人体3D姿态估计方法、装置、计算机设备及存储介质与流程
人体3d姿态估计方法、装置、计算机设备及存储介质
技术领域
1.本发明涉及计算机视觉领域,特别涉及一种人体3d姿态估计方法、装置、计算机设备及存储介质。
背景技术:
2.三维人体姿态估计是从二维图像中识别出人体所做出的三维动作的技术。
3.现有技术中,通常是采用端到端的卷积神经网络,直接从输入图像中预测人体的3d关节点位置,然而采用传统的卷积神经网络需要根据人体3d姿态节点进行标注,通过标注信息对卷积神经网络进行训练,利用训练后的卷积神经网络对输入图像进行估计。然而人体3d姿态节点进行标注是一项劳动成本较高的工作,但当标注图像不够多时,现有技术对人体3d姿态的估计可能不够准确。
技术实现要素:
4.基于此,本技术实施例提供了一种人体3d姿态估计方法、装置、计算机设备及存储介质,可以解决现有技术对人体3d姿态估计不准确的问题。
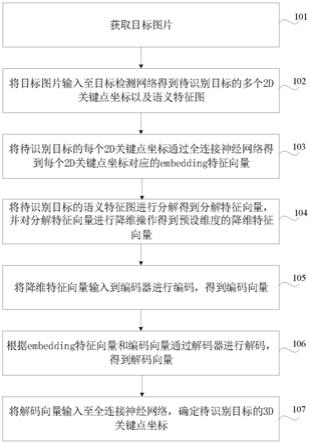
5.第一方面,提供了一种人体3d姿态识别方法,该方法包括:
6.获取目标图片,所述目标图片中包括一个待识别目标;
7.将所述目标图片输入至目标检测网络得到所述待识别目标的多个2d关键点坐标以及语义特征图;
8.将所述待识别目标的每个2d关键点坐标通过全连接神经网络得到所述每个2d关键点坐标对应的embedding特征向量;
9.将所述待识别目标的语义特征图进行分解得到分解特征向量,并对所述分解特征向量进行降维操作得到预设维度的降维特征向量;
10.将所述降维特征向量输入到编码器进行编码,得到编码向量,所述降维特征向量的个数与所述编码器的节点个数相同;
11.根据所述embedding特征向量和所述编码向量通过解码器进行解码,得到解码向量;
12.将所述解码向量输入至所述全连接神经网络,确定所述待识别目标的3d关键点坐标。
13.在其中一个实施例中,所述解码器包括三层,所述根据所述embedding特征向量和所述编码向量通过解码器进行解码,得到解码向量,包括:
14.将所述embedding特征向量和所述编码向量输入至第一解码器进行解码,得到第一解码向量;将所述第一解码向量和所述编码向量输入至第二解码器进行解码,得到第二解码向量;将所述第二解码向量和所述编码向量输入至第三解码器进行解码,得到解码向量。
15.在其中一个实施例中,所述第一解码器、所述第二解码器以及所述第三解码器具
有相同的结构。
16.在其中一个实施例中,所述将所述降维特征向量输入到编码器进行编码,得到编码向量,包括:
17.将所述降维特征向量中的每个特征向量通过3个变换矩阵变换为3个第一变换特征向量;
18.将所述第一变换特征向量输入至multi-head attention网络进行计算,得到与所述降维特征向量个数和维度相同的第一反馈向量;
19.将所述第一反馈向量与所述降维特征向量相加后,采用归一化算法进行处理,并将处理后的归一化向量中的每个向量输入2层全连接前馈网络后,与所述归一化向量相加,再将相加后的向量做归一化处理,得到编码向量。
20.在其中一个实施例中,所述语义特征图包括了特征通道数、图像高度以及图像宽度。
21.在其中一个实施例中,所述目标检测网络包括maskrcnn。
22.在其中一个实施例中,所述全连接神经网络为两层全连接神经网络。
23.第二方面,提供了一种人体3d姿态识别装置,该装置包括:
24.目标检测模块,用于将所述目标图片输入至目标检测网络得到所述待识别目标的多个2d关键点坐标以及语义特征图;
25.全连接网络模块,用于将所述待识别目标的每个2d关键点坐标通过全连接神经网络得到所述每个2d关键点坐标对应的embedding特征向量;
26.处理模块,用于根据所述待识别目标的语义特征图分解得到分解特征向量,并对所述分解特征向量进行降维操作得到预设维度的降维特征向量;
27.编码模块,用于将所述降维特征向量输入到编码器进行编码,得到编码向量,所述降维特征向量的个数与所述编码器的节点个数相同;
28.解码模块,用于根据所述embedding特征向量和所述编码向量通过解码器进行解码,得到解码向量;
29.确定模块,用于将所述解码向量输入至所述全连接神经网络,确定所述待识别目标的3d关键点坐标。
30.第三方面,提供了一种计算机设备,包括存储器和处理器,存储器存储有计算机程序,处理器执行计算机程序时实现上述第一方面任一所述的人体3d姿态识别方法。
31.第四方面,提供了一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述第一方面任一所述的人体3d姿态识别方法。
32.本技术实施例提供的技术方案通过获取具有一个待识别目标的目标图片,将目标图片输入至目标检测网络得到待识别目标的多个2d关键点坐标以及语义特征图;将得到的每个2d关键点坐标通过全连接神经网络得到对应的embedding特征向量;并将所述待识别目标的语义特征图进行分解与降维操作得到预设维度的降维特征向量;将降维特征向量输入到编码器进行编码,得到编码向量,再根据embedding特征向量和编码向量通过解码器进行解码,得到解码向量;将解码向量输入至全连接神经网络,从而确定待识别目标的3d关键点坐标,可以看出,相比于现有技术本技术通过编码器-解码器方法提高了对人体3d姿态估计的准确性。
附图说明
33.图1为本技术实施例提供的一种人体3d姿态识别方法的流程图;
34.图2为本技术实施例提供的一种人体3d姿态识别装置的框图;
35.图3为本技术实施例提供的一种计算机设备的示意图。
具体实施方式
36.为使本技术的目的、技术方案和优点更加清楚,下面将结合附图对本技术实施方式作进一步地详细描述。
37.请参考图1,其示出了本技术实施例提供的一种人体3d姿态估计方法的流程图,该人体3d姿态估计方法可以包括以下步骤:
38.步骤101,获取目标图片。
39.其中,目标图片中包括一个待识别目标,在本技术实施例中,待识别目标为人,且获取的目标图片中仅存在一个人。
40.在本技术一个实施例中,若获取到的图片中包括多个人,可以利用现有图像识别技术对该图片进行识别裁剪,将该图片裁剪成只具有一个人的目标图片。
41.步骤102,将目标图片输入至目标检测网络得到待识别目标的多个2d关键点坐标以及语义特征图。
42.其中,目标检测网络可以是maskrcnn算法,将目标图片输入至maskrcnn中可以得到目标图片中待识别目标的多个2d关键点坐标,在本技术一个实施例中可以表示为p1=(x1,y1),p2=(x2,y2),
……
pk=(xk,yk),其中k为预定义的人体关键点数目,还可以得到待识别目标roi align后的语义特征图,该语义特征图记为sem_feat_map,维度为(c,h,w),c为特征通道数,h为卷积后图像高度,w为卷积后图像宽度。
43.步骤103,将待识别目标的每个2d关键点坐标通过全连接神经网络得到每个2d关键点坐标对应的embedding特征向量。
44.其中,全连接神经网络为两层全连接神经网络,待识别目标的每个2d关键点坐标通过两层全连接神经网络提取出每个2d关键点坐标对应的embedding特征向量,在本技术一个实施例中提取出256维embedding特征向量。
45.步骤104,将待识别目标的语义特征图进行分解得到分解特征向量,并对分解特征向量进行降维操作得到预设维度的降维特征向量。
46.其中,将待识别目标的语义特征图进行分解得到分解特征向量。
47.在本技术一个实施例中将维度为(c,h,w)的特征图sem_feat_map分解为h
×
w个c维特征向量,并记h
×
w为m。由于c要大于256,所以需要对分解特征向量进行降维操作,通过降维操作将m个c维特征向量变换为m个256维特征向量。
48.步骤105,将降维特征向量输入到编码器进行编码,得到编码向量。
49.其中,降维特征向量的个数与编码器的节点个数相同。在本技术实施例中将降维特征向量中的每个特征向量通过3个变换矩阵变换为3个第一变换特征向量;将第一变换特征向量输入至multi-head attention网络进行计算,得到与降维特征向量个数和维度相同的第一反馈向量;将第一反馈向量与降维特征向量相加后,采用归一化算法进行处理,并将处理后的归一化向量中的每个向量输入2层全连接前馈网络后,与归一化向量相加,再将相
加后的向量做归一化处理,得到编码向量。
50.在本技术一个实施例中,将步骤104得到的m个256维特征向量输入到单层编码器,每个特征向量输入到编码器的一个节点,编码器共m个输入节点,具体编码过程如下:
51.s1,每个特征向量通过3个变换矩阵变换为3个特征向量q,k,v,得到共3
×
m个特征向量qi,ki,vi(i从1到m);
52.s2,将以上得到的3
×
m个特征向量输入multi-head attention层,得到m个256维向量;
53.s3,将步骤s2得到的m个向量与编码器输入的m个向量相加,得到m个256维向量;
54.s4,针对s3得到的m个256维向量,做layernorm运算,得到归一化的m个256维向量;
55.s5,针对s4得到的m个向量,将每个向量输入2层全连接前馈网络,得到m个256维向量。其中,m个向量共享一个前馈网络;
56.s6,将s5和s4得到的m个向量相加,并对相加后的m个向量做layernorm运算,得到归一化的m个256维向量,记为encoder_feat_i(i从1到m)。
57.步骤106,根据embedding特征向量和编码向量通过解码器进行解码,得到解码向量。
58.其中,将embedding特征向量和编码向量输入至第一解码器进行解码,得到第一解码向量;将第一解码向量和编码向量输入至第二解码器进行解码,得到第二解码向量;将第二解码向量和编码向量输入至第三解码器进行解码,得到解码向量。第一解码器、第二解码器以及第三解码器具有相同的结构。
59.在本技术一个实施例中,将步骤103中得到的k个256维embedding特征向量,或者每个解码层输出的k个256维向量,记为p_feat_j(j从1到k),连同步骤105中得到的m个向量encoder_feat_i(i从1到m),输入解码层,本实施例共设置3个解码层(decoder)。一次解码的具体过程包括:
60.s1,将k个向量p_feat_j中的每个特征向量通过3个变换矩阵变换为3个特征向量q,k,v,得到共3
×
k个特征向量qj,kj,vj(j从1到k);
61.s2,将以上得到的3
×
k个特征向量输入multi-head attention层,得到k个256维向量;
62.s3,将s2得到的k个向量与该层解码输入的k个向量相加,得到k个256维向量;
63.s4,针对s3得到的k个256维向量,做layernorm运算,得到归一化k个256维向量;
64.s5,将s4得到的k个向量中的每个向量通过变换矩阵变为向量q,将m个向量encoder_feat_i中的每个向量通过2个不同的变换矩阵变为k,v。总共得到2
×
m+k个向量,记为qj(j从1到k),ki,vi(i从1到m);
65.s6,将s5得到的q,k,v输入multi-head attention层,得到k个256维向量;
66.s7,将s6得到的k个向量与4)得到的k个向量相加,得到k个256维向量;
67.s8,针对s7得到的k个256维向量,做layernorm运算,得到归一化k个256维向量;
68.s9,针对s8得到的k个向量,将每个向量输入2层全连接前馈网络,得到k个256维向量。其中,k个向量共享一个前馈网络;
69.s10将s8和s9得到的k个向量相加,并对相加后的k个向量做layernorm运算,得到归一化的k个256维向量,作为每个解码层输出的k个256维向量,同时作为下一个解码层的
输入。
70.在本实施例中当解码层为3层时,进行3次上述迭代得到解码向量。
71.步骤107,将解码向量输入至全连接神经网络,确定待识别目标的3d关键点坐标。
72.在本技术一个实施例中,针对最后一个解码层输出的k个256维向量,将每个向量输入两层全连接神经网络,该网络的输出为每个关键点的3d坐标,其中,每个向量共享一个全连接网络。
73.请参考图2,其示出了本技术实施例提供的一种人体3d姿态识别装置200的框图。如图2所示,该装置200可以包括:获取模块201、目标检测模块202、全连接网络模块203、处理模块204、编码模块205、解码模块206、确定模块207。
74.获取模块201,用于获取目标图片,目标图片中包括一个待识别目标;
75.目标检测模块202,用于将目标图片输入至目标检测网络得到待识别目标的多个2d关键点坐标以及语义特征图;
76.全连接网络模块203,用于将待识别目标的每个2d关键点坐标通过全连接神经网络得到每个2d关键点坐标对应的embedding特征向量;
77.处理模块204,用于根据待识别目标的语义特征图分解得到分解特征向量,并对分解特征向量进行降维操作得到预设维度的降维特征向量;
78.编码模块205,用于将降维特征向量输入到编码器进行编码,得到编码向量,降维特征向量的个数与编码器的节点个数相同;
79.解码模块206,用于根据embedding特征向量和编码向量通过解码器进行解码,得到解码向量;
80.确定模块207,用于将解码向量输入至全连接神经网络,确定待识别目标的3d关键点坐标。
81.关于人体3d姿态识别装置的具体限定可以参见上文中对于人体3d姿态识别方法的限定,在此不再赘述。上述人体3d姿态识别装置中的各个模块可全部或部分通过软件、硬件及其组合来实现。上述各模块可以硬件形式内嵌于或独立于计算机设备中的处理器中,也可以以软件形式存储于计算机设备中的存储器中,以便于处理器调用执行以上各个模块对应的操作。
82.在一个实施例中,提供了一种计算机设备,该计算机设备可以是服务器,其内部结构图可以如图3所示。该计算机设备包括通过系统总线连接的处理器、存储器和网络接口。其中,该计算机设备的处理器用于提供计算和控制能力。该计算机设备的存储器包括非易失性存储介质、内存储器。该非易失性存储介质存储有操作系统、计算机程序和数据库。该内存储器为非易失性存储介质中的操作系统和计算机程序的运行提供环境。该计算机设备的数据库用于人体3d姿态识别数据。该计算机设备的网络接口用于与外部的终端通过网络连接通信,显示器用于显示姿态识别结果。该计算机程序被处理器执行时以实现一种人体3d姿态识别方法。
83.本领域技术人员可以理解,如图3中示出的结构,仅仅是与本技术方案相关的部分结构的框图,并不构成对本技术方案所应用于其上的计算机设备的限定,具体的计算机设备可以包括比图中所示更多或更少的部件,或者组合某些部件,或者具有不同的部件布置。
84.在本技术的一个实施例中,提供了一种计算机可读存储介质,其上存储有计算机
程序,计算机程序被处理器执行时实现上述人体3d姿态识别方法的步骤。
85.本实施例提供的计算机可读存储介质,其实现原理和技术效果与上述方法实施例类似,在此不再赘述。
86.本领域普通技术人员可以理解实现上述实施例方法中的全部或部分流程,是可以通过计算机程序来指令相关的硬件来完成,所述的计算机程序可存储于一非易失性计算机可读取存储介质中,该计算机程序在执行时,可包括如上述各方法的实施例的流程。其中,本技术所提供的各实施例中所使用的对存储器、存储、数据库或其它介质的任何引用,均可包括非易失性和/或易失性存储器。非易失性存储器可包括只读存储器(rom)、可编程rom(prom)、电可编程rom(eprom)、电可擦除可编程rom(eeprom)或闪存。易失性存储器可包括随机存取存储器(ram)或者外部高速缓冲存储器。作为说明而非局限,ram以m种形式可得,诸如静态ram(sram)、动态ram(dram)、同步dram(sdram)、双数据率sdram(ddrsdram)、增强型sdram(esdram)、同步链路(symchlimk)dram(sldram)、存储器总线(rambus)直接ram(rdram)、直接存储器总线动态ram(drdram)、以及存储器总线动态ram(rdram)等。
87.以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
88.以上所述实施例仅表达了本技术的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对申请专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本技术构思的前提下,还可以做出若干变形和改进,这些都属于本技术的保护范围。因此,本技术专利的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1