三维场景重建方法、装置、介质及设备与流程
1.本公开涉及自动驾驶领域技术领域,具体地,涉及一种三维场景重建方法、装置、介质及设备。
背景技术:
2.深度估计在自动驾驶技术领域中具有重要作用,可以用于确定拍摄目标与拍摄源之间的距离,从而确定车辆行驶环境信息。目前,主要通过深度传感器,例如,激光雷达、rgb相机直接确定拍摄目标与拍摄源之间的距离。在实际应用中,为降低配置激光雷达的成本等原因,通常采用单目相机场景图像,进而基于深度估计模型输出的像素点深度值进行三维重建。但是,单目相机缺少双目相机中两个摄像头之间的基线距离作为参考尺度,导致难以将单目相机采集的图像数据集直接作为样本进行模型训练。
3.相关技术中,根据imu(inertial measurement unit,惯性测量单元)确定的图像帧之间相机位姿信息、双目相机的两个摄像头之间的基线、以及激光雷达确定的拍摄目标与拍摄源之间的距离信息对场景图像进行三角化得到训练样本集,并利用训练样本集训练得到深度估计模型,进而通过迁移学习的方式将训练得到的深度估计模型迁移到配置单目相机的自动驾驶车辆上,进而基于该深度估计模型,根据车辆的单目相机采集的场景图像,完成实际自动驾驶过程中的三维场景重建。
技术实现要素:
4.本公开的目的是提供一种三维场景重建方法、装置、介质及设备,以部分地解决相关技术中存在的技术问题。
5.为了实现上述目的,本公开实施例的第一方面,提供一种三维场景重建方法,所述方法包括:
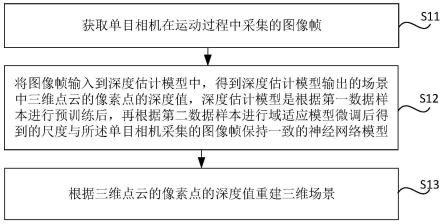
6.获取单目相机在运动过程中采集的图像帧;
7.将所述图像帧输入到深度估计模型中,得到所述深度估计模型输出的场景中的三维点云的像素点的深度值,其中,所述深度估计模型是根据第一数据样本进行预训练后,再根据第二数据样本进行域适应模型微调后得到的尺度与所述单目相机采集的图像帧保持一致的神经网络模型,其中,所述第一数据样本是基于多目相机采集到的样本图像帧得到的,所述第二数据样本是针对单目相机采集的图像帧进行预处理后得到的;
8.根据所述三维点云的所述像素点的深度值重建三维场景。
9.可选地,针对单目相机采集到的图像帧进行的预处理,包括:
10.获取所述单目相机在所述运动过程中的不同采集位置的位姿信息、以及所述不同采集位置之间的距离;
11.根据所述位姿信息、所述距离以及所述单目相机的内参,对所述单目相机在所述不同采集位置采集到的图像帧中相同的像素点做三角化处理,得到对应该像素点的深度值。
12.可选地,根据所述第二数据样本进行的域适应模型微调,包括:
13.针对预训练完成的所述深度估计模型,将所述第二数据样本输入所述深度估计模型,得到所述深度估计模型输出的像素点深度的预测值;
14.将对所述图像帧进行预处理后得到的像素点的深度值作为真值,根据所述真值与所述预测值对所述深度估计模型进行域适应微调,以得到尺度与所述单目相机采集的图像帧保持一致的神经网络模型。
15.可选地,所述深度估计模型在预训练过程中采用第一损失函数,所述第一损失函数用于计算所述第一数据样本中各样本图像帧的光度误差和/或绝对误差,所述深度估计模型在域适应模型微调过程中采用第二损失函数,所述第二损失函数用于在所述光度误差和/或所述绝对误差的基础上,计算对所述第二数据样本中的图像帧进行预处理后得到的像素点的深度值与所述深度估计模型输出的预测值之间的误差;和/或,所述深度估计模型在域适应模型微调过程中的学习率参数小于所述深度估计模型在预训练过程中的学习率参数。
16.可选地,所述获取所述单目相机在所述运动过程中的不同采集位置的位姿信息,包括:
17.提取所述单目相机在所述不同位置采集的图像帧的像素点特征;
18.根据所述像素点特征确定所述不同位置采集的图像帧的像素点之间的对应关系,得到像素点特征对;
19.根据所述像素点特征对确定所述单目相机在所述不同采集位置的位姿信息。
20.可选地,所述单目相机包括全球定位系统模块,或者所述单目相机安装在包括全球定位系统模块的运动物体上;相应地,所述单目相机在所述不同采集位置之间的距离是通过所述全球定位系统模块在所述不同采集位置的定位信号确定的。
21.可选地,所述根据所述位姿信息、所述距离以及所述单目相机的内参,对所述单目相机在所述不同采集位置采集到的图像帧中相同的像素点做三角化处理,得到对应该像素点的深度值,包括:
22.针对所述单目相机在所述不同采集位置采集到的图像帧中相同的像素点,设定三维像素点,并针对在所述不同采集位置采集到的每一图像帧,通过所述单目相机的内参以及对应的所述位姿信息,计算所述三维像素点投影到该图像帧上的投影点的二维坐标与该像素点在该图像帧上的二维坐标之间的误差,直到设定的三维像素点使得计算得到的误差总和最小,得到目标三维像素点;
23.根据所述目标三维像素点以及所述距离,通过几何计算得到该像素点的深度值。
24.本公开实施例的第二方面,提供一种三维场景重建装置,所述装置包括:
25.获取模块,被配置为用于获取单目相机在运动过程中采集的图像帧;
26.输入模块,被配置为用于将所述图像帧输入到深度估计模型中,得到所述深度估计模型输出的场景中的三维点云的像素点的深度值,其中,所述深度估计模型是根据第一数据样本进行预训练后,再根据第二数据样本进行域适应模型微调后得到的尺度与所述单目相机采集的图像帧保持一致的神经网络模型,其中,所述第一数据样本是基于双目相机采集到的样本图像帧得到的,所述第二数据样本是针对单目相机采集的图像帧进行预处理后得到的;
27.重建模块,被配置为根据所述三维点云的所述像素点的深度值重建三维场景。
28.可选地,所述输入模块,被配置为用于针对单目相机采集到的图像帧进行的预处理,包括:
29.获取所述单目相机在所述运动过程中的不同采集位置的位姿信息、以及所述不同采集位置之间的距离;
30.根据所述位姿信息、所述距离以及所述单目相机的内参,对所述单目相机在所述不同采集位置采集到的图像帧中相同的像素点做三角化处理,得到对应该像素点的深度值。
31.可选地,输入模块,被配置为用于根据所述第二数据样本进行的域适应模型微调,包括:
32.针对预训练完成的所述深度估计模型,将所述第二数据样本输入所述深度估计模型,得到所述深度估计模型输出的像素点深度的预测值;
33.将对所述图像帧进行预处理后得到的像素点的深度值作为真值,根据所述真值与所述预测值对所述深度估计模型进行域适应微调,以得到尺度与所述单目相机采集的图像帧保持一致的神经网络模型。
34.可选地,所述深度估计模型在预训练过程中采用第一损失函数,所述第一损失函数用于计算所述第一数据样本中各样本图像帧的光度误差和/或绝对误差,所述深度估计模型在域适应模型微调过程中采用第二损失函数,所述第二损失函数用于在所述光度误差和/或所述绝对误差的基础上,计算对所述第二数据样本中的图像帧进行预处理后得到的像素点的深度值与所述深度估计模型输出的预测值之间的误差;和/或,所述深度估计模型在域适应模型微调过程中的学习率参数小于所述深度估计模型在预训练过程中的学习率参数。
35.可选地,所述输入模块,被配置为用于提取所述单目相机在所述不同位置采集的图像帧的像素点特征;
36.根据所述像素点特征确定所述不同位置采集的图像帧的像素点之间的对应关系,得到像素点特征对;
37.根据所述像素点特征对确定所述单目相机在所述不同采集位置的位姿信息。
38.可选地,所述单目相机包括全球定位系统模块,或者所述单目相机安装在包括全球定位系统模块的运动物体上;相应地,所述单目相机在所述不同采集位置之间的距离是通过所述全球定位系统模块在所述不同采集位置的定位信号确定的。
39.可选地,所述输入模块,被配置为用于:
40.针对所述单目相机在所述不同采集位置采集到的图像帧中相同的像素点,设定三维像素点,并针对在所述不同采集位置采集到的每一图像帧,通过所述单目相机的内参以及对应的所述位姿信息,计算所述三维像素点投影到该图像帧上的投影点的二维坐标与该像素点在该图像帧上的二维坐标之间的误差,直到设定的三维像素点使得计算得到的误差总和最小,得到目标三维像素点;
41.根据所述目标三维像素点以及所述距离,通过几何计算得到该像素点的深度值。
42.本公开实施例的第三方面,提供一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现第一方面任一项所述方法的步骤。
43.本公开实施例的第四方面,提供一种电子设备,包括:
44.存储器,其上存储有计算机程序;
45.处理器,用于执行所述存储器中的所述计算机程序,以实现第一方面任一项所述方法的步骤。
46.通过上述技术方案,至少可以达到以下技术效果:
47.通过获取单目相机在运动过程中采集的图像帧;将图像帧输入到深度估计模型中,得到深度估计模型输出的场景中的三维点云的像素点的深度值,深度估计模型是根据第一数据样本进行预训练后,再根据第二数据样本进行域适应模型微调后得到的尺度与所述单目相机采集的图像帧保持一致的神经网络模型,第一数据样本是基于双目相机采集到的样本图像帧得到的,第二数据样本是针对单目相机采集的图像帧进行预处理后得到的;根据三维点云的像素点的深度值重建三维场景。这样,基于单目相机采集的图像帧进行预处理后得到的第二数据样本,对预训练后深度估计模型进行域适应模型微调,实现模型的尺度与单目相机采集的图像帧保持一致,能够提高迁移学习的模型在单目相机采集的图像进行场景重建时的性能,避免域差异带来的尺度偏移,进而提高三维场景重建的准确性,提高车辆自动驾驶的安全性能。
48.本公开的其他特征和优点将在随后的具体实施方式部分予以详细说明。
附图说明
49.附图是用来提供对本公开的进一步理解,并且构成说明书的一部分,与下面的具体实施方式一起用于解释本公开,但并不构成对本公开的限制。在附图中:
50.图1是根据一示例性示出的一种三维场景重建方法的流程图。
51.图2是根据一示例性示出的一种实现图1中步骤s12的流程图。
52.图3是根据一示例性示出的另一种实现图1中步骤s12的流程图。
53.图4是根据一示例性示出的一种实现图2中步骤s121的流程图。
54.图5是根据一示例性示出的一种确定像素点特征对的示意图。
55.图6是根据一示例性示出的一种实现图2中步骤s122的流程图。
56.图7是根据一示例性示出的一种确定像素点特征对交点的示意图。
57.图8是根据一示例性示出的另一种三维场景重建方法的流程图。
58.图9是根据一示例性实施例示出的一种三维场景的示意图。
59.图10是相关技术中根据迁移学习的深度估计模型重建后的三维场景图。
60.图11是根据本公开的三维场景重建方法重建后的三维场景图。
61.图12是根据本公开的三维场景重建方法重建后的三维场景图。
62.图13是根据一示例性实施例示出的一种三维场景重建装置的框图。
63.图14是根据一示例性实施例示出的一种电子设备的框图。
具体实施方式
64.以下结合附图对本公开的具体实施方式进行详细说明。应当理解的是,此处所描述的具体实施方式仅用于说明和解释本公开,并不用于限制本公开。
65.需要说明的是,在本公开中,说明书和权利要求书以及附图中的术语“第一”、“第
二”等是用于区别类似的对象,而不必理解为描述特定的顺序或先后次序。同理,术语“s121”、“s1201”等用于区别步骤,而不必理解为按照特定的顺序或先后次序执行方法步骤。
66.在相关场景中,通过迁移学习的方式将基于高精度图像数据集训练得到的深度估计模型迁移到自动驾驶车辆上,由于模型训练的图像数据集与车辆的单目相机采集的视频图像存在较大差异,即基于双目相机采集的图像数据集与基于单目相机采集的视频数据存在较大的域差异,数据分布上存在较大差异,导致在实际使用过程中,深度估计模型的性能急剧下降,造成3d场景误差较大。具体表现为深度估计模型估计出的深度尺度与实际尺度相差较大,造成拍摄目标的尺度偏移,导致深度估计模型的实用性较低。
67.为此,本公开提供一种三维场景重建方法,图1是根据一示例性示出的一种三维场景重建方法的流程图,所述方法包括以下步骤。
68.在步骤s11中,获取单目相机在运动过程中采集的图像帧。
69.在步骤s12中,将图像帧输入到深度估计模型中,得到深度估计模型输出的场景中的三维点云的像素点的深度值,深度估计模型是根据第一数据样本进行预训练后,再根据第二数据样本进行域适应模型微调后得到的尺度与所述单目相机采集的图像帧保持一致的神经网络模型。
70.其中,第一数据样本是基于双目相机采集到的样本图像帧得到的,第二数据样本是针对单目相机采集的图像帧进行预处理后得到的。
71.在步骤s13中,根据三维点云的像素点的深度值重建三维场景。
72.在具体实施时,在运动过程中具体指配置有单目相机的车辆在行驶过程中,示例地,通过车载单目相机在车辆行驶过程中,采集车辆行驶方向上的场景图像数据,进而对图像数据进行分割等操作,将目标对象从场景图像数据中分割出来,并将分割出来的目标对象去除边界噪声,得到在运动过程中的图像帧。又一示例,通过配置有单目相机的移动电子设备,例如智能手机,在车辆行驶过程中,采集车辆行驶方向上的场景图像数据,进而经过分割、去除边界噪声后得到在运动过程中的图像帧。
73.值得说明的是,第二样本数据是在车辆的行驶过程中,通过单目相机采集的图像帧,并对该图像帧进行预处理后得到的。在预处理过程中,由于单目相机没有双目相机的左、右目相机之间的基线、视差作为参考基准,因而采用相邻帧同一像素点在世界坐标系下的距离作为基线,即根据单目相机针对同一像素点采集的相邻图像帧构建类似于双目相机通过左、右目相机计算像素点的三维坐标。
74.进一步地,根据三维点云的像素点的深度值在图像坐标系中重建三维场景,其中三维场景可以包括车辆行驶路面的车道线标识、行驶前进方向上的其他道路参与者,例如,行人、其他车辆,也可以包括道路设施,例如,红绿灯、路灯、栏杆等。
75.采用上述技术方案,通过获取单目相机在运动过程中采集的图像帧;将图像帧输入到深度估计模型中,得到深度估计模型输出的场景中的三维点云的像素点的深度值,深度估计模型是根据第一数据样本进行预训练后,再根据第二数据样本进行域适应模型微调后得到的尺度与所述单目相机采集的图像帧保持一致的神经网络模型,第一数据样本是基于双目相机采集到的样本图像帧得到的,第二数据样本是针对单目相机采集的图像帧进行预处理后得到的;根据三维点云的像素点的深度值重建三维场景。这样,基于单目相机采集
的图像帧进行预处理后得到的第二数据样本,对预训练后深度估计模型进行域适应模型微调,实现模型的尺度与单目相机采集的图像帧保持一致,能够提高迁移学习的模型在单目相机采集的图像进行场景重建时的性能,避免域差异带来的尺度偏移,进而提高三维场景重建的准确性,提高车辆自动驾驶的安全性能。
76.在上述实施例的基础上,图2是根据一示例性示出的一种实现图1中步骤s12的流程图,参考图2所示,在步骤s12中,针对单目相机采集到的图像帧进行的预处理,包括以下步骤。
77.在步骤s121中,获取单目相机在运动过程中的不同采集位置的位姿信息、以及不同采集位置之间的距离。
78.在步骤s122中,根据位姿信息、距离以及单目相机的内参,对单目相机在不同采集位置采集到的图像帧中相同的像素点做三角化处理,得到对应该像素点的深度值。
79.可以说明的是,此处所说的距离为单目相机之间的真实距离。具体地,实时获取单目相机在车辆的行驶运动过程中,在不同采集位置的位姿信息,通过刚体转换矩阵将相机坐标系下的单目相机的位置转换到世界坐标系下,进而在世界坐标系中确定单目相机在不同采集位置之间的距离。
80.示例地,在车辆的行驶过程中,获取单目相机在采集第一个图像帧时的位姿信息,并获取单目相机在采集第二个图像帧时的位姿信息,其中,第一个图像帧与第二个图像帧为相邻图像帧。根据采集第一个图像帧时单目相机的位姿信息,通过刚体转换矩阵将其在相机坐标系下的位置转换到世界坐标系下,并根据采集第二个图像帧时单目相机的位姿信息,通过刚体转换矩阵将其在相机坐标系下的位置转换到世界坐标系下,进而在世界坐标系下,确定采集第一个图像帧时与采集第二个图像帧时,单目相机之间的距离。
81.采用上述技术方案,可以基于位姿信息、距离以及单目相机的内参,对单目相机在不同采集位置采集到的图像帧中相同的像素点做三角化处理,得到对应该像素点的深度值,这样,可以确定不同图像帧中同一像素点的深度值,提升确定像素点的深度值的准确性。
82.在上述实施例的基础上,图3是根据另一示例性示出的一种实现图1中步骤s12的流程图,参考图3所示,在步骤s12中,根据所述第二数据样本进行的域适应模型微调,包括以下步骤。
83.在步骤s1201中,针对预训练完成的所述深度估计模型,将所述第二数据样本输入所述深度估计模型,得到所述深度估计模型输出的像素点深度的预测值;
84.在步骤s1202中,将对所述图像帧进行预处理后得到的像素点的深度值作为真值,根据所述真值与所述预测值对所述深度估计模型进行域适应微调,以得到尺度与所述单目相机采集的图像帧保持一致的神经网络模型。
85.试验发现,预训练后的深度估计模型输出的像素点的数量大于第二数据样本中的三维点云的像素点的数量,即第二数据样本是较为稀疏的三维点云的像素点的深度值,深度估计模型后输出较为稠密的三维点云的像素点的深度值。可见,预训练后的深度估计模型可以对第二数据样本中缺失的关键三维点云的像素点进行补充,并确定出该补充的像素点的深度值。
86.进一步地,计算对单目相机采集的图像帧进行预处理后得到的像素点的深度值与
深度估计模型输出的像素点深度的预测值之间的差值,根据该差值对深度估计模型进行域适应微调,以得到尺度与所述单目相机采集的图像帧保持一致的神经网络模型。
87.采用上述技术方案,通过预训练后的深度估计模型输出稠密的三维点云的像素点深度值,并基于该稠密的三维点云的深度值对预训练后的深度估计模型进行域适应微调,以得到尺度与所述单目相机采集的图像帧保持一致的神经网络模型,可以实现模型的域适应,提高深度估计模型在无双目相机、imu和激光雷达时估计三维点云像素点的深度值的性能。
88.在上述实施例的基础上,所述深度估计模型在预训练过程中采用第一损失函数,所述第一损失函数用于计算所述第一数据样本中各样本图像帧的光度误差和/或绝对误差,所述深度估计模型在域适应模型微调过程中采用第二损失函数,所述第二损失函数用于在所述光度误差和/或所述绝对误差的基础上,计算对所述第二数据样本中的图像帧进行预处理后得到的像素点的深度值与所述深度估计模型输出的预测值之间的误差;和/或,所述深度估计模型在域适应模型微调过程中的学习率参数小于所述深度估计模型在预训练过程中的学习率参数。
89.在具体实施时,通过多目相机采集第一数据样本,例如,通过双目相机采集第一数据样本。
90.在一种实施方式中,基于第一损失函数,针对第一数据样本中图像帧i
t
中的像素点p,通过imu确定像素点p与第一数据样本中任意图像帧is之间的相对位姿t
gt
,并且在图像帧is中可以对应找到像素点p的投影像素点p1,其中,像素点p和投影像素点p1对应三维空间中的同一个目标对象。且像素点p与投影像素点p1满足如下关系式:
91.p1~k*t
gt
*d
t
(p)*k-1
92.其中,k为相机内参,d
t
(p)为像素点p的深度值,其中,d
t
(p)是由模型估计得出的。
93.进一步地,由于像素点p和投影像素点p1对应三维空间中的同一个目标对象,像素点p和投影像素点p1的像素值原则上应该是相等的,但是模型估计存在误差,因而,像素点p和投影像素点p1的像素值之间的差值可以作为光度误差l
ph
,参见如下公式:
94.l
ph
=|i
t
(p)-is(p1)|
95.其中,i
t
(p)为像素点p的像素值,is(p1)为投影像素点p1的像素值。
96.在另一种实施方式中,基于第一损失函数,针对第一数据样本中图像帧i
t
中的像素点p,通过双目相机或者多目相机确定像素点的深度值,示例地,基于双目相机的左目相机和右目相机的相机参数,具体为基于左、右目相机的焦距,左、右目相机的视差以及左、右目相机的基线,视差即左、右目相机的成像点之间的距离,基线即左、右目相机的光心的距离,确定双目相机采集的图像帧i
t
中的像素点p的三维坐标。其中,左目相机和右目相机位于同一平面,即光轴平行,并且左目相机和右目相机的相机参数一致。
97.进一步地,根据像素点p的三维坐标,以及双目相机或者多目相机采集的第一数据样本中图像帧is中像素点p1的三维坐标,确定采集图像帧i
t
与采集图像帧is时,双目相机或者多目相机的相对位姿,并确定图像帧i
t
中像素点p与采集图像帧is中像素点p1的深度值之间的差值,该差值即为光度误差。
98.针对绝对误差,基于第一损失函数,通过深度探测器,例如激光雷达,获得第一数据样本中像素点的稀疏深度值,并根据像素点的深度值以及像素点的稀疏深度值确定绝对
误差。
99.在一种实施方式中,通过如下公式计算得到像素点的绝对误差l
sp
:
[0100][0101]
其中,d
t1
(p)为像素点的稀疏深度值。
[0102]
进一步地,深度估计模型在预训练过程中的学习率参数为深度估计模型在域适应模型微调过程中的学习率参数的10-100倍。
[0103]
在上述实施例的基础上,图4是根据一示例性示出的一种实现图2中步骤s121的流程图,参考图4所示,在步骤s121中,所述获取所述单目相机在所述运动过程中的不同采集位置的位姿信息,包括:
[0104]
在步骤s1211中,提取所述单目相机在所述不同位置采集的图像帧的像素点特征。
[0105]
在步骤s1212中,根据所述像素点特征确定所述不同位置采集的图像帧的像素点之间的对应关系,得到像素点特征对。
[0106]
在步骤s1213中,根据所述像素点特征对确定所述单目相机在所述不同采集位置的位姿信息。
[0107]
具体地,上述所说的图像帧是从图像数据流中得到的图像序列,图像序列中每一图像帧中像素点均具有纹理特征,例如,像素点的梯度、局部二值模式和灰度共生矩阵等。在具体实施时,可以提取单目相机在不同位置采集的图像帧的像素点的纹理特征,进而根据像素点的纹理特征确定多个像素点是否为同一目标对象在不同位置采集时图像帧中的像素点,并在像素点为同一目标对象在不同位置采集时图像帧中的像素点的情况下,确定该多个像素点为像素点特征对。
[0108]
可以理解的是,像素点特征对可以仅包括两个像素点,也可以包括两个以上的像素点。仅在两个图像帧中采集到同一目标对象的图像数据,则该像素点特征对仅包括两个像素点,而在两个以上图像帧中采集到同一目标对象的图像数据,则该像素点特征对包括两个以上的像素点。
[0109]
示例地,参考图5所示,image1、image2和image3分别是单目相机在不同采集位置采集到的连续三帧的图像帧,image1、image2和image3表示的是目标对象在单目相机的相机成像,例如,image1中的像素点a1是在第一采集位置上目标对象在单目相机的成像平面的像点,同理,image2中的像素点a2是在第二采集位置上目标对象在单目相机的成像平面的像点,image3中的像素点a3是在第一采集位置上目标对象在单目相机的成像平面的像点。
[0110]
进一步地,可以基于像素点的纹理特征,或者基于sfm(structure from motion)算法,确定image1中的像素点a1、image2中的像素点a2以及image3中的像素点a3,是否为同一目标对象在不同采集位置在单目相机的成像平面的像点。
[0111]
进一步地,在确定image1中的像素点a1与image2中的像素点a2为同一目标对象在不同采集位置在单目相机的成像平面的像点的情况下,确定像素点a1与像素点a2为像素点特征对,进一步地,在确定image2中的像素点a2与image3中的像素点a3为同一目标对象在不同采集位置在单目相机的成像平面的像点的情况下,确定像素点a1、a2与像素点a3为像素点特征对。同理,采用增量式的方式,确定后续采集的图像帧中是否存在同一目标对象在
不同采集位置在单目相机的成像平面的像点。
[0112]
采用上述技术方案,可以基于sfm等方式确定不同位置采集的图像帧的像素点之间的对应关系,得到像素点特征对,进而确定单目相机在不同采集位置的位姿信息。可以在未配置imu的情况下,准确地确定单目相机在不同采集位置的位姿信息。
[0113]
可选地,所述单目相机包括全球定位系统模块,或者所述单目相机安装在包括全球定位系统模块的运动物体上;相应地,所述单目相机在所述不同采集位置之间的距离是通过所述全球定位系统模块在所述不同采集位置的定位信号确定的。
[0114]
在具体实施时,全球定位系统模块可以根据单目相机采集图像帧时的时间节点,确定单目相机所处的经纬度,进而根据采集各图像帧时单目相机的经纬度,确定单目相机在不同采集位置之间的距离。
[0115]
采用上述技术方案,可以基于全球定位系统模块在不同采集位置的定位信号确定单目相机在不同采集位置之间的距离,可以提高确定单目相机在不同采集位置之间的距离的便捷性和准确性。
[0116]
在上述实施例的基础上,图6是根据一示例性示出的一种实现图2中步骤s122的流程图,参考图6所示,在步骤s1202中,所述根据所述位姿信息、所述距离以及所述单目相机的内参,对所述单目相机在所述不同采集位置采集到的图像帧中相同的像素点做三角化处理,得到对应该像素点的深度值,包括:
[0117]
在步骤s1221中,针对所述单目相机在所述不同采集位置采集到的图像帧中相同的像素点,设定三维像素点,并针对在所述不同采集位置采集到的每一图像帧,通过所述单目相机的内参以及对应的所述位姿信息,计算所述三维像素点投影到该图像帧上的投影点的二维坐标与该像素点在该图像帧上的二维坐标之间的误差,直到设定的三维像素点使得计算得到的误差总和最小,得到目标三维像素点。
[0118]
在步骤s1222中,根据目标三维像素点以及距离,通过几何计算得到该像素点的深度值。
[0119]
在具体实施时,参考图7所示,沿用图5的实施例进行说明,针对image1、image2、image3中的像素点a1、a2和a3,设定一三维像素点p,其三维坐标例如为(x,y,z),进而根据单目相机的内参,以及单目相机在采集image1、image2、image3时分别的位姿信息,计算三维像素点分别在image1、image2、image3中的投影点的二维坐标(即所述单目相机的成像坐标系的投影点的二维坐标,例如计算得到的二维坐标分别为(x
p1
,y
p1
)、(x
p2
,y
p2
)、以及(x
p3
,y
p3
)。进一步地,计算像素点a1在image1中的二维坐标与三维像素点在image1中的投影点的二维坐标(x
p1
,y
p1
)之间的误差,计算像素点a2在image2中的二维坐标与三维像素点在image2中的投影点的二维坐标(x
p2
,y
p2
)之间的误差,计算像素点a3在image3中的二维坐标与三维像素点在image3中的投影点的二维坐标(x
p3
,y
p3
)之间的误差,并对计算得到的误差计算总和。这样,通过多次设定三维像素点,并计算误差总和,可以将误差总和最小或者满足预设的误差总和阈值条件的三维像素点作为目标三维像素点。
[0120]
可以理解的是,像素点a1、像素点a2以及像素点a3为单目相机在不同采集位置采集到的同一目标对象在相邻图像帧中的像素点,该目标三维像素点的三维坐标即为该同一目标对象的三维坐标。同理,针对单目相机采集到的图像帧中的其他像素点,也可以采用上述方式确定该其他像素点对应的目标三维像素点。
[0121]
进一步地,根据目标三维像素点p的三维坐标以及单目相机在不同采集位置之间的距离,通过三角几何计算得到该像素点的深度值。
[0122]
图8是根据一示例性示出的一种从预训练深度估计模型到微调深度估计模型的示意图。如图8所示,在预训练过程中,深度估计模型的第一数据样本是基于双目相机、imu以及激光雷达采集的图像作为尺度约束,具体地,通过imu确定前、后图像帧中同一目标对象像素点的之间的相对位移,以及基于双目相机的左、右目相机和相机内参,例如基线、焦距等,确定图像帧中每一像素点的深度值,以及通过激光雷达确定深度图,并进而得到第一数据样本。基于第一损失函数以及第一数据样本,对深度估计模型进行预训练。并将预训练后的深度估计模型通过迁移学习到单目相机。
[0123]
进一步地,在域适应模型微调过程中,深度估计模型的第二数据样本是基于单目相机采集的图像作为尺度约束,具体地,对单目相机采集的前、后图像帧的单目相机的相对位姿,并基于gps作为约束,对图像帧进行约束,得到第二数据样本。进而通过第二数据样本对预训练后的深度估计模型进行域适应模型微调。进而基于微调后的深度估计模型得到单目相机采集的目标对象对应的稠密的三维点云的像素点的深度值,并三维点云的像素点的深度值重建三维场景。如图8,重建后的三维场景深度尺度与实际尺度相差较小,拍摄目标对象的尺度偏移较小,从而提高了深度估计模型的实用性。
[0124]
图9是根据一示例性实施例示出的一种三维场景的示意图,图10是相关技术中根据迁移学习的深度估计模型重建后的三维场景图,图11以及图12是根据本公开的三维场景重建方法重建后的三维场景图。
[0125]
可见,在图11的三维场景图中,在距离车辆较远处的左侧道路护栏较为模糊,并且右侧路灯杆的大小相较于真实路灯杆的大小偏大,与之相对的,本公开在距离车辆较远处的左侧道路护栏较为清晰,并且右侧路灯杆的大小更接近真实路灯杆的大小。并且,如图12所示,本公开可以重建出道路路面标识的三维场景。
[0126]
采用上述技术方案,可以通过连续图像帧中像素点特征对确定像素点的深度值,可以解决单目相机无双目的基线以及视觉差,无法确定目标对象对应像素点的深度值的问题,进而可以通过该三维点云的深度值对深度估计模型进行域适应微调,实现模型的尺度与单目相机采集的图像帧保持一致,能够提高迁移学习的模型在单目相机采集的图像进行场景重建时的性能,避免域差异带来的尺度偏移,进而提高三维场景重建的准确性,提高车辆自动驾驶的安全性能。
[0127]
基于相同的发明构思,本公开还提供一种三维场景重建装置,用于执行上述方法实施例提供的三维场景重建方法的步骤,该装置可以以软件、硬件或者两者相结合的方式实现三维场景重建方法。图13是根据一示例性实施例示出的一种三维场景重建装置100的框图,如图13所示,所述装置100包括:获取模块110,输入模块120和重建模块130。
[0128]
其中,获取模块110,被配置为用于获取单目相机在运动过程中采集的图像帧;
[0129]
输入模块120,被配置为用于将所述图像帧输入到深度估计模型中,得到所述深度估计模型输出的场景中的三维点云的像素点的深度值,其中,所述深度估计模型是根据第一数据样本进行预训练后,再根据第二数据样本进行域适应模型微调后得到的尺度与所述单目相机采集的图像帧保持一致的神经网络模型,其中,所述第一数据样本是基于双目相机采集到的样本图像帧得到的,所述第二数据样本是针对单目相机采集的图像帧进行预处
理后得到的;
[0130]
重建模块130,被配置为根据所述三维点云的所述像素点的深度值重建三维场景。
[0131]
上述装置,基于单目相机采集的图像帧进行预处理后得到的第二数据样本,对预训练后深度估计模型进行域适应模型微调,实现模型的尺度与单目相机采集的图像帧保持一致,能够提高迁移学习的模型在单目相机采集的图像进行场景重建时的性能,避免域差异带来的尺度偏移,进而提高三维场景重建的准确性,提高车辆自动驾驶的安全性能。
[0132]
可选地,所述输入模块120,被配置为用于针对单目相机采集到的图像帧进行的预处理,包括:
[0133]
获取所述单目相机在所述运动过程中的不同采集位置的位姿信息、以及所述不同采集位置之间的距离;
[0134]
根据所述位姿信息、所述距离以及所述单目相机的内参,对所述单目相机在所述不同采集位置采集到的图像帧中相同的像素点做三角化处理,得到对应该像素点的深度值。
[0135]
可选地,所述输入模块120,被配置为用于根据所述第二数据样本进行的域适应模型微调,包括:
[0136]
针对预训练完成的所述深度估计模型,将所述第二数据样本输入所述深度估计模型,得到所述深度估计模型输出的像素点深度的预测值;
[0137]
将对所述图像帧进行预处理后得到的像素点的深度值作为真值,根据所述真值与所述预测值对所述深度估计模型进行域适应微调,以得到尺度与所述单目相机采集的图像帧保持一致的神经网络模型。
[0138]
可选地,所述深度估计模型在预训练过程中采用第一损失函数,所述第一损失函数用于计算所述第一数据样本中各样本图像帧的光度误差和/或绝对误差,所述深度估计模型在域适应模型微调过程中采用第二损失函数,所述第二损失函数用于在所述光度误差和/或所述绝对误差的基础上,计算对所述第二数据样本中的图像帧进行预处理后得到的像素点的深度值与所述深度估计模型输出的预测值之间的误差;和/或,所述深度估计模型在域适应模型微调过程中的学习率参数小于所述深度估计模型在预训练过程中的学习率参数。
[0139]
可选地,所述输入模块120,被配置为用于提取所述单目相机在所述不同位置采集的图像帧的像素点特征;
[0140]
根据所述像素点特征确定所述不同位置采集的图像帧的像素点之间的对应关系,得到像素点特征对;
[0141]
根据所述像素点特征对确定所述单目相机在所述不同采集位置的位姿信息。
[0142]
可选地,所述单目相机包括全球定位系统模块,或者所述单目相机安装在包括全球定位系统模块的运动物体上;相应地,所述单目相机在所述不同采集位置之间的距离是通过所述全球定位系统模块在所述不同采集位置的定位信号确定的。
[0143]
可选地,所述输入模块120,被配置为用于:
[0144]
针对所述单目相机在所述不同采集位置采集到的图像帧中相同的像素点,设定三维像素点,并针对在所述不同采集位置采集到的每一图像帧,通过所述单目相机的内参以及对应的所述位姿信息,计算所述三维像素点投影到该图像帧上的投影点的二维坐标与该
signal processor,简称dsp)、数字信号处理设备(digital signal processing device,简称dspd)、可编程逻辑器件(programmable logic device,简称pld)、现场可编程门阵列(field programmable gate array,简称fpga)、控制器、微控制器、微处理器或其他电子元件实现,用于执行上述的三维场景重建方法。
[0155]
在另一示例性实施例中,还提供了一种包括程序指令的计算机可读存储介质,该程序指令被处理器执行时实现上述的三维场景重建方法的步骤。例如,该计算机可读存储介质可以为上述包括程序指令的存储器702,上述程序指令可由电子设备700的处理器701执行以完成上述的三维场景重建方法。
[0156]
以上结合附图详细描述了本公开的优选实施方式,但是,本公开并不限于上述实施方式中的具体细节,在本公开的技术构思范围内,可以对本公开的技术方案进行多种简单变型,这些简单变型均属于本公开的保护范围。
[0157]
另外需要说明的是,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本公开对各种可能的组合方式不再另行说明。
[0158]
此外,本公开的各种不同的实施方式之间也可以进行任意组合,只要其不违背本公开的思想,其同样应当视为本公开所公开的内容。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1