融合通道与关系特征学习的知识蒸馏方法、装置及设备
1.本发明涉及知识蒸馏技术领域,具体是指一种融合通道与关系特征学习的知识蒸馏方法、装置及设备。
背景技术:
2.深度学习技术在近年来发展非常迅速,在计算机视觉和自然语言处理领域也有突破性的进展。从2012年提出的alexnet到2016年提出的densenet,这些神经网络都有着强大的性能,并且在图像分类任务中突破了传统算法。更深的神经网络可以提取更多信息,也就拥有着更好的表示能力。但是更深、更复杂的神经网络需要更多的算力和推理时间,不能够满足实际工业应用中的实时响应,并且在移动终端上进行实时推断也无法接受大量的网络参数和计算。alexnet和densenet神经网络仅仅考虑了如何提高准确性,但是忽略了实际工业应用中的实时响应性。如何能够保持神经网络的高准确性和降低神经网络的复杂度,成为了目前深度学习研究的一个热门方向,也是需要解决的一个问题。
3.对于神经网络压缩,目前有知识蒸馏、网络结构搜索和量化等这几种方法。其中知识蒸馏是geoffrey hinton在2015年提出的一种压缩技术,也是模型压缩领域中一个特别重要的技术。这里只谈知识蒸馏这种模型压缩技术,2006年bulica最早提出了知识蒸馏模型的概念,hinton在2014年对知识蒸馏做了归纳和发展。知识蒸馏的主要目的是训练一个小的网络模型(小参数模型)去模仿一个预先训练好的大型或者集成的网络(大参数模型)。这种训练模式又被称为“teacher
‑
student”,大型的网络是“教师”,小型的网络是“学生”。实际上就是让学生模型去学习已经在目标数据集上训练过的老师模型的输出。训练出的学生模型不仅模型规模小,而且精度高,甚至会超过教师模型的性能。这样的小型网络,可以很容易的应用在小型终端设备中,例如手机、移动机器人等,在有限的计算资源下能够发挥更好的效益。
4.传统的教师学生知识蒸馏方法是学生网络通过学习大型教师的软标签输出,进而提升学生网络的性能,学生学习的知识只有教师输出的软标签,这使得学生网络的性能提升非常有限。后期提出的知识蒸馏方法中,学生网络能够学习教师网络全连接层的映射图输出学习教师网络的内部结构,使得学生网络性能能够继续提升。但上述的方法没有考虑到卷积层上通道的相关知识,同时也忽略了不同样本在通道内的关系特征知识。并且,在学习过程中,学生网络会受到教师错误知识的影响,使得训练学生网络后期不能有效的提升学生网络的性能。
技术实现要素:
5.基于以上技术问题,本发明提供了一种融合通道与关系特征学习的知识蒸馏方法、装置及设备,学生网络不仅可以学习教师网络卷积层的通道知识和不同样本在通道内的关系特征知识,并且在训练过程中逐渐降低教师错误知识对学生的影响,进而提升学生网络的性能。这样不仅能够有效的压缩学生网络模型,也能让学生网络的性能进一步提升,
甚至超越大型教师网络的性能。具体包括以下技术方案:
6.一种融合通道与关系特征学习的知识蒸馏方法,其特征在于,包括:
7.构建未训练的学生网络和完成预训练的教师网络;
8.将训练数据分别输入学生网络和教师网络获得学生网络的输出结果、教师网络的输出结果,训练数据还包括对应的真实标签数据;
9.基于学生网络和教师网络的通道数据、学生网络的输出结果、教师网络的输出结果、学习网络与教师网络迁移样本间关系确定蒸馏损失函数;
10.基于蒸馏损失函数对学生网络进行迭代训练。
11.一种融合通道与关系特征学习的知识蒸馏装置,其特征在于,包括:
12.网络构建模块,网络构件模块用于构建未训练的学生网络和完成预训练的教师网络;
13.数据处理模块,数据处理模块用于将训练数据输入学生网络和教师网络获得学生网络和教师网络的输出结果,训练数据还包括对应的真实标签数据;
14.损失函数确定模块,损失函数确定模块用于基于学生网络和教师网络的通道数据、学生网络的输出结果、教师网络的输出结果、学习网络与教师网络迁移样本间关系确定蒸馏损失函数;
15.网络训练模块,网络训练模块用于基于蒸馏损失函数对学生网络进行迭代训练。
16.一种计算机设备,其特征在于,包括存储器和处理器,存储器中存储有计算机程序,处理器执行计算机程序时实现上述融合通道与关系特征学习的知识蒸馏方法的步骤。
17.一种计算机可读存储介质,其特征在于,计算机可读存储介质上存储有计算机程序,计算机程序被处理器执行时实现上述融合通道与关系特征学习的知识蒸馏方法的步骤。
18.与现有技术相比,本发明的有益效果是:
19.本发明提出的知识蒸馏方法,学生网络不仅可以学习教师网络卷积层的通道知识以及不同样本之间在通道内的关系知识,并且在训练过程中在通道内逐渐降低教师错误知识对学生的影响,进而提升学生网络的性能。这样不仅能够有效的压缩学生网络模型,也能让学生网络的性能进一步提升,甚至超越大型教师网络的性能。
附图说明
20.本申请将以示例性实施例的方式进一步说明,这些示例性实施例将通过附图进行详细描述,其中:
21.图1为融合通道与关系特征学习的知识蒸馏方法流程示意图。
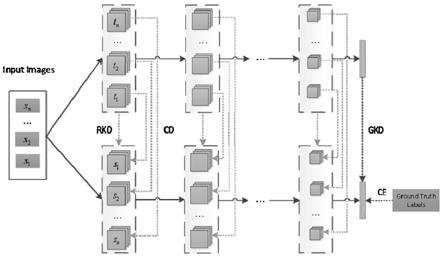
22.图2为融合通道与关系特征学习的知识蒸馏方法基本框架结构示意图。
23.图3为教师网络预训练流程示意图。
具体实施方式
24.为使本公开实施例的目的、技术方案和优点更加清楚,下面将结合本公开实施例的附图,对本公开实施例的技术方案进行清楚、完整地描述。显然,所描述的实施例是本公开的一部分实施例,而不是全部的实施例。基于所描述的本公开的实施例,本领域普通技术
人员在无需创造性劳动的前提下所获得的所有其他实施例,都属于本公开保护的范围。
25.本申请的目的在于提供一种融合通道与关系特征学习的知识蒸馏方法、装置及设备,所述方法包括:构建未训练的学生网络和完成预训练的教师网络;将训练数据分别输入学生网络和教师网络获得学生网络的输出结果、教师网络的输出结果,训练数据还包括对应的真实标签数据;基于学生网络和教师网络的通道数据、学生网络的输出结果、教师网络的输出结果、学习网络与教师网络迁移样本间关系确定蒸馏损失函数;基于蒸馏损失函数对学生网络进行迭代训练。
26.本申请实施例可用于以下应用场景,包括但是不限于,计算机视觉应用领域的各种场景例如人脸识别、图像分类、目标检测、语义分割等,或者是部署到边缘设备上(例如移动电话、可穿戴设备、计算节点等)的基于神经网络模型的处理系统,或者用于语音信号处理、自然语言处理、推荐系统的应用场景,或者是由于有限资源和时延要求需要对神经网络模型进行压缩的应用场景。
27.仅仅出于说明性目的,本申请实施例可用于手机端物体检测的应用场景。该应用场景需要解决的技术问题是:当用户使用手机拍照时,需要自动抓取人脸、动物等目标,从而帮助手机自动对焦、美化等,因此需要一个体积小、运行快的用于目标检测的卷积神经网络模型,进而给用户带来更好的用户体验并提升手机产品品质。
28.仅仅出于说明性目的,本申请实施例还可用于自动驾驶场景分割的应用场景。该应用场景需要解决的技术问题是:自动驾驶车辆的摄像头捕捉到道路画面后需要对画面进行分割,从中分出路面、路基、车辆、行人等不同物体,从而保持车辆行驶在正确的区域。因此需要能够快速实时对画面进行正确解读和语义分割的卷积神经网络模型。
29.仅仅出于说明性目的,本申请实施例还可用于入口闸机人脸验证的应用场景。该应用场景需要解决的技术问题是:在高铁、机场等入口的闸机上,乘客进行人脸认证时,摄像头会拍摄人脸图像并使用卷积神经网络抽取特征,然后和存储在系统中的身份证件的图像特征进行相似度计算;如果相似度高就验证成功。其中,通过卷积神经网络抽取特征是最耗时的,因此需要能够快速进行人脸验证和特征提取的高效的卷积神经网络模型。
30.仅仅出于说明性目的,本申请实施例还可用于翻译机同声传译的应用场景。该应用场景需要解决的技术问题是:在语音识别和机器翻译问题上,必须达到实时语音识别并进行翻译,因此需要高效的卷积神经网络模型。
31.本申请实施例可以依据具体应用环境进行调整和改进,此处不做具体限定。
32.为了使本技术领域的人员更好地理解本申请方案,下面将结合本申请实施例中的附图,对本申请的实施例进行描述。
33.参阅图1,在本实施方式中,融合通道与关系特征学习的知识蒸馏方法,包括:
34.s101,构建未训练的学生网络和完成预训练的教师网络;
35.s102,将训练数据分别输入学生网络和教师网络获得学生网络的输出结果、教师网络的输出结果,训练数据还包括对应的真实标签数据;
36.s103,基于学生网络和教师网络的通道数据、学生网络的输出结果、教师网络的输出结果、学习网络与教师网络迁移样本间关系确定蒸馏损失函数;
37.其中,卷积神经网络中通道(channels)分为三种:其一是最初输入的图片样本的channels,取决于图片类型,比如rgb三色图片,则channels=3;其二是卷积操作完成后输
出的out_channels,其取决于卷积核的数量,此时的out_channels也会作为下一次卷积时的卷积核的in_channels。如果是第一次做卷积,就是图片样本的channels。
38.s104,基于蒸馏损失函数对学生网络进行迭代训练。
39.在本实施例中,已知对于传统的教师
‑
学生知识蒸馏方法,学生网络能够学习大型教师网络的知识,从而提升学生网络的性能。但是在传统的知识蒸馏方法中,学生网络通过学习教师网络全连接层的映射图输出学习其内部结构,却忽略了卷积层上通道的相关知识,同时也忽略了不同数据样本在通道内的关系知识。并且,在学习过程中,学生网络会受到教师错误知识的影响,后期不能有效的提升学生网络的性能。
40.本申请提出的知识蒸馏方法,学生网络不仅可以学习教师网络卷积层的通道知识以及不同样本之间在通道内的关系知识,并且在训练过程中在通道内逐渐降低教师错误知识对学生的影响,进而提升学生网络的性能。这样不仅能够有效的压缩学生网络模型,也能让学生网络的性能进一步提升,甚至超越大型教师网络的性能。
41.参与图2,在一些实施例中,基于学生网络和教师网络的通道数据、学生网络的输出结果和教师网络的输出结果确定蒸馏损失函数包括:
42.基于学生网络和教师网络的通道数据确定第一损失函数;
43.具体的,第一损失函数为:
[0044][0045]
其中,l
cd
表示第一损失函数,s表示学生网络,t表示教师网络,m表示一个batch中的样本个数,k表示一个样本中的总通道数,c
ij
表示第i个样本的第j个通道的权重。
[0046]
其中,batch用于定义在更新内部模型参数之前要处理的样本数,其大小是一个超参数。将批处理视为循环迭代一个或多个样本并进行预测。在批处理结束时,将预测与预期输出变量进行比较,并计算误差。从该错误中,更新算法用于改进模型,例如沿误差梯度向下移动。训练数据集可以分为一个或多个batch。当所有训练样本用于创建一个batch时,学习算法称为批量梯度下降。当批量是一个样本的大小时,学习算法称为随机梯度下降。当批量大小超过一个样本且小于训练数据集的大小时,学习算法称为小批量梯度下降。
[0047]
其中,第一损失函数具体为通道知识迁移损失函数,具体用于学生网络学习教师网络的通道知识。
[0048]
基于学生网络的输出结果和教师网络的输出结果确定第二损失函数;
[0049]
具体的,第二损失函数为:
[0050][0051]
其中,l
dkd
表示第二损失函数,表示网络输出的概率分布,z表示网络经过logits函数的输出结果,t表示温度参数,l
kl
表示学生网络和教师网络输出之间的kl散度,y表示真实标签数据;
[0052]
其中,第二损失函数具体用于学生网络学习教师网络的输出知识,其目的在于让学生网络的输出分布更加逼近教师网络的输出分布。
[0053]
其中,d(
·
)表示降低教师网络错误知识影响的函数,具体为:
[0054][0055]
其中,a表示超参数,λ表示恒定系数,ep
n
表示训练过程中第n个epoch。
[0056]
其中,epoch是一个超参数,定义了学习算法在整个训练数据集中的工作次数。一个epoch意味着训练数据集中的每个样本都有机会更新内部模型参数。epoch由一个或多个batch组成。
[0057]
其中,一般而言,尽管教师网络的准确率高于学生网络的预测,但是教师网络仍然会有错误的预测。在传统的知识蒸馏中,这些错误的预测也会被学生网络学习,过多的错误知识会降低学生网络的性能。因此在本申请中改进了传统的知识蒸馏方法,利用降低函数d(
·
)降低教师网络错误知识对学生网络的影响。
[0058]
基于学习网络与教师网络之间样本在通道内的关系确定第三损失函数;
[0059]
具体的,第三损失函数包括距离损失函数和角度损失函数,其中:
[0060]
第三损失函数具体为:
[0061]
l
rd
=l
dd
(c
u
,c
v
)+βl
ad
(c
u
,c
v
,c
ω
)
[0062]
其中,l
rd
表示第三损失函数,l
dd
表示距离损失函数,l
ad
表示角度损失函数,β表示权重系数,c
u
,c
v
,c
w
表示第u、v、w个样本的权重;
[0063]
所述距离损失函数具体为:
[0064][0065]
其中,χ
n
表示一个batch中n个不同样本的组合个数,χ2={(c
u
,c
v
)|u≠v};
[0066]
其中,l(
·
)表示距离函数,表示在教师网络t、学生网络s中样本之间的距离,具体为:
[0067][0068][0069]
其中,归一化常数
[0070]
其中,h(
·
)表示实例关系的huber损失,具体为:
[0071][0072]
所述角度损失函数具体为:
[0073][0074]
其中,χ3={(c
u
,c
v
,c
w
)|u≠v≠w};
[0075]
其中,r(
·
)表示角度函数,表示在教师网络t、学生网络s中样本之间的角度,具体为:
[0076][0077][0078]
其中,其中,其中,表示标记。
[0079]
基于学生网络的输出结果和真实标签数据确定第四损失函数;
[0080]
具体的,第四损失函数为:
[0081]
l
ce
=crossentropy(p
s
,y)
[0082]
其中,crossentropy表示交叉熵损失函数,p
s
表示学生网络的预测输出,y为真实数据标签值。
[0083]
将第一损失函数、第二损失函数、第三损失函数和第四损失函数加权求和获得蒸馏损失函数。
[0084]
具体的,蒸馏损失函数为:
[0085]
loss=αl
cd
+γl
dkd
+ηl
rd
+l
ce
[0086]
其中,α、γ、η表示超参数。
[0087]
其中,在图2中,rkd对应第三损失函数l
rd
、cd对应第一损失函数l
cd
、gkd对应第二损失函数l
dkd
、ce对应第四损失函数l
ce
。
[0088]
参阅图3,在一些实施例中,预训练包括:
[0089]
s301,构建未训练的待训练网络;
[0090]
s302,将训练数据输入待训练网络中获取待训练网络的输出结果;
[0091]
s303,基于待训练网络的输出结果和真实标签数据确定交叉熵损失函数;
[0092]
s304,基于交叉熵损失函数对待训练网络进行迭代训练获取教师网络。
[0093]
在一些实施例中,一种融合通道与关系特征学习的知识蒸馏装置,包括:
[0094]
网络构建模块,网络构件模块用于构建未训练的学生网络和完成预训练的教师网络;
[0095]
数据处理模块,数据处理模块用于将训练数据输入学生网络和教师网络获得学生网络和教师网络的输出结果,训练数据还包括对应的真实标签数据;
[0096]
损失函数确定模块,损失函数确定模块用于基于学生网络和教师网络的通道数据、学生网络的输出结果、教师网络的输出结果、学习网络与教师网络迁移样本间关系确定蒸馏损失函数;
[0097]
网络训练模块,网络训练模块用于基于蒸馏损失函数对学生网络进行迭代训练。
[0098]
在一些实施例中,本申请还公开了一种计算机设备,其特征在于,包括存储器和处理器,存储器中存储有计算机程序,处理器执行计算机程序时实现上述融合通道与关系特征学习的知识蒸馏方法的步骤。
[0099]
其中,所述计算机设备可以是桌上型计算机、笔记本、掌上电脑及云端服务器等计
算设备。所述计算机设备可以与用户通过键盘、鼠标、遥控器、触摸板或声控设备等方式进行人机交互。
[0100]
所述存储器至少包括一种类型的可读存储介质,所述可读存储介质包括闪存、硬盘、多媒体卡、卡型存储器(例如,sd或d界面显示存储器等)、随机访问存储器(ram)、静态随机访问存储器(sram)、只读存储器(rom)、电可擦除可编程只读存储器(eeprom)、可编程只读存储器(prom)、磁性存储器、磁盘、光盘等。在一些实施例中,所述存储器可以是所述计算机设备的内部存储单元,例如该计算机设备的硬盘或内存。在另一些实施例中,所述存储器也可以是所述计算机设备的外部存储设备,例如该计算机设备上配备的插接式硬盘,智能存储卡(smart media card,smc),安全数字(secure digital,sd)卡,闪存卡(flash card)等。当然,所述存储器还可以既包括所述计算机设备的内部存储单元也包括其外部存储设备。本实施例中,所述存储器常用于存储安装于所述计算机设备的操作系统和各类应用软件,例如融合通道与关系特征学习的知识蒸馏方法的程序代码等。此外,所述存储器还可以用于暂时地存储已经输出或者将要输出的各类数据。
[0101]
所述处理器在一些实施例中可以是中央处理器(central processing unit,cpu)、控制器、微控制器、微处理器、或其他数据处理芯片。该处理器通常用于控制所述计算机设备的总体操作。本实施例中,所述处理器用于运行所述存储器中存储的程序代码或者处理数据,例如运行所述融合通道与关系特征学习的知识蒸馏方法的程序代码。
[0102]
在一些实施例中,本申请还公开了一种计算机可读存储介质,其特征在于,计算机可读存储介质上存储有计算机程序,计算机程序被处理器执行时实现上述融合通道与关系特征学习的知识蒸馏方法的步骤。
[0103]
其中,所述计算机可读存储介质存储有界面显示程序,所述界面显示程序可被至少一个处理器执行,以使所述至少一个处理器执行如上述的融合通道与关系特征学习的知识蒸馏方法的程序代码的步骤。
[0104]
通过以上的实施方式的描述,本领域的技术人员可以清楚地了解到上述实施例方法可借助软件加必需的通用硬件平台的方式来实现,当然也可以通过硬件,但很多情况下前者是更佳的实施方式。基于这样的理解,本申请的技术方案本质上或者说对现有技术做出贡献的部分可以以软件产品的形式体现出来,该计算机软件产品存储在一个存储介质(如rom/ram、磁碟、光盘)中,包括若干指令用以使得一台终端设备(可以是手机,计算机,服务器或者网络设备等)执行本申请各个实施例所述的方法。
[0105]
如上即为本发明的实施例。上述实施例以及实施例中的具体参数仅是为了清楚表述发明的验证过程,并非用以限制本发明的专利保护范围,本发明的专利保护范围仍然以其权利要求书为准,凡是运用本发明的说明书及附图内容所作的等同结构变化,同理均应包含在本发明的保护范围内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1