一种统计报表数据序列化加工处理方法与流程
1.本发明属于统计报表数据清洗加工处理技术领域,特别是涉及一种统计报表数据序列化加工处理方法。
背景技术:
2.政府部门对外发布的统计数据通常以电子表格(报表)的形式呈现,统计报表依然是政府统计工作成果的主要载体,是获取统计数据的重要来源。统计报表发布具有连续性,通常按月度、季度、年度频率定期发布,为了能有效地利用统计报表中的数据进行商业智能分析,通常需要对其进行序列化清洗加工,意义在于对非结构化报表数据进行标准化处理,明确报表包含的维度属性,以使处理后的标准结构化序列数据包含指标、地区、行业、国家、时间五个维度,对历史相同统计报表和序列进行关联,合并抽取包含标准序列的历年时间序列数据供分析研究使用。
3.统计报表数据序列化加工清洗的主要难点在于报表样式众多,统计制度、标准一直在发生变化,从而导致历年间相同报表存在结构与内容上的差异。
技术实现要素:
4.为了解决上述问题,本发明的目的在于提供了一种统计报表数据序列化加工处理方法。
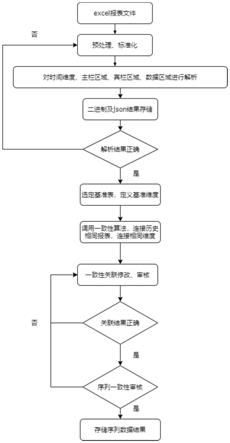
5.为了达到上述目的,本发明提供的统计报表数据序列化加工处理方法包括按顺序进行的下列步骤:
6.1)每一类别统计资料包含多期,每一期中又包含多张统计报表;对同一类别的原始excel形式的所有统计报表分别进行预处理和标准化,获得预处理和标准化后的统计报表;
7.2)对所有上述预处理和标准化后的统计报表进行解析,获得二维统计报表集合;
8.3)从上述二维统计报表集合中选择最新一期作为基准报表,基准报表中包含多个统计报表,然后分别将每个统计报表拆解成具有多个维度的基准二维统计报表,由所有基准二维统计报表构成基准二维统计报表集合;
9.4)将上述基准二维统计报表集合中的每个基准二维统计报表与二维统计报表集合中任一期的所有二维统计报表逐个进行标题相似度计算,获得多组标题相似度,将每组中标题相似度最大的两个统计报表确认为一致并作为一个统计报表对,由多个统计报表对构成待处理报表集合,由此将标题相似的统计报表进行了关联;
10.5)将上述待处理报表集合中指标维度、地区维度、行业维度、国家维度分别与基准二维统计报表中对应的维度进行匹配,由此将维度相似的统计报表进行关联;
11.6)以基准序列作为基准,将其他统计报表中与基准序列关联一致的序列进行合并,合并数据时按照统计报表发布时间先后进行取舍,以最新发布的统计报表数据为准,进行数据选取,由此将历年统计报表处理成包含历史数据的时间序列数据,从而完成统计报
表数据序列化处理。
12.在步骤1)中,所述对同一类别的原始excel形式的所有统计报表分别进行预处理和标准化的方法是:将标题放置在excel表格的第一单元格内;表格框线不完整时对表格框线进行修改;对于存在续表的情况将续表与主表进行合并。
13.在步骤2)中,所述对所有上述预处理和标准化后的统计报表进行解析,获得二维统计报表集合的方法是:
14.2.1)一份完整的统计报表通常包括标题区域、表头注释区域、表尾注释区域和表体a;其中表体a包括主栏区域b、宾栏区域c和数据区域d;主栏区域a 中每一列代表一个主栏指标zz;宾栏区域c中每一行代表一个宾栏指标bz;主栏指标zz与宾栏指标bz在统计报表中交叉的位置为数值v;
15.首先利用报表解析算法依据表格框线识别出统计报表的标题区域、表头注释区域、表尾注释区域和表体a;然后进一步通过底色特征和表格框线识别出表体a内部的主栏区域b、宾栏区域c和数据区域d;之后利用表格框线对主栏区域b进行父子层级分析,以主栏指标zz为起点遍历,查找主栏指标zz的所有子节点指标,将主栏指标zz改为以冒号分隔的全路径名称表示形式,形成主栏指标全称zz1;再对宾栏区域c利用缩进和对应数据区域d的数值进行父子层级分析,以宾栏指标bz为起点遍历,查找宾栏指标bz的所有子节点指标,将宾栏指标bz改为以冒号分隔的全路径名称表示形式,形成宾栏指标全称bz1;将标题中序号及年份在内的无用信息剔除,形成标题指标title;最后按照“标题指标 title&主栏指标全称zz1&宾栏指标全称bz1”的形式组成序列指标;由序列指标与数值v构成序列;
16.2.2)利用时间解析算法依据统计报表发布时间解析出报表默认时间t1;使用正则表达式从标题中解析出标题时间t2;从上述序列指标中解析出序列时间t3;如果存在的话将报表默认时间t1、标题时间t2和序列时间t3相应的表述内容从序列指标中移除;然后按照t3>t2>t1的优先级提取出相应的时间指标;最终将所有预处理和标准化后的统计报表均处理成包含序列指标、时间指标和指标数值的二维统计报表,并以json形式保存;由所有二维统计报表构成二维统计报表集合j。
17.在步骤3)中,所述从上述二维统计报表集合中选择最新一期作为基准报表,基准报表中包含多个统计报表,然后分别将每个统计报表拆解成具有多个维度的基准二维统计报表,由所有基准二维统计报表构成基准二维统计报表集合的方法是:
18.在上述二维统计报表集合j中选择最新一期作为基准报表,该基准报表中包含多个统计报表,然后分别对每个统计报表进行序列指标拆解,将属于地区、行业、国别的内容从序列指标中移除并定义为地区维度、行业维度、国家维度,地区维度、行业维度、国家维度允许为空,形成基准序列指标;由基准序列指标和对应的数值v构成基准序列,由此将基准报表拆解成具有指标维度、地区维度、行业维度、国家维度、时间维度和相应维度数值的基准二维统计报表jj,由所有基准二维统计报表构成基准二维统计报表集合jz。
19.在步骤4)中,所述将上述基准二维统计报表集合中的每个基准二维统计报表与二维统计报表集合中任一期的所有二维统计报表逐个进行标题相似度计算,获得多组标题相似度,将每组中标题相似度最大的两个统计报表确认为一致并作为一个统计报表对,由多个统计报表对构成待处理报表集合h,由此将标题相似的统计报表进行了关联的方法是:
20.4.1)使用正则表达式将上述二维统计报表集合j中任一期的每个二维统计报表标
题中的报表序号、年份内容进行剔除,获得多个待匹配标题m1;使用正则表达式将上述基准二维统计报表集合jz中每个基准二维统计报表标题中的序号、年份内容进行剔除,获得多个基准标题m;
21.4.2)使用jieba工具分别对待匹配标题m1和基准标题m进行分词,得到各自的字符串;
22.4.3)将基准标题m与待匹配标题m1的字符串合并构成一个词袋,那么这两个标题就可以用两个向量来表示;
23.4.4)根据上述向量利用余弦相似度公式计算出标题相似度,计算公式如下:
[0024][0025]
其中,d1为基准标题m的向量;d2为待匹配标题m1的向量;
[0026]
由此获得多组标题相似度;
[0027]
4.5)将每组中标题相似度最大的两个统计报表确认为一致并作为一个统计报表对,当最大的标题相似度小于0.9时,由人工进行确认,由此将标题相似的统计报表进行了关联;由多个统计报表对构成待处理报表集合h。
[0028]
在步骤5)中,所述将上述待处理报表集合h中指标维度、地区维度、行业维度、国家维度分别与基准二维统计报表中对应的维度进行匹配,由此将维度相似的统计报表进行关联的方法是:
[0029]
由于地区、行业、国别均有相应的国标,因此利用维度字典进行自动匹配;对于指标维度,按照步骤4)中标题相似度计算类似的方法进行序列相似度计算,将序列相似度最大的两个指标序列确认为一致,当最大的序列相似度小于0.9 时,由人工进行确认,从而将历史相同的序列指标进行了关联。
[0030]
本发明提供的统计报表数据序列化加工处理方法具有如下有益效果:依靠自然语言处理技术实现统计报表数据智能化、自动化清洗,从而可以从历年非结构化报表数据中提取出标准的时间序列数据,由此实现高效、快捷的数据清洗加工,从而降低统计报表数据清洗加工的复杂度,提升统计报表数据加工效率。
附图说明
[0031]
图1为本发明提供统计报表数据序列化加工处理方法流程图。
具体实施方式
[0032]
下面结合附图和具体实施例对本发明进行详细说明。
[0033]
如图1所示,本发明提供的统计报表数据序列化加工处理方法包括按顺序进行的下列步骤:
[0034]
1)每一类别统计资料包含多期,每一期中又包含多张统计报表;对同一类别的原始excel形式的所有统计报表分别进行预处理和标准化,获得预处理和标准化后的统计报表;
[0035]
将标题放置在excel表格的第一单元格内;表格框线不完整时对表格框线进行修改;对于存在续表的情况将续表与主表进行合并。
[0036]
2)对所有上述预处理和标准化后的统计报表进行解析,获得二维统计报表集合;
[0037]
2.1)一份完整的统计报表通常包括标题区域、表头注释区域、表尾注释区域和表体a;其中表体a包括主栏区域b、宾栏区域c和数据区域d;主栏区域a 中每一列代表一个主栏指标zz;宾栏区域c中每一行代表一个宾栏指标bz;主栏指标zz与宾栏指标bz在统计报表中交叉的位置为数值v;
[0038]
首先利用报表解析算法依据表格框线识别出统计报表的标题区域、表头注释区域、表尾注释区域和表体a;然后进一步通过底色特征和表格框线识别出表体a内部的主栏区域b、宾栏区域c和数据区域d;之后利用表格框线对主栏区域b进行父子层级分析,以主栏指标zz为起点遍历,查找主栏指标zz的所有子节点指标,将主栏指标zz改为以冒号分隔的全路径名称表示形式,形成主栏指标全称zz1;再对宾栏区域c利用缩进和对应数据区域d的数值进行父子层级分析,以宾栏指标bz为起点遍历,查找宾栏指标bz的所有子节点指标,将宾栏指标bz改为以冒号分隔的全路径名称表示形式,形成宾栏指标全称bz1;将标题中序号及年份在内的无用信息剔除,形成标题指标title;最后按照“标题指标 title&主栏指标全称zz1&宾栏指标全称bz1”的形式组成序列指标;由序列指标与数值v构成序列;
[0039]
2.2)利用时间解析算法依据统计报表发布时间解析出报表默认时间t1;使用正则表达式从标题中解析出标题时间t2;从上述序列指标中解析出序列时间 t3;如果存在的话将报表默认时间t1、标题时间t2和序列时间t3相应的表述内容从序列指标中移除;然后按照t3>t2>t1的优先级提取出相应的时间指标;最终将所有预处理和标准化后的统计报表均处理成包含序列指标、时间指标和指标数值的二维统计报表,并以json形式保存;由所有二维统计报表构成二维统计报表集合j。
[0040]
3)从上述二维统计报表集合中选择最新一期作为基准报表,基准报表中包含多个统计报表,然后分别将每个统计报表拆解成具有多个维度的基准二维统计报表,由所有基准二维统计报表构成基准二维统计报表集合;
[0041]
在上述二维统计报表集合j中选择最新一期作为基准报表,该基准报表中包含多个统计报表,然后分别对每个统计报表进行序列指标拆解,将属于地区、行业、国别的内容从序列指标中移除并定义为地区维度、行业维度、国家维度,地区维度、行业维度、国家维度允许为空,形成基准序列指标;由基准序列指标和对应的数值v构成基准序列,由此将基准报表拆解成具有指标维度、地区维度、行业维度、国家维度、时间维度和相应维度数值的基准二维统计报表jj,由所有基准二维统计报表构成基准二维统计报表集合jz。
[0042]
4)将上述基准二维统计报表集合中的每个基准二维统计报表与二维统计报表集合中任一期的所有二维统计报表逐个进行标题相似度计算,获得多组标题相似度,将每组中标题相似度最大的两个统计报表确认为一致并作为一个统计报表对,由多个统计报表对构成待处理报表集合h,由此将标题相似的统计报表进行了关联;
[0043]
具体步骤如下:
[0044]
4.1)使用正则表达式将上述二维统计报表集合j中任一期的每个二维统计报表标题中的报表序号、年份内容进行剔除,获得多个待匹配标题m1,假设该期中共包括10个二维统计报表,则剔除处理后共获得10个待匹配标题m1;使用正则表达式将上述基准二维统计报表集合jz中每个基准二维统计报表标题中的序号、年份内容进行剔除,获得多个基准标题m;假设基准二维统计报表集合jz中也包括10个基准二维统计报表,使用正则表达式将基
准二维统计报表标题中的报表序号、年份内容进行剔除,则剔除处理后共获得10个基准标题m;
[0045]
例如:一个二维统计报表标题为“1
‑
4中国香港按行业分就业人数(2019年底)”,一个基准二维统计报表标题为“1
‑
3中国香港按行业划分的就业人数”;使用正则表达式剔除报表序号、年份内容后分别获得待匹配标题m1=“中国香港按行业分的就业人数”和基准标题m=“中国香港按行业划分的就业人数”。
[0046]
4.2)使用jieba工具分别对待匹配标题m1和基准标题m进行分词,得到各自的字符串;
[0047]
例如:待匹配标题m1=“中国香港按行业分的就业人数”分词后得到的字符串为“中国香港/按/行业/分/的/就业人数”;基准标题m=“中国香港按行业划分的就业人数”分词后得到的字符串为“中国香港/按/行业/划分/的/就业人数”。
[0048]
4.3)将基准标题m与待匹配标题m1的字符串合并构成一个词袋,那么这两个标题就可以用两个向量来表示:
[0049]
例如:上述基准标题m和待匹配标题m1的向量分别为:
[0050]
[1,1,1,1,1,1,0]
[0051]
[1,1,1,0,1,1,1]
[0052]
4.4)根据上述向量利用余弦相似度公式计算出标题相似度,计算公式如下:
[0053][0054]
其中,d1为基准标题m的向量;d2为待匹配标题m1的向量。
[0055]
例如:上述基准标题m和待匹配标题m1的标题相似度为0.83。
[0056]
由此获得多组标题相似度;
[0057]
4.5)将每组中标题相似度最大的两个统计报表确认为一致并作为一个统计报表对,当最大的标题相似度小于0.9时,由人工进行确认,由此将标题相似的统计报表进行了关联;由多个统计报表对构成待处理报表集合h,
[0058]
5)将上述待处理报表集合h中指标维度、地区维度、行业维度、国家维度分别与基准二维统计报表中对应的维度进行匹配,由此将维度相似的统计报表进行关联;
[0059]
由于地区、行业、国别均有相应的国标,因此利用维度字典进行自动匹配;对于指标维度,按照步骤4)中标题相似度计算类似的方法进行序列相似度计算,将序列相似度最大的两个指标序列确认为一致,当最大的序列相似度小于0.9 时,由人工进行确认,从而将历史相同的序列指标进行了关联。
[0060]
6)通过标题相似度计算将历史各期中相同统计报表与基准报表进行了关联,进一步通过指标相似度计算将相同统计报表中相同序列进行了关联。以基准序列作为基准,将其他统计报表中与基准序列关联一致的序列进行合并,合并数据时按照统计报表发布时间先后进行取舍,以最新发布的统计报表数据为准,进行数据选取,由此将历年统计报表处理成包含历史数据的时间序列数据,从而完成统计报表数据序列化处理。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1