一种基于改进YOLOv5模型的丝饼缺陷检测方法
一种基于改进yolov5模型的丝饼缺陷检测方法
技术领域
1.本发明涉及深度学习、计算机视觉领域,具体的说是一种基于改进yolov5模型的丝饼缺陷检测方法。
背景技术:
2.我国作为最大的氨纶生产国,随着制造业的不断发展,智能装配系统被广泛应用到自动化生产线上。在生产丝饼的生产流水线上,丝饼要经过卷丝、落筒、输送、储存、检测分类、包装等多个流程,因此,丝饼不可避免的会出现一些缺陷。目前,对丝饼缺陷的检测主要采用人工方式,人为因素影响较大,且工作劳动强度大,生产效率和精确度十分低下,无法满足大规模自动化生产的需求,氨纶丝饼的产量和质量受到严重制约。因此,为了提高生产效率,降低人力成本投入,研发出能够适应工厂环境中光线等不稳定因素,同时确保精度和速度的智能丝饼检缺陷测方法势在必行。
3.随着深度学习的飞速发展,计算机视觉技术取得了令人瞩目的成果,尤其是物体检测这一基础又核心的需求,诞生了众多经典算法,在自动驾驶、智能安防以及智能装配等多个领域都得到了广泛应用。其中,yolo因为其较快的检测速度,在工业界应用极为广泛,尤其是在不追求预测框高精度的场景下,与其他检测算法精度相同时,可以达到3到4倍的前向速度,是一个十分适合实际应用的检测框架。yolov5是一种单阶段目标检测算法,该算法在yolov4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。
4.以上算法虽然自动化程度较高,但是对于丝饼缺陷中目标较小时仍然会很大程度上影响算法的检测精度。因此,需要有一种能准确识别和定位丝饼缺陷的检测方法,以适用于各种复杂条件下的缺陷检测。
技术实现要素:
5.针对上述技术不足,对丝饼检测的研究需要提高目标检测精度,同时,保证较高的检测速度。本发明解决其技术问题所采用的技术方案是:
6.一种基于改进yolov5算法的目标检测方法,建立基于yolov5算法构建改进型yolov5神经网络结构并训练优化模型,用于丝饼缺陷的实时检测,所述该方法包括:
7.步骤1、获取包含缺陷的丝饼检测图像数据,并进行数据预处理得到缺陷图像数据样本集;
8.步骤2、基于yolov5算法构建改进型yolov5神经网络结构,得到改进yolov5算法;
9.步骤3、利用所述样本集数据对所述改进yolov5算法进行训练,将训练后最佳的权重参数加载至改进yolov5算法得到优化的丝饼缺陷目标检测模型;
10.步骤4、现场采集待检测图像并进行图像预处理,然后输入优化的丝饼缺陷目标检测模型,自动输出对应的缺陷目标检测结果;所述目标检测结果包括待检测图像中缺陷目标区域的位置以及每个目标区域对应的类别,其中目标区域的缺陷类别为绊丝、油污、成型
不良。
11.所述改进型yolov5网络结构包括特征提取骨干网络backbone模块、用于预测分类和目标边界框head模块;所述特征提取骨干网络backbone模块输出3个不同尺度的特征图;其中所述backbone模块包括focus子模块、conv子模块、c3se子模块、spp子模块,所述head模块包括bifpn子模块、detect子模块;
12.所述focus模块对输入的图像进行切片操作,用于特征提取;
13.所述c3se结构是在通道维度引入注意力机制,用于提取不同尺度的特征图;
14.所述spp模块用于融合多尺度的特征;
15.所述bifpn模块,在fpn模块基础上进一步上采样c3se的输出特征进行融合,用于加强网络特征融合能力;
16.所述detect子模块,包括3个分类器,用于将融合特征图输入多分类器进行丝饼缺陷定位及分类,给出缺陷目标预测框。
17.所述步骤1的数据预处理包括:将大小为640
×
640的4张丝饼缺陷的图片采用mosaic数据增强方法进行随机缩放、随机裁剪、随机排布,用于丰富缺陷样本数据集;所述丝饼缺陷包括绊丝、油污、成型不良的图片。
18.所述对图片进行切片操作,是将w、h信息进行分割,用于扩充通道空间,将原先的rgb三通道模式变成了12个通道,然后将得到的新图片再经过3
×
3卷积操作提取特征;w、h分别为宽、高。
19.所述c3模块包括两个分支:y1和y2,其中分支y1由依次连接的conv模块、x个添加shortcut分支的bottleneck模块、conv组成,分支y2由conv组成,最后将2个分支进行concat操作,并依次经过bn层、leakyrelu激活函数、conv模块;所述conv模块由conv、bn、silu激活函数三者组成。
20.所述c3se模块包括c3模块并在通道维度引入注意力机制se模块,通过在feature map层上执行全局平均池化,把原本h
×w×
c的特征,压缩为1
×1×
c,得到当前feature map的全局压缩特征量,每个通道用一个数值表示;通过两个全连接层的bottleneck结构去建模通道间的相关性,得到feature map中每个通道的权值,并将加权后的feature map作为下一层网络的输入;将上一步得到的归一化权重加权到每个通道的特征上,与原始特征图相乘,得到最终特征图输出,完成在通道维度上引入注意力机制。
21.所述spp模块采用5
×
5、9
×
9、13
×
13的最大池化尺寸进行多尺度融合,对输入的特征图分别利用三个最大池化层进行处理,并将不同尺度的特征图与输入进行concat操作,得到池化特征图输出。
22.所述head结构中,在完成特征的初步提取后,增加上采样分支进一步对c3se输出的特征图进行融合,使特征更加具有高语义信息、增强网络特征融合能力,得到预测的特征图。
23.所述detect模块的多个分类器用于接收所述特征融合模块输出的大小为20
×
20的融合特征、大小为40
×
40的融合特征、大小为80
×
80的融合特征,在特征图上应用初始锚框输出预测框,与真实框进行比对,并生成带有类概率、对象置信度得分和目标缺陷预测框的最终输出向量;是采用非极大值抑制nms操作对多目标框进行筛选确定最终的目标缺陷预测框。
24.所述缺陷图像数据样本集中的图像数据要人工预先进行缺陷标注,再按比例分为训练集和验证集,训练集用于训练网络,采用ciou_loss计算bounding box损失函数并与预设阈值比较,从而回调网络参数;所述验证集用于验证模型的泛化能力,得到最佳的权重参数。
25.本发明具有以下优点和有益效果:
26.本发明提供了一种改进yolov5模型的丝饼缺陷检测方法,以解决目前对丝饼缺陷的检测主要采用人工方式检测效率低、效果差的问题,有效的提升丝饼缺陷检测和定位的精度和速度,满足大规模自动化生产的需求。本发明在yolov5的网络架构基础上,引入了注意力机制,用于提取不同尺度的特征图,采用了bifpn结构,用于加强网络特征融合能力,相较于原yolov5算法具有较高的检测速度和小目标检测精度,从而有效提高生产效率,降低了丝饼缺陷检测的错误率。
附图说明
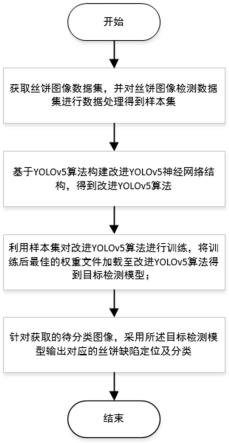
27.图1为本发明方法流程图;
28.图2为本发明的改进yolov5神经网络的结构图。
具体实施方式
29.下面结合实施例对本发明做进一步的详细说明。
30.如图1所示:一种基于yolov5神经网络的丝饼缺陷检测方法,包括以下步骤:
31.步骤1:获取丝饼检测数据集,并对所述丝饼检测数据集进行数据处理得到样本集。
32.丝饼检测数据集总共有6000张图像,包含绊丝、油污、成型不良丝饼各2000个,将数据集中的图片统一缩放为640
×
640分辨率,所有的图像采用labelimg标注出目标区域及类别。样本集中样本标签共三类:当目标区域为绊丝则将其标注为tripwire,表示目标区域的类别为绊丝;当目标区域为油污则将其标注为grease,表示目标区域的类别为油污;当目标区域为成型不良则将其标注为badmolding,表示目标区域的类别为成型不良。
33.并且对丝饼检测数据集进行数据增强处理得到样本集,数据增强处理基于现有方法实现即可,例如mosaic数据增强、labelsmoothing数据增强等方法。
34.mosaic是一种新的混合4幅训练图像的数据增强方法,就是把四张图片拼接为一张图片,并分别对四张图片进行翻转、缩放、色域变化,使四个不同的上下文信息被混合,丰富了图像的上下文信息,这使得网络能够检测正常图像之外的对象,增强模型的鲁棒性。这等于变相的增大了一次训练的图片数量,并且四张图片拼接在一起变相地提高了batch-size,在进行批处理规范化bn层的时候也会计算四张图片,所以对batch-size不是很依赖,可以让batch-size进一步降低,使其在一个gpu上训练就可以达到比较好的效果。
35.步骤2:丝饼图像输入改进型yolov5特征提取骨干网络提取不同尺度的特征图,将融合特征图输入多分类器模块进行丝饼缺陷定位及分类。
36.yolov5算法在检测速度和检测精度方面均具有较优的效果,本实施例在现有的yolov5算法的基础上进行改进,改进的重点为针对yolov5算法中的网络结构进行改进,构建改进型yolov5网络结构,从而得到改进yolov5算法,以提升目标检测效果。
37.如图2所示,本实施例中改进型yolov5网络结构包括包括特征提取骨干网络backbone、head模块。其中backbone模块包括focus模块、c3se模块、spp模块,head模块包括bifpn、detect模块。
38.输入的图片640
×
640
×
3经过预处理后首先经过focus模块,变成320
×
320
×
64的特征图,接着,将输出的320
×
320
×
64的特征图依次通过conv模块、3个包含注意力se block的c3se模块,conv模块、9个包含注意力se block的c3se模块,conv模块、9个包含注意力se block的c3se模块,conv模块、spp模块、3个包含注意力se block的c3se模块,conv模块、3个包含注意力se block的c3se模块,得到一个20
×
20
×
1024的特征图;backbone网络结构输出的大小分别为80
×
80、40
×
40、20
×
20的特征图输入所述特征融合模块bifpn,detect模块基于特征融合模块输出的80
×
80、40
×
40、20
×
20三个尺度的融合特征进行分类检测,输出最终的目标检测结果。
39.具体的,改进yolov5神经网络结构的各个模块如下。
40.1、focus模块
41.输入的图片640
×
640
×
3经过预处理后首先经过focus模块,将w、h信息集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的rgb三通道模式变成了12个通道,最后将得到的新图片再经过3
×
3卷积操作,对其进行特征提取,使得特征提取得更加的充分。虽然增加了一点点的计算量,但是为后续的特征提取保留了更完整的图片下采样信息。采用切片操作,先变成320
×
320
×
12的特征图,再经过一次64个卷积核的卷积操作,最终变成320
×
320
×
64的特征图。
42.2、conv模块
43.本实施例中的标准卷积conv模块,是网络结构中的最小组件,具体包括:conv、bn、silu激活函数。其中conv是一个普通的二维卷积nn.conv2d;bn(batch normalization)本质意思就是在batch和h
×
w维度进行归一化,解决在训练过程中,中间层数据分布发生改变的问题,以防止梯度消失或爆炸、加快网络的训练和收敛的速度,可以看出和batch-size相关,如果batch-size比较小,那么可能统计就不准确。并且由于测试时候batch-size可能和训练不同,导致分布不一致,因此多了两个参数:全局统计的均值和方差值,对batch-size输入计算均值和方差(n、h和w维度求均值),得到维度为c,然后对输入(n,c,h,w)采用计算出来的c个值进行广播归一化操作,最后再乘上可学习的c个权重参数即可;silu(sigmoid weighted liner unit)是较为平滑的激活函数,在深层模型上要优于传统的relu,计算公式为:
[0044][0045]
3、c3se模块
[0046]
与现有技术不同的是,本实施例c3模块的基础上,在通道维度引入了注意力机制se模块,通过在feature map层上执行全局平均池化,把原本h
×w×
c的特征,压缩为1
×1×
c,得到当前feature map的全局压缩特征量,每个通道用一个数值表示;通过全连接层fc、relu,得到1
×1×
c/r(为了减少参数,所以设置了r比率,本实施例中取的是16)大小的特征图;通过全连接层fc、sigmoid,得到1
×1×
c大小的特征图,通过这两个全连接层的结构去建模通道间的相关性,得到feature map中每个通道的权值,并将加权后的feature map作
为下一层网络的输入;将上一步得到的归一化权重加权到每个通道的特征上,与原始特征图相乘,得到最终特征图输出,完成在通道维度上引入注意力机制。通过引入该模块,让神经网络重点关注某些特征通道,即提升对当前任务有用的通道并抑制对当前任务用处不大的特征通道。
[0047]
4、spp模块
[0048]
本实施例中spp模块对输入的大小为20
×
20
×
1024的特征图分别利用5
×
5、9
×
9、13
×
13三个最大池化层进行下采样处理,对于不同的分支,padding大小分别为2、4、6,stride均为1,并将不同尺度的特征图与输入进行concat操作,得到大小为20
×
20
×
1024池化特征图输出。通过采用spp模块的方式,更有效的增加了感受野,显著的分离了最重要的上下文特征,并且不会导致网络操作速度的减少。所述spp模块的池化采用padding操作,维度不变,得到池化特征图输出,spp模块的方式比单纯的使用k
×
k最大池化的方式,更有效的增加感受野,显著的分离了最重要的上下文特征,并且不会导致网络操作速度的减少。
[0049]
5、特征融合模块bifpn
[0050]
所述head结构中,在完成特征的初步提取后,为了使特征更加具有高语义信息,还需加强网络特征融合的能力,采用了bifpn结构。fpn是自顶向下的,将高层的特征信息通过上采样的方式进行传递融合,得到进行预测的特征图;利用简单但高效加权的bifpn,该方法使用可学习的权重来学习不同特征的重要性,同时反复地进行上采样与下采样的多尺度融合,实现了一种效果和性能兼顾,更低的计算量还能达到更好的效果。
[0051]
本实施例中特征融合模块包括依次连接的conv模块、第一upsample层、第一concat层、第一c3模块、conv模块、第二upsample层、第二concat层、第二c3模块、conv模块、第三concat层、第三c3模块、conv模块、第四concat层、第四c3模块。
[0052]
其中spp模块输出的池化特征图输入至第三个包含注意力se block的c3se模块,得到大小为20
×
20
×
1024特征图,接着输入第四concat层,得到大小为20
×
20
×
1024特征图,经第四c3模块后,该特征图作为大小为20
×
20的融合特征输出至多分类器模块。
[0053]
backbone网络结构输出的大小为40
×
40
×
512的特征图同时输入至所述第一concat层、第三concat层,所述第一concat层的输出作为所述第一c3模块的输入,所述第三concat层的输出输入第三c3模块,所述第三c3模块的输出作为大小为40
×
40的融合特征输出至多分类器模块。
[0054]
backbone网络结构输出的大小为80
×
80
×
256的特征图输入至所述第二concat层,所述第二concat层的输出作为第二c3模块的输入,所述第二c3模块的输出作为大小为80
×
80的融合特征输出至多分类器模块。
[0055]
本实施例的特征融合模块将深层特征层经过上采样与浅层特征层相连,经过上述特征融合模块,可以使负责小目标检测的浅层融合特征层最大限度融合深层特征,使后续分类器分类得到表达效果更好的特征,从而达到提高小目标检测的目的。另外,密集连接还有很好的减小梯度消失、抗过拟合和泛化性能。由于丝饼缺陷一般相对于整个图片而言面积相对较小,所以对网络小目标检测要求更高,密集连接的方式可以实现特征的重用,提升梯度的反向传播,加强了特征的传播,从而提升小目标的检测。
[0056]
6、detect模块
[0057]
主要用于最终检测部分,即特征融合模块特征直接输出至分类器进行分类,它在
特征图上应用锚框,并生成带有类概率、对象置信度得分和目标检测框的最终输出向量。包括3个分类器:用于接收所述特征融合模块输出的大小为20
×
20的融合特征;用于接收所述特征融合模块输出的大小为40
×
40的融合特征;用于接收所述特征融合模块输出的大小为80
×
80的融合特征。最后三个特征图是不同缩放尺度的head被用来检测不同大小的物体,每个head一共(3个类别+1个概率+4坐标)
×
3锚框,一共24个channels。
[0058]
本实施例中使用采用80
×
80、40
×
40、20
×
20三个尺度的融合特征层分别做检测,采用独立的logistic分类器。以20
×
20为例,将输入图片划分为20
×
20的单元格,如果目标的真值框中心落在某个单元格区域内,则由这个单元格作为预测目标的单元格,每个单元格可产生三个预测框,共生成20
×
20
×
3=1200个预测框。当目标的类别置信度大于设置好的阈值时,相应单元格产生的三个预选框将会被保留,再通过非极大值抑制筛选出最合适的边界框。所以三个尺度最多可检测(80
×
80)+(40
×
40)+(20
×
20)=8400个目标,共可以生成8400
×
3=25200个预选框。用三个不同尺寸预测,从而满足不同大小的目标物体,最浅层特征图80
×
80具有较小的感受野,适用于检测小物体。最深层特征图20
×
20,具有较大的感受野,适用于大目标的检测。剩余特征层40
×
40,具有中等尺度的感受野,适合检测中等尺寸的对象,使得本实施例的改进型yolov5网络结构适用范围大,对各体积的物体均具有较优的检测结果。
[0059]
步骤3:利用所述样本集对改进yolov5算法进行训练,将训练后最佳的权重文件加载至改进yolov5算法得到目标检测网络。
[0060]
本实施例在训练时,按4:1的比例将样本集划分为训练集和验证集,将训练集中的样本图像输入改进yolov5算法,通过不断迭代训练得到丝饼目标检测最优的权重文件。其本质就是利用损失函数不断调节网络中的权重,再利用验证集计算平均精度map,从而验证训练结果是否达标,直至得到达标的权重文件,并将该权重文件加载至改进yolov5算法中得到作为目标检测的目标检测网络。
[0061]
本实施例中使用多尺度训练的方法提高算法对不同尺度的检测精度,即采用80
×
80、40
×
40、20
×
20三个尺度的融合特征层分别做检测,并且在训练过程中采用以下方法来保证训练的有效性。
[0062]
1、使用mosaic数据增强方法,利用四张图片进行拼接,从而使拼接后的图片具有丰富的物体检测背景,且在bn计算时会一次计算四张图片的数据。
[0063]
2、超参数进化。超参数的设置对于模型性能有着直接影响,通过利用遗传算法ga(genetic algorithm)进行超参数优化,选择更加合适的超参数。
[0064]
3、自动计算锚框。根据丝饼监测数据集,在网络训练中,网络在初始锚框的基础上输出预测框,进而和真实框ground truth进行比对,计算两者差距,再反向更新,迭代网络参数。每次训练时,自适应的计算不同训练集中的最佳锚框值,从而获得获取9种尺寸的anchor,得到最适合丝饼检测的anchor。自动计算锚框只在最大可能召回率bpr(best possible recall)小于给定阈值时启动。
[0065]
4、采用训练预热warmup。选择warmup预热学习率的方式,可以使得开始训练的几个epoch内学习率较小,在预热的小学习率下,模型可以慢慢趋于稳定,等模型相对稳定后再选择预先设置的学习率进行训练,使得模型收敛速度变得可快,模型效果更佳。
[0066]
5、采用余弦退火调整学习率cosineannealinglr。权重衰减的公式为:
[0067][0068]
其中,为学习率最小值,为学习率的最大值,t
cur
是从上次开始后已经记录了多少个epoch,是固定的数;一旦t
cur
=ti,代表cos为-1,因此通过余弦函数来降低学习率,余弦函数中随着x的增加余弦值首先缓慢下降,然后加速下降,再次缓慢下降。这种下降模式能和学习率配合,以一种十分有效的计算方式来产生很好的效果。
[0069]
6、采用ciou。ciou将目标与anchor(候选框)之间的距离,重叠率、尺度以及惩罚项都考虑进去,使得目标框回归变得更加稳定,不会像iou和giou一样出现训练过程中发散等问题。ciou的惩罚项是在diou的惩罚项基础上加了一个影响因子αv,这个因子把预测框长宽比拟合目标框的长宽比考虑进去。ciou公式如下:
[0070][0071]
其中,ρ2(b,b
gt
)分别代表了预测框b和真实框b
gt
的中心点的欧式距离,c代表的是能够同时包含预测框和真实框的最小闭包区域的对角线距离。而α是用于做权衡的参数,v是用来衡量长宽比一致性的参数,公式如下:
[0072][0073][0074]
其中ω
gt
、h
gt
、ω、h分别表示真实框和预测框的宽和高。
[0075]
可以得到相应loss函数:
[0076][0077]
步骤4:、针对获取的待分类图像,采用所述目标检测网络输出对应的目标检测结果,所述目标检测结果包括待分类图像中目标区域的位置以及每个目标区域对应的类别,其中目标区域的类别为绊丝、油污、成型不良丝饼。
[0078]
针对生产丝饼的生产流水线上的缺陷检测而言,可以通过安装在生产流水线上的摄像头实时采集视频信息,通过视频帧截取,并对截取的每一帧图像进行预处理,进行裁剪或者填充使其符合640
×
640大小,然后作为待分类图像输入目标检测网络中。
[0079]
综上所述,本发明提供了一种基于改进yolov5模型的丝饼缺陷检测方法,相比于传统方法,具有较高的检测速度和小目标检测精度,减轻了员工的劳动强度,从而有效提高生产效率,降低了丝饼缺陷检测的错误率。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1