基于图卷积神经网络的恶意软件多标签分类方法
1.本发明涉及恶意软件检测技术领域,尤其涉及一种基于图卷积神经网络的恶意软件多标签分类方法。
背景技术:
2.随着恶意软件防护技术与恶意软件的博弈中,在当今网络环境中,恶意软件不在局限于一种行为的攻击,如2017年爆发的wannacry,因为其具有鲜明的加密数据进行勒索的行为,被大众划分为勒索病毒,但该恶意软件中除去勒索病毒加密文件的行为,还分别具有蠕虫通过网络进行复制传播、木马伪装软件的行为。近些年随着图神经网络(graph neural network, gnn)的发展,在提取实体之间的联系工作中取得不俗的成绩,各个领域开始尝试将引入图神经网络开展研究,恶意软件检测领域也尝试将二进制文件的控制流图(control flow graph,cfg),函数调用图(function call graph, fcg)作为切入点开展研究,但是在恶意软件的多分类中,数据集的标签只会具有一种行为标签,往往将其划分为勒索病毒、蠕虫病毒、木马中的一种,在训练的过程中,也仅仅使用一种标签,这样的模型训练后得到的单一结果与实际样本的行为有所偏差,不能够代表样本全部的真实行为。
3.图卷积神经网络(graph convolutional network,gcn)是一种图表示学习方法。它是卷积神经网络在图数据上的自然推广,能够同时对节点属性信息和拓扑结构信息进行端到端学习。
4.有鉴于此,确有必要提供一种新的基于图卷积神经网络的恶意软件多标签分类方法,以解决上述问题。
技术实现要素:
5.本发明的目的在于提供一种基于图卷积神经网络的恶意软件多标签分类方法,对具有多种标签的恶意软件具有很好的分类效果。
6.为实现上述目的,本发明提供了一种基于图卷积神经网络的恶意软件多标签分类方法,该基于图卷积神经网络的恶意软件多标签分类方法包括如下步骤:
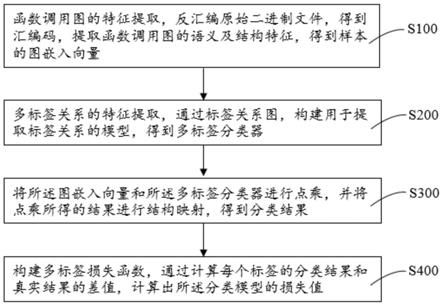
7.s100:函数调用图的特征提取,反汇编原始二进制文件,得到汇编码,提取函数调用图的语义及结构特征,得到样本的图嵌入向量;
8.s200:多标签关系的特征提取,通过标签关系图,构建用于提取标签关系的模型,得到多标签分类器;
9.s300:将所述图嵌入向量和所述多标签分类器进行点乘,并将点乘所得的结果进行结构映射,得到分类结果;
10.s400:构建多标签损失函数,通过计算每个标签的分类结果和真实结果的差值,计算出所述分类模型的损失值。
11.作为本发明的进一步改进,所述步骤s100具体包括:
12.s1:提取所述函数调用图的语义及结构特征,反汇编所述原始二进制文件得到汇
编码,构建用于提取所述函数调用图的语义及结构特征的模型,所述模型的函数调用图表示为
13.其中,代表函数调用图的语句块的集合,ε1代表函数调用图的语句块的连边集合,代表所述语句块的语义特征经过词嵌入后得到的向量,表示为
14.其中,n代表所述函数调用图的语句块的个数,r代表语句块经所述词嵌入后的向量维度,
15.经gcn训练得到所述函数调用图的图嵌入向量
16.作为本发明的进一步改进,所述步骤s1具体包括:
17.s11:获取所述二进制文件的函数调用图,对所述原始二进制文件进行反汇编,得到汇编码,分析所述汇编码的跳转关系,得到二进制文件的函数调用图
18.其中,为所述函数调用图中语句块的节点集合,ε1为所述函数调用图中语句块的连边集合;
19.s12:统计所有的所述函数调用图的语句块,提取其中的操作码(opcode) 作为单词,每个所述opcode对应自然语言处理(nlp)任务中的单词,每个所述语句块对应一个句子,采用词的向量化(world2vec)模型对所述语句块训练,得到每个所述语句块的向量进而得到所述函数调用图,表示为
20.其中,
21.s13:得到的所述函数调用图经过gcn模型公式(1)处理,得到每层卷积后节点的信息更新:
22.h
(l+1)
=f(h
l
,a)
ꢀꢀ
(1)
23.其中,使用kipf图卷积和自注意力图池化机制(sagpool)的注意力分数计算方法得到公式(2):
[0024][0025]
其中,σ是非线性激活函数,是的度矩阵,代表每一层学习权重,
[0026]
对图卷积后的结果采用sagpool进行全局池化,对于节点选择采用
[0027]
其中,池化比率k∈(0,1]是一个超参数,代表需要保留的节点数,
[0028]
通过掩模(masking)操作得到全局池化后的结果;
[0029]
s14:对所述全局池化后的结果进行读出(readout)操作,得到所述图嵌入向量
[0030]
作为本发明的进一步改进,所述步骤s200具体包括:
[0031]
s2:提取多标签关系的行为特征,通过标签关系图,构建用于提取标签关系的模型,所述模型输入为所述标签关系图,表示为
[0032]
其中,代表样本所有标签的集合,ε2代表所述标签关系的连边集合,代表节
点经一位有效编码(one
‑
hot编码)后得到的向量,表示为
[0033]
其中,c和c分别代表节点的类别个数和标签经过编码后的维度,
[0034]
经多标签训练得到多标签分类器,表示为
[0035]
作为本发明的进一步改进,所述步骤s2具体包括:
[0036]
s21:统计所述样本的标签,得到每个所述标签的条件概率和联合概率,经公式p(a|b)=p(a,b)/p(b)得到不同所述标签之间的概率;
[0037]
s22:构建相关系数矩阵a
ij
:
[0038][0039]
其中,a
ij
代表在j存在时,i发生的概率,
[0040]
将每个所述标签进行one
‑
hot编码,可以得到标签关系图
[0041]
其中,代表节点经过one
‑
hot编码后得到的向量,
[0042]
其中,c和c分别代表节点的类别个数和所述标签经过编码后的维度;
[0043]
s23:使用gcn对获取的标签关系图进行半监督学习,将不同节点关系映射到一个向量中,
[0044]
其中,学习的函数的目标分类器为卷积公式为:
[0045][0046]
其中,即为l层的多标签分类器。
[0047]
作为本发明的进一步改进,所述步骤s300具体包括:
[0048]
s3:将所述图嵌入向量x与所述多标签分类器进行点乘操作,表示为得到一个多标签的分类分数,然后经非线性运算得到最终的分类结果
[0049][0050]
其中,代表所述样本训练后对应的多分类结果,
[0051]
采用激活函数(sigmoid)将所述多分类结果结构映射到{0,1}中。
[0052]
作为本发明的进一步改进,所述步骤s400的优化目标为:
[0053]
针对每个样本的标签y∈{y1,y2,
…
y
c
},
[0054]
其中,y∈{0,1},0代表样本不具有此行为特征,1代表样本具有此行为特征,
[0055]
模型的损失函数为多个二分类的损失和,则损失函数表示为如下公式:
[0056][0057]
通过计算每个标签的分类结果和真实结果的差值,计算出模型的损失值。
[0058]
本发明的有益效果是:本发明通过从二进制文件汇编码构造出的函数调用图分析,利用world2vec提取函数调用图中的每个块语义信息,再利用gcn提取函数调用图的结构信息,得到每个二进制文件的语义和图结构嵌入,能够有效地反应二进制文件在运行过程中执行的操作特征。其次,本发明使用多标签分类,通过构建不同标签之间的联系,来构
造多标签分类器,充分考虑了恶意软件会具有多种类别行为的情况,充分分析恶意软件的行为,对具有多种标签的恶意软件具有很好的分类效果。
附图说明
[0059]
图1是本发明的基于图卷积神经网络的恶意软件多标签分类方法的流程图。
[0060]
图2是图1中的函数调用图特征提取的流程图。
[0061]
图3是图1中的获得多标签分类器的流程图。
具体实施方式
[0062]
为使本公开实施例的目的、技术方案和优点更加清楚,下面将结合本公开实施例的附图,对本公开实施例的技术方案进行清楚、完整地描述。
[0063]
请参阅图1
‑
3所示,为本发明的一种基于图卷积神经网络的恶意软件多标签分类方法,该基于图卷积神经网络的恶意软件多标签分类方法包括如下步骤:
[0064]
s100:函数调用图的特征提取,反汇编原始二进制文件,得到汇编码,提取函数调用图的语义及结构特征,得到样本的图嵌入向量;
[0065]
s200:多标签关系的特征提取,通过标签关系图,构建用于提取标签关系的模型,得到多标签分类器;
[0066]
s300:将所述图嵌入向量和所述多标签分类器进行点乘,并将点乘所得的结果进行结构映射,得到分类结果;
[0067]
s400:构建多标签损失函数,通过计算每个标签的分类结果和真实结果的差值,计算出所述分类模型的损失值。
[0068]
具体地,所述步骤s100具体包括:
[0069]
s1:提取所述函数调用图的语义及结构特征,反汇编所述原始二进制文件得到汇编码,构建用于提取所述函数调用图的语义及结构特征的模型,所述模型的函数调用图表示为
[0070]
其中,代表函数调用图的语句块的集合,ε1代表函数调用图的语句块的连边集合,代表所述语句块的语义特征经过词嵌入后得到的向量,表示为
[0071]
其中,n代表所述函数调用图的语句块的个数,r代表语句块经所述词嵌入后的向量维度,
[0072]
经gcn训练得到所述函数调用图的图嵌入向量
[0073]
进一步地,所述步骤s1具体包括:
[0074]
s11:获取所述二进制文件的函数调用图,对所述原始二进制文件进行反汇编,得到汇编码,分析所述汇编码的跳转关系,得到二进制文件的函数调用图
[0075]
其中,为所述函数调用图中语句块的节点集合,ε1为所述函数调用图中语句块的连边集合;
[0076]
s12:统计所有的所述函数调用图的语句块,提取其中的opcode作为单词,每个所述opcode对应nlp任务中的单词,每个所述语句块对应一个句子,采用world2vec模型对所
述语句块训练,得到每个所述语句块的向量进而得到所述函数调用图,表示为
[0077]
其中,
[0078]
s13:得到的所述函数调用图经过gcn模型公式(1)处理,得到每层卷积后节点的信息更新:
[0079]
h
(l+1)
=f(h
l
,a)
ꢀꢀ
(1)
[0080]
其中,使用kipf图卷积和sagpool的注意力分数计算方法得到公式(2):
[0081][0082]
其中,σ是非线性激活函数,是的度矩阵,代表每一层学习权重,
[0083]
对图卷积后的结果采用sagpool进行全局池化,对于节点选择采用
[0084]
其中,池化比率k∈(0,1]是一个超参数,代表需要保留的节点数,
[0085]
通过masking操作得到全局池化后的结果;
[0086]
s14:对所述全局池化后的结果进行readout操作,得到所述图嵌入向量
[0087]
在本技术中,步骤s200具体包括:
[0088]
s2:提取多标签关系的行为特征,通过标签关系图,构建用于提取标签关系的模型,所述模型输入为所述标签关系图,表示为
[0089]
其中,代表样本所有标签的集合,ε2代表所述标签关系的连边集合,代表节点经one
‑
hot编码后得到的向量,表示为
[0090]
其中,c和c分别代表节点的类别个数和标签经过编码后的维度,
[0091]
经多标签训练得到多标签分类器,表示为
[0092]
进一步地,步骤s2具体包括:
[0093]
s21:统计所述样本的标签,得到每个所述标签的条件概率和联合概率,经公式p(a|b)=p(a,b)/p(b)得到不同所述标签之间的概率。
[0094]
s22:构建相关系数矩阵a
ij
:
[0095][0096]
其中,a
ij
代表在j存在时,i发生的概率,
[0097]
将每个所述标签进行one
‑
hot编码,可以得到标签关系图
[0098]
其中,代表节点经过one
‑
hot编码后得到的向量,
[0099]
其中,c和c分别代表节点的类别个数和所述标签经过编码后的维度。
[0100]
s23:使用gcn对获取的标签关系图进行半监督学习,将不同节点关系映射到一个向量中,
[0101]
其中,学习的函数的目标分类器为卷积公式为:
[0102][0103]
其中,即为l层的多标签分类器。
[0104]
步骤s300具体包括:
[0105]
s3:将所述图嵌入向量x与所述多标签分类器进行点乘操作,表示为得到一个多标签的分类分数,然后经非线性运算得到最终的分类结果
[0106][0107]
其中,代表所述样本训练后对应的多分类结果,
[0108]
采用sigmoid将所述多分类结果结构映射到{0,1}中。
[0109]
步骤s400的优化目标为:针对每个样本的标签y∈{y1,y2,
…
y
c
},
[0110]
其中,y∈{0,1},0代表样本不具有此行为特征,1代表样本具有此行为特征,
[0111]
模型的损失函数为多个二分类的损失和,则损失函数表示为如下公式:
[0112][0113]
通过计算每个标签的分类结果和真实结果的差值,计算出模型的损失值。
[0114]
综上所述,本发明通过从二进制文件汇编码构造出的函数调用图分析,利用world2vec提取函数调用图中的每个块语义信息,再利用gcn网络提取函数调用图的结构信息,得到每个二进制文件的语义和图结构嵌入,能够有效地反应二进制文件在运行过程中执行的操作特征。其次,本发明使用多标签分类,通过构建不同标签之间的联系,来构造多标签分类器,充分考虑了恶意软件会具有多种类别行为的情况,充分分析恶意软件的行为,对具有多种标签的恶意软件具有很好的分类效果。
[0115]
以上实施例仅用以说明本发明的技术方案而非限制,尽管参照较佳实施例对本发明进行了详细说明,本领域的普通技术人员应当理解,可以对本发明的技术方案进行修改或者等同替换,而不脱离本发明技术方案的精神和范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1