一种基于长短时记忆和径向基函数神经网络的水质时空关联预测方法
:
1.本发明水质预测方法,具体应用于水环境中重要污染参数的预测,针对水质变化的时间特性,提出了一种基于长短时记忆(long short
‑
term memory,lstm)和径向基函数(radial basis function,rbf)神经网络的水质时空关联预测方法。针对水质变化的多元相关性,利用灰色关联分析和深度自编码降维分别进行时间、空间维度特征选择。该方法能够有效提高水质预测模型的精度和泛化能力。
背景技术:
2.水质预测是水污染治理的重要支撑,是水环境管理的基础。分析水质预测结果,能够更好的了解当地水环境质量的变化趋势,追溯水质恶化的源头,并及时采取相应的治理措施。在京津冀协同发展的大背景下,廊坊市生态环境面临巨大压力。水资源的过度开发,水污染及生态环境恶化成为廊坊市社会经济可持续发展的主要限制因素。
3.水环境条件错综复杂,水质预测模型多种多样,其中大多数模型都仅针对特定的研究对象,维度低且对随机成分较高的水体预测能力不佳。尽管对于多维度、多支流河段的动态模式已有初步探索,但在综合考虑各种因素方面尚存不足。涉及到实际应用,单一水质预测模型精度不高,不能充分利用水质变化的时空特性和多元相关性。因此本发明提出了一种基于lstm
‑
rbf的水质时空关联预测方法。
技术实现要素:
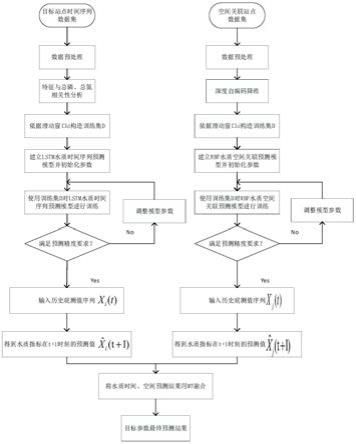
4.对传统水质预测方法在预测水质参数时存在的不足,本发明提出了一种基于长短时记忆网络和径向基函数神经网络组合的水质时空关联预测方法。首先对数据进行异常值处理、缺失值填充以及归一化;其次,分析得到用于水质空间关联预测的空间数据,分析水质参数与总磷、总氮浓度之间的相关性,分别建立时间、空间维度数据集;接着分别建立时间、空间维度水质预测模型;最后,将时间、空间维度预测结果作为两个新的特征,通过模型树融合,使得水质参数预测准确度提高,模型泛化能力大大增强,更有利于本方法在实际应用中的实现。本发明水质预测方法的流程图参见图4。
5.一种基于lstm
‑
rbf的水质时空关联预测方法,依次包括下述步骤:
6.(1)首先对原始数据集中的相关水质参数进行正态分布检验,水质指标均不服从正态分布,因此采用箱型图法进行异常值识别,取异常值前后相邻两个时刻的平均值代替。采用min
‑
max标准化方法进行归一化处理。
7.(2)数据集分为两部分:时间维度的时间序列水质数据、空间维度的相关站点水质数据。根据地区各水质自动站的经度、维度、海拔高程、距离等信息,确定用于空间关联分析的数据集。其中空间数据集选择的方法如下所示:
8.步骤1:利用经度、纬度数据绘制水质自动站分布图;
9.步骤2:以目标水质自动站为中心作圆,圆的半径为监测站点4h水流平均流速数据
乘以监测时间间隔4h。比较落在圆域内的各水质自动站的海拔高程数据;其中海拔高程小的站点位于下游,海拔高程大的站点位于上游;
10.步骤3:根据步骤2计算结果,确定具有上下游关系的站点,并将具有上下游关系的水质自动站的水质数据分别保存到不同数据集中,构成空间数据集;
11.(3)选择区域最终需要预测的水质参数,利用灰色关系分析方法分析其他水质参数与目标参数总磷、总氮浓度之间的相关性。
12.(4)利用目标站点的历史水质数据构建基于lstm的水质时间序列预测模型。
13.(5)利用(2)所获得的空间数据集,建立基于rbf的水质空间相关预测模型。
14.(6)将(4)(5)获得的预测结果,利用模型树融合生成最终的水质时空融合预测模型。
15.本方法旨在利用lstm
‑
rbf水质时空关联预测方法,提高水质预测模型的精度和泛化能力,并且能够充分利用水质变化的时间特性、空间关联和多元相关性。与现有技术相比,本发明具有以下优点:
16.①
、提取与目标参数相关性较高的主要水质指标,可以有效滤除其中包含的冗余特征
17.和噪声;
18.②
空间预测模型的建立能够充分考虑上游水质对下游水质的影响。
19.③
lstm
‑
rbf时空融合模型,可以弥补单一模型泛化能力低、精度不够的缺点。
附图说明:
20.图1是空间数据集获取示意图;
21.图2是深度自编码网络结构图;
22.图3是lstm网络基本结构图;
23.图4是rbf神经网络基本结构图;
24.图5是本发明所述方法流程图;
具体实施方式:
25.参见图1水质自动站空间分布示意图,其中圆心代表目标站点,以目标站点为圆心,圆的半径=区域水流流速*水质监测间隔时间。落在区域中的水质自动站包括站点2、站点3、站点6,通过比较三个站点与目标站点的距离、给站点的高程,选择位于目标站点5上游且距离较近的水质自动站构建空间数据集。
26.本发明的方法流程图参见图5。首先确定预测参数,通过分析区域水质数据,发现水质指标为五类水的指标为预测对象。空间数据集的确定需要用到gis,根据经纬度数据获得空间站点的分布情况,然后确定空间数据集。对于某一站点时间序列数据集,根据相关性分析进行特征提取;对于空间数据集,利用深度自编码网络进行特征提取,深度自编码网络结构见图2。
27.为了获得高维非线性网络结构的低维表示,使用了多个非线性函数来执行多层编码和解码,其中第一个隐含层表示如式(1)所示:
28.29.第k层隐含层表示如式(2)所示:
[0030][0031]
其中σ是激活函数,常用sigmoid,w
(k)
为第k层的权重矩阵,b
k
为第k层的偏置向量,k为隐含层数量,为经过k个隐含层后,得到的网络的特征表示。为了得到最优化的模型参数,需要将x
i
和的平均重构误差最小化,本文选择用均方误差表示损失函数,如式(3)所示:
[0032][0033]
lstm通过遗忘门决定舍弃哪些不利于后续任务的信息,根据前一时刻的神经元输出和当前时刻的输入h
t
‑1和当前时刻输入x
t
,通过激活函数sigmoid,得到遗忘门的输出f
t
,表示如式(4):
[0034]
f
t
=sigmoid(w
f
×
c
t
‑1+u
f
×
x
t
+b
f
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(4)
[0035]
其中w
f
是遗忘门的权重矩阵,u
f
是遗忘门的输入层和隐藏层间的权重矩阵,b
f
是偏置项。然后通过输入门决定将哪部分新信息存储到长期记忆状态中,这个过程分为两步:第一,利用输入门的sigmoid函数选择要存储的新的信息,记作i
t
;然后根据前一时刻的记忆c
t
‑1和当前的输入x
t
,,利用tanh函数创建新的初始值向量表示如下:
[0036]
i
t
=sigmoid(w
i
×
h
t
‑1+u
i
×
x
t
+b
i
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(5)
[0037][0038]
其中w和u分别代表各自门控的权重矩阵,b表示各自门控的偏置项。接下来,依据遗忘门和输出门系数,lstm会更新当前的长期记忆状态c
t
,更新细胞状态的计算过程如式(7)所示。
[0039][0040]
得到新的长期记忆状态c
t
,就可以看输出门了。最终输出的信息h
t
的更新由两部分决定,第一部分是o
t
,它由上一时刻的神经元输出h
t
‑1和当前时刻的输入x
t
,通过激活函数sigmoid得到。第二部分由长期记忆状态c
t
和tanh激活函数组成,如式所示:
[0041]
o
t
=sigmoid(w
o
×
h
t
‑1+u
o
×
x
t
+b
o
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0042]
h
t
=o
t
×
tanh(c
t
)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(9)
[0043]
建立lstm时间序列水质预测模型具体流程如图2所示,主要步骤如下:
[0044]
(1)对数据集进行异常值、空缺值和归一化等预处理操作;
[0045]
(2)选择单一站点数据作为数据集,依据滑动窗口的大小,构造训练集d;
[0046]
(3)建立lstm水质时间序列预测模型,初始化模型参数;
[0047]
(4)用训练集d对预测模型进行训练,使用梯度下降法进行反向传播并更新模型参数,直至满足预测精度要求;
[0048]
(5)输入x
i
的前d个历史观测值序列x
i
(t)到完成训练的lstm水质预测模型中,得到x
i
的第t+1时刻预测值
[0049]
建立rbf空间关联水质预测模型具体流程如图3所示,空间预测模型确定空间数据
集后主要步骤和时间序列预测模型基本相同,rbf网络的建立需要确定中心向量c
i
,宽度σ
i
以及隐含层到输出层的权重w
ik
。其中rbf的中心的选取对网络性能是至关重要,中心太近,会产生近似线性相关,中心太远,产生的网络会过大。本方法采用k
‑
均值聚类算法是进行中心点选择。这种算法需要先选出初始点,不同的初始点,分类结果不同,每类得到的神经元中心也不同。具体步骤如下:
[0050]
(1):任意选取在样本集中的r个样本作初始聚类中心。
[0051]
(2):计算此时每个中心与剩余样本的距离记为d。如果样本与第r类的中心距离最短即min{d},则称属于r类。
[0052]
(3):每当有一个新样本加入该类,则取该类中样本的均值作为新的中心。
[0053]
(4):当满足中心不在变化或者变化程度小于给定限额的条件时,停止聚类。
[0054]
若不满足上述条件,则重新进行(2)。
[0055]
径向基函数采用高斯函数,表达如式(10)所示:
[0056][0057]
式中,||x
‑
c
i
||是向量x
‑
c
i
的欧式范数,表示输入向量x与隐含层神经元中心c之间的距离,其表达式如下:
[0058][0059]
r
i
(x)是一种中心点径向对称衰减局部分布的非负非线性函数。r
i
(x)能在c
i
取得唯一的最大值,并会随||x
‑
c
i
||增大迅速减小到零。σ
i
是高斯函数的围绕隐含层神经元中心的宽度。
[0060]
本方法采用线性回归法计算rbf神经网络中的权重,如下式所示。
[0061][0062]
其中β是权重,y是样本的真实值,y
nn
是训练时rbf神经网络的输出值。
[0063]
宽度σ
i
的选取遵循使得所有rbf网络的神经单元的接受域之和覆盖整个训练样本空间的原则。本方法利用固定法确定宽度,当rbf网络的中心确定后,宽度为max{d}表示为样本与中心距离最大的值,m为隐含层神经元数。rbf网络的最终的输出结果,是隐含层径向基函数值的线性加权和,即表示为:
[0064][0065]
式中表示的是由隐含层神经单元到输出神经单元的各个
加权值。
[0066]
本方法利用了stack的集成思想,将两个单一模型的预测结果作为模型树的训练与测试数据。模型树的构建主要分为三个步骤:建树、剪枝和回归。
[0067]
步骤1:将时间、空间维度预测结果作为两个新的特征,构建新的数据集;
[0068]
步骤2:构建模型树模型,将标准差减少值sdr(standard deviation reduction)作为节点的分裂属性,表示如式(14)所示:
[0069][0070]
其中,t表示到达该节点的样本集合,|t|表示数据集中样本总数量,t
i
表示第i个子树上样本集合,sd表示标准差。本文采用的模型树为二叉树,i取值为1和2。
[0071]
步骤3:训练模型树模型,将步骤1中所得新数据集依据分裂属性分裂,直至没有更多特征生成,形成叶子节点。对每个子集分别建立线性回归方程,线性回归方程如式(15)所示。
[0072]
y=w0+w1x1+w2x2+
…
+w
n
x
n
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(15)
[0073]
其中,x1,x2,
…
,x
n
是属性值,w1,w2,
…
,w
n
表示属性权重。
[0074]
步骤4:模型树建树完成后,利用后剪枝方法进行剪枝。计算每个子集回归方程预测的均方误差;比较每个节点与其子节点均方误差大小,若子节点均方误差比母节点的均方误差小,则保留该子树,否则将该节点转变成叶子节点。
[0075]
步骤5:输入水质历史n天观测值序列,得到总磷、总氮参数第n+1天的预测值。n取值为[10,15]。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1