基于无监督学习的内窥镜图像增强方法
1.本发明涉及医学图像增强及计算机网络技术领域,特别涉及一种基于无监督学习的内窥镜图像增强方法。
背景技术:
2.内窥镜成像是一种诊断和医疗程序。医生通过电子内窥镜能直接观察到人体内脏器官的组织形态及病变情况。内窥镜已广泛应用于胃、肠等食管消化系统的检查、诊断和治疗。内窥镜图像的质量直接影响医生对疾病的准确分析和诊断。然而,由于照明条件的限制和人体内脏器官的复杂环境的限制,由内窥镜直接获得的图像往往存在纹理特征弱、亮度不均匀、对比度低等问题,导致一些人体内的组织形态特征的缺失。从而影响医生对疾病分析和诊断的准确度。因此,内窥镜图像增强的研究对于辅助医生诊断具有重要意义。
3.近年来,研究人员提出了一些经典的图像增强方法来提高内窥镜图像的质量。随着深度学习的迅速发展,深度卷积神经网络逐渐成为图像增强领域的主要驱动力。此类方法通过对深度卷积神经网络的学习,建立低质图像与高质量图像之间复杂的非线性映射关系,从而达到增强低质图像的目的。由于内窥镜图像的复杂特点,内窥镜图像增强技术的研究主要集中在光照调节、对比度和清晰度的提高等方面。内窥镜图像增强作为图像增强中的难点,现有方法无法获得对比度增强、亮度均匀、清晰度高、颜色自然性等综合性能,对于内窥镜图像增强效果不佳。
技术实现要素:
4.本发明的目的在于针对已有技术的不足,提出一种基于无监督学习的内窥镜图像增强方法,是一种基于python语言、matlab语言和pytorch框架的用于对内窥镜图像进行增强的方法,该方法不仅使内窥镜图像中的有用细节信息和色彩信息更丰富,还提高图像对比度和清晰度。
5.为达到上述目的,本发明采用如下的技术方案:
6.一种基于无监督学习的内窥镜图像增强方法,其步骤如下:
7.步骤1:对原始内窥镜图像数据集进行预处理,利用三种图像增强技术处理原始图像得到三张派生图;
8.步骤2:将原始内窥镜图像和其对应的派生图转换到hsi颜色空间,保持h通道图像不变,将派生图的i通道图像输入无监督学习网络derivedfuse,进行深度网络模型训练;
9.步骤3:根据网络训练后得到的训练参数,得到i通道图像增强结果;
10.步骤4:对原始内窥镜图像的s通道图像进行自适应非线性拉伸处理,并将hsi颜色空间图像转换回rgb颜色空间输出最终增强图像;
11.优选地,所述步骤1的预处理包括如下操作:
[0012]1‑
1:调整原始内窥镜图像的分辨率为256
×
256像素;
[0013]1‑
2:利用三种经典的图像增强技术
‑
clahe、gamma和lime来处理原始图像得到相
应的派生图;
[0014]1‑
3:将得到的数据集按3:1:1的比例划分训练集、验证集和测试集。
[0015]
优选地,所述步骤2的网络模型训练包括如下操作:
[0016]2‑
1:将rgb颜色空间转换到hsi颜色空间;
[0017]2‑
2:无监督学习网络derivedfuse由三个部分组成,分别是特征提取、特征融合和重建。将数据集中的派生图的i通道图像输入无监督学习网络进行训练,最终得到预测图;
[0018]2‑
3:目标函数为non
‑
reference损失函数,其值受输入网络图像的luminance,contrast和structure三个分量影响;
[0019]2‑
4:网络模型采用学习率为0.002的优化算法,总共训练100个epochs。
[0020]
优选地,所述步骤3的i通道图像增强结果包括如下操作:
[0021]3‑
1:经过100个epochs的训练后,得到对应的网络模型训练参数;
[0022]3‑
2:将测试集输入训练好的网络模型,得到模型预测的i通道增强图。
[0023]
优选地,所述步骤4的自适应非线性拉伸包括如下操作:
[0024]4‑
1:计算原始内窥镜图像在rgb颜色空间,对应像素点的r、g、b颜色分量的最大值m(r,g,b)、最小值m(r,g,b)和平均值mean(r,g,b);
[0025]4‑
2:对原始内窥镜图像在hsi颜色空间s通道图像信息s
original
进行自适应非线性拉伸处理,得到饱和度调整的s通道图s
enhanced
;
[0026]4‑
3:将步骤3
‑
2得到的亮度分量和步骤4
‑
2得到的饱和度分量整合原始色调分量,并反转换至rgb颜色空间得到最终增强图像。
[0027]
本发明与现有技术相比较,具有如下显而易见的突出实质性特点和显著优点:
[0028]
1、本发明方法将gamma图像、clahe图像和lime图像的优点与深度学习相结合,提出了一种无监督的派生图像融合网络derivedfuse,用于派生图的精细细节融合。该模型能准确地提取并融合派生图的有用特征,而不需要groundtruth。
[0029]
2、与现有方法相比,本发明能使增强后图像对比度强、细节清晰、颜色丰富且自然,明显改善了内窥镜图像的视觉效果,对于临床具有重要的意义。
附图说明
[0030]
图1为本发明方法的程序框图。
[0031]
图2为本发明方法的整体流程图。
[0032]
图3为本发明无监督学习网络derivedfuse架构。
[0033]
图4为本发明方法训练的网络模型对内窥镜图像数据集的增强结果图。
[0034]
图5为本发明方法训练的网络模型对内窥镜图像数据集的预测得到增强结果图与多个现有方法的结果对比图。
具体实施方式
[0035]
以下结合附图对本发明的优选实施例进行详细的说明。
[0036]
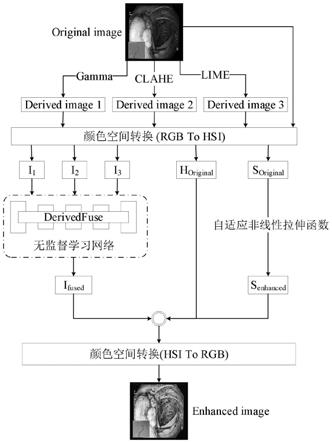
参见图1,一种基于无监督学习的内窥镜图像增强方法,包含以下操作步骤:
[0037]
步骤1:对原始内窥镜图像数据集进行预处理,利用三种图像增强技术处理原始图像得到三张派生图,包括如下操作:
[0038]1‑
1:调整原始内窥镜图像的分辨率为256
×
256像素;
[0039]1‑
2:利用三种经典的图像增强技术
‑
clahe、gamma和lime来处理原始图像相应的派生图;
[0040]1‑
3:将得到的数据集按3:1:1的比例划分训练集、验证集和测试集。
[0041]
步骤2:将rgb颜色空间的原始内窥镜图像和其对应的派生图转换到hsi颜色空间,保持h通道图像不变,将派生图的i通道图像输入无监督学习网络,进行深度网络模型训练,包括如下操作:
[0042]2‑
1:将rgb颜色空间转换到hsi颜色空间,转换公式如下:
[0043][0044]
其中,r、g、b分别代表rgb颜色空间的红、绿、蓝颜色分量,h、s、i分别代表hsi颜色空间的色度分量、饱和度分量、亮度分量。
[0045]2‑
2:无监督学习网络derivedfuse由三个部分组成,分别是特征提取、特征融合和重建。将数据集中的派生图的i通道图像输入无监督学习网络进行训练,最终得到预测图,完整的网络结构如图3所示:
[0046]
本发明提出的derivedfuse网络模型主要由特征提取、特征融合和重建3部分组成。
[0047]
特征提取模块由两层部分卷积层组成。设置的第一层卷积核的尺寸为5
×
5,通道数为16。第二层卷积核的尺寸为7
×
7,通道数为32。5
×
5的卷积核可用来提取图像低级特征。7
×
7的卷积核感受野加大,用于捕获图像更复杂,更抽象的信息。通过不同尺度的卷积提取特征图,便可以从三种派生图像亮度分量中提取出数据不同方面的特征,使网络训练速度提高。
[0048]
特征融合模块简单地通过融合层将多个特征图各个像素相加来组合各个特征图。利用融合层对l21,l22和l23的特征进行融合,融合的图像尺寸不变,为256
×
256,包含了32个通道。
[0049]
对于图像的重建模块,本发明使用u
‑
net模型提取图像的深层特征,分别包含了7个上采样层和下采样层。网络输入的是通道数为64,大小为256
×
256的特征图。输出的是通道数为1,大小为256
×
256的亮度图。7层下采样卷积层使用4
×
4的卷积核,stride为2,padding为1,并且采用了leaky leru激活函数。前六个上采样卷积层使用的卷积核的大小为4
×
4,stride为2,padding为1,并且采用了leru激活函数。最后一次反卷积层使用tanh激
活函数以产生最终得到细节保存更完整的亮度图像。
[0050]2‑
3:目标函数为non
‑
reference损失函数,其值受输入网络图像的luminance,contrast和structure三个分量影响;
[0051]
所述目标函数表达式如下:
[0052][0053]
其中,i
f
表示实际从derivedfuse输出的融合图像中同一空间位置提取的图像patch,代表期望的融合图像patch。为的方差。为和i
f
的协方差。c代表常数。的计算公式为计算公式为和分别表示期望的luminance,contrast和structure分量。
[0054]
ssim将任何给定的图像patch分解为luminance,contrast和structure三个分量,则派生图n在hsi颜色空间i通道图像中的相同空间位置提取的输入图像patches i
n
可由公式(3)表示:
[0055][0056]
其中,n表示派生图数量。||
·
||表示向量的l2范数。表示i
n
的平均值。l
n
,c
n
和s
n
分别表示i
n
的luminance、contrast和structure分量。
[0057]
为了获得高对比度的融合图像,选取hsi颜色空间i通道中三个不同图像块的最大对比度作为i
f
的期望contrast的期望contrast的详细表达式如下:
[0058][0059]
其中,max表示取均值。
[0060]
为了融合clahe派生图和lime派生图的纹理结构信息,期望的structure的详细表达式如下:
[0061][0062]
为了获得高亮度的融合图像,选取hsi颜色空间i通道中三个不同图像块的亮度均值作为i
f
的期望luminance的期望luminance的详细表达式如下:
[0063][0064]
其中,mean表示取均值。
[0065]2‑
4:网络模型采用学习率为0.002的优化算法,总共训练100个epochs。
[0066]
步骤3:根据网络训练后得到的训练参数,得到i通道图像增强结果,包括如下操作:
[0067]3‑
1:经过100个epochs的训练后,得到对应的网络模型训练参数;
[0068]3‑
2:将测试集输入训练好的网络模型,得到模型预测的i通道增强图i
fused
。
[0069]
步骤4:对原始内窥镜图像的s通道图像进行自适应非线性拉伸处理,并将hsi颜色空间图像转换回rgb颜色空间输出最终增强图像,包括如下操作:
[0070]4‑
1:计算原始内窥镜图像在rgb颜色空间,对应像素点的r、g、b颜色分量的最大值m(r,g,b)、最小值m(r,g,b)和平均值me(r,g,b);
[0071]4‑
2:对原始内窥镜图像在hsi颜色空间s通道图像信息s
original
进行自适应非线性拉伸处理,得到饱和度调整的s通道图s
enhanced
,本发明所构建的自适应非线性拉伸函数定义为:其中,m(r,g,b)可通过matlab中函数max来获取,m(r,g,b)可通过matlab中函数min来获取,me(r,g,b)则可通过计算图像三通道各像素点的像素值总和除以图像总的像素点数来获取;
[0072]4‑
3:如图2所示,将3
‑
2得到的亮度分量i
fused
和4
‑
2得到的饱和度分量s
enhanced
整合原始色调分量,并反转换至rgb颜色空间得到最终增强图像,转换到rgb颜色空间公式如下:
[0073][0074]
其中,r、g、b分别代表rgb颜色空间的红、绿、蓝颜色分量,h、s、i分别代表hsi颜色空间的色度分量、饱和度分量、亮度分量。
[0075]
本实施例方法能准确地提取并融合派生图的有用特征,而不需要ground truth就可完成内窥镜图像的增强。
[0076]
本实施例方法从公共内窥镜数据集kvasir dataset、kvasir
‑
seg、cvc
‑
clinicdb、etis
‑
larib polyp db、cvc
‑
endoscenestill以及cvc
‑
clinicspec选取一部分图像来进行网络效率的验证。采用本发明方法对内窥镜图像进行增强处理,并与直方图均衡化算法(he)、限制对比度自适应直方图均衡(clahe)、单尺度retinex算法(ssr)、带彩色恢复的多尺度retinex算法(msrcr)、带有色彩保护的多尺度retinex(msrcp)、基于rubost retinex分解模型的structure
‑
revealing弱光增强方法(rrm)、通过估计低亮度的图像的光照图增
强图像的方法(lime)、自适应伽马校正加权分布(agcwd)、al
‑
ameen提出方法以及无监督学习方法zero
‑
dce、zero
‑
dce++、enlightengan进行增强效果对比。本发明方法的增强效果如图4所示。由图4增强结果可以看出,本发明方法相在对比度、清晰度和饱和度方面都有显著的提高,具有很高的临床应用价值。图5是本发明方法和现有方法的预测结果的比较。由图5对比结果可以看出,本发明方法处理内窥镜图像对于图像纹理细节的增强效果更加优秀,具有最好的视觉效果。
[0077]
上面对本发明实施例结合附图进行了说明,但本发明不限于上述实施例,还可以根据本发明的发明创造的目的做出多种变化,凡依据本发明技术方案的精神实质和原理下做的改变、修饰、替代、组合或简化,均应为等效的置换方式,只要符合本发明的发明目的,只要不背离本发明的技术原理和发明构思,都属于本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1