一种基于蒙特卡洛搜索树种子调度的深度学习模糊测试方法
1.本发明涉及人工智能安全技术领域,尤其涉及一种基于蒙特卡洛搜索树种子调度的深度学习模糊测试方法。
背景技术:
2.模糊测试已经成为软件和硬件上最流行的漏洞发掘方案之一,在安全界得到了广泛的应用和研究。像afl这样的覆盖率引导模糊测试取得了巨大的成功。最先进的覆盖率引导模糊器,包括libfuzzer、honggfuzz、afl等,为发现成千上万的漏洞做出了贡献。一般来说,模糊测试的目的是通过生成,并向目标程序发送大量的测试用例来检测非预期的行为并发现漏洞。模糊测试基于测试用例的生成方式可以分为两类:基于变异的和基于生成的模糊测试。基于生成的模糊测试旨在根据程序输入的语法生成高度结构化的测试用例。然而,由于特定语法的构建主要是手工完成,所以基于生成的模糊测试效率并不高。
3.与之相反,基于变异的模糊器通过突变现有的测试用例(初始种子)来生成新的测试用例。因此,基于变异的测试用例质量是影响模糊器的有效性和效率的最重要的因素之一。由于基于变异的模糊测试几乎是通过随机变异现有的测试用例来生成,其变异效率高度依赖引导策略。在现有的基于变异的模糊测试中,针对深度神经网络系统的测试方法引起了研究者们的广泛关注。与传统软件不同的是,深度学习模型是数据驱动的系统。因此深度学习测试不能直接应用传统的软件测试度量元。深度学习系统的代码较容易被覆盖,但是深度学习的错误行为并不来源于代码本身。为了克服这一难题,pei等人在deepxplore中首次将神经元覆盖率作为度量元引入深度学习测试,并将该度量元应用于deeptest的现实生活应用场景。在他们的工作之后,ma等人开发了多种深度学习系统的度量元,包括k分区神经元覆盖率来区分更小粒度的测试用例,使将来的工作可以在一个统一的标准上进行实验。
4.基于所提出的测试度量元,xie等人提出了一个新型的深度学习系统的覆盖率引导的模糊测试框架deephunter,并在一系列指标上取得了显著的效果。zhang等人证明了基于模糊测试的系统也可以为dnn模型构建黑盒攻击。对抗训练是利用测试样本来增强深度学习系统鲁棒性的最常见的方式。然而,当前的深度学习测试模糊器在种子调度上仅使用简单的power
‑
scheduling(功耗调度)策略,使得整体测试效率欠佳。
技术实现要素:
5.本发明提出一种基于蒙特卡洛搜索树种子调度的深度学习模糊测试方法,基于蒙特卡洛搜索树的种子调度策略可以同时兼顾搜索时的广度与深度。从而高效的大量生成测试用例,提高了测试效率,并使用测试用例进行对抗训练从而增强深度神经网络自身的鲁棒性。
6.为了解决上述技术问题,本发明提供了一种基于蒙特卡洛搜索树种子调度的深度学习模糊测试方法,包括:
7.s1:将测试用例以批形式存入蒙特卡洛搜索树的初始节点α;
8.s2:采用置信区间上界算法ucb选择蒙特卡洛搜索树中每一层的最优节点α
best
,直到选择至树形结构的叶子节点α
leaf
,其中,每一层的最优节点为该层中ucb值最大的节点,ucb值根据节点的评估值和访问次数获得,用以平衡搜索的广度与深度;
9.s3:通过变异函数对叶子节点α
leaf
存储的样本进行变异,得到变异后的样本,存入新节点α
leaf+1
中,α
leaf+1
为α
leaf
的子节点;
10.s4:对新节点α
leaf+1
中的样本进行随机模拟,随机模拟过程中生成新的样本i
m
,m=1,2,
…
n;每一次随机模拟前检查i
m
中样本语义限制违反情况,若i
m
中部分样本违反预设语义限制则仅变异未违反预设语义限制的样本,每一轮变异都将本轮i
m
存储进queue,n轮模拟后,直到i
m
中所有的样本违反预设语义限制则停止模拟,最终得到终局前数据序列queue(i1,i2,i3,...,i
n
);
11.s5:将测试生成的新节点中终局前的数据序列输入待测深度学习模型,观察能否促进待测深度学习模型神经元覆盖率的提升;
12.s6:如果新生成的节点中终局前的数据序列的平均模拟结果能够引导深度学习模型获得更高的神经元覆盖率,则将新生成的节点的结果中的bonus加1,bonus表示每次采样覆盖率增加次数,并延树形结构进行反向传播;
13.s7:循环执行步骤s2至步骤s6,通过不断扩大蒙特卡洛搜索树得到能够增加神经网络覆盖率的测试用例,并利用得到的测试用例进行模糊测试。
14.在一种实施方式中,步骤s1包括:
15.s1.1:从预设数据集中获取测试用例作为初始种子;
16.s1.2:将初始种子以state属性存储于初始节点对象中,其中batch大小为64,节点中的属性包括state,child,parent,bonus和visits,其中,state为以批形式存储的种子,child为子节点的对象,parent为父节点的对象,bonus为节点每次采样覆盖率增加次数,表示节点的价值,visits为节点被采样次数。
17.在一种实施方式中,步骤s2包括:
18.s2.1:从初始节点开始逐层使用ucb算法进行选择,选择出该层中ucb值最大的节点,ucb值为reward:
[0019][0020]
上式中,v
i
为节点的评估值,c为常数,n与n
i
分别为父节点与本节点的访问次数;
[0021]
s2.2:当选择出一个节点后继续选择该节点的子节点,并对该节点的子节点采用ucb算法进行选择,直到到达蒙特卡洛搜索树的叶子节点。
[0022]
在一种实施方式中,变异后的样本为图像样本,步骤s3包括:
[0023]
s3.1:随机在图像样本坐标上取点作为变异点,并获得预设大小的正方形区域;
[0024]
s3.2:对正方形区域中的像素随机施加变异操作;
[0025]
s3.3:将变异后的样本存入新节点中。
[0026]
在一种实施方式中,步骤s4包括:
[0027]
s4.1:对新节点α
leaf+1
中的样本进行变异操作,生成新样本,将生成的新样本进行保存得到输入i;
[0028]
s4.2:检查输入i是否违反样本预设语义限制,公式如下:
[0029][0030]
其中,f(i,i')表示预设语义限制函数,i表示原始样本,i'表示变异后样本,size为样本总像素数,α,β为常数,l
∞
(i,i')表示样本i与i'的l
∞
距离,即样本i'相对于i单像素修改最大值绝对值,l0(i,i')表示样本i与i'的l0距离,即样本i'相对于i的像素修改个数;预设语义限制函数表示当样本被修改的像素数小于α
×
size(s)时,l
∞
(i,i')小于像素最大值255,不要求变异的幅度;否则,l
∞
(i,i')小于β
×
255,违反限制的样本将不在下一轮变异;
[0031]
s4.3:若生成的新样本没有违反限制,则将样本存储进queue(i1,i2,i3,...,i
n
);
[0032]
s4.4:重复步骤s4.1与s4.3直至i中所有样本违反限制。
[0033]
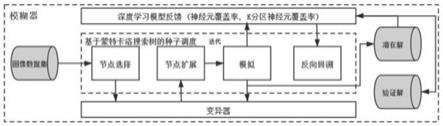
在一种实施方式中,步骤s5包括:
[0034]
步骤5.1,将得到的最终样本输入进神经网络,测算神经元覆盖程度,获得神经元覆盖率;
[0035]
步骤5.2,若获得的神经元覆盖率大于新节点α
leaf+1
内样本的神经元覆盖率,则将新节点α
leaf+1
的bonus加1,bonus为节点每次采样覆盖率增加次数,表示节点的价值。
[0036]
本技术实施例中的上述一个或多个技术方案,至少具有如下一种或多种技术效果:
[0037]
本发明提供的一种基于蒙特卡洛搜索树种子调度的深度学习模糊测试方法,基于蒙特卡洛搜索树的种子调度策略可以同时兼顾搜索时的广度与深度,从而高效的大量生成测试用例,提高了测试的效率,用基于蒙特卡洛搜索树的调度策略替换传统power
‑
scheduling,使生成的测试用例在被测系统的覆盖率显著提高,提高了被测系统的鲁棒性。
附图说明
[0038]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0039]
图1为本发明具体实施例中测试用例示例图;
[0040]
图2为本发明具体实施例中模糊器工作流程图。
具体实施方式
[0041]
本发明主要是解决现有针对深度学习系统的模糊测试种子调度策略使得测试效率低下问题,提供了一种基于蒙特卡洛搜索树种子调度策略的模糊测试方法。该方法及装置在预先构建的cnn模型上进行实验,设计种子调度策略来优先变异有价值的测试用例(种子)。针对参数和结构未知的深度学习模型,利用生成的对抗样本作为输入数据进行对抗训练,同时提高被测模型的鲁棒性。。
[0042]
本发明的技术方案包括:采用公认的mnist和cifar
‑
10图像数据集,设计新的模糊器种子调度策略与深度学习测试变异方法,用基于蒙特卡洛搜索树的调度策略替换传统
power
‑
scheduling,使生成的测试用例在被测系统的覆盖率显著提高,提高了被测系统的鲁棒性。
[0043]
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0044]
本发明实施例提供了一种基于蒙特卡洛搜索树种子调度的深度学习模糊测试方法,包括:
[0045]
s1:将测试用例以批形式存入蒙特卡洛搜索树的初始节点α;
[0046]
s2:采用置信区间上界算法ucb选择蒙特卡洛搜索树中每一层的最优节点α
best
,直到选择至树形结构的叶子节点α
leaf
,其中,每一层的最优节点为该层中ucb值最大的节点,ucb值根据节点的评估值和访问次数获得,用以平衡搜索的广度与深度;
[0047]
s3:通过变异函数对叶子节点α
leaf
存储的样本进行变异,得到变异后的样本,存入新节点α
leaf+1
中,α
leaf+1
为α
leaf
的子节点;
[0048]
s4:对新节点α
leaf+1
中的样本进行随机模拟,随机模拟过程中生成新的样本i
m
,m=1,2,
…
n;每一次随机模拟前检查i
m
中样本语义限制违反情况,若i
m
中部分样本违反预设语义限制则仅变异未违反预设语义限制的样本,每一轮变异都将本轮i
m
存储进queue,n轮模拟后,直到i
m
中所有的样本违反预设语义限制则停止模拟,最终得到终局前数据序列queue(i1,i2,i3,...,i
n
);
[0049]
s5:将测试生成的新节点中终局前的数据序列输入待测深度学习模型,观察能否促进待测深度学习模型神经元覆盖率的提升;
[0050]
s6:如果新生成的节点中终局前的数据序列的平均模拟结果能够引导深度学习模型获得更高的神经元覆盖率,则将新生成的节点的结果中的bonus加1,bonus表示每次采样覆盖率增加次数,并延树形结构进行反向传播;
[0051]
s7:循环执行步骤s2至步骤s6,通过不断扩大蒙特卡洛搜索树得到能够增加神经网络覆盖率的测试用例,并利用得到的测试用例进行模糊测试。
[0052]
具体来说,蒙特卡洛搜索树作为人工智能领域广泛使用的搜索技术备受关注。通过不断采样来逼近问题的最优求解。一般来说,构造蒙特卡洛搜索树分为四个过程:1,选择(selection):选择树中的最优叶子节点,如果没有节点则构建根节点;2,扩展(expansion):对选择的叶子节点进行扩展,从而得到新节点;3,模拟(simulation):对新节点进行模拟从而得到2中叶子节点的评估值;4,回溯(back
‑
propagation):通过反向传播将评估值传播至整个选择路径。蒙特卡洛搜索树算法通过一次次迭代不断扩大搜索树的规模来得到最优解。
[0053]
其中,步骤s2~s4分别对应选择、扩展和模拟过程,s6对应回溯过程。s1中的初始节点即为蒙特卡洛搜索树的根节点,s2的选择过程中,每一次选择都是以层为单位,选择每一层节点中ucb评估值最优的节点,直到选择到整个树形结构的叶子节点,然后从叶子节点向下延展一位,用于扩展搜索树的结构,再通过对新生成的节点模拟,得到新的reward,最后将这个新的结果反向传播至整个树。
[0054]
在一种实施方式中,步骤s1包括:
[0055]
s1.1:从预设数据集中获取测试用例作为初始种子;
[0056]
s1.2:将初始种子以state属性存储于初始节点对象中,其中batch大小为64,节点中的属性包括state,child,parent,bonus和visits,其中,state为以批形式存储的种子,child为子节点的对象,parent为父节点的对象,bonus为节点每次采样覆盖率增加次数,表示节点的价值,visits为节点被采样次数。
[0057]
具体实施过程中,预设数据集包括mnist、cifar
‑
10等数据集。
[0058]
在一种实施方式中,步骤s2包括:
[0059]
s2.1:从初始节点开始逐层使用ucb算法进行选择,选择出该层中ucb值最大的节点,ucb值为reward:
[0060][0061]
上式中,v
i
为节点的评估值,c为常数,n与n
i
分别为父节点与本节点的访问次数;
[0062]
s2.2:当选择出一个节点后继续选择该节点的子节点,并对该节点的子节点采用ucb算法进行选择,直到到达蒙特卡洛搜索树的叶子节点。
[0063]
其中,reward(ucb值)用以搜索过程中平衡搜索广度与深度,常数c经验设置为
[0064]
在一种实施方式中,变异后的样本为图像样本,步骤s3包括:
[0065]
s3.1:随机在图像样本坐标上取点作为变异点,并获得预设大小的正方形区域;
[0066]
s3.2:对正方形区域中的像素随机施加变异操作;
[0067]
s3.3:将变异后的样本存入新节点中。
[0068]
具体实施过程中,预设大小为kernel,可以取kernel=3。变异操作具体如下表:
[0069]
变异操作描述侵蚀缩减图形边界扩张扩张图形边界开运算消除图形外部噪声闭运算消除图形内部噪声模糊平滑像素连续性噪声添加高斯噪声
[0070]
变异操作可以通过公开图形库opencv中获取。
[0071]
在一种实施方式中,步骤s4包括:
[0072]
s4.1:对新节点α
leaf+1
中的样本进行变异操作,生成新样本,将生成的新样本进行保存得到输入i;
[0073]
s4.2:检查输入i是否违反样本预设语义限制,公式如下:
[0074][0075]
其中,f(i,i')表示预设语义限制函数,i表示原始样本,i'表示变异后样本,size为样本总像素数,α,β为常数,l
∞
(i,i')表示样本i与i'的l
∞
距离,即样本i'相对于i单像素修改最大值绝对值,l0(i,i')表示样本i与i'的l0距离,即样本i'相对于i的像素修改个数;
预设语义限制函数表示当样本被修改的像素数小于α
×
size(s)时,l
∞
(i,i')小于像素最大值255,不要求变异的幅度;否则,l
∞
(i,i')小于β
×
255,违反限制的样本将不在下一轮变异;
[0076]
s4.3:若生成的新样本没有违反限制,则将样本存储进queue(i1,i2,i3,...,i
n
);
[0077]
s4.4:重复步骤s4.1与s4.3直至i中所有样本违反限制。
[0078]
具体来说,预设语义限制函数表示:如果对单一的图像进行变异,变异的像素点比例小于α
×
size(s)时,不要求变异的幅度,l无限距离l
∞
(i,i')小于像素最大值255即可;在变异像素点过多,超过比例后,单一变异像素点的最大值l
∞
(i,i')不可以超过β
×
255。size表示图像的像素总数,例如样本为32
×
32
×
3,则size为3072,变异操作分别在三个通道对像素点变异。α,β为自定义常数,在本实施方式中设置为0.3与0.1。
[0079]
步骤s3的扩展和步骤s4中的模拟的区别和关联包括:步骤s3是用于生成新节点,因此新节点中的数据(样本)是以node的形式存储的(即生成一个node的对象),具体地,在生成新节点时会同时给出节点的state属性以及该节点的上下节点关系等。而步骤s4中的simulation模拟过程,只需要获得这一次采样的评估结果,因而不生成新节点。扩展和模拟的本质都是进行了变异操作,区别在于expansion中变异操作只进行一次,simulation在所有样本达到限制前会不断变异(即多次变异),这样可以得到一次随机模拟至终局(到达限制)的采样结果。
[0080]
在具体的模拟过程中,是一个迭代的过程,每一轮都会在上一轮的基础上进行变异,例如第一轮变异得到样本i1,第二轮变异在第一轮变异的基础上进行,得到样本i2,依此类推,第n轮变异后的结果为i
n
,并将变异得到的所有样本存入输入序列i中。每一次变异后都会对输入i进行检查是否违反限制,当输入序列中所有的样本都违反限制则停止,否则继续。其中,在检查是否违反限制时,会将没有违反限制的样本存入queue中。
[0081]
在一种实施方式中,步骤s5包括:
[0082]
步骤5.1,将得到的最终样本输入进神经网络,测算神经元覆盖程度,获得神经元覆盖率;
[0083]
步骤5.2,若获得的神经元覆盖率大于新节点α
leaf+1
内样本的神经元覆盖率,则将新节点α
leaf+1
的bonus加1,bonus为节点每次采样覆盖率增加次数,表示节点的价值。
[0084]
具体来说,步骤s5的前提条件如下:
[0085]
神经元覆盖指预先训练一个cnn替代模型,将一个图像数据作为输入,神经元接到上层输入后经过激活函数会得到一个输出o,设置一个常数t为神经元激活的阈值,cnn最终输出分类结果为c,样本原始标签为l。
[0086]
①
当c≠l时,且不违反语义限制时,该输入被判别为对抗样本(adversarial samples);当c=l时,被判别为正常样本;
[0087]
②
当单个神经元输出o>t时,视为神经元被覆盖;
[0088]
③
阈值t的经验值为0.25、0.5、0.75,这里我们选取0.75作为阈值;
[0089]
然后执行步骤s5.1~步骤s5.2,将得到的最终样本输入进神经网络,测算神经元覆盖程度,获得神经元覆盖率;若获得的神经元覆盖率大于α
leaf+1
内样本的神经元覆盖率,则视为α
leaf+1
的bonus加1.
[0090]
在一种实施方式中,步骤s6中的回溯传播方法:
[0091]
s6.1,α
leaf+1
获得bonus后更新其评估值v
i
,其中v
i
计算公式如下:
[0092][0093]
其中,v
i
为ucb公式中的节点评估值,bonus为模拟结果中使覆盖率增加的次数,visits为节点的被访问次数。
[0094]
s6.2,从α
leaf+1
向α
leaf
更新评估值,直到更新至根节点α,首先α
leaf+1
的bonus依据模拟结果决定是否加1,其visits+1,然后选择α
leaf+1
节点中的属性parent即选择节点α
leaf
,如果α
leaf+1
的结果使α
leaf+1
加1,则此时α
leaf
中的bonus也加1,visits加1,继续选择α
leaf
的父节点parent并重复迁移过程直至根节点α;
[0095]
下面通过一个具体示例对本发明的方法进行介绍。
[0096]
本发明的方法是为了解决现有的以power
‑
scheduling为代表的深度学习测试种子调度机制效率低下问题,为了方便阐述,现以图1中的图像样本为例说明cifar
‑
10数据集下样本的生成情况:
[0097]
将图1中左边的样本为cifar
‑
10数据集中的正常样本,右边的样本为经过变异后的样本。作为输入数据导入训练好的cnn模型中,左边的样本获得正确的分类“鸟”,右边的变异样本获得分类“飞机”,并获得更高神经元覆盖率。具体实施时,本发明的方法可以通过计算机流程来实现,实现该方法的程序构成模糊器,用以实现本发明的基于蒙特卡洛搜索树种子调度的深度学习模糊测试方法,其中,图2是本发明中的模糊器工作流程图,其详细说明过程如下:
[0098]
步骤1,以图1中的图像样本以批的形式输入进模糊器,并记录下其label(标签);
[0099]
步骤2,以初始输入样本(初始种子)作为根节点进行搜索。进行首轮迭代,选择至搜索树的叶子节点;对该叶子节点的数据(样本)进行一次变异操作,得到变异后的样本,并以此生成该叶子节点的子节点。对该节点进行一次随机模拟,将模拟得到的变异样本输入深度学习系统获得神经元覆盖率反馈,以获得其节点评估值;验证模拟中生成的变异样本,并将潜在的解存储;将该评估值反向回溯至树形结构中所有的父节点。
[0100]
步骤3,将模拟中生成的潜在解输入深度学习模块进行验证对比label。得到验证解。
[0101]
从以上描述可知,本发明的有益效果是:本发明采用公认的mnist和cifar
‑
10图像数据集,设计新的模糊器种子调度策略与深度学习测试变异方法,用基于蒙特卡洛搜索树的调度策略替换power
‑
scheduling,使生成的测试用例在被测系统的覆盖率显著提高,提高了被测系统的鲁棒性。
[0102]
以上实施例仅用以说明本发明的技术方案,而非对其限制;尽管参照前述实施例对本发明进行了详细的说明,本领域的普通技术人员应当理解:其依然可以对前述各实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换;而这些修改或者替换,并不使相应技术方案的本质脱离本发明各实施例技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1