一种数据传输方法、数据处理方法及相关产品与流程
1.本技术涉及计算机技术领域,尤其涉及一种数据传输方法、数据处理方法及相关产品。
背景技术:
2.随着人工智能、云计算等技术的快速发展,计算机集群的应用也越来越广泛。计算机集群是由一组相互独立的计算机利用高速通信网络组成的一个计算机系统。计算机集群在处理突发业务时,可能出现以下情况:该集群中的某些计算节点不堪重负,而某些计算节点却资源过剩,这将影响业务的处理进度。因此,如何在计算机集群中实现跨计算节点的资源共享是一个亟需解决的问题。
技术实现要素:
3.本技术提供了一种数据传输方法、数据处理方法及相关产品,能够在计算机集群中实现跨计算节点的资源共享。
4.第一方面,本技术提供了一种数据传输方法,应用于计算机系统,该计算机系统包括第一计算节点和第二计算节点,第一计算节点包括第一设备和第一内存,第二计算节点包括第二设备和第二内存,第一内存包括第一内存空间,第二内存包括第二内存空间,上述方法包括以下步骤:
5.第一设备获取跨节点读指令,跨节点读指令用于指示第一设备从第二内存空间中读取第一数据,跨节点读指令包括第一源地址和第一数据的大小,第一源地址为第二内存空间的虚拟地址,第一设备存储有第一对应关系,第一对应关系包括第二内存空间的虚拟地址与第二计算节点的id之间的对应关系;
6.第一设备根据第二内存空间的虚拟地址和第一对应关系,确定第二计算节点的id;
7.第一设备根据第二计算节点的id和跨节点读指令,得到第一网络传输报文,并将第一网络传输报文发送至第二设备,第一网络传输报文包括第二内存空间的虚拟地址和第一数据的大小;
8.第二设备接收第一网络传输报文,从第二内存空间中读取第一数据,并将第一数据发送至第一设备。
9.实施第一方面所描述的方法,第一设备可以从第二计算节点的内存(即第二内存空间)中读取第一数据,实现了跨计算节点的数据传输,从而实现跨计算节点的内存资源共享。而且,第一设备中存储有第一对应关系,第一设备根据第一对应关系可以获得第一网络传输报文,并将第一网络传输报文发送至第二设备,这一过程可以绕过第一计算节点的cpu和操作系统,因此,利用上述方法还能够提高跨计算节点的数据传输效率。
10.在一种可能的实现方式中,上述计算机系统中的计算节点共享内存资源池中的资源,内存资源池包括上述第一内存和第二内存。通过建立内存资源池,计算机系统中的任意
一个计算节点可以使用其他计算节点的内存资源,从而解决因单个计算节点的内存配置不满足实际需求而影响任务执行进度的问题。
11.在一种可能的实现方式中,上述第一计算节点还包括第一处理器,上述方法还包括:第一处理器对内存资源池的地址空间进行编址,得到内存资源池的全局虚拟地址;第一计算节点通过全局虚拟地址访问内存资源池的存储空间。如此,计算机系统中的任意一个计算节点可以获得其他计算节点的内存空间的地址,从而可以使用其他计算节点的内存资源。
12.在一种可能的实现方式中,上述第一设备获取跨节点读指令,包括:第一处理器从内存资源池获得与上述第一数据对应的第一内存空间的虚拟地址和第二内存空间的虚拟地址,生成上述跨节点读指令,然后,第一处理器将跨节点读指令发送至第一设备。在另一种可能的实现方式中,上述第一设备获取跨节点读指令,包括:第一设备从内存资源池获得与上述第一数据对应的第一内存空间的虚拟地址和第二内存空间的虚拟地址,生成上述跨节点读指令。可以看出,上述跨节点读指令可以是第一处理器生成的,也可以是第一设备生成的。当第一处理器的负载过重或第一处理器需要优先处理其他任务时,第一设备可以自行生成跨节点读指令,无需等待第一处理器生成跨节点读指令,从而提高第一设备从第二内存空间读取第一数据的效率。
13.在一种可能的实现方式中,上述跨节点读指令还包括第一目的地址,第一目的地址为第一内存空间的虚拟地址,上述方法还包括:第一设备接收第一数据,然后根据第一内存空间的虚拟地址,将第一数据写入第一内存空间。如此,第一设备可以将从第二内存空间中读取的数据写入第一内存空间。
14.在一种可能的实现方式中,上述第一对应关系包括内存资源池的全局虚拟地址、内存资源池的存储空间的物理地址以及内存资源池关联的各个计算节点的id之间的对应关系,上述第一设备根据第一内存空间的虚拟地址,将第一数据写入第一内存空间,包括:第一设备根据第一对应关系和第一内存空间的虚拟地址,确定第一内存空间的物理地址,然后通过直接内存访问(direct memory access,dma)方式将第一数据写入第一内存空间。如此,可以提高第一设备将第一数据写入第一内存空间的速度。
15.在一种可能的实现方式中,上述第二设备存储有上述第一对应关系,上述第二设备接收第一网络传输报文,从第二内存空间中读取第一数据,包括:第二设备接收第一网络传输报文,获得第二内存空间的虚拟地址,然后根据第一对应关系和第二内存空间的虚拟地址,确定第二内存空间的物理地址,然后通过dma方式从第二内存空间中读取第一数据。如此,可以提高第二设备从第二内存空间中读取第一数据的速度。而且,第二设备中存储有第一对应关系,使得第二设备可以根据第一对应关系确定第二内存空间的物理地址,从而从第二内存空间中读取第一数据,这一过程绕开了第二计算节点的cpu和操作系统,因此,利用上述方法还能够提供跨计算节点的数据传输效率。
16.在一种可能的实现方式中,上述第一内存还包括第三内存空间,上述第二内存还包括第四内存空间,上述方法还包括:第一设备获取跨节点写指令,跨节点写指令用于指示第一设备向第三内存空间中写入第二数据,跨节点写指令包括第二源地址、第二目的地址以及第二数据的大小,第二源地址为第三内存空间的虚拟地址,第二目的地址为第四内存空间的虚拟地址;第一设备根据上述第一对应关系和第三内存空间的虚拟地址,确定第三
内存空间的物理地址;第一设备通过dma方式从第三内存空间中读取第二数据;第一设备根据第一对应关系和第四内存空间的虚拟地址,确定第二计算节点的id;第一设备根据第二计算节点的id和跨节点写指令,得到第二网络传输报文,并将第二网络传输报文发送至第二设备,其中,第二网络传输报文包括第四内存空间的虚拟地址和上述第二数据;第二设备接收第二网络传输报文,将第二数据写入第四内存空间。
17.实施上述实现方式所描述的方法,第一设备可以向第二计算节点的内存(即第四内存空间)中写入第二数据,实现了跨计算节点的数据传输,从而实现跨计算节点的内存资源共享。而且,第一设备中存储有第一对应关系,第一设备根据第一对应关系可以获得第二数据,并将第二数据发送至第二设备。这一过程绕开了第一计算节点的cpu和操作系统,因此,利用上述方法能够提高跨计算节点的数据传输效率。
18.第二方面,本技术提供了一种数据处理方法,应用于计算机系统,该计算机系统包括第一计算节点和第二计算节点,第一计算节点包括第一设备,第二计算节点包括第二设备,上述方法包括:
19.第一设备获取跨节点加速指令,跨节点加速指令用于指示第一设备使用第二设备来处理第三数据,跨节点读指令包括第二设备的id和目标加速功能id,第一设备存储有第二对应关系,第二对应关系包括第二设备的id与第二计算节点的id之间的对应关系;
20.第一设备根据第二设备的id和第二对应关系,确定第二计算节点的id;
21.第一设备根据第二计算节点的id和跨节点加速指令,得到第三网络传输报文,并将第三网络传输报文发送至第二设备,第三网络传输报文包括上述目标加速功能id;
22.第二设备根据目标加速功能id,对第三数据进行相应的处理;
23.第二设备将第三数据的处理结果发送至第一计算节点。
24.实施第二方面所描述的方法,第一设备可以使用第二计算节点中的第二设备来处理第三数据,实现了跨计算节点的数据处理,从而实现跨计算节点的计算资源共享。而且,第一设备中存储有第二对应关系,第一设备根据第二对应关系可以获得第三网络传输报文,并将第三网络传输报文发送至第二设备,这一过程可以绕开第一计算节点的cpu和操作系统,因此,利用上述方法还能够提供跨计算节点的数据处理效率。
25.在一种可能的实现方式中,上述计算机系统中的计算节点共享计算资源池中的资源,计算资源池包括上述第二设备。通过建立计算资源池,计算机系统中的任意一个计算节点可以使用其他计算节点的计算资源,从而可以在上述计算机系统中实现全局的负载均衡,提高任务的处理效率。
26.在一种可能的实现方式中,上述第一计算节点还包括第一处理器,上述方法还包括:第一处理器对上述计算资源池中的加速设备及每个加速设备的加速功能进行编号,得到多个加速设备id以及每个加速设备id对应的加速功能id;第一计算节点通过多个加速设备id以及每个加速设备id对应的加速功能id,使用上述计算资源池中的加速设备对第三数据进行处理。如此,计算机系统中的任意一个计算节点可以获得其他计算节点的计算资源的信息,从而可以使用其他计算节点的计算资源。
27.在一种可能的实现方式中,上述第一设备获取跨节点加速指令,包括:第一处理器从计算资源池获得与上述第三数据对应的第二设备的id以及目标加速功能id,生成跨节点加速指令,然后将跨节点加速指令发送至第一设备。在另一种可能的实现方式中,上述第一
设备获取跨节点加速指令,包括:第一设备从计算资源池获得与上述第三数据对应的第二设备的id以及目标加速功能id,生成跨节点加速指令。可以看出,上述跨节点加速指令可以是第一处理器生成的,也可以是第一设备生成的。当第一处理器的负载过重或第一处理器需要优先处理其他任务时,第一设备可以自行生成上述跨节点加速指令,无需等待第一处理器生成跨节点加速指令,从而提高数据处理的效率。
28.在一种可能的实现方式中,上述跨节点加速指令还包括第三源地址和第三目的地址,第三源地址为存储有第三数据的设备存储空间的地址,第三目的地址为将第三数据的处理结果写入的设备存储空间的地址。
29.在一种可能的实现方式中,上述第三源地址为第一设备的存储空间的地址,在第二设备根据目标加速功能id,对第三数据进行相应的处理之前,上述方法还包括:第一设备根据跨节点加速指令,获得第三源地址,然后从第一设备的存储空间中读取第三数据,然后将第三数据发送至第二设备。
30.在另一种可能的实现方式中,上述第三源地址为第二设备的存储空间的地址,上述第三网络传输报文还包括第三源地址,在第二设备根据目标加速功能id,对第三数据进行相应的处理之前,上述方法还包括:第二设备根据第三网络传输报文,获取第三源地址,然后从第二设备的存储空间中读取第三数据。
31.可以看出,上述第三数据可以存储在第一设备的设备存储空间,还可以存储在第二设备的设备存储空间,利用本技术提供的数据处理方法均能够使用第二设备对第三数据进行处理。
32.第三方面,本技术提供了一种计算机系统,该计算机系统包括第一计算节点和第二计算节点,第一计算节点包括第一设备和第一内存,第二计算节点包括第二设备和第二内存,第一内存包括第一内存空间,第二内存包括第二内存空间,
33.第一设备用于获取跨节点读指令,跨节点读指令包括第一源地址和第一数据的大小,第一源地址为第二内存空间的虚拟地址,第一设备存储有第一对应关系,第一对应关系包括第二内存空间的虚拟地址与第二计算节点的id之间的对应关系;
34.第一设备还用于根据第二内存空间的虚拟地址和第一对应关系,确定第二计算节点的id;
35.第一设备还用于根据第二计算节点的id和跨节点读指令,得到第一网络传输报文,并将第一网络传输报文发送至第二设备,第一网络传输报文包括第二内存空间的虚拟地址和第一数据的大小;
36.第二设备用于接收第一网络传输报文,从第二内存空间中读取第一数据,并将第一数据发送至第一设备。
37.在一种可能的实现方式中,上述计算机系统中的计算节点共享内存资源池中的资源,内存资源池包括上述第一内存和上述第二内存。
38.在一种可能的实现方式中,上述第一计算节点还包括第一处理器,第一处理器用于对上述内存资源池的地址空间进行编址,得到内存资源池的全局虚拟地址;第一计算节点用于通过全局虚拟地址访问内存资源池的存储空间。
39.在一种可能的实现方式中,上述第一处理器还用于从上述内存资源池获得与上述第一数据对应的第一内存空间的虚拟地址和第二内存空间的虚拟地址,生成跨节点读指
令;第一处理器还用于将跨节点读指令发送至第一设备。
40.在一种可能的实现方式中,上述第一设备具体用于:从上述内存资源池获得与上述第一数据对应的第一内存空间的虚拟地址和第二内存空间的虚拟地址,生成跨节点读指令。
41.在一种可能的实现方式中,上述跨节点读指令还包括第一目的地址,第一目的地址为第一内存空间的虚拟地址,第一设备还用于接收第一数据;第一设备还用于根据第一内存空间的虚拟地址,将第一数据写入第一内存空间。
42.在一种可能的实现方式中,上述第一对应关系包括上述内存资源池的全局虚拟地址、内存资源池的存储空间的物理地址以及内存资源池关联的各个计算节点的id之间的对应关系,第一设备具体用于:根据第一对应关系和第一内存空间的虚拟地址,确定第一内存空间的物理地址,然后通过dma方式将第一数据写入第一内存空间。
43.在一种可能的实现方式中,第二设备存储有上述第一对应关系,第二设备具体用于:接收第一网络传输报文,获得第二内存空间的虚拟地址,然后根据第一对应关系和第二内存空间的虚拟地址,确定第二内存空间的物理地址,然后通过dma方式从第二内存空间中读取第一数据。
44.在一种可能的实现方式中,上述第一内存还包括第三内存空间,上述第二内存还包括第四内存空间,上述第一设备还用于获取跨节点写指令,跨节点写指令用于指示第一设备向第四内存空间中写入第二数据,跨节点写指令包括第二源地址、第二目的地址以及第二数据的大小,第二源地址为第三内存空间的虚拟地址,第二目的地址为第四内存空间的虚拟地址;第一设备还用于根据第一对应关系和第三内存空间的虚拟地址,确定第三内存空间的物理地址;第一设备还用于通过dma方式从第三内存空间中读取第二数据;第一设备还用于根据第一对应关系和第四内存空间的虚拟地址,确定第二计算节点的id;第一设备还用于根据第二计算节点的id和跨节点写指令,得到第二网络传输报文,并将第二网络传输报文发送至第二设备,其中,第二网络传输报文包括第四内存空间的虚拟地址和第二数据;第二设备还用于接收第二网络传输报文,将第二数据写入第四内存空间。
45.第四方面,本技术还提供了一种计算机系统,该计算机系统包括第一计算节点和第二计算节点,第一计算节点包括第一设备,第二计算节点包括第二设备,
46.第一设备用于获取跨节点加速指令,跨节点加速指令用于指示第一设备使用第二设备来处理第三数据,跨节点加速指令包括第二设备的id和目标加速功能id,第一设备存储有第二对应关系,第二对应关系包括第二设备的id与第二计算节点的id之间的对应关系;
47.第一设备还用于根据第二设备的id和第二对应关系,确定第二计算节点的id;
48.第一设备还用于根据第二计算节点的id和跨节点加速指令,得到第三网络传输报文,并将第三网络传输报文发送至第二设备,第三网络传输报文包括目标加速功能id;
49.第二设备还用于根据目标加速功能id,对第三数据进行相应的处理;
50.第二设备用于将第三数据的处理结果发送至第一计算节点。
51.在一种可能的实现方式中,上述计算机系统中的计算节点共享计算资源池中的资源,计算资源池包括上述第二设备。
52.在一种可能的实现方式中,上述第一计算节点还包括第一处理器,第一处理器用
于对上述计算资源池中的加速设备及每个加速设备的加速功能进行编号,得到多个加速设备id以及每个加速设备id对应的加速功能id;第一计算节点用于通过多个加速设备id以及每个加速设备id对应的加速功能id,使用计算资源池中的加速设备对第三数据进行处理。
53.在一种可能的实现方式中,上述第一处理器还用于从上述计算资源池获得与上述第三数据对应的第二设备的id以及目标加速功能id,生成跨节点加速指令;第一处理器还用于将跨节点加速指令发送至第一设备。
54.在一种可能的实现方式中,第一设备具体用于:从上述计算资源池获得与上述第三数据对应的第二设备的id以及目标加速功能id,生成跨节点加速指令。
55.在一种可能的实现方式中,上述跨节点加速指令还包括第三源地址和第三目的地址,第三源地址为存储有上述第三数据的设备存储空间的地址,第三目的地址为将上述第三数据的处理结果写入的设备存储空间的地址。
56.在一种可能的实现方式中,上述第三源地址为第一设备的存储空间的地址,第一设备具体用于:根据跨节点加速指令,获得第三源地址,然后从第一设备的存储空间中读取第三数据,然后将第三数据发送至第二设备。
57.在一种可能的实现方式中,上述第三源地址为第二设备的存储空间的地址,上述第三网络传输报文还包括第三源地址,第二设备还用于:根据第三网络传输报文,获取第三源地址,然后从第二设备的存储空间中读取第三数据。
58.第五方面,本技术提供了一种计算机可读存储介质,存储有第一计算机指令和第二计算机指令,第一计算机指令和第二计算指令分别运行在第一计算节点和第二计算节点上,以执行前述第一方面、第一方面的任意一种可能的实现方式、第二方面、第二方面的任意一种可能的实现方式中的方法,从而实现第一计算节点与第二计算节点之间的数据处理。
附图说明
59.图1是本技术提供的一种计算机系统的结构示意图;
60.图2是本技术提供的一种内存资源池及第一对应关系的示意图;
61.图3是本技术提供的一种数据传输方法的流程示意图;
62.图4是本技术提供的一种跨节点读指令的格式的示意图;
63.图5是本技术提供的另一种数据传输方法的流程示意图;
64.图6是本技术提供的另一种计算机系统的结构示意图;
65.图7是本技术提供的一种第二对应关系的示意图;
66.图8是本技术提供的一种数据处理方法的流程示意图;
67.图9是本技术提供的一种跨节点加速指令的格式的示意图。
具体实施方式
68.为了便于理解本技术提供的技术方案,首先介绍本技术适用的应用场景:计算机系统(例如,集群)的资源共享。
69.本技术中,计算机系统包括两个或两个以上的计算节点(即计算机),计算机系统的资源包括两个方面:一方面是内存资源,即该系统中所有计算节点拥有的内存资源;另一
方面是计算资源,即该系统中所有计算节点拥有的计算资源。计算机系统的资源共享包括该系统的内存资源的共享,以及该系统的计算资源的共享。
70.计算机系统的内存资源的共享旨在构建一个内存资源池,如此,当计算机系统中的某个计算节点的内存资源不够用时,该计算节点可以把其他计算节点的内存当作磁盘或缓存,以用于存储一些数据,当该计算节点需要使用这些数据时,再从其他计算节点的内存中读取数据,从而解决因单个计算节点的内存配置不满足实际需求而影响任务执行进度的问题。
71.计算机系统的计算资源的共享旨在构建一个计算资源池,如此,当计算机系统中的某个计算节点的负载过重时,该计算节点可以使用其他计算节点的算力来处理一部分需要由本计算节点完成的任务,从而在计算机系统范围内实现全局负载均衡,以加快任务的完成进度。本技术实施例中,计算机系统的计算资源的共享具体是指计算机系统的加速资源的共享。加速资源是指加速计算能力,可以由加速设备提供。加速设备是一类能够减轻计算节点中cpu的工作量,并提高计算节点处理任务的效率的硬件,例如,专门用于进行图像和图形相关运算工作的图形处理器(graphics processing unit,gpu)、专门用于处理视频和图像类的海量多媒体数据的神经网络处理器(neural-network processing units,npu),数据流加速器(data stream accelerator,dsa)等。因此,计算机系统的加速资源的共享可以理解为:当计算机系统中的某个计算节点上的加速设备的负载过重时,可以将一些计算任务分配给该系统中的其他计算节点上的加速设备来执行,从而减轻该计算节点的cpu和加速设备的工作量,提高计算任务的完成效率。
72.本技术提供了一种数据传输方法,该方法可以由计算机系统执行,当在计算机系统中执行该方法时,能够实现跨计算节点的数据传输,从而在该系统中实现内存资源的共享。下面将结合图1示出的计算机系统介绍本技术提供的数据传输方法。
73.如图1所示,图1示出了本技术提供的一种计算机系统的结构示意图。其中,计算机系统100包括第一计算节点110和第二计算节点120。第一计算节点110包括第一处理器111、第一设备112以及第一内存113,第一处理器111包括第一资源管理器1111,第一设备112包括第一管理单元1121。第二计算节点120包括第二处理器121、第二设备122以及第二内存123,第二处理器121包括第二资源管理器1211,第二设备122包括第二管理单元1221。
74.第一计算节点110:
75.第一处理器111可以包括中央处理器(central processing unit,cpu),也可以包括专用集成电路(application specific integrated circuit,asic),或可编程逻辑器件(programmable logic device,pld),上述pld可以是复杂程序逻辑器件(complex programmable logical device,cpld),现场可编程逻辑门阵列(field programmable gate array,fpga),通用阵列逻辑(generic array logic,gal)或其任意组合。
76.第一设备112是第一计算节点110上的外部设备。第一设备112可以是gpu、npu、dsa、张量处理器(tensor processing unit,tpu)、人工智能(artificial intelligent)芯片、网卡、数据处理器(data processing unit,dpu)或者一个或多个集成电路。
77.可选的,第一处理器111和第一设备112之间可以通过快捷外围部件互连标准(peripheral component interconnect express,pcie)连接,也可以通过计算快速链接(compute express link,cxl)连接。第一处理器111和第一设备112之间还可以通过其他总
线连接,例如:外围部件互连标准(peripheral component interconnect,pci)、通用串行总线(universal serial bus,usb)等,此处不作具体限定。
78.第一内存113为第一计算节点110中的内存,用于存储第一计算节点110的cpu中的数据,以及与第一计算节点110上的外部存储器(例如,第一设备112的存储器)交换数据。
79.第一资源管理器1111是第一计算节点110中管理计算机系统100中所有计算节点拥有的内存资源的部件。具体地,第一资源管理器1111用于构建内存资源池,内存资源池包括第一内存113和第二内存123。第一资源管理器1111还用于对内存资源池的地址空间进行编址,得到内存资源池的全局虚拟地址。第一资源管理器1111还用于构建第一对应关系,并将第一对应关系配置到第一管理单元1121。其中,第一对应关系是指上述全局虚拟地址、内存资源池的存储空间的物理地址、以及内存资源池关联的各个计算节点的id(即提供上述存储空间的计算节点的id)之间的对应关系。
80.本技术实施例中,第一资源管理器1111对内存资源池的内存地址空间进行编址是指:将第一内存113提供的离散的内存地址空间和第二内存123提供的离散的内存地址空间编辑成一个虚拟的、线性连续的内存地址空间。计算机系统100中的计算节点共享内存资源池中的资源,并且通过上述全局虚拟地址访问内存资源池的存储空间。
81.以图1示出的计算机系统100为例,对第一资源管理器1111进行说明:
82.第一计算节点110拥有的内存资源为第一内存113提供的内存空间(例如,图1所示的第一内存空间、第三内存空间),第二计算节点120拥有的内存资源为第二内存123提供的内存空间(例如,图1所示的第二内存空间、第四内存空间)。那么,第一资源管理单元114用于获取第一内存113和第二内存123的内存信息,其中,第一内存113的内存信息包括第一内存空间的物理地址、第三内存空间的物理地址,第二内存123的内存信息包括第二内存空间的物理地址、第四内存空间的物理地址。
83.可选的,第一内存113的内存信息还包括第一内存113提供的内存空间的大小(包括第一内存113中可用的内存空间大小、已用的内存空间大小),第一内存113中已用的内存空间的物理地址、可用的内存空间的物理地址等。第二内存123的内存信息还包括第二内存123提供的内存空间的大小(包括第二内存123中可用的内存空间大小、已用的内存空间大小),第二内存123中已用的内存空间的物理地址、可用的内存空间的物理地址等。
84.第一资源管理器1111还用于将第一内存113提供的内存空间和第二内存123提供的内存空间连接成一个内存空间,得到内存资源池,内存资源池包括第一内存空间、第二内存空间、第三内存空间以及第四内存空间。然后,对内存资源池的内存地址空间进行编址,得到全局虚拟地址,全局虚拟地址包括第一内存空间的虚拟地址、第二内存空间的虚拟地址、第三内存空间的虚拟地址以及第四内存空间的虚拟地址。
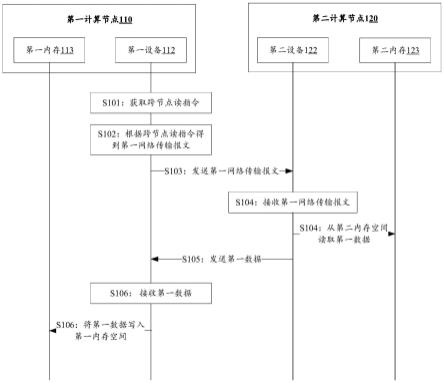
85.第一资源管理器1111还用于构建第一对应关系,并将第一对应关系配置到第一管理单元1121。其中,第一对应关系包括第一内存空间的虚拟地址、第一内存空间的物理地址以及第一计算节点110的id之间的对应关系,第二内存空间的虚拟地址、第二内存空间的物理地址以及第二计算节点120的id之间的对应关系,第三内存空间的虚拟地址、第三内存空间的物理地址以及第一计算节点110的id之间的对应关系,第四内存空间的虚拟地址、第四内存空间的物理地址以及第二计算节点120的id之间的对应关系。
86.举例说明,假设第一内存空间的物理地址为100:200,第三内存空间的物理地址为
300:350,第二内存空间的物理地址为110:210,第四内存空间的物理地址为400:500,那么,第一资源管理器1111通过上述方式可以得到如图2所示的内存资源池和第一对应关系。
87.第二计算节点120:
88.第二处理器121可以包括cpu,也可以包括asic、pld,上述pld可以是cpld、fpga、gal或其任意组合。
89.第二设备122是第二计算节点120上的外部设备。第二设备122可以是gpu、npu、dsa、tpu、人工智能(artificial intelligent)芯片、网卡、dpu或者一个或多个集成电路。
90.可选的,第二处理器121和第二设备122之间可以通过pcie连接,也可以通过cxl连接,还可以通过pci、usb等连接,此处不作具体限定。
91.第二内存123为第二计算节点120中的内存,用于存储第二计算节点120的cpu中的数据,以及与第二计算节点120上的外部存储器(例如,第二设备122的存储器)交换数据。
92.第二资源管理器1211是第二计算节点120中用于管理计算机系统100中所有计算节点拥有的内存资源的部件。可选的,第二资源管理器1211可以采用与第一资源管理器1111类似的方式来管理计算机系统100中所有计算节点拥有的内存资源,此处不再展开叙述。第二资源管理器1211也可以通过以下方式管理计算机系统100中所有计算节点拥有的内存资源:第一资源管理器1111得到全局虚拟地址以及第一对应关系后,将全局虚拟地址以及第一对应关系发送至第二资源管理器1211,然后,第二资源管理器1211将第一对应关系发送至第二管理单元1221。
93.本技术实施例中,第一计算节点110和第二计算节点120之间能够通过第一设备112和第二设备122进行通信。可选的,第一设备112和第二设备122之间可以通过有线接口或无线接口进行连接。其中,有线接口可以是以太网接口、控制器局域网接口、局域互联网络(local interconnect network,lin)接口等,无线接口可以是蜂窝网络接口、无线局域网接口等,此处不作具体限定。
94.下面以第一计算节点110从第二计算节点120的内存中读取数据、以及第一计算节点110向第二计算节点120的内存中写入数据为例,介绍上述计算机系统100如何实现跨计算节点的内存资源的共享。
95.(一)第一计算节点110从第二计算节点120的内存中的读取数据
96.如图3所示,图3示出了本技术提供的一种数据传输方法的流程示意图。该方法包括但不限于如下步骤:
97.s101:第一设备112获取跨节点读指令。
98.其中,跨节点读指令用于指示第一设备112从第二内存空间中读取第一数据。本技术实施例中,跨节点读指令可以是一个原子指令(atomic instruction),例如,arm的st64bv指令、st64bv0指令,x86的enqcmd指令、enqcmds指令等。原子指令是用于指示设备执行原子操作(atomic operation)的命令,原子操作是一种不会被线程调度机制打断的操作。因此,原子指令可以理解为一旦被执行就不会被打断,直至运行完毕的指令。
99.在一具体的实施例中,跨节点读指令包括第一源地址、第一目的地址以及第一数据的大小。其中,第一源地址为存储有第一数据的内存空间的虚拟地址,此处为第二内存空间的虚拟地址;第一目的地址为读取到第一数据后,将第一数据写入的内存空间的虚拟地址,此处为第一内存空间的虚拟地址;第一数据的大小可以是第一数据的字节数。
100.应理解,上述第一源地址、第一目的地址以及第一数据的大小在跨节点读指令中的位置可以根据实际情况进行分配。还应理解,上述跨节点读指令还可以包括第一操作描述信息等其他信息,第一操作描述信息用于描述跨节点读指令,从而指示接收到该指令的第一设备112从第一源地址对应的内存空间中读取第一数据,并将读取到的第一数据写入第一目的地址。以图4为例,跨节点读指令为一个64位的指令,跨节点读指令中的第0-7字节用于填写第一源地址,第8-15字节用于填写第一目的地址,第16-21字节用于填写第一数据的大小,第22-64字节用于填写跨节点读指令所包含的其他信息,例如,上述第一操作描述信息。图4示出了一种示例性的跨节点读指令的格式,跨节点读指令的格式还可以是其他的格式,本技术不作具体限定。
101.在一种可能的实现方式中,第一设备112获取跨节点读指令,包括:第一处理器111从内存资源池获得与第一数据对应的第一内存空间的虚拟地址、第二内存空间的虚拟地址,生成跨节点读指令,并发送至第一设备112。
102.在另一种可能的实现方式中,第一设备112获取跨节点读指令,包括:第一设备112从内存资源池获得与第一数据对应的第一内存空间的虚拟地址、第二内存空间的虚拟地址,生成跨节点读指令。
103.s102:第一设备112根据跨节点读指令得到第一网络传输报文。
104.具体地,第一设备112接收到跨节点读指令后,对跨节点读指令进行解析,获得第一源地址和第一数据的大小。然后,第一设备111根据第一源地址和第一管理单元1121中存储的第一对应关系,确定第二计算节点120的id。然后,第一设备111根据第二计算节点120的id和跨节点读指令,得到第一网络传输报文,其中,第一网络传输报文包括第一源地址和第一数据的大小,以及第一源ip地址和第一目的ip地址,第一源ip地址为第一计算节点110的ip地址,第一目的ip地址为第二计算节点120的ip地址。
105.可选的,第二计算节点120的id可以是第二计算节点120的ip地址,也可以是用于指示第二计算节点120的编号。当第二计算节点120的id是第二计算节点120的ip地址时,第一设备112根据第二计算节点120的id和跨节点读指令,得到第一网络传输报文,包括:第一设备112根据第一计算节点110的ip地址和第二计算节点120的id,对第一源地址和第一数据的大小进行封装,得到第一网络传输报文。当第二计算节点120的id是用于指示第二计算节点120的编号时,第一设备112根据第二计算节点120的id和跨节点读指令,得到第一网络传输报文,包括:第一设备112根据第二计算节点120的id,确定第二计算节点120的ip地址,然后根据第一计算节点110的ip地址和第二计算节点120的ip地址,对第一源地址和第一数据的大小进行封装,得到第一网络传输报文。
106.可选的,第一设备112还可以通过以下方式中的任意一种得到第一网络传输报文:方式1、第一设备111根据第一计算节点110的ip地址和第二计算节点120的ip地址,对第一源地址、第一目的地址以及第一数据的大小进行封装,得到第一网络传输报文。方式2、第一设备111根据第一计算节点110的ip地址和第二计算节点120的ip地址,对跨节点读指令进行封装,得到第一网络传输报文。
107.s103:第一设备112将第一网络传输报文发送至第二设备122。
108.s104:第二设备122接收第一网络传输报文,从第二内存空间中读取第一数据。
109.具体地,第二设备122接收第一网络传输报文,然后对第一网络传输报文进行解
析,获得第一源地址和第一数据的大小。然后,第二设备122根据第一源地址和第二管理单元1221中存储的第一对应关系,确定第二内存空间的物理地址。然后,第二设备122根据第二内存的物理地址,从第二内存空间中读取第一数据。
110.可选的,第二设备122可以通过dma方式从第二内存空间中读取第一数据。其中,dma是一种高速的数据传输方式,当第二设备122通过dma方式从第二内存空间中读取数据时,无需依赖第二计算节点120中的cpu,因此通过这种方式可以减少cpu拷贝数据的开销,从而提高第二设备122从第二内存空间中读取数据的效率。
111.s105:第二设备122将第一数据发送至第一设备112。
112.具体地,第二设备122对第一数据进行封装,得到第二网络传输报文。其中,第二网络传输报文包括第一数据、第二源ip地址以及第二目的ip地址,第二源ip地址为第二计算节点120的ip地址,第二目的ip地址为第一计算节点110的ip地址。然后,第二设备122将第二网络传输报文发送至第一设备112。
113.s106:第一设备112接收第一数据,并将第一数据写入第一内存空间。
114.在一种可能的实现方式中,第一设备112接收到第二网络传输报文,并对第二网络传输报文进行解析,获得第一数据。第一设备112还根据上述跨节点读指令,获得第一目的地址(即第一内存空间的虚拟地址),并根据第一内存空间的虚拟地址和第一管理单元1121中存储的第一关系,确定第一内存空间的物理地址。然后,第一设备112将上述第一数据写入第一内存空间。
115.在另一种可能的实现方式中,上述第二网络传输报文还包括第一内存空间的虚拟地址,那么,第一设备112可以通过以下方式将第一数据写入第一内存空间:第一设备112接收到第二网络传输报文后,对第二网络传输报文进行解析,获得第一数据和第一内存空间的虚拟地址,然后根据第一内存空间的虚拟地址和第一管理单元1121中存储的第一关系,确定第一内存空间的物理地址,然后将第一数据写入第一内存空间。应理解,当第二网络传输报文包括第一内存空间的虚拟地址时,上述第一网络传输报文可以包括第一内存空间的虚拟地址(即第一目的地址),这样,在上述s106中,第二设备122可以对第一数据以及第一内存空间的虚拟地址一起进行封装,从而得到包括第一内存空间的虚拟地址的第二网络传输报文。
116.可选的,第一设备112可以通过dma方式将第一数据写入第一内存空间。如此,可以提高第一设备112向第一内存空间写入第一数据的速度。
117.上述s101-s106描述了第一计算节点110从第二计算节点120的内存中读取数据的过程,应理解,第二计算节点120从第一计算节点110的内存中读取数据的过程与上述s101-s106的过程类似,为了简便,此处不再叙述。
118.通过图3示出的数据传输方法,第一设备112能够将从第二内存空间中读取第一数据,从而在计算机系统100中实现跨计算节点的内存资源共享。而且,在利用上述数据传输方法读取数据时,除了上述s101中可能需要第一处理器111生成跨节点读指令,并发送至第一设备112外,其他步骤均不需要第一处理器111和第二处理器121,也就是说,利用上述数据传输方法可以绕过第一计算节点110和第二计算节点120中的cpu和操作系统,如此,可以提高跨计算节点的数据传输效率,从而提高计算机系统100的内存资源的共享效率。另外,在第一设备112从第二内存空间中读取第一数据的过程中,第二计算节点120的cpu可以执
行其他任务,而如果第一计算节点110的cpu需要生成跨节点读指令,并发送至第一设备112,那么,第一计算节点110的cpu将跨节点读指令发送至第一设备112之后,还可以释放出来执行其它任务,从而减少资源浪费,提供资源利用率。
119.(二)第一计算节点110向第二计算节点120的内存中写入数据
120.如图5所示,图5示出了本技术提供的另一种数据传输方法的流程示意图。
121.s201:第一设备112获取跨节点写指令。
122.其中,跨节点写指令用于指示第一设备112向第四内存空间写入第二数据。与上述跨节点读指令类似的,跨节点写指令也可以是一个原子指令。
123.在一具体的实施例中,跨节点写指令包括第二源地址、第二目的地址以及第二数据的大小。其中,第二源地址为存储有第二数据的内存空间的虚拟地址,此处为第三内存空间的虚拟地址;第二目的地址为将第二数据写入的内存空间的虚拟地址,此处为第四内存空间的虚拟地址;第二数据的大小可以是第二数据的字节数。
124.应理解,上述第二源地址、第二目的地址以及第二数据的大小在跨节点写指令中的位置可以根据实际情况进行分配。还应理解,上述跨节点写指令还可以包括第二操作描述信息等,第二操作描述信息用于描述跨节点写指令,从而指示接收到该指令的第一设备112从第二源地址对应的内存空间中读取第二数据,并将读取到的第二数据写入第二目的地址对应的内存空间。跨节点写指令的具体格式也可以采用如图4示出的跨节点读指令的格式,本技术不作具体限定。
125.在一种可能的实现方式中,第一设备112获取跨节点写指令,包括:第一处理器111从内存资源池获得与第二数据对应的第二源地址和第二目的地址,生成跨节点写指令,并发送至第一设备112。
126.在另一种可能的实现方式中,第一设备112获取跨节点读指令,包括:第一设备112从内存资源池获得与第二数据对应的第二源地址和第二目的地址,生成跨节点写指令。
127.s202:第一设备112根据跨节点写指令获得第二数据。
128.具体地,第一设备112接收到跨节点写指令后,对跨节点写指令进行解析,获得第二源地址和第二数据的大小,然后根据第二源地址和第一管理单元1121中存储的第一对应关系,确定第三内存空间的物理地址。然后,第一设备112根据第二数据的大小,从第三内存空间中读取第二数据。
129.可选的,第一设备112可以通过dma方式从第三内存空间中读取到第二数据,如此,可以提高第一设备获得第二数据的速度。
130.s203:第一设备112根据跨节点写指令得到第三网络传输报文。
131.具体地,第一设备112接收到跨节点写指令后,对跨节点写指令进行解析,获得第二目的地址,然后根据第二目的地址和第一管理单元1121中存储的第一对应关系,确定第二计算节点120的id。然后,第一设备112根据第二计算节点120的id,对第二数据、第二目的地址进行封装,得到第三网络传输报文。其中,第三网络传输报文包括第二数据、第二目的地址、以及第三源ip地址和第三目的ip地址,第三源ip地址为第一计算节点110的ip地址,第三目的ip地址为第二计算节点120的ip地址。
132.可选的,第二计算节点120的id可以是第二计算节点120的ip地址,也可以是用于指示第二计算节点120的编号。当第二计算节点120的id是第二计算节点120的ip地址时,第
一设备112根据第二计算节点120的id,对第二数据、第二目的地址进行封装,得到第三网络传输报文,包括:第一设备112根据第一计算节点110的ip地址和第二计算节点120的id,对第二源地址和第二目的地址进行封装,得到第三网络传输报文。当第二计算节点120的id是用于指示第二计算节点120的编号时,第一设备112根据第二计算节点120的id,对第二数据、第二目的地址进行封装,得到第三网络传输报文,包括:第一设备112根据第二计算节点120的id,确定第二计算节点120的ip地址,然后根据第一计算节点110的ip地址和第二计算节点120的ip地址,对第二数据、第二目的地址进行封装,得到第三网络传输报文。
133.s204:第一设备112将第三网络传输报文发送至第二设备122。
134.s205:第二设备122接收第三网络传输报文,将第二数据写入第四内存空间。
135.具体地,第二设备122接收第三网络传输报文后,对第三网络传输报文进行解析,获得第二数据以及第二目的地址,然后根据第二目的地址和第二管理单元1221中存储的第一对应关系,确定第四内存空间的物理地址。然后,第二设备122通过dma方式将第二数据写入四内存空间。
136.上述s201-s205描述了第一计算节点110向第二计算节点的内存中写入数据的过程,应理解,第二计算节点120向第一计算节点110的内存中写入数据的过程与上述s201-s205类似,为了简便,此处不再叙述。
137.通过图5示出的数据传输方法,第一设备112能够将存储在第三内存空间中的第二数据写入第四内存空间,从而在计算机系统100中实现跨计算节点的内存资源共享。而且,在利用上述数据传输方法在传输数据时,除了上述s201中可能需要第一处理器111生成跨节点写指令,并发送至第一设备112外,其他步骤均不需要第一处理器111和第二处理器121,也就是说,利用上述数据传输方法可以绕过第一计算节点110和第二计算节点120中的cpu和操作系统,如此,可以提高跨计算节点的数据传输效率,从而提高计算机系统100的内存资源的共享效率。另外,在第一设备112向第四内存空间写入第二数据的过程中,第二计算节点120的cpu可以执行其他任务,而如果第一计算节点110的cpu需要生成跨节点写指令,并发送至第一设备112,那么,第一计算节点110的cpu将跨节点写指令发送至第一设备112之后,还可以释放出来执行其它任务,从而减少资源浪费,提供资源利用率。
138.本技术还提供了一种数据处理方法,当在计算机系统中执行该方法时,能够实现跨计算节点的数据处理,从而在该系统中实现计算资源(加速资源)的共享。下面将结合图6示出的计算机系统介绍本技术提供的数据传输方法。
139.如图6所示,图6示出了本技术提供的另一种计算机系统的结构示意图。其中,计算机系统200包括第一计算节点210和第二计算节点220。第一计算节点210包括第一处理器211、第一设备212以及第一内存213,第一处理器211包括第一资源管理器2111,第一设备212包括第一管理单元2121。第二计算节点220包括第二处理器221、第二设备222以及第二内存223,第二处理器221包括第二资源管理器2211,第二设备222包括第二管理单元2221。相较于图1示出的计算机系统100,图6示出的计算机系统200中:
140.第一设备212和第二设备222分别是第一计算节点210和第二计算节点220上的外部设备。第一设备212和第二设备222均具有计算能力。本技术实施例中,第一设备212和第二设备222具有的计算能力均可以是加速计算能力,那么,第一设备212和第二设备222分别是第一计算节点210和第二计算节点220中的加速设备。可选的,第一设备212或第二设备
222可以是gpu、npu、dsa、tpu、人工智能(artificial intelligent)芯片、网卡、dpu或者一个或多个集成电路。
141.可选的,第一设备212和第二设备222均可以具有一种或多种加速功能,例如,用于加速数据完整性校验过程的功能,用于加速数据加密、解密过程的功能,用于加速数据压缩、解压缩过程的功能,用于加速机器学习过程的功能,用于加速数据分类过程的功能,用于加速深度学习过程的功能,用于加速浮点计算的功能等。
142.可选的,第一设备212也可以不具有计算能力。
143.第一资源管理器2111是第一计算节点210中用于管理计算机系统200中所有计算节点拥有的计算资源的部件。具体地,第一资源管理器2111用于构建计算资源池,计算资源池包括第二设备222。可选的,当第一设备212也具有计算能力时,计算资源池还包括第一设备212。第一资源管理器2111还用于将计算机系统200中所有计算节点包括的加速设备和每个加速设备具有的加速功能进行编号,得到多个加速设备id以及每个加速设备id对应的加速功能id。第一资源管理器2111还用于构建第二对应关系,并将第二对应关系配置到第一管理单元2121。第二对应关系是指计算资源池中的加速设备的id、每个加速设备具有的加速功能的id以及计算资源池关联的各个计算节点的id(即加速设备所在的计算节点的id)之间的对应关系。
144.本技术实施例中,计算机系统200中的计算节点共享计算资源池中的资源,并且能够通过上述多个加速设备id以及每个加速设备id对应的加速功能id,使用计算资源池中的加速设备来处理数据。
145.以图6示出的计算机系统200为例,对第一资源管理器2111进行说明:
146.第一计算节点210拥有的计算资源包括第一设备212提供的加速计算的能力,第二计算节点220拥有的计算资源包括第二设备222提供的加速计算的能力。那么,第一资源管理器2111用于获取第一设备212和第二设备222的加速计算能力的信息,其中,第一设备212的加速计算能力信息包括第一设备212具有的加速功能,第二设备222的加速计算能力信息包括第二设备222具有的加速功能。可选的,第一设备212的加速计算能力信息还包括第一设备212已用的算力和可用的算力,第二设备222的加速计算能力信息还包括第二设备222已用的算力和可用的算力。
147.第一资源管理器2111还用于对第一设备212和第二设备222进行编号,得到第一设备212的id和第二设备222的id,以及对第一设备212具有的加速功能和第二设备222具有的加速功能进行编号,得到每种加速功能的id。
148.第一资源管理器2111还用于构建第二对应关系,并将第二对应关系配置到第一管理单元2121。其中,第二对应关系包括第一设备212的id、第一设备212具有的加速功能的id以及第一计算节点210的id之间的对应关系,以及第二设备222的id、第二设备222具有的加速功能的id以及第二计算节点220的id之间的对应关系。
149.举例说明,第一设备212提供的加速功能包括用于加速机器学习过程的功能和用于加速数据加密、解密过程的功能,第二设备222提供的加速功能包括用于加速机器学习过程的功能和用于加速数据压缩、解压缩过程的功能。那么,第一资源管理器2111可以将第一设备212编号为1,将第二设备222编号为2,将加速机器学习过程的功能编号为1,将加速数据加密、解密过程的功能编号为2,将加速数据压缩、解压缩过程的功能编号为3,将第一计
算节点编号为1,将第二计算节点编号为2,从而得到如图7所示的第二对应关系。
150.第二资源管理器2211是第二计算节点220中用于管理计算机系统200中所有计算节点拥有的计算资源。可选的,第二资源管理器2211可以采用与第一资源管理器2111类似的方式来管理计算机系统200中所有计算节点拥有的内存资源,此处不再展开叙述。第二资源管理器2211也可以通过以下方式管理计算机系统200中所有计算节点拥有的计算资源:第一资源管理器2111将计算资源池的相关信息(例如,计算资源池中每个加速设备具有的加速计算能力的信息)以及第二对应关系发送至第二资源管理器2211,再由第二资源管理器2211将第二对应关系发送至第二管理单元2221。
151.需要说明的,计算机系统200中的第一处理器211、第二处理器221、第一内存213、第二内存223的功能,与计算机系统100中的第一处理器111、第二处理器121、第一内存113、第二内存123的功能类似,计算机系统200中的第一处理器211与第一设备212的连接关系、第二处理器221与第二设备222的连接关系,分别与计算机系统100中的第一处理器111与第一设备112的连接关系、第二处理器121与第二设备122的连接关系类似,为了简便,本技术实施例不再叙述。
152.下面以第一计算节点210使用第二计算节点120的计算资源为例,介绍上述计算机系统200如何实现跨计算节点的计算资源的共享。
153.如图8所示,图8示出了本技术提供的一种数据处理方法的流程示意图。该方法包括但不限于如下步骤:
154.s301:第一设备212获取跨节点加速指令。
155.其中,跨节点加速指令用于指示第一设备212使用第二设备222对第三数据进行处理。与上述跨节点读指令、跨节点写指令类似的,跨节点加速指令也可以是一个原子指令。
156.在一具体的实施例中,跨节点加速指令包括第三源地址、第三目的地址、第三数据的大小、目标加速设备id以及目标加速功能id。其中,第三源地址为存储有第三数据的设备的存储空间的地址,此处为第一存储空间的地址,第一设备212的设备存储空间包括第一存储空间;第三目的地址为将第三数据的处理结果写入的设备存储空间的地址,此处为第二存储空间的地址,第一设备212的设备存储空间还包括第二存储空间;第三数据的大小可以是第三数据的字节数;目标加速设备id为第一设备212使用的、用于处理第三数据的加速设备的id,此处为第二设备的id;目标加速功能id为第二设备222具有的加速功能的id,用于指示第二设备222处理第三数据,例如,当目标加速功能id为数据完整性校验功能对应的id时,第二设备222对第三数据执行数据完整性校验的操作,又例如,当目标加速功能id为数据加密功能对应的id时,第二设备222对第三数据执行数据加密的操作。
157.可选的,跨节点加速指令还包括第三存储空间的地址,第二设备222的设备存储空间包括第三存储空间,第三存储空间的地址为第二设备222接收到第三数据后,存储第三数据的地址。应理解,上述第三源地址、第三目的地址、第三数据的大小、目标加速设备id、目标加速功能id以及第三存储空间的地址在上述跨节点加速指令中的位置可以根据实际情况进行分配。以图9为例,跨节点加速指令为一个64位的指令,跨节点加速指令中的第0-7字节用于填写第三源地址,第8-15字节用于填写第三目的地址,第16-23字节用于填写第三存储空间的地址,第24-27字节用于填写目标加速设备id,第28-31字节用于填写目标加速功能id,第32-37字节用于填写第三数据的大小,第38-64字节用于填写跨节点加速指令所包
含的其他信息,例如,第三操作描述信息,第三操作描述信息用于描述跨节点加速指令,从而指示接收到该指令的第一设备212使用第二设备222来对第三数据进行处理。图9示出了一种示例性的跨节点加速指令的格式,跨节点加速指令的格式还可以是其他的格式,本技术不作具体限定。
158.在一种可能的实现方式中,第一设备212获取跨节点加速指令,包括:第一处理器211从计算资源池获得与第三数据对应的目标加速设备id以及目标加速功能id,生成跨节点加速指令,并发送至第一设备112。
159.在另一种可能的实现方式中,第一设备212获取跨节点加速指令,包括:第一设备212从计算资源池获得与第三数据对应的目标加速设备id以及目标加速功能id,生成跨节点加速指令。
160.s302:第一设备212根据跨节点加速指令,获得第三数据和目标加速功能id。
161.具体地,第一设备212接收到跨节点加速指令后,对跨节点加速指令进行解析,获得第三源地址、目标加速设备id和目标加速功能id,然后从第一存储空间中读取第三数据。
162.s303:第一设备212将第三数据和目标加速功能id进行封装,得到第四网络传输报文。
163.具体地,第一设备212根据目标加速设备id和第一管理单元2121中存储的第二对应关系,确定第二计算节点220的id。然后,第一设备212根据第二计算节点220的id对第三数据和目标加速功能id进行封装,得到第四网络传输报文。其中,第四网络传输报文包括第三数据、目标加速功能id,以及第四源ip地址、第四目的ip地址,第四源ip地址为第一计算节点210的ip地址,第四目的ip地址为第二计算节点220的ip地址。
164.可选的,第二计算节点220的id可以是第二计算节点220的ip地址,也可以是用于指示第二计算节点220的编号。当第二计算节点220的id是第二计算节点220的ip地址时,第一设备212根据第二计算节点220的id对第三数据和目标加速功能id进行封装,得到第四网络传输报文,包括:第一设备212根据第一计算节点210的ip地址和第二计算节点220的id,对第三数据和目标加速功能id进行封装,得到第四网络传输报文。当第二计算节点220的id是用于指示第二计算节点220的编号时,第一设备212根据第二计算节点220的id对第三数据和目标加速功能id进行封装,得到第四网络传输报文,包括:第一设备212根据第二计算节点120的id,确定第二计算节点220的ip地址,然后根据第一计算节点210的ip地址和第二计算节点220的ip地址,对第三数据和目标加速功能id进行封装,得到第四网络传输报文。
165.s304:第一设备212将第四网络传输报文发送至第二设备222。
166.s305:第二设备222接收第四网络传输报文,并根据第四网络传输报文对第三数据进行处理。
167.具体地,第二设备222接收到第四网络传输报文后,对第四网络传输报文进行解析,获得第三数据和目标加速功能id,然后根据目标加速功能id对第三数据进行处理。
168.s306:第二设备222将第三数据的处理结果发送至第一设备212。
169.具体地,第二设备222对第三数据的处理结果进行封装,得到第五网络传输报文。其中,第五网络传输报文包括第三数据、第五源ip地址以及第五目的ip地址,第五源ip地址为第二计算节点220的ip地址,第五目的ip地址为第一计算节点210的ip地址。
170.s307:第一设备212接收第三数据的处理结果,并将该结果写入第三存储空间。
171.在一种可能的实现方式中,第一设备212接收到第五网络传输报文后,对第五网络传输报文进行解析,获得第三数据的处理结果。第一设备212还根据上述跨节点加速指令,获得第三目的地址。然后,第一设备212将第三数据的处理结果写入第三目的地址对应的存储空间(即第二存储空间)。
172.在另一种可能的实现方式中,上述第五网络传输报文还包括第三目的地址,那么,第一设备212将第三数据的处理结果写入第二存储空间,包括:第一设备212接收到第五网络传输报文后,对第五网络传输报文进行解析,得到第三数据和第三目的地址,然后将第三数据写入第二存储空间。应理解,当第五网络传输报文包括第三目的地址时,上述第四网络传输报文也包括第三目的地址,这样,在上述s306中,第二设备222可以对第三数据的处理结果和第三目的地址一起进行封装,从而得到第五网络传输报文。
173.上述实施例描述了第三数据为第一设备212中存储的数据,第三数据的处理结果写入的是第一设备212的设备存储空间,即跨节点加速指令中的第三源地址为第一存储空间的地址,跨节点加速指令中的第三目的地址为第二存储空间的地址。在实际应用中,第三数据还可以是第二设备222中存储的数据,或第一计算节点210的内存中存储的数据,或第二计算节点220的内存中存储的数据。第三数据的处理结果还可以写入第一计算节点210的内存。下面将对以上几种情况进行简单的说明。
174.情况1、当第三数据为第二设备222中存储的数据、第三数据的处理结果写入的是第一设备212的设备存储空间时,跨节点加速指令中的第三源地址为第四存储空间的地址,第三目的地址仍为第二存储空间,其中,第二设备222的设备存储空间包括第四存储空间。
175.那么,第一设备212在获取跨节点加速指令后,可以通过以下步骤使用第二设备222对第三数据进行处理:第一设备212对跨节点加速指令进行解析,获得第二设备的id,然后根据第二设备的id和第一管理单元2121中存储的第二对应关系,确定第二计算节点220的id,然后根据第二计算节点220的id,对第三源地址、目标加速功能id进行封装,得到对应的网络传输报文,并将该网络传输报文发送至第二设备222,第二设备222接收到该网络传输报文后,获得第三源地址和目标加速功能id。然后,第二设备222从第四存储空间中读取第三数据,并根据目标加速功能id对第三数据进行相应的处理。之后,第二设备222将第三数据的处理结果发送至第一设备212,第一设备212接收到第三数据的处理结果后,将第三数据的处理结果写入第二存储空间。
176.情况2、当第三数据为第一计算节点210的内存中存储的数据、第三数据的处理结果写入的是第一计算节点220的内存中时,计算机系统200可以结合上述数据传输方法来实现上述跨计算节点的数据处理,为了简便,此处仅描述与上述s301-s307的不同步骤:
177.(1)跨节点加速指令包括的第三源地址为第五内存空间的虚拟地址,第三目的地址为第六内存空间的虚拟地址,其中,第一内存213包括第五内存空间和第六内存空间。也就是说,该跨节点加速指令是第一处理器212或第一设备222通过以下步骤得到的:从内存资源池获得第五内存空间的虚拟地址和第六内存空间的虚拟地址,从计算资源池获得第二设备的id和目标加速功能id,从而生成跨节点加速指令。
178.需要说明的是,在情况2中,第一资源管理器2111除了用于管理计算机系统200中所有计算节点拥有的计算资源,还用于管理计算机系统200中所有计算节点拥有的内存资源,具体可参见第一资源管理器1111的管理方式。因此,第一管理单元2121除了包括第二对
应关系外,还包括第五内存空间的虚拟地址、第五内存空间的物理地址以及第一计算节点210的id之间的对应关系,以及第六内存空间的虚拟地址、第六内存空间的物理地址以及第一计算节点210的id之间的对应关系。
179.(2)第一设备212通过以下步骤获取第三数据:第一设备212获取跨节点加速指令后,对跨节点加速指令进行解析,获得第三源地址,然后根据第三源地址和第一管理单元2121中存储的第五内存空间的虚拟地址与第五内存空间的物理地址之间的对应关系,从第五内存空间中读取第三数据。
180.(3)第一设备212得到第三数据的处理结果后,通过以下步骤将第三数据写入第三目的地址:第一设备212获取第三数据的处理结果后,根据第三目的地址以及第一管理单元2121中存储的第六内存空间的虚拟地址与第六内存空间的物理地址之间的对应关系,将第三数据的处理结果写入第六内存空间。
181.应理解,当第三数据为第二设备222中存储的数据、第三数据的处理结果写入的是第一计算节点210的内存中,或者第三数据为第二计算节点220的内存中存储的数据,第三数据的处理结果写入的是第一设备212的设备存储空间中,或者第三数据为第二计算节点220的内存中存储的数据,第三数据的处理结果写入的是第一计算节点210的内存中时,第一设备212使用第二设备222处理第三数据的方法也可以结合本技术提供的数据传输方法,具体过程可参见情况2所描述的方法,并对其进行适应性的修改,为了简便,此处不再叙述。
182.上述实施例描述了第一计算节点210使用第二计算节点120的加速设备处理数据的过程,应理解,第二计算节点220使用第一计算节点220的加速设备处理数据的过程与上述实施例描述的过程类似,为了简便,此处不再叙述。
183.通过上述数据处理方法,第一设备212能够使用第二设备222处理第三数据,从而在计算机系统200中实现跨计算节点的计算资源共享。而且,在利用上述数据处理方法在处理数据时,除了上述s301中可能需要第一处理器211生成跨节点写指令,并发送至第一设备212,其他步骤均不需要第一处理器211和第二处理器221,也就是说,利用上述数据处理方法可以绕过第一计算节点210和第二计算节点220中的cpu和操作系统,如此,可以提高跨计算节点的数据处理效率,从而提高计算机系统200的计算资源的共享效率。另外,在第一设备212使用第二设备222处理第三数据的过程中,第二计算节点220的cpu可以执行其他任务,而如果第一计算节点210的cpu需要生成跨节点加速指令,并发送至第一设备212,那么,在第一计算节点210的cpu将跨节点加速指令发送至第一设备212之后,还可以释放出来执行其它任务,从而减少资源浪费,提供资源利用率。
184.上文中结合图1至图9,详细描述了本技术提供的数据传输方法和数据处理方法,下面将描述执行上述数据传输方法和数据处理方法的系统。
185.本技术还提供了一种计算机系统,如前述图1所示,计算机系统100可以包括第一计算节点110和第二计算节点120,第一计算节点110可以包括第一设备112、第一内存113,第二计算节点120可以包括第二设备122。可选的,第一计算节点110还可以包括第一处理器111。
186.其中,第一设备112用于执行前述s101-s103、s106、s201-s204,第二设备122用于执行前述s104-s105、s205。
187.可选的,当第一计算节点110包括第一处理器111时,第一处理器111用于对计算机
系统110的内存资源池的地址空间进行编址,得到内存资源池的全局虚拟地址,以及构建第一对应关系。第一处理器111还用于执行前述s101中生成跨节点读指令,并将跨节点读指令发送至第一设备112的步骤。第一处理器111还可以用于执行前述s201中生成跨节点写指令,并将跨节点写指令发送至第一设备112的步骤。
188.本技术还提供了一种计算机系统,如前述图6所示,计算机系统200可以包括第一计算节点210和第二计算节点220,第一计算节点210可以包括第一设备212,第二计算节点220可以包括第二设备222。可选的,第一计算节点110还可以包括第一处理器211。
189.其中,第一设备212用于执行前述s301-s304、s307、以及情况1和情况2中第一设备212执行的步骤,第二设备222用于执行前述s305-s306、以及情况1和情况2中第二设备222执行的步骤。
190.可选的,当第一计算节点210包括第一处理器211时,第一处理器211用于对计算机系统200的计算资源池中的加速设备及每个加速设备的加速功能进行编号,得到多个加速设备id以及每个加速设备id对应的加速功能id,以及构建第二对应关系。第一处理器211还用于执行前述s301中生成跨节点加速指令,并将跨节点加速指令发送至第一设备212的步骤。
191.本技术还提供了一种计算机可读存储介质,该计算机可读存储介质存储有第一计算机指令和第二计算机指令,第一计算机指令和第二计算机指令分别运行在第一计算节点(例如,图1所示的第一计算节点110、图6所示的第一计算节点210)和第二计算节点(例如,图1所示的第二计算节点120、图6所示的第二计算节点220)上,以实现前述方法实施例所描述的第一计算节点110与第二计算节点120之间的数据传输,以及第一计算节点210与第二计算节点220之间的数据处理,从而在计算机系统中实现跨计算节点的资源(内存资源和计算资源)的共享。
192.上述计算节点可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。上述计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,上述计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如,同轴电缆、光纤、双绞线或无线(例如,红外、无线、微波)等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。上述计算机可读存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个介质集成的服务器、数据中心等数据存储设备。上述可用介质可以是磁性介质(例如,软盘、硬盘、磁带)、光介质(例如,光盘)、或者半导体介质(例如,固态硬盘(solid state disk,ssd))。
193.以上所述,仅为本技术的具体实施方式。熟悉本技术领域的技术人员根据本技术提供的具体实施方式,可想到变化或替换,都应涵盖在本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1