一种面向典型有源干扰的雷达图像目标检测系统的制作方法
1.本发明属于图像处理和目标识别技术领域,尤其涉及一种面向典型有源干扰的雷达图像目标检测系统。
背景技术:
2.区别于传统的光学图像,雷达图像信息量严重不足,在成像机理、目标特性、分辨率方面差异显著。雷达回波数据在多普勒维上成像特点和光学图像存在显著差异:图像包含了杂波信号等大量混合有源无源噪声,目标及干扰物相比整张图像的所占像素比极低且分布稀疏。传统的雷达图像目标检测一般利用先验知识通过候选区域提取特征。经典的恒虚警检测只对背景信息统计建模,没有考虑对目标信息的完整建模,只是利用目标成像区域的部分特征来检测,没有充分利用全局特征,漏警率较高;传统特征提取方法需要考虑特定环境下信息建模或者规则匹配,然而实际应用中雷达所处的电磁环境恶劣,特定统计建模方法和规则匹配方式只适用于既定的环境。同时目标本身轮廓、方位、尺寸、背景干扰等变化均会对实际的目标检测造成显著地影响,人工设定的背景信息建模和规则匹配难以实现通用,局限性较大。
技术实现要素:
3.本发明解决的技术问题是:克服现有技术的不足,提供了一种面向典型有源干扰的雷达图像目标检测系统,具有高可靠性、高效率、适用于有源干扰时导引头成像目标识别方法。
4.本发明目的通过以下技术方案予以实现:一种面向典型有源干扰的雷达图像目标检测系统,包括:有源干扰图像数据增强模块、数据加载器模块、网络结构模块、网络训练模块及目标定位预测模块;其中,所述有源干扰图像数据增强模块对所有的有源干扰的数据图像进行数据增强得到全部增强的数据图像;对有源干扰的数据图像随机选出若干个数据图像,对若干个数据图像进行数据扩充得到若干个扩充数据图像;将全部增强的数据图像和若干个扩充数据图像传输给数据加载器模块;所述数据加载器模块将数据包封装到一个dataset类,dataset类将数据包按批次进行切分,并且将数据包进行随机打乱处理,封装完成后将dataset类对应的数据包送入到一个迭代器中,迭代器将数据包传输给网络结构模块;其中,全部增强的数据图像和若干个扩充数据图像组成数据包;所述网络结构模块构建神经网络结构;所述网络训练模块控制数据加载器模块将数据包加载到神经网络结构将;数据包以数据流经过神经网络结构计算后输出图像中的目标类别和目标位置坐标的概率矩阵,该概率矩阵与训练数据的标签值通过损失函数运算得出误差值,将误差值回传至神经网络结构进行权重参数的梯度更新,循环结束后将最佳的权重参数传输给目标定位预测模块;其中,训练数据为全部增强的数据图像数据和若干个扩充数据图像数据;目标定位预测模块将有源干扰的图像作为输入,加载网络训练模块传输给的最佳的权重参数,将最佳的权重参数赋值回给神经网络结构,得到输出目标所在位置的矩形框坐标与目标类别。
5.上述面向典型有源干扰的雷达图像目标检测系统中,数据扩充是在模型训练前将有源干扰的数据图像进行随机打乱操作,统计所有训练集图像素分布,计算图像像素均值与方差,将训练集一分为二得到第一份图像和第二份图像,将第一份图像进行干扰提取,随机施加到第二份图像去除自身干扰的图像中,从而可扩充数据集。
6.上述面向典型有源干扰的雷达图像目标检测系统中,数据增强则是利用功率放大,将每张图像的像素均值减去整个数据集中所有图像像素均值取其绝对值作为功率调整阈值,将随机在每张图像上整体加上或减去调整阈值,以达到干扰噪声多样化数据增强作用。
7.上述面向典型有源干扰的雷达图像目标检测系统中,所述网络结构模块构建神经网络结构包括如下步骤:(41)搭建backbone网络;(42)搭建neck网络;(43)搭建rpn网络;(44)配置roi网络层;(45)配置训练超参数。
8.上述面向典型有源干扰的雷达图像目标检测系统中,在步骤(41)中,前馈网络选用新一代特征提取网络resnest,其中,分支通道数为64,网络层深度为50,每个阶段输出特征图的索引out_indices=(0,1,2,3),批归一化设置norm_cfg=dict(type='bn',requires_grad=true),冻住第一阶段的权重frozen_stages=1。
9.上述面向典型有源干扰的雷达图像目标检测系统中,在步骤(42)中,设置neck网络为金字塔特殊映射网络fpn;输入通道与主干网络保持一致,in_channels=[256,512,1024,2048];每个金字塔特征映射层输出通道数out_channels=256;输出特征数量num_outs=5。
[0010]
上述面向典型有源干扰的雷达图像目标检测系统中,在步骤(43)中,每个输入特征图的通道数in_channels=256;头部卷积层的特征通道数feat_channels=256;锚点框生成配置为type='anchorgenerator';基本矩形框面积大小scales=[8];纵横比的设置是将数据增强后的干扰图像训练集的图像进行纵横比例统计后选取占比最高纵横比为代表来设置,ratios=[0.5,1.0,2.0];锚点框生成时的步长strides=[4,8,16,32,64];分类分支损失函数使用交叉熵损失函数type='crossentropyloss',激活函数使用sigmoid函数use_sigmoid=true,分类分支损失函数的权重loss_weight=1.0;回归分支的损失函数使用l1损失type='l1loss',回归分支损失函数的权重loss_weight=1.0。
[0011]
上述面向典型有源干扰的雷达图像目标检测系统中,在步骤(44)中,roi网络层使用三个type='sharedfcbboxhead'字典结构,每一个dict配置为输入通道数in_channels=256;卷积输出通道数conv_out_channels=256,全连接层输出通道数fc_out_channels=1024,池化尺寸roi_feat_size=7,边框编码器使用类型type='deltaxywhbboxcoder';目标均值方差三个字典分别设置为target_means=[0.,0.,0.,0.],target_stds=[0.1,0.1,0.2,0.2];target_means=[0.,0.,0.,0.],target_stds=[0.05,0.05,0.1,0.1];target_means=[0.,0.,0.,0.],target_stds=[0.033,0.033,0.067,0.067];分类损失函数和回归损失函数分别为type='crossentropyloss'和type='smoothl1loss',权重设置各为1。
[0012]
上述面向典型有源干扰的雷达图像目标检测系统中,在步骤(45)中,使用随机翻转;iou阈值大于等于0.7的为正样本pos_iou_thr=0.7,iou阈值小于0.3的为负样本neg_iou_thr=0.3;采样数量num=256,正样本比率pos_fraction=0.5;rpn网络提取操作设置
取前2000个矩形框nms_pre=2000,经过nms算法作用后保留1000个矩形框nms_post=1000。
[0013]
上述面向典型有源干扰的雷达图像目标检测系统中,目标位置坐标包括左上横坐标、左上纵坐标、目标框宽度、目标框长度。
[0014]
本发明与现有技术相比具有如下有益效果:
[0015]
(1)雷达在其工作的各个阶段,都可能受到来自各方面的电磁干扰,不同的干扰样式对雷达工作过程的影响也不尽相同。本发明用于雷达工作时的各个阶段面临的各样式电磁干扰时精确定位目标所在区域;
[0016]
(2)有源压制干扰大多可分为射频噪声干扰、噪声调幅干扰、噪声调频干扰和噪声调相干扰等,以传统算法进行目标识别时,往往需要先区分图像受到干扰的类型,从而提出不同干扰下目标的特征进行设计以进行特征匹配识别。而本发明提出的图像增强方法不需要事先识别有源干扰类别,随机从干扰数据集图像中抽取干扰再随机施加到另一张剥去干扰的原图像上,从而达到随机数据增强的效果;
[0017]
(3)在有源压制干扰下的复杂背景的目标检测中,交并比(iou)是用来界定区分正样本(目标)和负样本(有源干扰背景)的阈值。在以往的深度学习目标检测方法,当使用低阈值如0.5时,训练的目标探测器通常会产生噪声,而随意提升阈值可能会导致检测性能随阈值的增加而下降。造成这一现象的主要原因主要是训练过程中由于数据集中的正样本图像如果出现指数性消失将会导致的过拟合以及检测器为最优的iou与输入假设的iou之间的推断时间不匹配造成的。针对雷达有源压制干扰下的复杂背景图像的特殊性可能出现的这些问题,本发明引用一种多级目标检测体系结构-级联r-cnn.其由一系列的随着iou阈值的提高而训练的探测器组成,以便对强干扰下接近假阳性的目标图像有更多的选择性;
[0018]
(4)噪声压制干扰主要是通过抬高背景噪声,淹没有用信号,降低信噪比,达到干扰雷达正常工作的目的。某种意义上而言,雷达抗噪声干扰的技术手段就是提高信噪比,干扰信号带宽大,幅度动态范围小,功率利用率高。调制噪声的的概率密度为高斯分布时,噪声调频干扰的功率谱密度分布也近似满足高斯分布。本发明提出的级联探测器是分阶段训练的,r-cnn级的级联是按顺序训练的,使用一个阶段的输出来训练下一个阶段。这是因为观察到回归器的输出iou几乎总是优于输入iou,所以用一定的iou阈值训练的检测器的输出是训练下一次较高iou阈值检测器的良好分布;
[0019]
(5)基于深度学习的级联rcnn算法在有源压制干扰的雷达图像数据集上进行训练时,提出一种针对该特殊场景的调参调优方法,该方法可以通过统计图像像素分布及训练数据真实边界框的纵横比分布来降低推理预测时目标锚框相对于边界框的预测偏移量,从而使目标识别出的位置更加精准;
[0020]
(6)本发明在深度学习pytorch+mmdetction框架进行实践创造,本发明可显著提高在有源压制干扰的雷达图像目标识别精度,有效解决了以往传统方法多阶段识别高分辨率干扰背景下图像小目标的低时效性,有效降低了有源干扰所引起的“假阳性”的错误识别率,为实现人工智能制导领域对于雷达有源压制干扰下舰船车辆建筑群等识别提供重要技术基础。因此,将该技术应用于工程实际具有重要意义。
附图说明
[0021]
通过阅读下文优选实施方式的详细描述,各种其他的优点和益处对于本领域普通技术人员将变得清楚明了。附图仅用于示出优选实施方式的目的,而并不认为是对本发明的限制。而且在整个附图中,用相同的参考符号表示相同的部件。在附图中:
[0022]
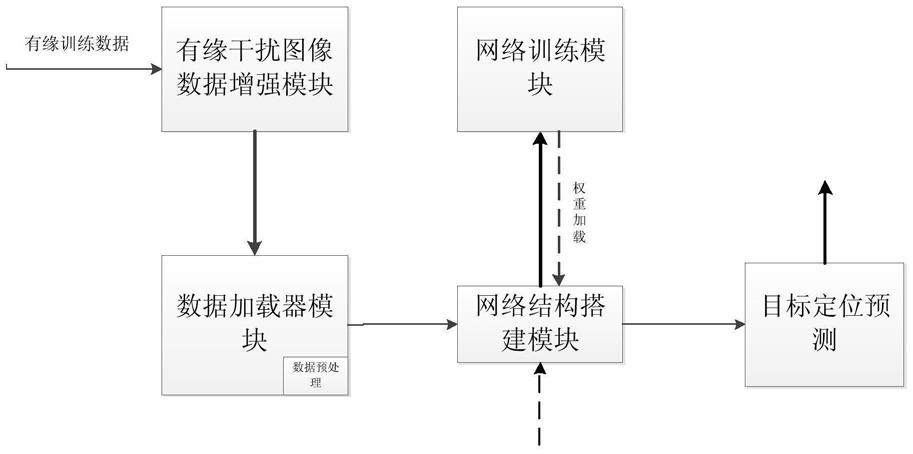
图1是本发明实施例提供的面向典型有源干扰的雷达图像目标检测系统的框图;
[0023]
图2是本发明实施例提供的数据表生成模块工作流程图;
[0024]
图3是本发明实施例提供的数据加载器模块工作流程图;
[0025]
图4是本发明实施例提供的网络结构搭建模块工作流程图;
[0026]
图5是本发明实施例提供的网络训练模块工作流程图;
[0027]
图6是本发明实施例提供的目标识别预测模块的工作流程图。
具体实施方式
[0028]
下面将参照附图更详细地描述本公开的示例性实施例。虽然附图中显示了本公开的示例性实施例,然而应当理解,可以以各种形式实现本公开而不应被这里阐述的实施例所限制。相反,提供这些实施例是为了能够更透彻地理解本公开,并且能够将本公开的范围完整的传达给本领域的技术人员。需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。下面将参考附图并结合实施例来详细说明本发明。
[0029]
近年来随着深度学习技术的发展,目标检测技术被广泛地应用到多个领域,对社会经济发展和生产生活带来巨大改变,随着技术的日益成熟,深度学习技术在泛图像识别领域的应用也取得显著进步,雷达时频数据作为一种泛图像信号,其与深度学习技术的深入结合将是未来发展的重要趋势。
[0030]
国内外对于解决雷达有源压制干扰下的复杂背景图像识别方法中,尚无针对基于深度学习的抗有源压制干扰目标识别设计实例,因此,提出一种基于深度学习的具有高可靠性、高效率、适用于有源干扰时导引头成像目标识别方法具有重要意义和实用价值。
[0031]
图1是本发明实施例提供的面向典型有源干扰的雷达图像目标检测系统的框图。如图1所示,该系统包括有源干扰图像数据增强模块、数据加载器模块、网络结构模块、网络训练模块及目标定位预测模块构成。其中,数据加载器构建模块中包含数据预处理子模块。
[0032]
所述有源干扰图像数据增强模块对所有的有源干扰的数据图像进行数据增强得到全部增强的数据图像;对有源干扰的数据图像随机选出若干个数据图像,对若干个数据图像进行数据扩充得到若干个扩充数据图像;将全部增强的数据图像和若干个扩充数据图像传输给数据加载器模块。数据扩充是在模型训练前将有源干扰的数据图像进行随机打乱(shuffle)操作,统计所有训练集图像素分布,计算图像像素均值与方差,将训练集一分为二,将第一份的图像进行干扰提取,随机施加到第二份去除自身干扰的图像中,从而可扩充数据集;数据增强则是利用功率放大,将每张图像的像素均值减去整个数据集中所有图像像素均值取其绝对值作为功率调整阈值,将随机在每张图像上整体加上或减去调整阈值,以达到干扰噪声多样化数据增强作用。
[0033]
所述数据加载器模块将数据包封装到一个dataset类,dataset类将数据包按批次进行切分,并且将数据包进行随机打乱处理,封装完成后将dataset类对应的数据包送入到一个迭代器中,迭代器将数据包传输给网络结构模块;其中,全部增强的数据图像和若干个
扩充数据图像组成数据包。具体的,训练数据增强操作后,将增强的数据图像和若干个扩充数据图像加载到数据加载器模块,该模块将充分利用系统子进程进行快速加载数据,并将增强的数据图像和若干个扩充数据图像即数据包封装到一个dataset类,该类可以将数据包按批次进行切分,并且可将数据包进行随机打乱处理,封装完成后将该类对应的数据包送入到一个迭代器中,迭代器将数据包传输给网络结构模块;在算法训练阶段便可以通过遍历该迭代器,在雷达干扰下的背景应用深度学习算法,本发明发现数据的数量和分布对模型的性能有很大的影响,因此,在数据加载模块本发明将使用图像预处理算法,如仿射变换(二维线性变换)及标准化方法。
[0034]
所述网络结构模块构建神经网络结构。具体的,数据加载模块构建完成后,构建网络结构,定义损失函数创建网络骨架以待数据流输入,同时完成网络权重参数的初始化运算,以及设置训练超参数,如学习率、学习衰减率、训练周期,本发明在训练调优方面提出针对该特殊场景下的参数设置方式。
[0035]
所述网络训练模块控制数据加载器模块将数据包加载到神经网络结构将;数据包以数据流经过神经网络结构计算后输出图像中的目标类别和目标位置坐标的概率矩阵,该概率矩阵与训练数据的标签值通过损失函数运算得出误差值,将误差值回传至神经网络结构进行权重参数的梯度更新,循环结束后将最佳的权重参数传输给目标定位预测模块;其中,训练数据为全部增强的数据图像数据和若干个扩充数据图像数据。
[0036]
目标定位预测模块将有源干扰的图像作为输入,加载网络训练模块传输给的最佳的权重参数,将最佳的权重参数赋值回给神经网络结构,得到输出目标所在位置的矩形框坐标与目标类别。
[0037]
图2是本发明实施例提供的数据表生成模块工作流程图。如图2所示,有源干扰数据增强模块的工作流程:
[0038]
(21)将有源干扰导引头雷达数据集图像按数量/2的方式,分为a组/b组;
[0039]
(22)遍历b组图像,鉴于训练集目标基本集中于右半区域,将1024*64图像中左半部分512*64像素复制扩充为无目标的1024*64的图像,后用原图像减去复制后无目标图像,此时为有目标去除干扰的图像,再有目标去除干扰的图像减去的其像素均值,此时认为该图像为无干扰无目标纯背景图;
[0040]
(23)遍历a组图像,将每张图像的左半部分512*64像素复制扩充为无目标的1024*64的图像,逐像素减去步骤2无目标纯背景图像像素均值,后将其逐像素随机与b组有目标去除干扰的图像像素相加,此时新的图像为随机加入干扰的图像。
[0041]
(24)将新图像重新命名,目标点仍为未加入干扰时的坐标标签,保存至数据库。
[0042]
图3是本发明实施例提供的数据加载器模块工作流程图。如图3所示,数据加载器模块的工作流程为:
[0043]
(31)获取训练图像数据在本地的存储路径,图像与对应的标签文件分别记录在不同名称的文本文件中,存储在本地统一路径文件夹下;
[0044]
(32)遍历训练图像数据的存储路径,是否为最后一张图像,若是,则结束,否则则执行步骤(33);
[0045]
(33)根据当前训练图像,获取对应的标签文件路径,查看该路径是否存在,若存在则执行步骤(34),否则,返回步骤2;
[0046]
(34)打开标签txt文件,以空格为分割符,逐字读入内存,其中前四个为目标位置坐标(左上横坐标、左上纵坐标、目标框宽度、目标框长度),最后一个数字代表目标类别;
[0047]
(35)将类别进行one-shot映射,如有三个类别,则舰船:[0,1,0,0],车辆:[0,0,1,0],建筑群[0,0,0,1]:3,背景:[0,0,0,0];
[0048]
(36)按训练图像数据的存储路径读取雷达有源干扰图像,并将图像输入图像预处理子模块进行图像预处理;
[0049]
(37)利用pytorch深度学习框架预处理算法transforms.randomerasing将图像进行随机遮挡,设置参数(p=0.5,scale=(0.02,0.33),ratio=(0.3,3.3),value=0,inplace=false),其中p:执行概率,scale:遮挡面积,随机选择(a,b)中的一个遮挡比例,ratio:长宽比,随机选择(a,b)中的一个长宽比,value:像素值,(r,g,b)或gray或任意字符串。由于totensor对像素值归一化,因此(r,g,b)要除以255;
[0050]
(38)利用pytorch深度学习框架预处理算法transforms.normalize(mean,std,inplace=false)进行标准化操作,其中mean为该图像的像素均值,std为该图像像素方差;
[0051]
(39)将图像矩阵与标签索引序列封装到dataset类包中,待全部训练数据遍历完送入数据加载器;
[0052]
(310)数据加载器对所有数据包进行随机打乱操作,并按设置的批次数量划分,为网络训练模块完成数据准备工作。
[0053]
图4是本发明实施例提供的网络结构搭建模块工作流程图。如图4所示,网络结构搭建模块的工作流程为:
[0054]
(41)搭建backbone网络:本发明的前馈网络选用新一代特征提取网络resnest,其中个分支通道数stem_channels=64,网络层深度depth=50,每个阶段输出特征图的索引out_indices=(0,1,2,3),批归一化设置norm_cfg=dict(type='bn',requires_grad=true),冻住第一阶段的权重frozen_stages=1;
[0055]
(42)搭建neck网络:设置neck网络为金字塔特殊映射网络fpn,输入通道与主干网络保持一致,in_channels=[256,512,1024,2048],每个金字塔特征映射层输出通道数out_channels=256,输出特征数量num_outs=5;
[0056]
(43)搭建rpn网络:每个输入特征图的通道数in_channels=256,头部卷积层的特征通道数feat_channels=256,锚点框生成配置为type='anchorgenerator',基本矩形框面积大小scales=[8],纵横比的设置是将数据增强后的干扰图像训练集的图像进行纵横比例统计后选取占比最高纵横比为代表来设置,ratios=[0.5,1.0,2.0],锚点框生成时的步长strides=[4,8,16,32,64];分类分支损失函数使用交叉熵损失函数type='crossentropyloss',激活函数使用sigmoid函数use_sigmoid=true,分类分支损失函数的权重loss_weight=1.0;回归分支的损失函数使用l1损失type='l1loss',回归分支损失函数的权重loss_weight=1.0;
[0057]
(44)roi网络层:该层使用三个type='sharedfcbboxhead'字典结构,每一个dict配置为输入通道数in_channels=256,卷积输出通道数conv_out_channels=256,全连接层输出通道数fc_out_channels=1024,池化尺寸roi_feat_size=7,类为数据集中目标种类+1(背景)即num_classes=2,边框编码器使用类型type='deltaxywhbboxcoder',目标均值方差三个字典分别设置为target_means=[0.,0.,0.,0.],target_stds=[0.1,0.1,
0.2,0.2];target_means=[0.,0.,0.,0.],target_stds=[0.05,0.05,0.1,0.1];target_means=[0.,0.,0.,0.],target_stds=[0.033,0.033,0.067,0.067];分类损失函数和回归损失函数分别为type='crossentropyloss'和type='smoothl1loss',权重设置各为1;
[0058]
(45)训练超参数配置:本发明将使用多尺度进行训练设置type='resize',img_scale=[(5280,640),(5280,320)],multiscale_mode='range',keep_ratio=true;使用随机翻转dict(type='randomflip',flip_ratio=0.5);rpn网络超参数设置中分配操作使用type='maxiouassigner',iou阈值大于等于0.7的为正样本pos_iou_thr=0.7,iou阈值小于0.3的为负样本neg_iou_thr=0.3,,iou作为最小样本的阈值min_pos_iou=0.3;采样配置中使用随机采样type='randomsampler',采样数量num=256,正样本比率pos_fraction=0.5;rpn网络提取操作设置取前2000个矩形框nms_pre=2000,经过nms算法作用后保留1000个矩形框nms_post=1000;rcnn网络超参配置同上。
[0059]
图5是本发明实施例提供的网络训练模块工作流程图。如图5所示,网络训练模块的工作流程为:
[0060]
(51)初始化数据加载器模块,等待训练数据加载;
[0061]
(52)初始化网络搭建模块,等待数据流输入;
[0062]
(53)查看设备cuda可用情况,若cuda可用,将模型训练模式更改为gpu计算模式,否则调用cpu模型;
[0063]
(54)初始化所有网络层总损失函数等待数据流输入;
[0064]
(55)初始化训练周期end_epochs,当epoch小于end_epochs时执行下一步骤6,否则结束;
[0065]
(56)将数据按批次输入网络骨架,数据流经过cascade rcnn层后计算总损失值;
[0066]
(57)定义rmpprop优化器,将损失值传入优化器后进行反向传播,逐层迭代更新网络权重参数,跳回步骤(55)。
[0067]
图6是本发明实施例提供的目标识别预测模块的工作流程图。如图6所示,雷达有源压制干扰图像目标识别预测模块的工作流程为:
[0068]
(61)初始化网络搭建模块,等待数据流输入;
[0069]
(62)输入捕获到的干扰图像;
[0070]
(63)从本地加载训练好的模型参数文件,并恢复各层网络的权重参数;
[0071]
(64)数据流通过cacade rcnn层输出概率矩阵;
[0072]
(65)通过one-shot以及nms和坐标阈值过滤算法,将概率矩阵进行反映射,输出预测的目标矩形框左上顶点坐标和右下顶点坐标以及框内目标的类别。
[0073]
雷达在其工作的各个阶段,都可能受到来自各方面的电磁干扰,不同的干扰样式对雷达工作过程的影响也不尽相同。本发明用于雷达工作时的各个阶段面临的各样式电磁干扰时精确定位目标所在区域。
[0074]
有源压制干扰大多可分为射频噪声干扰、噪声调幅干扰、噪声调频干扰和噪声调相干扰等,以传统算法进行目标识别时,往往需要先区分图像受到干扰的类型,从而提出不同干扰下目标的特征进行设计以进行特征匹配识别。而本发明提出的图像增强方法不需要事先识别有源干扰类别,随机从干扰数据集图像中抽取干扰再随机施加到另一张剥去干扰的原图像上,从而达到随机数据增强的效果。
[0075]
在有源压制干扰下的复杂背景的目标检测中,交并比(iou)是用来界定区分正样本(目标)和负样本(有源干扰背景)的阈值。在以往的深度学习目标检测方法,当使用低阈值如0.5时,训练的目标探测器通常会产生噪声,而随意提升阈值可能会导致检测性能随阈值的增加而下降。造成这一现象的主要原因主要是训练过程中由于数据集中的正样本图像如果出现指数性消失将会导致的过拟合以及检测器为最优的iou与输入假设的iou之间的推断时间不匹配造成的。针对雷达有源压制干扰下的复杂背景图像的特殊性可能出现的这些问题,本发明引用一种多级目标检测体系结构-级联r-cnn.其由一系列的随着iou阈值的提高而训练的探测器组成,以便对强干扰下接近假阳性的目标图像有更多的选择性。
[0076]
噪声压制干扰主要是通过抬高背景噪声,淹没有用信号,降低信噪比,达到干扰雷达正常工作的目的。某种意义上而言,雷达抗噪声干扰的技术手段就是提高信噪比,干扰信号带宽大,幅度动态范围小,功率利用率高。调制噪声的的概率密度为高斯分布时,噪声调频干扰的功率谱密度分布也近似满足高斯分布。本发明提出的级联探测器是分阶段训练的,r-cnn级的级联是按顺序训练的,使用一个阶段的输出来训练下一个阶段。这是因为观察到回归器的输出iou几乎总是优于输入iou,所以用一定的iou阈值训练的检测器的输出是训练下一次较高iou阈值检测器的良好分布。
[0077]
基于深度学习的级联rcnn算法在有源压制干扰的雷达图像数据集上进行训练时,提出一种针对该特殊场景的调参调优方法,该方法可以通过统计图像像素分布及训练数据真实边界框的纵横比分布来降低推理预测时目标锚框相对于边界框的预测偏移量,从而使目标识别出的位置更加精准。
[0078]
本发明在深度学习pytorch+mmdetction框架进行实践创造,本发明可显著提高在有源压制干扰的雷达图像目标识别精度,有效解决了以往传统方法多阶段识别高分辨率干扰背景下图像小目标的低时效性,有效降低了有源干扰所引起的“假阳性”的错误识别率,为实现人工智能制导领域对于雷达有源压制干扰下舰船车辆建筑群等识别提供重要技术基础。因此,将该技术应用于工程实际具有重要意义。
[0079]
本发明虽然已以较佳实施例公开如上,但其并不是用来限定本发明,任何本领域技术人员在不脱离本发明的精神和范围内,都可以利用上述揭示的方法和技术内容对本发明技术方案做出可能的变动和修改,因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所作的任何简单修改、等同变化及修饰,均属于本发明技术方案的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1