发性致灾因子的选择缺乏理论依据,以及致灾因子本身可能具有强相关性,同时在深度学习模型中,特征维度过大易造成模型过拟合与执行效率下降,学习过多样本的异常噪声特征,也会使模型的泛化能力降低,因此需要对滑坡易发性致灾因子进行筛选。通过皮尔逊相关系数和随机森林特征重要性排序来对致灾因子进行筛选以提高模型运行效率和保证精度。皮尔逊相关系数是以介于
‑
1至1之间的具体数值来表征两个评估因子之间的相关性程度。当两个评估因子之间相互独立、无任何相关性时,其对应的相关系数值为0;当两个评估因子之间符合线性正相关关系时,两者之间的相关系数值为1;当两个评估因子的相关系数值为
‑
1时,表示因子之间满足线性负相关关系。随机森林特征重要性排序是根据随机森林直接测量每种特征对模型预测准确率的影响,基本思想是重新排列某一列特征值的顺序,观测降低了多少模型的准确率。通过这两种装置方式不仅可以排除强相关特征,得到的滑坡易发性致灾因子均为弱相关的地理—环境因子,即弱相关特征,同时对于模型训练贡献小的特征进行排除,使得aco
‑
dbn模型效率与精度都得到提高。
[0083]
经过采集单元110以及筛选单元120的处理后,最终在本发明的滑坡易发性评估装置中,筛选的到的滑坡易发性致灾因子一共有9个,分别为岩性、坡度、距道路距离、归一化植被指数(normalizeddifference vegetation index,ndvi)、坡位、距水系距离、土地利用、曲率和坡向,可以理解的是,以上9个滑坡易发性致灾因子会参与到aco
‑
dbn模型的构建过程。
[0084]
图10示例了一种电子设备的实体结构示意图,如图10所示,该电子设备可以包括:
处理器(processor)810、通信接口(communications interface)820、存储器(memory)830和通信总线840,其中,处理器810,通信接口820,存储器830通过通信总线840完成相互间的通信。处理器810可以调用存储器830中的逻辑指令,以执行滑坡易发性评估方法,该方法包括以下步骤:
[0085]
s100、筛选出样本区域的滑坡易发性致灾因子;
[0086]
s200、将所述滑坡易发性致灾因子与从所述样本区域采集到的滑坡样本集组合在一起,得到致灾因子
‑
样本集;
[0087]
s300、将所述致灾因子
‑
样本集作为训练使用的输入数据,采用深度学习方式,得到用于生成待评估区域的滑坡易发性结果的蚁群优化算法
‑
深度信念网络模型。
[0088]
此外,上述的存储器830中的逻辑指令可以通过软件功能单元的形式实现并作为独立的产品销售或使用时,可以存储在一个计算机可读取存储介质中。基于这样的理解,本发明的技术方案本质上或者说对现有技术做出贡献的部分或者该技术方案的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质中,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行本发明各个实施例所述方法的全部或部分步骤。而前述的存储介质包括:u盘、移动硬盘、只读存储器(rom,read
‑
onlymemory)、随机存取存储器(ram,random access memory)、磁碟或者光盘等各种可以存储程序代码的介质。
[0089]
另一方面,本发明还提供一种计算机程序产品,所述计算机程序产品包括存储在非暂态计算机可读存储介质上的计算机程序,所述计算机程序包括程序指令,当所述程序指令被计算机执行时,计算机能够执行上述各方法所提供的滑坡易发性评估方法,该方法包括以下步骤:
[0090]
s100、筛选出样本区域的滑坡易发性致灾因子;
[0091]
s200、将所述滑坡易发性致灾因子与从所述样本区域采集到的滑坡样本集组合在一起,得到致灾因子
‑
样本集;
[0092]
s300、将所述致灾因子
‑
样本集作为训练使用的输入数据,采用深度学习方式,得到用于生成待评估区域的滑坡易发性结果的蚁群优化算法
‑
深度信念网络模型。
[0093]
又一方面,本发明还提供一种非暂态计算机可读存储介质,其上存储有计算机程序,该计算机程序被处理器执行时实现以执行上述各提供的执行滑坡易发性评估方法,该方法包括以下步骤:
[0094]
s100、筛选出样本区域的滑坡易发性致灾因子;
[0095]
s200、将所述滑坡易发性致灾因子与从所述样本区域采集到的滑坡样本集组合在一起,得到致灾因子
‑
样本集;
[0096]
s300、将所述致灾因子
‑
样本集作为训练使用的输入数据,采用深度学习方式,得到用于生成待评估区域的滑坡易发性结果的蚁群优化算法
‑
深度信念网络模型。
[0097]
以上所描述的装置实施例仅仅是示意性的,其中所述作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部模块来实现本实施例方案的目的。本领域普通技术人员在不付出创造性的劳动的情况下,即可以理解并实施。
[0098]
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到各实施方式可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件。基于这样的理解,上述技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品可以存储在计算机可读存储介质中,如rom/ram、磁碟、光盘等,包括若干指令用以使得一台计算机设备(可以是个人计算机,服务器,或者网络设备等)执行各个实施例或者实施例的某些部分所述的方法。
[0099]
最后应说明的是:以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1