一种基于八叉树索引的海量点云分层实时渲染方法与流程
1.本发明属于三维激光扫描数据处理技术领域,涉及一种基于八叉树索引的海量点云分层实时渲染方法。
背景技术:
2.目前三维激光扫描技术可用于文物数字化保护、土木工程、工业测量、自然灾害调查、数字城市地形可视化、城乡规划等领域,其数据量往往达到gb甚至tb级,而常用的电脑内存只有4
‑
16gb,无法将点云数据一次性加载,需要对海量点云进行管理及调度。目前常用kd树、r树、四叉树、八叉树等,并结合金字塔结构对点云构建索引,而索引构建的好坏直接影响对点云数据的组织查询效率,若点云不能做到实时刷新,则不能满足海量点云可视化的需求。
3.专利cn104750854b公开了一种海量三维激光点云压缩存储及快速加载显示方法,通过采集点云数据总体结构、按照不同级别对数据进行分类、压缩,每一级别包括块集、块和包三级索引,实现高度存储和快速加载显示,但其在点云分块时未考虑点云文件数据大小,及点云稀疏分布的特点,会造成很多的空包与内存浪费等。
4.专利cn106407408b、cn105808672等公开了一种海量点云数据的空间索引构建方法及装置对获取的原始点云数据进行分块处理,得到多个点云数据块;对于每个点云数据块,构建当前点云数据块的八叉树索引;将多个点云数据块的八叉树索引进行合并处理,得到原始点云数据的空间索引结构,但其在点云八叉树金字塔结构建立过程中,不同层存在交集,造成数据冗余;且其采用随机采样方法,造成抽稀的点云数据不均匀。
技术实现要素:
5.为了弥补现有技术的不足,本发明提供一种基于八叉树索引的海量点云分层实时渲染方法,减少了内存消费,提高了索引查询效率且避免数据冗余。
6.为了达到上述目的,本发明所采用的技术方案为:
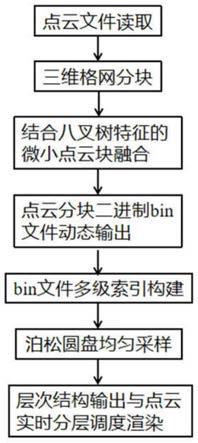
7.一种基于八叉树索引的海量点云分层实时渲染方法,包括如下步骤:
8.步骤一:点云三维格网分块;
9.步骤二:结合八叉树特征的微小点云块融合;
10.步骤三:点云分块二进制bin文件动态输出;
11.步骤四:点云分块二进制bin文件的多级索引构建;
12.步骤五:泊松圆盘均匀采样;
13.步骤六:层次结构输出与点云实时分层调度渲染。
14.具体地,步骤一包括如下步骤:
15.1)根据点云文件头记录的坐标范围及点云个数,定义三维空间格网单元的边长大小;依据所述三维空间格网单元的边长大小,定义三维格网线性编码数组;
16.2)固定读取点云文件中一百万个点,依据数据的地址位链接访问所述一百万个点
的点坐标,并定义线程池,采用多线程机制动态循环并行读取点云数据;
17.3)根据点云文件头记录的坐标范围,计算每个点在三维格网中的位置索引及线性索引编码;以线性编码方式进行单元块的映射,并分别统计落入各个三维网格单位中的点个数;
18.所述每个点在三维格网中的位置索引计算公式如下:
19.possize=(max
‑
min).max()
[0020][0021]
所述每个点在三维格网中的线性索引编码计算公式如下:
[0022]
index=nx+ny*gridsize+nz*gridsize*gridsize
[0023]
式中,index—各点线性索引编码;(nx,ny,nz)—各点位置索引;gridsize—三维空间格网单元的边长大小;possize—三维坐标差最大值。
[0024]
具体地,步骤二包括如下步骤:
[0025]
1)定义点云块点个数阈值threshold1,以所述三维空间格网单元边长的对数作为金字塔最大分层level
max
;
[0026]
2)从所述金字塔最大分层开始从下往上层级循环,依据所述每个点在三维格网中的位置索引及线性索引编码,访问各点的八个临近节点,计算八个单元块点个数总和;
[0027]
3)若所述八个单元块点个数总和小于等于点云块点个数阈值threshold1,进行块融合处理;若所述八个单元块点个数总和大于点云块点个数阈值threshold1,根据位置编码及当前层级,保存各个节点node,建立对应的节点查询索引编码luindex,并设置标识符flag=true,表示此单元块已完成融合;所述保存各个节点node方法如下:
[0028][0029]
位置编码索引(mx,my,mz)定义公式如下:
[0030][0031]
式中,位置编码(ox,oy,oz)的值为{(0,0,0),(0,0,1),(0,1,0),(0,1,1),(1,0,0),(1,0,1),(1,1,0),(1,1,1)};i=0,1,2,3,4,5,6,7;nx/ny/nz为三维格网坐标轴的单元序号;
[0032]
所述节点查询索引编码定义公式如下:
[0033][0034]
式中,currentgridsize=2
level
,luindex的初始值为0
[0035]
4)逐层循环步骤2)和3)获得具有金字塔结构的八叉树点云分块结果;
[0036]
5)根据存储的分块节点node,完成三维格网合并后索引的构建,后续每个点坐标落入对应块建立查询表,即完成三维格网点云块的融合处理。
[0037]
具体地,步骤三包括如下步骤:
[0038]
1)对读取的固定点个数进行循环,根据每个点坐标在三维格网中的线性编码及所述查询表,判断每个点落入的点云块节点;
[0039]
2)对点云坐标减去坐标范围的最小值,并与比例尺相除,取整的结果以二进制格式输出到文件中,其中二进制文件以步骤二中获得的查询索引编码luindex命名;
[0040]
3)利用多线程方式在内存中完成数据读取和输出的动态过程,且实时对各个文件的属性值进行更新,最终获得输出到外存中的各个分块节点的二进制bin文件。
[0041]
具体地,步骤四包括如下步骤:
[0042]
1)读取输出的点云分块二进制bin文件,将单个bin文件作为根节点,进行点云格网分块计数;定义最大分层为level=5,则格网单元边长为32;
[0043]
2)点云分块计数过程中采用线性八叉树的morton编码,存储点数据;
[0044]
3)对分块的点云从下往上循环建立金字塔层级结构8
level
,依据地址码索引,计算其相邻八个子节点的点个数之和sum,作为上一层的点云块索引值,由此建立统计金字塔sumpyramid;
[0045]
4)在完成点云分层计数后,定义点云块点个数阈值threshold2,所述点云块点个数阈值threshold2小于点云块点个数阈值threshold1;从上往下判断各个点云块点个数是否大于设定的点云块点个数阈值threshold2;
[0046]
5)若点云块点个数小于等于点云块点个数阈值threshold2,与微小点云块融合不同,此时记录点云块为节点node;为节点结构设置比特掩码bit
‑
mask,来确定子节点是否为空,并记录节点查询索引编码、地址码起始位、点个数、层级、位置编码等属性信息;
[0047]
6)若点云块点个数大于点云块点个数阈值threshold2,则通过morton地址码访问下一层阶对应的统计金字塔sumpyramid;
[0048]
依据4)、5)、6),直到检索到最底层金字塔;若点云块点个数大于点云块点个数阈值threshold2,则判定此点云块为新的根节点,重复上述点云格网分块、金字塔分层计数步骤。
[0049]
具体地,步骤五包括如下步骤:
[0050]
1)根据三维格网范围大小,设定最大采样间距s,对不同层级level,自适应最小采样半径r=s/2
level
;
[0051]
2)以bin文件的范围中心为枢纽,以点到中心的距离从小到大进行排序;
[0052]
3)以经过排序后点云数组中第一个点作为采样点,当候选点pt到中心点center的距离与任何一个采样点到中心点的距离差值都大于指定采样半径r或候选点与所有采样点的距离差均大于采样半径r时,将候选点添加到采样点数组中;反之,将候选点作为非采样点;对所有候选点重复以上步骤;
[0053]
4)将非采样点数组保存为level层的点云,输出采样后的节点数据到二进制文件result.bin中,并记录点个数、字节大小,以不断更新累加的输出点云字节总大小作为地址起始位进行数据的输出存储,完成多个bin文件的合并处理;
[0054]
5)将采样点更新为高一级即level
‑
1层的点云,并重复上述步骤1)、2)、3)、4),完成八叉树点云块的金字塔分层抽稀。
[0055]
具体地,步骤六包括如下步骤:
[0056]
1)在bin文件的层级采样过程中,对建立的层次结构索引进行输出;
[0057]
2)对层次结构信息输出定义:节点命名+比特掩码+点个数+地址起始位+字节大小+节点坐标范围最小值+节点坐标范围最大值,定义公式如下:
[0058][0059]
3)根据视口范围,判断节点是否落入视野内,并设定点云密度,读取输出的result.bin文件,自适应加载对应金字塔层级的点云数据;
[0060]
4)采用直方图均衡化方法,对读取的点云数据进行灰度值统计,获得每个灰度值的概率分布,最后进行动态范围的扩展,完成灰度直方图的对比度拉伸处理;
[0061]
5)采取灰度分割法或灰度彩色变换法完成伪彩色渲染。
[0062]
本发明的有益效果:
[0063]
1)考虑到点云数据量超过100gb、甚至tb级别时,常规方法只对点云进行一次格网划分,在构建索引及后续查询时,会造成时间消耗,甚至会造成内存卡顿;本发明对点云文件进行三维格网分块,定义的格网边长不需太大,且将点数较少的格网单元合并到临近网格中;完成索引构建及二进制bin文件输出后,分别读取输出的bin文件,并将单个bin文件作为根节点,再次进行点云格网分块计数,大大减少了内存消费,提高了索引查询效率;
[0064]
2)在对三维格网进行分块计数过程中,建立了三维线性索引编码,并利用线性八叉树的数据压缩功能,通过morton地址码访问相邻子节点,从下往上循环建立具有金字塔层级结构的八叉树点云节点结构,同时为避免不需要的映射关联,为节点结构设置了比特
掩码bit
‑
mask等;
[0065]
3)本发明采用改进泊松圆盘采样策略,定义自适应最小采样半径,从下而上对二进制文件进行金字塔分层抽稀处理,最终可得到均匀分布的采样点,且不同金字塔层点云属于并集关系,不存在交叉,避免了数据冗余。
附图说明
[0066]
图1是本发明总流程图;
[0067]
图2是三维格网分块及单元合并结果俯视图;
[0068]
图3是三维格网分块及单元合并结果侧视图;
[0069]
图4是金字塔不同分层结果示例图;
[0070]
图5是泊松圆盘采样点与候选点判断示意图;
[0071]
图6是金字塔分层采样二维简化图。
具体实施方式
[0072]
下面结合具体实施方式对本发明进行详细的说明。
[0073]
本实施例以las点云文件为基础,其文件大小为28gb,共11亿个点;如图1本发明总流程图所示,本发明包括如下步骤:
[0074]
步骤一:点云三维格网分块
[0075]
1)根据点云文件头记录的坐标范围及点云个数,定义三维空间格网单元的边长大小,格网边长采用256;依据所述三维空间格网单元的边长大小,定义三维格网线性编码数组grid[256*256*256];
[0076]
2)固定读取点云文件中一百万个点,依据数据的地址位链接访问所述一百万个点的点坐标,并定义线程池,采用多线程机制动态循环并行读取点云数据;
[0077]
3)根据点云文件头记录的坐标范围,可得三维坐标差最大值possize=4150,计算每个点在三维格网中的位置索引及线性索引编码;以线性编码方式进行单元块的映射,并分别统计落入各个三维网格单位中的点个数;
[0078]
所述每个点在三维格网中的位置索引计算公式如下:
[0079]
possize=(max
‑
min).max()
[0080][0081]
所述每个点在三维格网中的线性索引编码计算公式如下:
[0082]
index=nx+ny*gridsize+nz*gridsize*gridsize
[0083]
式中,index—各点线性索引编码;(nx,ny,nz)—各点位置索引;gridsize—三维空间格网单元的边长大小;
[0084]
步骤二:结合八叉树特征的微小点云块融合
[0085]
为减少网格单元中点云数据过少,造成数据块稀疏分布的缺点,结合八叉树结构特征,通过金字塔分层方式对微小点云块进行融合,具体步骤如下:
[0086]
1)定义点云块点个数阈值threshold1,比如1千万,以所述三维空间格网单元边长
的对数log2(gridsize)作为金字塔最大分层level
max
;gridsize取256时,最大层level
max
=8;
[0087]
2)从所述金字塔最大分层开始从下往上层级循环,依据所述每个点在三维格网中的位置索引及线性索引编码,访问各点的八个临近节点,计算八个单元块点个数总和;
[0088]
3)若所述八个单元块点个数总和小于等于点云块点个数阈值threshold1,进行块融合处理;若所述八个单元块点个数总和大于点云块点个数阈值threshold1,根据位置编码及当前层级,保存各个节点node,建立对应的节点查询索引编码luindex,并设置标识符flag=true,表示此单元块已完成融合;所述保存各个节点node方法如下:
[0089][0090]
位置编码索引(mx,my,mz)定义公式如下:
[0091][0092]
式中,位置编码(ox,oy,oz)的值为{(0,0,0),(0,0,1),(0,1,0),(0,1,1),(1,0,0),(1,0,1),(1,1,0),(1,1,1)};i=0,1,2,3,4,5,6,7;nx/ny/nz为三维格网坐标轴的单元序号;
[0093]
所述节点查询索引编码定义公式如下:
[0094][0095]
式中,currentgridsize=2
level
,luindex的初始值为0
[0096]
4)逐层循环步骤2)和3)获得具有金字塔结构的八叉树点云分块结果;
[0097]
5)根据存储的分块节点node,完成三维格网合并后索引的构建,后续每个点坐标落入对应块建立查询表,即完成三维格网点云块的融合处理;如图2与图3所示为对点数较少的单元进行合并后的不规则八叉树格网;
[0098]
步骤三:点云分块二进制bin文件动态输出
[0099]
1)对读取的固定点个数进行循环,根据每个点坐标在三维格网中的线性编码及所述查询表,判断每个点落入的点云块节点;
[0100]
2)为节省存储空间,对点云坐标减去坐标范围的最小值,并与比例尺相除,取整的结果以二进制格式输出到文件中,其中二进制文件以步骤二中获得的查询索引编码luindex命名;比如r240,即表示此二进制文件落入八叉树的第3层,第1层位于子节点2,第2层以第1层子节点2作为根节点,其位于子节点4,第3层以第2层的子节点4为根节点,其位于子节点0,由此完成bin文件的快速查找;
[0101]
3)利用多线程方式在内存中完成数据读取和输出的动态过程,且实时对各个文件的属性值进行更新,最终获得输出到外存中的各个分块节点的二进制bin文件。
[0102]
步骤四:点云分块二进制bin文件的多级索引构建
[0103]
为减小后续对点云浏览时内存调用,以及优化点云密度较大块的处理效果,需对输出的分块bin文件进行金字塔多级索引构建处理,具体步骤如下:
[0104]
1)读取输出的点云分块二进制bin文件,将单个bin文件作为根节点,进行点云格网分块计数;定义最大分层为level=5,则格网单元边长为32;这种处理方式避免了总数据量达到tb级时容易出错崩溃问题,且大大提高了索引查询效率;
[0105]
2)为对点云数据进一步压缩,点云分块计数过程中采用线性八叉树的morton编码,存储点数据;
[0106]
3)对分块的点云从下往上循环建立金字塔层级结构8
level
,依据地址码索引,可计算其相邻八个子节点即0
‑
7点云块的点个数之和sum,作为上一层的点云块索引值,由此建立统计金字塔sumpyramid;
[0107]
4)在完成点云分层计数后,定义点云块点个数阈值threshold2,所述点云块点个数阈值threshold2小于点云块点个数阈值threshold1;从上往下判断各个点云块点个数是否大于设定的点云块点个数阈值threshold2;
[0108]
5)若点云块点个数小于等于点云块点个数阈值threshold2,与微小点云块融合不同,此时记录点云块为节点node;为节点结构设置比特掩码bit
‑
mask,来确定子节点是否为空,并记录节点查询索引编码、地址码起始位、点个数、层级、位置编码等属性信息;
[0109]
6)若点云块点个数大于点云块点个数阈值threshold2,则通过morton地址码访问下一层阶对应的统计金字塔sumpyramid;
[0110]
依据4)、5)、6),直到检索到最底层金字塔;若点云块点个数仍大于点云块点个数阈值threshold2,则判定此点云块为新的根节点,重复上述点云格网分块、金字塔分层计数步骤,即点密度越大的节点块,分层层级越深;
[0111]
通过线性八叉树对bin文件进行金字塔分块分层处理,即可反应八叉树的层次关系,对应的分割节点node记录了对bin文件的访问起始地址、字节大小等属性,又达到了数据的快速检索目的
[0112]
步骤五:泊松圆盘均匀采样
[0113]
完成bin文件的node多级索引构建后,从下而上对bin文件进行金字塔分层抽稀处理。为解决随机采样造成数据采样不均匀的缺点,本专利采用泊松圆盘采样方法对建立的金字塔进行分层均匀采样策略,具体步骤如下:
[0114]
1)根据三维格网范围大小,设定最大采样间距s,比如利用点云坐标最大范围与三维格网分割时设置的格网大小相除,本实施例点云最大范围为4150米,格网大小256,则最大采样距离s设置为16.21米,对不同层级level,自适应最小采样半径r=s/2level,即从下而上,采样半径逐渐变大;深度越深,分辨率越高,细节越丰富;
[0115]
2)以bin文件的范围中心为枢纽,以点到中心的距离从小到大进行排序;
[0116]
3)以经过排序后点云数组中第一个点作为采样点,当候选点pt到中心点center的距离与任何一个采样点到中心点的距离差值都大于指定采样半径r或候选点与所有采样点的距离差均大于采样半径r时,将候选点添加到采样点数组中;反之,将候选点作为非采样
点;对所有候选点重复以上步骤;
[0117]
4)将非采样点数组保存为level层的点云,输出采样后的节点数据到二进制文件result.bin中,并记录点个数、字节大小,以不断更新累加的输出点云字节总大小作为地址起始位进行数据的输出存储,完成多个bin文件的合并处理;
[0118]
5)将采样点更新为高一级即level
‑
1层的点云,并重复上述步骤1)、2)、3)、4),完成八叉树点云块的金字塔分层抽稀,如图6所示,最顶层level0点云最少,越往下点密度越大,细节越丰富,此方法不仅可获得均匀分布的点云数据,且不同层的点云数据并集存储,不存在交集(level0∩level1∩level2∩
…
=null),又避免了数据保存的冗余;
[0119]
步骤六:层次结构输出与点云实时分层调度渲染
[0120]
1)在bin文件的层级采样过程中,对建立的层次结构索引进行输出,以方便后续点云分层实时调用;
[0121]
2)对层次结构信息输出定义:节点命名+比特掩码+点个数+地址起始位+字节大小+节点坐标范围最小值+节点坐标范围最大值,定义公式如下:
[0122][0123]
3)根据视口范围,判断节点是否落入视野内,并设定点云密度,读取输出的result.bin文件,自适应加载对应金字塔层级的点云数据,以减少内存调用,实现近密远稀;
[0124]
4)点云数据存储了强度信息,可进行灰度渲染,但有时地物点云颜色对比不明显,本专利采用直方图均衡化方法,对读取的点云数据进行灰度值统计,获得每个灰度值的概率分布,最后进行动态范围的扩展,完成灰度直方图的对比度拉伸处理;
[0125]
5)点云灰度值只分布在0
‑
255区间,采取灰度分割法或灰度彩色变换法完成伪彩色渲染。
[0126]
本发明的内容不限于实施例所列举,本领域普通技术人员通过阅读本发明说明书而对本发明技术方案采取的任何等效的变换,均为本发明的权利要求所涵盖。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1