一种基于机器学习的可视化图表代码自动生成方法与流程
1.本发明属于计算机科学领域,具体涉及一种基于机器学习的可视化图表代码自动生成方法。
背景技术:
2.随着信息化和大数据技术的不断发展,各行各业对数据深层次应用的需求逐渐增大,数据可视化技术成为了政府、企业分析、展示数据的主要方式。对于软件开发工程师,尤其是前端工程师而言,数据可视化的开发主要是将ui设计稿中的图表转换成html、css、javascript代码,这部分工作难度一般,但由于存在很多重复性的代码以及很多自定义元素的处理,所以比较繁琐耗时。因此,如何提升设计稿中图表转换成代码的效率,是可视化前端开发工程师急需解决的问题。
3.目前业界处理该问题的方法主要有两种:一是将不同的图表分模块,把每个模块的代码封装为组件,从而提升图表的可复用性,减少冗余,提高开发效率。但对于企业自身而言,开发人员的技术能力参差不齐,在多人开发的项目中,很容易导致组件碎片化、组件库维护困难以及代码冗余的问题,直接或间接的导致代码运行效率、调试效率降低。另外随着业务的发展和个性化的驱动,通用封装的图表库无法覆盖所有应用场景。二是利用各种自动化技术,把设计稿转为前端代码,减少前端工程师的工作量,从设计稿直接生成前端代码,省去中间流程,做到精度还原的同时并节约研发资源。但是该解决方案只是针对通用页面的,并不能把可视化图表转为代码。
技术实现要素:
4.(一)要解决的技术问题
5.本发明要解决的技术问题是如何提供一种基于机器学习的可视化图表代码自动生成方法,以解决如何提升设计稿中图表转换成代码的效率的问题。
6.(二)技术方案
7.为了解决上述技术问题,本发明提出一种基于机器学习的可视化图表代码自动生成方法,该方法包括如下步骤:
8.步骤1:印记导入
9.导入文件类型符合规范的设计稿;
10.步骤2:组件识别
11.使用开源框架pipcook,基于神经网络算法计算,对设计稿图层进行遍历,识别每一个图层,通过解析得到图层结构、模板结构和图层信息,切割标注的图表组件,获得对应的组件元素;
12.步骤3:样式识别
13.使用ui2dsl多元组件识别提取设计稿中有组件的预打标信息,提炼视图组件信息和组件样式;
14.步骤4:数据合并
15.分析节点信息、修正信息及语义化信息,根据组件与数据规则,生成数据映射信息、文本数据映射信息和状态映射信息;
16.步骤5:转为视图树
17.由操作人员控制,修正解析图层、解析布局、解析属性的偏差;除此之外,对于非组件元素、异常的视图元素进行指定规则的元素转化或者抛弃,完成后生成视图树;
18.步骤6:输出代码
19.通过ui2dsl输出经过各层智能化处理好的代码协议,经过协议转代码的引擎输出各种dsl代码。
20.进一步地,所述步骤1中设计稿的规范的包括标注图表的类型,标注图表的类型包括折线图、柱状图、饼图、散点图、k线图、雷达图、盒须图、热力图、关系图、路径图、树图、矩形树图、旭日图、桑葚图、漏斗图和仪表盘。
21.进一步地,所述步骤1中设计稿的规范的包括规定区域内可用组件,可用组件类型包括图例、坐标轴、缩略轴、滚动条、数据标签、悬浮提示和图表标注。
22.进一步地,所述步骤1中设计稿的规范的包括规定组件的安全区域,在设计对应组件区域时不能越过安全区。
23.进一步地,所述步骤1中设计稿的规范的包括对组件打标签,对组件打标签指在设计组件的最外层图层标记为组件的类型,组件内的图层和标签图层属于被包含的关系。
24.进一步地,所述步骤s2具体包括:pipcook是基于管道的框架,包括数据收集、数据接入、数据处理、模型配置、模型训练、模型服务部署和在线训练七个部分,每个部分由某一具体的插件负责,用插件的方式提供每个环节的定制化能力,用pipcook串联插件实现算法工程;这些数据插件对整个设计稿图层进行遍历,使用图片分类的模型识别每一个图层,通过解析得到图层结构、模板结构和图层信息,对设计文档中的视图结构信息和图层属性读取和类型匹配,映射为对应的组件元素。
25.进一步地,所述步骤3中的组件样式包括字体、背景色和圆角。
26.进一步地,所述步骤4中的数据合并还包括:对交互、数据绑定等上层未带入数据,进行数据文件的合并。
27.进一步地,所述步骤5中由操作人员控制,修正解析图层、解析布局、解析属性的偏差具体包括:修正层的工作是内容的修正,包含图层信息修正、组件识别修正、布局及布局属性修正、组件属性修正和语义化项修正,通过操作人员在可视化工具上进行属性的提交及变更。
28.进一步地,所述步骤5中的完成后生成视图树包括:完成后使用ui2dsl生成视图树。
29.(三)有益效果
30.本发明提出一种基于机器学习的可视化图表代码自动生成方法,该方法针对现有技术中设计稿中图表转换成代码的难题,通过开源框架pipcook获得设计稿中的组件元素,提炼设计稿中的组件信息和组件样式,根据组件与数据规则,修正解析图层、解析布局、解析属性的偏差,生成视图树,并通过ui2dsl输出经过各层智能化处理好的代码协议,经过协议转代码的引擎输出各种dsl代码。该方法极大地提高了设计稿中图表转换成代码的效率,
而且准确率高。
附图说明
31.图1为本发明的架构图;
32.图2为组件识别图;
33.图3为切割组件图;
34.图4为本发明的流程图;
35.图5为组件语义识别图;
36.图6为组件样式识别图;
37.图7为生成视图树图。
具体实施方式
38.为使本发明的目的、内容和优点更加清楚,下面结合附图和实施例,对本发明的具体实施方式作进一步详细描述。
39.为了解决上述问题,本发明提供一种基于机器学习的可视化图表代码自动生成方法。如图1所示,本发明的发明架构图如下:
40.1、设计规范
41.图表生成代码的设计稿,必须为特定规范的格式,比如sketch(是一款适用于所有设计师的矢量绘图应用),在图表开发过程中,图表的种类有很多,而且图表内的组件也是丰富多彩的,但是数据源中并没有这些组件信息,只有图层信息,图层是设计师在设计稿中用到的视图控件。组件与图层的关系是一对多的关系,图层在设计稿中的表现形式是json数据结构,表述了图层的大小、形状和颜色等信息。这样不利于我们对设计稿进行组件切割,因此我们对设计稿的规范做了一些要求:
42.(1)标注图表的类型
43.(2)规定区域内可用组件
44.(3)规定组件的安全区域
45.(4)对组件进行打标签标注
46.2、dsl视图树
47.基于前期我们通过在设计稿中做的人工干预、标记点,根据图表的类型使用图片分类的模型识别循环计算,需要根据图层的数据描述信息,坐标信息,进行图层布局的合并、布局拆分及布局的预测,解析生成相关的组件布局属性,切割标注的图表组件,因为我们采取的是人工干预标注的方法,因此我们不用考虑图层冗余的问题造成的识别不出来、识别错误等情况。如图2、3所示。
48.为了提高生成图表的成功率和完整性,对于不同类型图表的必须类组件缺失的话,我们将采取系统默认的组件模块提取填充。进入修正阶段,由操作人员控制,修正解析图层、解析布局、解析属性的偏差;除此之外,对于非组件元素、异常的视图元素进行指定规则的元素转化或者抛弃,完成上述内容,整个视图树基本形成,最后将扁平化的数据源识别出的组件模块化生成dsl视图树。
49.3、dsl还原
50.dsl视图树只是生成代码的中间产物,还需要对dsl进行代码还原,主要包括四个步骤:属性推断、属性信息调整、数据合并、输出代码。
51.3.1属性推断
52.属性推断包括两个部分:
53.3.1.1组件结构
54.主要是针对标记点组件的识别和预测,通过算法,对布局进行基础的识别和预测,在组件库的支撑下,可以对已有的业务组件进行匹配使用,识别组件的属性,对热区资源进行识别,预测组件的内容数据为可变类型还是非可变类型,提取图层信息,使结构树内的节点信息语义化。
55.3.1.2组件属性
56.通过算法识别出组件的样式信息,提取组件的样式信息,包括字体、背景色、圆角等,通过组件样式库转义为图表需要的样式。
57.3.2属性信息调整
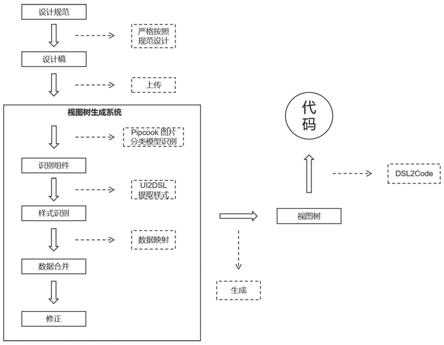
58.修正层的工作是内容的修正,包含图层信息修正,组件识别修正,布局及布局属性修正,组件属性修正,语义化项修正,进行预测或者修正,修正主要通过操作人员在可视化工具上进行属性的提交及变更。
59.3.3数据合并
60.除此外,对交互、数据绑定等上层未带入数据,进行数据文件的合并。
61.3.4输出代码
62.dsl编译器可以通过对组件跟视图布局的配置,载入对应不同的编译器,生成对应不同平台的代码。
63.如图4所示,本发明具体实施方式,包括以下步骤:
64.步骤1:印记导入
65.导入文件类型符合规范的设计稿。
66.1.1设计稿的规范
67.按照从组件布局设计到组件内部样式的设计流程进行设计稿的设计。
68.(1)标注图表的类型
69.折线图、柱状图、饼图、散点图、k线图、雷达图、盒须图、热力图、关系图、路径图、树图、矩形树图、旭日图、桑葚图、漏斗图、仪表盘等。
70.(2)规定区域内可用组件
71.由于生成代码种类的特殊性,不像页面设计稿转为代码那么的高自由度,所以只需要规范设计稿在什么区域块放置什么组件,规定区域内可用组件类型为:图例、坐标轴、缩略轴、滚动条、数据标签、悬浮提示、图表标注等。但是每个图表的类型是多种多样的,图表的内部组件布局也是不同的,所以针对不同图表有相应的组件区域用途做了设计规范。
72.(3)规定组件的安全区域
73.业务的丰富性也导致了设计师在设计过程中也会有五花八门的组件设计样式,因此规范了针对不同图表有相应的组件安全区域,设计对应组件区域不能越过安全区,组件的位置规定了区域内组件的类型。
74.(4)对组件打标签
75.以上规则针对图表的类型和组件做了规范,需要在设计组件的最外层图层标记为组件的类型,组件内的图层和标签图层属于被包含的关系。
76.步骤2:组件识别
77.使用淘宝开源框架pipcook,基于神经网络算法计算,对设计稿图层进行遍历,识别每一个图层,通过解析得到图层结构、模板结构和图层信息,切割标注的图表组件,获得对应的组件元素。
78.使用淘宝开源框架pipcook,基于神经网络算法计算,pipcook是基于管道的框架,包括数据收集、数据接入、数据处理、模型配置、模型训练、模型服务部署、在线训练七个部分,每个部分由某一具体的插件负责,用插件的方式提供每个环节的定制化能力,用pipcook串联插件实现算法工程。整个流程基于node.js的技术体系,定义了一套数据集规范,在数据收集、接入和处理的插件中避免了不同数据集标准带来的接入和使用数据成本,同时,保证数据在不同的pipcook之间能够共享。这些数据插件背后的协议标准,可以支撑在不同的标注工具下产生标准统一的数据集,对整个设计稿图层进行遍历,使用图片分类的模型识别每一个图层,通过解析得到图层结构、模板结构、图层信息,对设计文档中的视图结构信息和图层属性读取和类型匹配,映射为对应的组件元素。如图5所示。
79.步骤3:样式识别
80.由于设计稿中有组件的预打标信息描述,使用ui2dsl多元组件识别提取,将准确无误的提炼视图组件信息和组件样式。如图6所示。
81.步骤4:数据合并
82.分析节点信息、修正信息及语义化信息,根据组件与数据规则,生成数据映射信息、文本数据映射信息和状态映射信息,数据依赖语义化分析和修正信息,参数数值自动匹配。
83.步骤5:转为视图树
84.进入修正阶段,由操作人员控制,修正解析图层、解析布局、解析属性的偏差;除此之外,对于非组件元素、异常的视图元素进行指定规则的元素转化或者抛弃,完成后使用ui2dsl生成视图树。如图7所示。
85.步骤6:输出代码
86.最后通过ui2dsl输出经过各层智能化处理好的代码协议,经过表达能力(协议转代码的引擎)输出各种dsl代码。
87.以上所述仅是本发明的优选实施方式,应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明技术原理的前提下,还可以做出若干改进和变形,这些改进和变形也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1