一种多文档自动摘要生成方法与流程
本发明涉及一种多文档自动摘要生成方法,属于互联网和人工智能技术领域。
背景技术
近年来,随着互联网技术的高速发展,网络已经成为人们获取信息资讯的一个重要渠道,然而网络信息呈现出内容冗余、数量庞大的特点,导致人们获取重点资讯的效率大打折扣。多文档摘要(Multi-Document Summarization,MDS)技术旨在对主题相同或相近的多篇文档进行分析提炼、整合加工,生成一段能概括中心主题的总结性摘要,能够有效实现同一话题下多篇文档的内容聚合,从而帮助用户快速且清晰地了解文档信息的主要内容。
目前主流的多文档摘要技术通常利用深度神经网络模型在词汇与文档两个级别上分别进行富语义向量编码,从而捕获文档内部的词汇语义与文档之间的依赖关系,进而利用文档层次信息进行摘要生成。然而,上述方法主要存在以下三个问题:一,为了进行跨文档关系抽取,需要先对文档进行特征表示,然而现有方法缺乏全局性的显式约束,容易导致文档表示缺失重要信息,不利于文档关系建模;二,主题相同的多篇文档存在明显的信息重叠问题,在未经过筛选的情况下,容易造成生成的摘要存在较多的冗余信息;三,现有方法通过拼接或相加等形式对文档层次信息进行简单地融合,难以有效构建层次化特征的深层关联。
技术实现要素:
针对现有技术中存在的问题与不足,本发明提供一种多文档自动摘要生成方法,该方法可以有效结合文档内部的语义信息与文档之间的依赖关系,为摘要生成过程提供丰富的层次结构信息,从而提高摘要结果的上下文一致性与信息覆盖度。
为实现上述发明目的,本发明所述的一种多文档自动摘要生成方法,首先提取文档的子主题表示并构建出文档集合的中心主题表示,进而生成更具主题相关性的文档向量;然后,通过信息门控机制过滤文档内部语义信息,得到信息更为显著的词汇向量;最后利用层次化注意力机制在文档与词汇两个层次上进行信息整合,并将两个层次的语义信息融合为上下文向量,从而引导摘要生成过程。该方法主要包括四个步骤,具体如下:
步骤1:数据预处理,对预设的文本摘要数据集中的文本进行截断、词嵌入与位置编码,将词嵌入表示与位置编码相加后获得每个单词的词向量表示,预设的数据集中每一个样本包括同一主题的多篇文本以及相应的一份人工摘要;
步骤2:多文档摘要生成模型构建与训练。首先利用Transformer编码模块对词向量表示后的样本文本进行词汇语义信息的提取,并通过主题融合注意力模块整合词汇语义信息,生成文档向量表示;然后通过多头自注意力实现文档之间的信息交互,并经过残差结构、层归一化、前馈神经网络获得包含文档依赖关系的文档向量表示;接着经由信息门控,对词汇语义向量进行信息筛选,并通过层次化注意力机制对词汇与文档两个层次得到的语义向量进行融合,生成的上下文向量用于引导摘要生成;最后利用三元组损失与交叉熵损失联合训练所述模型。
步骤3:对待进行摘要的多篇文本生成摘要。对于待进行摘要的文本,首先进行文本截断、词嵌入与位置编码,将得到的词向量表示输入到步骤3中训练好的摘要生成模型中,生成文本话题摘要。
相对于现有技术,本发明的优点如下:
(1)本发明采用的基于主题融合注意力的文档表示方法,能够通过构建中心主题来指导词汇语义向量生成信息更为全面、主题更为相关的文档向量表示,缓解重要信息丢失问题;
(2)本发明采用的信息门控机制,能够对词汇语义向量进行信息预过滤,减少了冗余信息的干扰,有效提高了摘要结果的准确性;
(3)本发明采用的层次化注意力机制,通过对文档内部的词汇语义信息与文档之间的外部关联信息分层次地整合、关联,能够有效构建层次化特征的深层关联,能够为摘要生成过程提供丰富的层次语义信息,提高摘要结果的上下文一致性。
附图说明
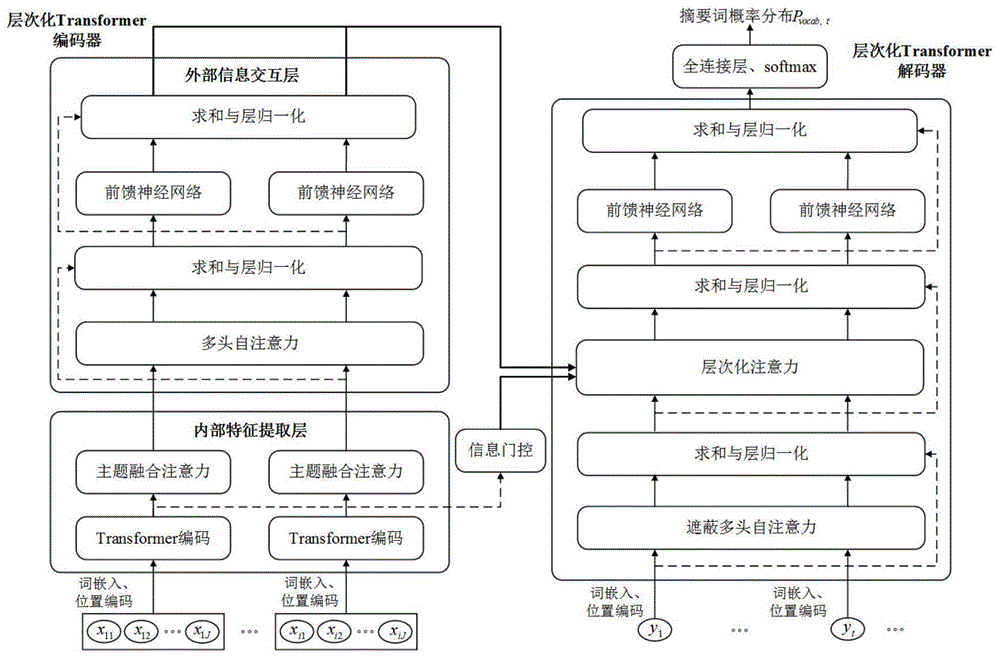
图1为本发明实施例的多文档摘要模型框架图。
图2为主题融合注意力模块的整体结构图。
具体实施方式
为了加深对本发明的认识和理解,下面结合具体实施例,进一步阐明本发明。
实施例:参见图1、图2,本发明提供的一种多文档自动摘要生成方法,具体实施步骤如下:
步骤1,数据预处理,本实施例首先对预设的数据集D进行预处理。对于每个样本中包含的M篇文本进行截断处理,截断后每篇文本的长度为Len/M,若截断前文本的长度小于Len/M,则截断前后文本长度不变,本实施例中Len取1500;对于截断后的每篇文本进行词嵌入映射与位置编码,词嵌入矩阵为可学习的参数矩阵,位置编码采用Transformer模型中的位置编码模块;
步骤2,利用步骤1处理后的数据集D对多文档摘要生成模型构建与训练进行训练,该步骤的实施可以分为以下子步骤:
子步骤2-1,构建内部特征提取层,利用l个堆叠的Transformer编码子层提取每个样本中各个输入文本词向量表示的语义信息,得到第i个输入文本中第j个词的词汇语义向量表示并通过主题融合注意力模块在词汇语义向量表示的基础上构建出固定维度的文档向量表示,主题融合注意力模块包括子主题编码、子主题融合与注意力计算三个部分。子主题编码采用两层的双向LSTM网络生成每个文本的子主题向量表示,子主题编码器的输入为词汇语义向量序列,并将输出的前向隐状态与后向隐状态拼接得到子主题向量表示采用加权求和的方式计算出输入文本集合的中心主题向量
其中,权重因子wi代表了该子主题向量对中心主题向量的贡献程度,N代表文档集合中的文档总数,Tsum代表文档集合中所有文档子主题向量的向量和,[Ti;Tsum]为Ti与Tsum的维度拼接结果,v为可学习的权重矩阵参数。基于中心主题向量采用注意力机制对词汇语义向量进行整合,并构建出文档向量表示
其中,为第i个文档的词汇语义向量序列,Wd为可学习的参数矩阵,J为输入文档所含的词汇个数。
子步骤2-2,构建外部信息交互层,本实施例采用多头自注意力机制(Multi-Head Self Attention)来实现文档之间的信息交互以捕获文档之间的关联信息,输入为各个文档的向量表示本实施例中注意力头数取值为8,并经由残差结构、层归一化、前馈神经网络模块得到最终的文档向量di。
子步骤2-3,信息门控过滤,利用文档子主题向量表示对于编码器生成的词汇语义向量进行信息过滤以减少不必要的冗余内容。对于第i个文档中第j个词语,相应的门控向量的计算公式如下:
其中,Wg、Ug、bg为可学习的参数,σ(·)为sigmoid函数,之后以门控向量对词汇语义向量进行向量点乘以实现信息过滤:
子步骤2-4,层次化注意力计算。本实施例采用一种层次化注意力机制来对文档向量与词汇向量进行融合,生成包含丰富层次语义信息的上下文向量,该机制的输入包括三个部分,分别是子步骤2-2得到的所有文档向量d、子步骤2-3过滤后的词汇语义向量以及当前解码时刻的隐状态向量ht,其中,ht由解码器t时刻的输入yt经由词嵌入、位置编码、遮蔽多头自注意力、残差连接以及层归一化后输出得到,在训练过程中yt为样本所含人工摘要的第t个词。该机制首先在文档级别上进行注意力计算,生成文档上下文向量
其中,为注意力权重,由ht与所有文档向量d按式3的形式计算得到。之后在词汇级别上进行注意力计算,并用文档注意力权重进行调整:
其中,为第i个文档中第j个词的词汇注意力权重,为词汇上下文向量。最后,对在文档层次与词汇层次上分别得到的上下文向量进行维度拼接与线性映射,生成上下文向量ct:
其中Wc为可学习的权重参数。
子步骤2-5,构建摘要概率化层,对上下文向量ct与隐状态向量ht经由残差连接、层归一化、前馈神经网络得到解码器t时刻的输出向量并通过一个全连接层fc与softmax函数,转化为摘要词的预测概率分布P,计算公式如下所示:
子步骤2-6,构建损失函数层,本层采用预测摘要与人工摘要的交叉熵损失函数LS以及文档主题抽取的三元组损失函数LT来构建模型的总体损失函数。其中三元组损失函数计算如下
LT=max{d(TA,TP)-d(TA,TN)+Margin,0} (12)
d(TA,TP)=1-cos(TA,TP) (13)
d(TA,TN)=1-cos(TA,TN) (14)
Ltotal=αLS+βLT (15)
其中LT为三元组损失,Margin为边界距离,本实施例取值为1,以保证正实例P与负实例N在主题语义上存在差异性,TA为真实摘要的子主题向量、TP为输入文档集合的中心主题向量、TN为另一样本文档集合的中心主题向量;cos函数用于计算两个主题向量夹角的余弦值,用以衡量主题向量间的语义相似度;ɑ与β为超参数,代表两个损失各自的权重系数,本实施例中分别取值0.9与1.5。LS为摘要词预测的交叉熵损失;Ltotal为模型的总体损失函数。
子步骤2-7,模型训练。本实施例采用随机初始化的方式初始化所有待训练参数,在训练过程中采用Adam优化器进行梯度反向传播来更新模型参数,初始学习率设置为0.001,β1、β2系数分别设置为0.9与0.998,批次尺寸设置为16,损失函数连续3轮不再下降或训练轮次超过50后停止模型训练。
步骤3,利用训练完毕的模型生成摘要。对待进行摘要的多篇文本按步骤1的方式进行预处理后输入到训练完毕的模型中,解码器的初始输入为特殊标记“<START>”,每一时刻的预测摘要词为摘要概率化层输出的概率最大的词,预测摘要词将作为下一时刻解码器的输入,当输出结束标记“<END>”时,停止摘要生成,输出已生成的摘要词作为输入文本集合的预测摘要。
基于相同的发明构思,本发明实施例还提供一种多文档自动摘要生成装置,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,该计算机程序被加载至处理器时实现上述的多文档自动摘要生成方法。
应理解实施例仅用于说明本发明而不用于限制本发明的范围,在阅读了本发明之后,本领域技术人员对本发明的各种等价形式的修改均落于本申请所附权利要求所限定的范围。
- 还没有人留言评论。精彩留言会获得点赞!