一种基于音形泛化的模糊搜索方法与流程
1.本发明涉及数据搜索、内容审查技术领域,具体涉及一种基于搜索关键字音、形泛化的模糊搜索方法。
背景技术:
2.传统的文本工具、编辑工具在进行内容搜索时,大多基于关键字、典型的“*”、“?”这类通配符进行。这类搜索均采用与关键字精准匹配的方法完成,但在实际的应用场景中,精准匹配特别是对中文的检索存在一定不足,会导致相关内容无法被搜索到。
3.(1)使用拼音输入法的人员,在输入文字时由于输入法的联想辅助功能,可能会输入发音相同而字形相异、或者语音相近而字形不同的内容;输入者对于如前鼻音、后鼻音等易混淆拼音误用,导致输入内容不正确;
4.(2)内容发布者为了某些目的故意使用发音相近或字形相似的词语进行混淆替代,以实现逃避内容审查的目的。
5.在上述情况中,均无法通过常规的精确匹配查找的方法检索到相关内容。
技术实现要素:
6.针对采用精确文字匹配进行内容检索的不足,本发明的目的在于一种基于音形泛化的模糊搜索方法,搜索关键字的字音、字形进行泛化处理,形成与搜索关键字关联的模糊搜索关键字集合,再基于该搜索关键字集合进行匹配搜索,实现与关键字字音相同或相近、字形相近的文字内容的检索,显著提高了检索的覆盖度和成功率。
7.为了实现上述目的,本发明采用如下技术方案:
8.一种基于基于音形泛化的模糊搜索方法,包括以下步骤:
9.步骤一、对搜索信息s
s
进行分词,生成关键词组{w0、...、w
i
};
10.基于词典分词或机器学习算法对所搜索信息s
s
进行中文分词处理,解析出关键词组{w0、...、w
i
、...、w
n
};
11.步骤二、对关键词组w
i
进行语音泛化,生成泛化字音集合yw
i
;
12.步骤1、关键词语w
i
转换为拼音串p
i
,p
i
=[y1...y
i
...y
n
],其中单个拼音的下标i的范围是从1到n,y
i
为第i个字的拼音,y
i
忽略掉声调;
[0013]
步骤2、泛化字音集合yw
i
默认包括拼音串p
i
,即yw
i
={p
i
};
[0014]
步骤3、设定字音泛化规则组sr,sr={r1、r2、r3};
[0015]
由平舌音和对应的翘舌音组成字音泛化规则r1,包括:{zh,z}、{ch、c}、{sh、s}三个组对;
[0016]
由前鼻音和后鼻音组成字音泛化规则r2,包括:{ang,an}、{eng、en}、{ing、in}三个组对;
[0017]
由鼻音与边音组成字音泛化规则r3,包括:{l,n}一个组对;
[0018]
步骤4、对泛化字音集合yw
i
中的元素按照顺序从前向后依次参照字音泛化规则组
sr进行泛化;
[0019]
具体过程如下:
[0020]
(a)对泛化字音集合yw
i
中的拼音串p
i
,即[y1...y
i
...y
n
],依次根据字音泛化规则r1进行泛化;
[0021]
如果y1包含字音泛化规则r1中的任一字音,则使用与该字音同一组对中的字音进行替换得到y1‘
,由y1‘
...y
i
...y
n
组成p
i
‑
11
,将p
i
‑
11
加入泛化字音集合yw
i
,即yw
i
={p
i
,p
i
‑
11
};
[0022]
同理,对y2...y
n
进行匹配替换,得到泛化字音集合yw
i
={p
i,
p
i
‑
11
,...,p
i
‑
1n
};
[0023]
(b)对泛化字音集合yw
i
中的拼音串p
i
,即[y1...y
i
...y
n
],依次进行根据字音泛化规则r2进行泛化,得到泛化字音集合yw
i
={p
i,
p
i
‑
21
,...,p
i
‑
2n
,p
i
‑
11
...,p
i
‑
11
‑
2n
,...,p
i
‑
1n
,p
i
‑
1n
‑
21
,...,p
i
‑
1n
‑
2n
};
[0024]
(c)对泛化字音集合yw
i
中的拼音串p
i
,即[y1...y
i
...y
n
],依次进行根据字音泛化规则r3进行泛化,得到泛化字音集合yw
i
={p
i,
p
i
‑
31
,...,p
i
‑
21
,p
i
‑
21
‑
31
...,p
i
‑
2n
,p
i
‑
2n
‑
31
...,p
i
‑
1n
‑
2n
,p
i
‑
1n
‑
2n
‑
31
};
[0025]
(d)由w
i
的首字母组成泛化串fp
i
,将泛化串fp
i
加入泛化字音集合中,得到泛化字音集合
[0026]
yw
i
={p
i,
p
i
‑
31
,...,p
i
‑
21
,p
i
‑
21
‑
31
...,p
i
‑
2n
,p
i
‑
2n
‑
31
...,p
i
‑
1n
‑
2n
,p
i
‑
1n
‑
2n
‑
31
、fp
i
};
[0027]
步骤三、对关键词语w
i
进行字形泛化,生成泛化字形集合xw
i
。
[0028]
字形相近不同于字音,无法进行规则的自动化泛化;选择字形识别中通用的部分空间法,对常用的汉字匹配筛选,形成相似汉字的字典;
[0029]
步骤1、泛化字形集合xw
i
默认包括w
i
,即xw
i
={w
i
};
[0030]
步骤2、关键词语w
i
包含的字为x1x
2...
x
n
,从x1开始进行字形泛化;
[0031]
具体如下:根据x1查找形近字词典获得{x
11
、...、x
1n
},由形近字替代生成字形泛化词组{t1‑1、...t1‑
n
},其中,t1‑1=x
11
x
2...
x
n
,t1‑
n
=x
1n
x
2...
x
n
,将泛化后的词组加入泛化字形集合xw
i
,即泛化字形集合
[0032]
xw
i
={w
i
、t1‑1、...t1‑
n
};
[0033]
步骤3、依次从x2~x
n
进行查找替代,形成泛化字形集合xw
i
={w
i
、...t
i
‑1、...t
i
‑
n
、...t
n
‑1、...t
n
‑
n
};
[0034]
步骤四、根据搜索信息s
s
中的关键词组{w0、...、w
i
}的泛化字音集合yw
i
、泛化字形集合xw
i
,形成总的模糊搜索集合s
all
;
[0035]
s
all=
{yw0、...yw
i
、...yw
n
、...xw0、...xw
i
、...xw
n
};
[0036]
步骤五、从总的模糊搜索集合s
all
中逐一取出进行检索的内容,完成相应的信息搜索,对搜索结果进行合并,搜索完成。
[0037]
总体而言,本发明所提供的方法与现有精确检索方法相比,具有以下优点:
[0038]
1)基于汉字检索中特有的音相同、相近而字不同的特征,进行字音泛化,实现了较好的搜索覆盖度。
[0039]
2)基于汉字检索中音不同而字相近的特征,进行字形泛化,实现了较好的检索覆盖度。
附图说明
[0040]
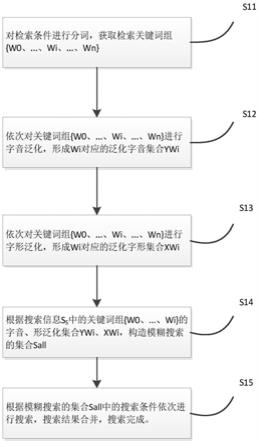
图1为本发明提供的基于音、形泛化的模糊搜索流程。
[0041]
图2为本发明中基于字音泛化规则组的字音泛化流程。
具体实施方式
[0042]
为了使本发明的目的、技术方案及优点更加清楚明白,以下结合附图及实施例,对本发明进行进一步详细说明。应当理解,此处所描述的具体实施例仅用以解释本发明,并不用于限定本发明。
[0043]
针对采用精确文字匹配进行内容检索的不足,本发明设计了一种基于搜索关键字的字音、字形进行泛化处理,形成与搜索关键字关联的模糊搜索关键字集合,再基于该搜索关键字集合进行匹配搜索,实现与关键字字音相同或相近、字形相近的文字内容的检索,显著提高了检索的覆盖度和成功率。
[0044]
如图1所示,基于音形泛化的模糊搜索方法,流程如下:
[0045]
s11、对搜索信息s
s
进行分词,生成关键词组{w0、...、w
i
}。
[0046]
根据相似字音、字形的模糊搜索,本质是基于搜索关键字进行搜索信息的泛化,如果对所有的搜索信息均进行泛化,生成的模糊搜索信息集合将成指数级增长,在搜索信息较长时影响搜索性能。为了在泛化的基础上确保搜索的性能,需要对搜索信息进行权重划分。
[0047]
基于词典分词或机器学习算法对所搜索信息s
s
进行中文分词处理,解析出关键词组{w0、...、w
i
、...、w
n
}。
[0048]
s12、对关键词组w
i
进行语音泛化,生成泛化字音集合yw
i
。
[0049]
(1)关键词语w
i
转换为拼音串p
i
,p
i
=[y1...y
i
...y
n
],其中单个拼音的下标i的范围是从1到n,y
i
为第i个字的拼音,y
i
忽略掉声调。
[0050]
(2)泛化字音集合yw
i
默认包括拼音串p
i
,即yw
i
={p
i
}。
[0051]
(3)设定字音泛化规则组sr,sr={r1、r2、r3}。
[0052]
由平舌音和对应的翘舌音组成字音泛化规则r1,包括:{zh,z}、{ch、c}、{sh、s}三个组对。
[0053]
由前鼻音和后鼻音组成字音泛化规则r2,包括:{ang,an}、{eng、en}、{ing、in}三个组对。
[0054]
由鼻音与边音组成字音泛化规则r3,包括:{l,n}一个组对。
[0055]
(4)对泛化字音集合yw
i
中的元素按照顺序从前向后依次参照字音泛化规则组sr进行泛化。
[0056]
具体过程如下:
[0057]
(a)对泛化字音集合yw
i
中的拼音串p
i
,即[y1...y
i
...y
n
],依次根据字音泛化规则r1进行泛化。
[0058]
如果y1包含字音泛化规则r1中的任一字音,则使用与该字音同一组对中的字音进行替换得到y1‘
,由y1‘
...y
i
...y
n
组成p
i
‑
11
,将p
i
‑
11
加入泛化字音集合yw
i
,即yw
i
={p
i
,p
i
‑
11
};
[0059]
同理,对y2...y
n
进行匹配替换,得到泛化字音集合yw
i
={p
i,
p
i
‑
11
,...,p
i
‑
1n
}。
[0060]
(b)对泛化字音集合yw
i
中的拼音串p
i
,即[y1...y
i
...y
n
],依次进行根据字音泛化规则r2进行泛化。得到泛化字音集合yw
i
={p
i,
p
i
‑
21
,...,p
i
‑
2n
,p
i
‑
11
...,p
i
‑
11
‑
2n
,...,p
i
‑
1n
,p
i
‑
1n
‑
21
,...,p
i
‑
1n
‑
2n
}。
[0061]
(c)对泛化字音集合yw
i
中的拼音串p
i
,即[y1...y
i
...y
n
],依次进行根据字音泛化规则r3进行泛化。得到泛化字音集合yw
i
={p
i,
p
i
‑
31
,...,p
i
‑
21
,p
i
‑
21
‑
31
...,p
i
‑
2n
,p
i
‑
2n
‑
31
...,p
i
‑
1n
‑
2n
,p
i
‑
1n
‑
2n
‑
31
}。
[0062]
前三步的泛化过程如图2所示。
[0063]
(d)由w
i
的首字母组成泛化串fp
i
,将泛化串fp
i
加入泛化字音集合中,得到泛化字音集合
[0064]
yw
i
={p
i,
p
i
‑
31
,...,p
i
‑
21
,p
i
‑
21
‑
31
...,p
i
‑
2n
,p
i
‑
2n
‑
31
...,p
i
‑
1n
‑
2n
,p
i
‑
1n
‑
2n
‑
31
、fp
i
}。
[0065]
s13、对对关键词组w
i
进行字形泛化,生成泛化字形集合xw
i
。
[0066]
字形相近不同于字音,无法进行规则的自动化泛化。选择字形识别中较为通用的部分空间法,对常用的汉字匹配筛选,形成相似汉字的字典。
[0067]
具体过程如下:
[0068]
(1)泛化字形集合xw
i
默认包括w
i
,即xw
i
={w
i
}。
[0069]
(2)关键词语w
i
包含的字为x1x
2...
x
n
,从x1开始进行字形泛化。
[0070]
具体如下:根据x1查找形近字词典获得{x
11
、...、x
1n
},由形近字替代生成字形泛化词组{t1‑1、...t1‑
n
},其中,t1‑1=x
11
x
2...
x
n
,t1‑
n
=x
1n
x
2...
x
n
,将泛化后的词组加入泛化字形集合xw
i
,即泛化字形集合
[0071]
xw
i
={w
i
、t1‑1、...t1‑
n
}。
[0072]
(3)依次从x2~x
n
进行查找替代,形成泛化字形集合xw
i
={w
i
、...t
i
‑1、...t
i
‑
n
、...t
n
‑1、...t
n
‑
n
}。
[0073]
s14、根据搜索信息s
s
中的关键词组{w0、...、w
i
}的泛化字音集合yw
i
、泛化字形集合xw,形成总的模糊搜索集合s
all
。
[0074]
s
all
={yw0、...yw
i
、...yw
n
、...xw0、...xw
i
、...xw
n
}。
[0075]
s15、从总的模糊搜索集合s
all
中逐一取出进行检索的内容,完成相应的信息搜索,对搜索结果进行合并,搜索完成。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1