一种遥感影像模糊多中心的监督分类方法及应用
一种遥感影像模糊多中心的监督分类方法及应用
1.基金项目:本申请得到国家自然科学基金(41971410)的支持。
技术领域
2.本发明涉及遥感科学中的遥感数据的模糊监督分类、非监督分类和半监督方法,更具体的涉及基于多光谱或高光谱遥感数据,用多中心表达地理现象的波谱多样性,进而利用多中心来计算遥感数据中像元的隶属度和确定像元类别的多中心分类方法。
背景技术:
3.模糊性是广泛存在于湿地和森林等地理世界的固有不确定性,在处理和分析多光谱遥感数据时带来了巨大的挑战。近年来,模糊集由于能够表达从一个类别到另一个类别的逐渐过渡性,在模糊土地覆盖分类中得到了广泛的应用。目前存在三类模糊分类方法,第一类是不需要先验知识的非监督分类方法。模糊的c
‑
均值(fcm)聚类是这种类型的一种典型方法。该算法需要两个参数:类别数n和模糊系数m。第二类是监督方法,这类方法需要先验知识来提高分类精度。这类模糊分类方法需要大量的标记样本来训练监督分类方法,但是在实际应用中,选择大量优质样本代价较大且可能比较困难的。第三类是模糊半监督聚类(fssc),它是为了提高fcm方法的分类精度和降低样本选择的难度而提出来的,然而,这类方法跟fcm等方法一样,均利用一个中心来表达地物的波谱特征。遥感数据同物异谱和同谱异物现象使得遥感数据在波谱空间具有复杂的数据结构,这种复杂的内在结构使得遥感数据的分类或特征提取变得非常困难。然而,非监督和半监督模糊方法往往忽略了复杂的内在结构,并采用单点(单值或区间值)来表示类别的中心,从而导致分类精度有限。光谱多样性可归纳为以下三个层次:(1)土地覆盖类型可能包含多个聚类,2)这些聚类可能具有不同的大小和类别,(3)某些聚类可能相互重叠。现有的单中心分类方法不能很好的处理这些光谱多样性,导致了精度非常有限。
技术实现要素:
4.为了处理这三个层次的光谱多样性,首先,土地覆盖类型应表示为多个聚类。对于第二个层次,应该识别多维空间中不同大小的聚类。对于第三级,应确定重叠的聚类,因为它们是产生分类不确定性的原因。
5.本发明提出了一种新的模糊监督分类方法,即多中心监督模糊分类(mcsfc)方法。首先,采用基于fcm方法的分层聚类方法,在光谱空间将图像分割成大小相似的粒子,粒子内波谱特征曲线具有极大的相似性。从而使得一个原始的大而异质的土地覆盖类型被分解成大量的粒子,而一个原始的小或同质的土地覆盖类型则由少量的颗粒组成。其次,利用标记样本对这些粒子进行标记和分类,将其分为三类:(1)纯粒子,仅对应于一类样本,它们位于光谱空间的内部聚类中(这些样本分类可靠);(2)不纯粒子,对应于多种类型的样本,位于不同样本类型之间的过渡带,用边界类型表示;(3)无样本的未标记粒子。由于不纯粒子是不同类型之间的重叠聚类,将其作为分类参考时会产生很大的不确定性。因此,不纯粒子
不能作为分类的参考。每个纯粒子的中心代表每种土地覆盖类型,而各种土地覆盖类型的光谱多样性则由这些中心来表示。每种类型的中心都由覆盖树存储,以提高最近邻中心的检索速度。第三,每个未标记样本属于每种土地覆盖类型的隶属度,都由最邻近的可信参考聚类来确定。
6.本发明公开了如下的技术内容:一种遥感影像模糊多中心的监督分类方法,其特征在于:首先采用基于fcm方法的分层聚类方法,在光谱空间将图像分割成大小相似的粒子;其次利用标记样本对这些粒子进行标记和分类,将其分为三类:1)纯粒子; 2)不纯粒子;3)无样本的未标记粒子;第三,每个未标记样本属于每种土地覆盖类型的隶属度,都由最邻近的纯粒子来确定;按如下的步骤进行:(1)粒度分割模块首先使用fcm算法将完整的数据集x分割成个叶子,加权欧氏距离的确定如下:这里是样本和中心之间的加权欧氏距离,是数据集的维度,是数据集第j维的标准偏差,将fcm算法应用于完整数据集后,得到个聚类,然后对完整数据集进行如下拆分:这里为叶子数量, 为样本属于叶子的隶属度,函数用于计算隶属度的最大值;为数据集的第个子集,在这里,因此完整数据被分为三个子集,分别标记为1、2和3;以叶子结点中的样本数或叶子的宽度(带宽)为阈值作为终止条件。也就是说,如果叶子的样本数或叶子的宽度大于阈值,则以与第一个节点相同的参数重复在该叶子上运行fcm。否则,就没有必要把叶子分割开。通过循环迭代,使得层次树上的每个叶子结点内的样本数小于阈值,或者叶子的宽度小于阈值。
7.(2)粒子分类模块选择层次树的所有叶子结点,然后将其分为三类:1)单一类型标记样本的纯粒子,是粒子标记样本的类型是单一的,并且标记样本的数量大于n个;2)不同类型标记样本的不纯粒子;3)未标记粒子;(3)计算隶属度模块
这里是属于型的样本的隶属度,分别是样型中心的最短距离,是模糊系数;当采用均值平滑法来考虑邻域隶属度,利用最大隶属度原理确定未标记样本的类型,可表示为.本发明进一步公开了遥感影像模糊多中心的监督分类方法在用于提高遥感分类的精度和可靠性方面的应用;其中所述的提高遥感分类的精度和可靠性指的是:以多中心表达遥感数据的波谱多样性和基于多样性表达的模糊分类方法。实验结果显示:本发明的监督分类方法实现了复杂遥感数据的多中心表达,通过描述地理数据波谱的多样性表达,进而提高了遥感分类的精度和可靠性。
8.本发明主要解决了目前不能有效表达遥感数据中地物波谱的多样性的问题,以及用单一中心表达波谱特征带来的分类精度低的问题。重点考察了波谱空间中遥感数据的分割方法,遥感数据波谱多样性表达及基于波谱多样性表达的模糊监督分类方法,主要的难点在于用多中心来表达地物的波谱多样性和不确定性。
附图说明
9.图1模糊多中心分类过程;图2.层次聚类树;图3.每种土地覆盖类型的纯标记叶、边界叶和未标记叶以及覆盖树;图4.wv
‑
2数据集,使用波段5、3和3的自然彩色合成图像;图5.训练和测试样本;其中(a)训练样本(b)测试样本;图6.用mcsfc方法对wv
‑
2数据集的分类结果。
具体实施方式
10.下面通过具体的实施方案叙述本发明。除非特别说明,本发明中所用的技术手段均为本领域技术人员所公知的方法。另外,实施方案应理解为说明性的,而非限制本发明的范围,本发明的实质和范围仅由权利要求书所限定。对于本领域技术人员而言,在不背离本发明实质和范围的前提下,对这些实施方案中的物料成分和用量进行的各种改变或改动也属于本发明的保护范围。
11.实施例1设该方法采用数据集为x,通过无标签的层次聚类过程直接生成粒子。因此,具有相似光谱属性的样本出现在给定的粒子中。这种层次聚类过程生成一棵聚类树,然后用标记的样本将叶片分为纯叶、不纯叶和未标记叶三种类型。将纯叶的中心视为土地覆盖类型的多个中心,不纯粒子核未标记粒子内的未标记样本的隶属度由样本与多个中心之间的最短距离决定。详细流程如图1所示:
1. 粒度分割模块为了对第一级和第二级的光谱多样性进行建模,在光谱空间中整个数据集被分解成具有相似大小的粒子。在fcm算法的基础上,采用加权欧氏距离的层次聚类方法生成层次树,是通过重复运行条件fcm算法来实现的。需要指出的是虽然it2fcm算法已经被证明比标准fcm算法更有效,但是在本发明中,由于分割时间过长而失去了实用价值,因此在本研究中没有使用它。在划分步骤之后,可以得到一个层次树,如图2所示。
12.在这个划分过程中,我们首先使用fcm算法将完整的数据集x分割成个叶子,加权欧氏距离的确定如下:这里是样本和中心之间的加权欧氏距离,是数据集的维度,是数据集第维的标准偏差。许多距离定义可用于遥感数据分析;因此,我们测试了欧几里德距离、加权欧几里德距离、光谱角度度量(sam)、光谱信息散度(sid)、sam
‑
sid混合度量和jeffries
–
matusita光谱角度映射器(jm
‑
sam)的性能。选择加权欧氏距离是因为它具有最高的分类精度和效率。将fcm算法应用于完整数据集后,我们得到个聚类,然后对完整数据集进行如下拆分:这里为叶子数量,为样本属于叶子的隶属度,函数用于计算隶属度的最大值;为数据集的第个子集,在这里,因此完整数据被分为三个子集,分别标记为1、2和3;以叶子结点中的样本数或叶子的宽度(带宽)为阈值作为终止条件,通过实验发现,这两种阈值设置方法得到的结果类似。也就是说,如果叶子的样本数或叶子的宽度大于阈值,则以与第一个节点相同的参数重复在该叶子上运行fcm。否则,就没有必要把叶子分割开。通过循环迭代,使得层次树上的每个叶子结点内的样本数小于阈值,或者叶子的宽度小于阈值。该过程如图2所示。首先,以叶子内的样本数为阈值,将完整数据分为三个子结点,分别标记为1、2和3。由于每个结点的样本数大于阈值,因此应进一步拆分所有三个聚类。因此,节点1被划分为结点4、5和6,并且结点2和3也相应地被划分。然而,结点4、5和6中的样本数小于阈值;因此,它们不能进一步分开。对于采样数大于阈值的结点,应重复执行分割操作,直到达到分割终止标准。
13.经过这种划分过程,数据集中的所有样本都被划分成小结点,结点中的样本具有高度相似的光谱属性,并且层次树中所有叶结点的样本数都小于阈值。我们把这些叶子结点称为粒子。除样本数外,还可以采用数据样本各维度上下确界差值的最大值作为阈值,这个阈值可以被视为一个聚集的最大大小值,在我们的实验中,上述这两种阈值产生基本一致的结果。结果表明,fcm算法的参数和阈值对层次树的结构有很大的影响;也就是说,不同的参数可以产生不同的层次树和数据划分。在本发明中,两个最具影响力的参数是模糊系
数m和阈值。对于参数c,虽然不同的c值会产生不同的树,但在我们的测试中,最终的分类精度非常接近;因此,没有深入讨论。对于fcm算法中的最大迭代次数和误差容限,众所周知,迭代次数越多,误差容限越小,结果越好;因此,不提供进一步的阐述。
14.2. 粒子分类模块选择层次树的所有叶子结点,然后将其分为三类:(1)单一类型标记样本的纯粒子,是粒子标记样本的类型是单一的,并且标记样本的数量大于n个,(2)不同类型标记样本的不纯粒子,(3)未标记粒子。图3示出了每种土地覆盖类型的纯粒子、边界粒子和未标记粒子以及覆盖树,其中粒子1
‑
4是类型1的纯粒子,粒子6
‑
8是类型2的纯粒子,聚类9和聚类10是两个未标记粒子。在本研究中,这些纯聚类类型的粒子被表示为内部粒子,用来表示类型的光谱多样性,并为分类提供可靠的参考。聚类5是一个不纯的标记粒子,因为它包含属于类型1和类型2的标记样本,这些样本出现在两种类型的过渡带。直观地说,过渡带越宽,就越难确定这两类叶的分界线,我们把这两类粒子称为边界粒子。
15.本发明将所有纯标记叶片的中心视为多个覆盖类型中心。图3中,采用四个中心表示类型1,三个中心表示类型2,这些中心可以很好地表示一种类型的数据分布和多个聚类的任意形状。换句话说,对于任何给定的土地覆盖类型,都可以获得许多中心来表达各种地理物体和现象的光谱多样性。每个聚类的大小都非常相似,避免了由于聚类体积差异较大而导致的分类不确定性。
16.需要注意的是,粒子大小控制了测量光谱多样性的能力。值越大,大颗粒的数量越少,这有两个影响,第一个影响是它会导致粒度大小之间的巨大差异,这进一步增加了不确定性。第二个影响是边界叶的大小随着阈值的增大而增大。因此,产生的纯叶数较少导致难以用较少的中心数来表示光谱多样性,同时由不纯叶片构成的土地覆盖类型之间的边界带增加;分类参考的可靠粒度中心与边界区域之间的距离增大,增加了分类的不确定性,降低了分类精度。反之,一个相对较小的阈值可以产生许多小的纯粒度,这有助于更准确地揭示数据类型的分布,更准确地识别不确定性边界。然而,阈值太小会导致分割结果非常零碎,因此无法帮助识别不确定区域。在阈值为1的极端情况下,即数据未被划分,我们无法识别类型之间的过渡带或边界带,也无法区分可靠和不可靠的参考样本进行分类。
17.3. 计算隶属度模块属于任何土地覆盖类型的未标记样本的隶属度由该样本与多个中心之间的最短距离决定。因此,对于未标记粒子,为了快速确定某一土地覆盖类型的最近中心,使用覆盖树来管理纯粒子的中心。在我们的实验中,覆盖树中使用的距离度量对结果有一定的影响,权重为的加权欧氏距离为覆盖树的距离度量。对于每种土地覆盖类型,我们使用其粒子中心来构建一棵覆盖树;如果要将数据集划分为h类,就需要建立h棵覆盖树。
18.在图3中,对于聚类9中的未标记样本,由于其位于类型1和类型2之间并且其在覆盖树中距离类型1最近的中心是聚类4的中心,因此最短距离是。类似地,此样本与类型2之间的最短距离为。最后,一个属于类型1和类型2的未标记样本的隶属度分别由一维和二维确定。
19.假设数据被划分为h类。对于纯标记叶中的未标记样本,由于纯标记叶中的样本具有很高的光谱相似性,最简单的处理方法是将纯叶的标记类型作为未标记样本类型,并将该类型的隶属度设置为1,其他类型的隶属度设置为0。对于其他叶中的未标记样本,隶属度由以下因素决定:这里是属于型的样本的隶属度,分别是样型中心的最短距离, 是模糊系数。
20.与其他基于像素的方法类似,等式(3)不考虑空间信息,导致明显的椒盐噪声。为了解决这一问题,采用均值平滑法来考虑邻域隶属度。利用最大隶属度原理确定未标记样本的类型,可表示为。4. 时间复杂度分析该方法的计算复杂度由三部分组成。首先是分工过程的复杂性。层次树的第一级的计算复杂度与标准fcm算法的计算复杂度相等,即,其中c是聚类数,n是样本数,m是属性数。为了估计总体复杂度,我们假设一个节点的每个子节点具有相同数量的样本;因此,在第二级中,每个叶中的样本数是。也就是说,每个叶的计算复杂性是;因此,该级的计算复杂性是。对于第三级,每个叶的样本数为,导致计算复杂度在这个水平上。因此,每一级具有相同的计算复杂度。一片叶子在层的样本数为,终止条件是小于阈值thr,最大层数可以通过估计。int()函数表示取大于浮点数的最小整数。因此,除法处理的总体计算复杂度为。
21.第二部分讨论了构造覆盖树的计算复杂性,这里是构建覆盖树,是有界展开常数。然而,由于中心数远小于样本数,,这一部分所用的时间远远少于第一部分。在隶属度计算阶段,每个未标记样本包含两个步骤:最近邻查询和隶属度计算。同样,因为,这部分的计算复杂度是。
22.综上所述,mcsfc方法的计算复杂度应该是。
23.5. 实验分析
本发明采用多光谱wv
‑
2图像来测试所发明方法的分类性能。wv
‑
2图像包含一个全色波段,空间分辨率为46厘米,8个多光谱波段(沿海蓝、蓝、绿、黄、红、红边、近红外1(nir1)和nir2)的空间分辨率为1.8米。该图像于2015年9月13日获得。选择了8个多光谱波段,并以2米的空间分辨率重新采样。实验区涵盖了天津师范大学的校园,大小为633
×
997。土地覆盖类型主要包括建筑物、湿地、树木、草地、裸地和水泥路等。选择该区域作为研究区域的原因主要是验证的便利性。在envi 5.3中进行了辐射和大气校正。使用波段2、3和5的自然彩色合成图像如图4所示。通过目视判读采集测试样本,并在arcgis 10.5中进行调查。训练样本是从测试数据集中提取的,每个类的样本都应该包含子类。例如,水的测试样本应包括深水、浅水、含叶绿素的水和含沉水植物的水。训练样本和测试样本如图5所示,训练数据集覆盖了大约8.7%的研究区域,如表1所示。
24.表1.训练和测试样本的像元数分类结果将fcm的参数c设置为3,模糊系数设置为m=2.0,最大迭代次数设置为100,误差容限为0.001。将粒子的阈值设为100,经过层次聚类处理,生成13521个粒子。这些粒子中有为3057纯标记粒子、69个不纯标记粒子和10395个未标记粒子。此外,水体、阴影、建筑、裸地、林地和草地的数量分别为1203、116、911、107、470和250。
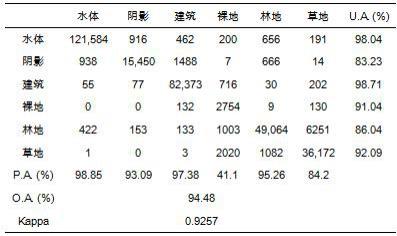
25.在第三步中,我们利用每种类型的纯标记叶的中心来建立六个覆盖树,分类结果如图6所示。混淆矩阵和分类精度如表2所示。所有土地覆盖类型的生产者精度(pas)和使用者精度(uas)均在80%以上,其中建筑面积精度最高,达98.71%。水体和阴影的识别准确率分别为98.04%和83.23%。
26.表2. mcsfc方法的混淆矩阵和准确度。
27.精度比较
本发明将mcsfc方法与三种有监督的方法进行比较:cfdt、lasvm和rf算法。为确保公平比较,cfdt中fcm算法的参数值与mcsfc方法中的参数值相同。选择不同准则作为终止条件,阈值优化为0.6。对于lasvm,选择了广泛使用的径向基函数(rbf)作为核函数,参数gamma设置为标记样本带值的平均方差,参数c优化为10。对于rf,根据作者的建议,分类树数设置为100,叶节点的最小大小设置为5,分割规则是基尼指数。
28.此外,还比较了四种半监督方法,即ssfcm、skfcm
‑
f、siit2
‑
fcm和ss
‑
ait2fcm算法。对于ssfcm和skfcm
‑
f算法,根据作者的建议,模糊系数的参数值、目标函数的最大迭代次数和最小误差容限与mcsfc方法相同,以确保公平比较,并通过以下公式计算维持监督分量和非监督分量之间平衡的权重因子。
29.skfcm
‑
f算法采用高斯核,通过标记样本的距离方差计算高斯核的参数。对于siit2
‑
fcm算法,两个模糊系数分别设置为2.0和5.0,其他参数与mcsfc方法相同。对于ss
‑
ait2fcm算法,根据作者的建议自动计算每种类型的自适应系数。这些方法的用户精度、总精度(o.a.)和kappa系数如表3所示。我们发现mcsfc方法(oa=94.48%)的精度在八种方法中最高。
30.表3八种方法的u.a. (%), o.a. (%) 和 kappa系数比较了mcsfc算法与cfdt、lasvm、rf、ssfcm、skfcm
‑
f、siit2
‑
fcm和ss
‑
ait2fcm算法的运行时间;本例中的运行时分别为150、6、61、10、399、1101、296和872秒。为了确保公平比较,所有方法都是用java实现的,并在相同的硬件上运行。mcsfc算法比cfdt、rf和lasvm算法慢,但比四种半监督算法快。主要原因是cfdt、lasvm和rf只使用训练样本来训练分类器,然后对未标记样本进行分类。mcsfc方法和四种半监督方法直接处理图像和训练样本,图像的大小明显大于训练样本的大小。虽然mcsfc方法需要更多的计算精力,但与四种半监督分类方法相比,该方法的分类速度明显更快,分类精度也更高。
31.分析样本数量的影响将cfdt、lasvm、rf和ss
‑
ait2fcm与mcsfc进行了比较,这些方法的参数设置与上一节相同。表4列出了这些方法的o.a.和kappa系数,样本比例为7.7%和4.8%。可以看出,随着样本比例的减小,mcsfc、rf和ss
‑
ait2fcm的精度损失小于其他两种方法,mcsfc算法仍然具有最高的精度。因此,mcsfc算法具有良好的稳定性和可靠性。
32.表.4五种方法结果的总准确度和kappa系数分别降低到7.7%和4.8%
3)分析粒度和模糊系数的影响如前所述,粒度大小和模糊系数可能会影响分类结果。如果粒度很小,数据会被分割成许多小聚类,反之亦然。关于模糊系数m,许多研究已经证明,不同的模糊系数值可能产生不同的结果。在本节中,我们将研究这两个参数对结果的影响。
33.首先将模糊系数m设置为2.0,以50为步长,在50~600之间变化,然后分析了精度的变化。表5总结了标记聚类、标记不纯聚类和未标记聚类的数量以及总体准确度。我们发现不同的粒度大小会产生不同的结果。在这种情况下,当粒度从50变为600时,纯标记和未标记聚类的数量以及总体分类精度随着粒度和不纯标记聚类比例的增加而降低。然而,不纯标记聚类的数量增加。这意味着表示光谱多样性的能力随着阈值的增加而降低。
34.直接表达土地覆盖类型光谱多样性的能力降低,导致分类精度下降。表5表明,当阈值从50增加到600时,分类精度一般呈下降趋势。当阈值在50~100之间时,准确率为94.48%;当阈值大于500时,准确率低于94%。
35.其次,将粒度设置为200,并将模糊系数以步长为0.2m从1.8更改为4。表六总结了标记纯聚类、标记不纯聚类和未标记聚类的数量以及总体精度。尽管不同的模糊系数在分层聚类过程后可能会对数据集产生不同的划分结果,但这三类聚类的数目没有明显的变化趋势。从准确度的角度,发现不同的模糊方法会产生不同的结果,例如fcm和fssc方法。对于这个数据集,当模糊系数在1.8和3之间时,总体准确率在94%以上,而在2和2.2之间的模糊系数产生最佳结果。另外,测试了参数c在2到8之间的影响,总体精度非常接近。
36.表5. 不同粒度下的聚类数和分类精度表6. 不同模糊系数下的聚类数和分类精度
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1