一种基于相似日理论和神经网络的光伏发电功率预测方法
1.本发明涉及一种光伏发电功率预测方法。特别是涉及一种基于相似日理论和神经网络的光伏发电功率预测方法。
背景技术:
2.随着化石燃料的枯竭和环境污染问题的日益严峻,传统的能源生产消耗模式已经难以适应目前经济的快速发展。同时,“碳达峰、碳中和”的提出,也促使大力发展新能源电力系统成为必然。
3.光能是清洁且可再生的新能源,但光伏发电具有随机性和波动性,给电力系统带来了巨大挑战,因此对光伏发电功率进行准确预测是十分必要的。
技术实现要素:
4.本发明所要解决的技术问题是,提供一种能够对光伏发电功率进行短期预测的基于相似日理论和神经网络的光伏发电功率预测方法。
5.本发明所采用的技术方案是:一种基于相似日理论和神经网络的光伏发电功率预测方法,包括如下步骤:
6.1)采用自适应噪声的完全集合经验模态分解方法对光伏发电功率原始数据序列引入正负白噪声,然后进行本征模态分解处理,在本征模态分解之后将高频分量和残余分量剔除掉,对保留的光伏发电功率原始数据序列的本征模态函数进行合成,得到处理后的光伏发电功率数据序列;
7.2)运用相似日理论、小数据集和综合相似度的概念,对处理后的光伏发电功率数据序列和与处理后的光伏发电功率数据序列对应的气象数据序列进行相似日的选取;
8.3)将属于相似日的处理后的光伏发电功率数据序列以及对应的气象数据序列输入bp神经网络,确定bp神经网络的拓扑结构及初始的参数,用纵横交叉算法优化bp神经网络的参数,再将预测日的气象因素数据序列输入优化后的bp神经网络即输出预测结果。
9.本发明的一种基于相似日理论和神经网络的光伏发电功率预测方法,具有如下优点:
10.1、对数据进行了详细的预处理,采用自适应噪声的完全集合经验模态分解方法对光伏发电功率原始数据序列引入正负白噪声,然后进行本征模态分解处理,在本征模态分解之后将高频分量和残余分量剔除掉,对保留的光伏发电功率原始数据序列的本征模态函数进行合成,得到处理后的光伏发电功率数据序列,解决了辐射、温度传感器的误差等造成的噪声问题;
11.2、利用互信息法确定了用于相似日选取和预测的气象因素。根据季节和天气状况,将历史数据集划分为9个数据集,提高了预测的精度和效率;
12.3、运用了综合相似度的概念确定相似日,弥补了传统方法缺少对数据距离考虑的不足;
13.4、采用纵横交叉算法对bp神经网络的权值和阈值进行优化,提高了预测精度,弥补了bp神经网络容易陷入局部最优解的缺陷。
附图说明
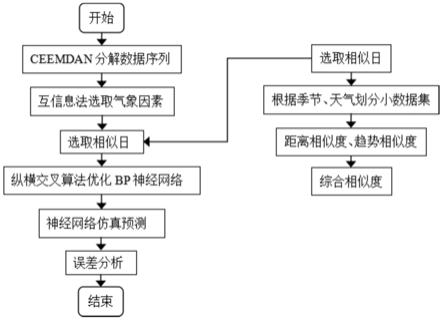
14.图1是本发明一种基于相似日理论和神经网络的光伏发电功率预测方法的流程图;
15.图2是本发明中的纵横交叉算法流程图;
16.图3是本发明中利用纵横交叉算法改进优化的bp神经网络流程图;
17.图4是本发明中选取春秋季晴天数据集,以优化前和优化后的结果进行实验对比;
18.图5是本发明中选取夏季雨天数据集,以优化前和优化后的结果进行实验对比;
19.图6是本发明中选取冬季阴天数据集,以优化前和优化后的结果进行实验对比。
具体实施方式
20.下面结合实施例和附图对本发明的一种基于相似日理论和神经网络的光伏发电功率预测方法做出详细说明。
21.本发明的一种基于相似日理论和神经网络的光伏发电功率预测方法,包括如下步骤:
22.1)采用自适应噪声的完全集合经验模态分解方法对光伏发电功率原始数据序列引入正负白噪声,然后进行本征模态分解处理,在本征模态分解之后将高频分量和残余分量剔除掉,对保留的光伏发电功率原始数据序列的本征模态函数进行合成,得到处理后的光伏发电功率数据序列,解决了辐射、温度传感器的误差等造成的噪声问题;包括:
23.(1.1)采用自适应噪声的完全集合经验模态分解方法对光伏发电功率原始数据序列引入正负白噪声公式如下:
24.m
τ+
(t)=g(t)+n
τ+
(t),τ∈{1,2,...,m}
25.m
τ-(t)=g(t)+n
τ-(t),τ∈{1,2,...,m}
26.式中:g(t)为光伏发电功率原始数据序列,和分别为第τ次引入的正、负白噪声;和分别为加入正、负白噪声后的光伏发电功率新的数据序列;m为加入的正、负白噪声的次数;
27.(1.2)分别对加入正、负白噪声后的光伏发电功率新的数据序列进行本征模态分解,得到加入正、负白噪声后分解获得的光伏发电功率新的数据序列分量组f
τ+
和f
τ-:
[0028][0029][0030]
i=f
+
+f-[0031]
式中:f
+
和f-分别为加入m次正、负白噪声后本征模态分解后获得的本征模态函数分量组的平均值;f
τ+
和f
τ-为加入第τ次正、负白噪声后分解获得的光伏发电功率新的数据序列分量组;m为加入的正、负白噪声的次数;i为光伏发电功率新的数据序列的本征模态函
数分量;
[0032]
(1.3)对于光伏发电功率新的数据序列的本征模态函数分量i进行合成:
[0033][0034]
式中:x为处理后的光伏发电功率数据序列;i
η
为第η个本征模态函数分量;a是本征模态函数分量的个数。
[0035]
2)运用相似日理论、小数据集和综合相似度的概念,对处理后的光伏发电功率数据序列和与处理后的光伏发电功率数据序列对应的气象数据序列进行相似日的选取;包括:
[0036]
(2.1)根据互信息理论,对处理后的光伏发电功率数据序列和全部对应的气象数据序列进行互信息值的求取,公式如下:
[0037][0038]
式中:z(x;y)是互信息值;p(x,y)是联合概率分布函数;p(x)是处理后的光伏发电功率数据序列的边缘概率分布函数;p(y)是对应的气象数据数列的边缘概率分布函数;x是处理后的光伏发电功率数据;x为处理后的光伏发电功率数据序列;y为对应的气象数据;y为对应的气象数据序列;
[0039]
(2.2)筛选出互信息值最大的3个气象因素数据序列:全辐射辐照度、温度、湿度,用于相似日的选取,通过减少气象因素数据序列的个数,可以降低输入变量的个数和模型复杂度,提高了运行速度;
[0040]
(2.3)根据对应的季节和天气状况类型,将处理后的光伏发电功率数据序列和对应的气象数据序列划分成9个数据集,选取与预测日的季节和天气状况类型相对应的数据集,通过细分数据集,数据搜集更加具有针对性,提高了数据搜索的效率和精度。
[0041]
划分数据集的标准如下:因为春秋季节的数据变化规律和阈值大致相似,所以将春秋两个季节合并,根据季节将划分成春秋、夏季和冬季三种类型。天气状况类型复杂,大致划分成晴天、多云和雨(雪)天三种类型。每种类型两两组合,将全部历史数据细分成九组,如下表1。
[0042]
表1 小数据集的划分
[0043][0044]
(2.4)在与预测日对应的数据集内,选取综合相似度最高的前k天作为相似日,综合相似度的求取方法如下:
[0045]
(2.4.1)求取和微增量相似度:
[0046][0047][0048]
式中:δx1(i,j)为处理后的光伏发电功率数据序列和第i个气象因素数据序列的第j个时刻的数值的和微增量;x
ij
为第i个气象因素数据序列的第j个时刻的数值;x
aj
为处理后的光伏发电功率数据序列的第j个时刻的数值;γ
′
(i,j)为和微增量相似度;
[0049]
(2.4.2)求取积微增量相似度
[0050][0051][0052]
式中:δx2(i,j)为处理后的光伏发电功率数据序列和第i个气象因素数据序列的第j个时刻的数值的积微增量;γ
″
(i,j)为积微增量相似度;
[0053]
(2.4.3)求取距离相似度
[0054]
γ1(i,j)=ε
·
γ'(i,j)+μγ”(i,j)
[0055]
式中:γ1(i,j)为距离相似度;ε和μ为比例系数;
[0056]
在求取距离相似度的过程中,应用了和微增量以及积微增量两种具体的表现形式,全面地表示了处理后的光伏发电数据序列与第i个气象因素数据序列的距离。
[0057]
(2.4.4)求取趋势相似度
[0058]
δx3(i,j)=|[x
a,j+1-x
aj
]-[x
i,j+1-x
ij
]|
[0059][0060]
式中:δx3(i,j)为处理后的光伏发电功率数据序列和第i个气象数据序列的第j个时刻的数值的趋势线段差;x
a,j+1
为处理后的光伏发电功率数据序列的第j+1个时刻的数值;x
i,j+1
为第i个气象因素数据序列的第j+1个时刻的数值;γ2(i,j)为趋势相似度;
[0061]
(2.4.5)求取综合相似度
[0062][0063]
式中:γ为综合相似度;α和β为比例系数;q为处理后的光伏发电功率数据序列数据点的个数。
[0064]
在求取综合相似度的过程中,引入了距离相似度的概念,弥补了传统方法缺少对数据距离考虑的不足。
[0065]
3)将属于相似日的处理后的光伏发电功率数据序列以及对应的气象数据序列输入bp神经网络,确定bp神经网络的拓扑结构及初始的参数,用纵横交叉算法优化bp神经网络的参数,再将预测日的气象因素数据序列输入优化后的bp神经网络即输出预测结果。
[0066]
bp神经网络的物理模型简单且预测效果良好,因此在光伏功率预测中应用广泛。同时,bp神经网络存在一些缺陷,如权值和阈值的选择对于训练结果的影响很大,非常容易
陷入局部极小值,从而不容易获得全局最优解。
[0067]
纵横交叉算法是一种全新的种群随机搜索方法,是在遗传算法的基础上发展而来的。与传统的遗传算法只用简单的横向交叉不同,该方法采用了一种包括横向交叉和纵向交叉的双搜索机制。在迭代过程中,每一代都会进行两个方向的交叉,每次交叉操作之后都会与父代进行竞争,只有比父代更优秀的粒子会被保留下来进入下次迭代,从而使得某些陷入局部最优的维有机会跳出迭代,取得全局最优解。其基本流程如图2。
[0068]
本发明采用纵横交叉算法优化bp神经网络,核心思想是用纵横交叉算法代替传统误差纠正方法,来优化神经网络的参数。图3给出了优化过程的流程图。
[0069]
其中,所述的用纵横交叉算法优化bp神经网络的参数如下:
[0070]
(3.1)对父代参数执行横向交叉算法,得到子代粒子,若子代粒子的适应度高于父代粒子的适应度,则用子代粒子代替父代粒子,否则保留父代粒子,横向交叉的计算公式如下:
[0071]
ms
hc
(e,d)=r1×
x(e,d)+(1-r1)
×
x(f,d)+c1×
(x(e,d)-x(f,d))
[0072]
ms
hc
(f,d)=r2×
x(e,d)+(1-r2)
×
x(f,d)+c2×
(x(e,d)-x(f,d))
[0073]
式中:x(e,d)为父代参数第e个个体的第d维数值;x(f,d)为父代参数第f个个体的第d维数值;ms
hc
(e,d)为子代参数第e个个体的第d维数值;ms
hc
(f,d)为子代参数第f个个体的第d维数值;r1和r2是[0,1]之间的随机数,c1和c2是[-1,1]之间的随机数;
[0074]
横向交叉机制中,前两项的系数较大,使得子代粒子较大概率在父代粒子和为对角顶点的超立方体内,同时为了尽量避免出现盲点的情况,又通过c参数以较小概率在父代范围外搜索新位置,这种交叉机制相比于遗传算法考虑更加全面,具有更强的全局搜索能力。
[0075]
(3.2)对父代参数执行纵向交叉算法,得到子代粒子,若子代粒子的适应度高于父代粒子的适应度,则用子代粒子代替父代粒子,否则保留父代粒子,纵向交叉的计算公式如下:
[0076]
ms
vc
(e,d1)=r
×
x(e,d1)+(1-r)
×
x(e,d2)
[0077]
式中:ms
hc
(e,d1)为子代参数第e个个体的第d1维数值;x(e,d1)为父代参数第e个个体的第d1维数值;x(e,d2)为父代参数第e个个体的第d2维数值;r是[0,1]之间的随机数;
[0078]
纵向交叉发生在同一个粒子的不同维之间,如果横向交叉陷入局部最优解,则纵向交叉机制能有效帮助陷入局部最优的维跳出。
[0079]
(3)迭代重复第(1)~(2)步,不断更新参数直到输出结果达到设定的迭代数;
[0080]
第(1)和(2)步所述的适应度的计算公式如下:
[0081][0082]
式中:fitness为适应度;yi为相似日的处理后的光伏发电功率数据的实际值;yi′
为相似日的处理后的光伏发电功率数据的预测值;n代表数据的维数。
[0083]
优化的目的是为了减小误差,适应度作为衡量粒子优越性的指标,采用能够衡量误差大小的均方误差公式来表示。
[0084]
下面给出实例
[0085]
选取我国某地光伏数据,包括每日7:00-18:00每隔30min测量一次的全辐射辐照
度(w/m2)、温度(℃)、湿度数据(%rh)以及光伏发电功率(kw)。然后选取该地光伏系统2020年2月4日、6月21日和9月1日三个典型日进行验证。
[0086]
有关参数的设置如下:在纵横交叉算法中,迭代代数设为200,纵向交叉概率设为0.7,bp神经网络设定为三层,含一个隐含层,训练次数设定为150次,最小误差为10e-5,学习速率为0.6。
[0087]
为了验证本发明的一种基于相似日理论和神经网络的光伏发电功率预测方法对传统的基于bp神经网络的光伏发电功率预测方法有优化效果,随机选取三个数据集,以优化前和优化后的预测方法进行对比,结果如图4、5、6所示。
[0088]
本发明选取了平均绝对百分比误差和希尔不等系数来评价预测结果的准确性,其中希尔不等系数源于经济学评价体系,更多的是分析数据间的方向变化趋势,类似于余弦相似度,从趋势上评估预测结果与实际数据的接近程度,计算公式如下:
[0089][0090][0091]
式中,mape代表平均绝对百分比误差;tic代表希尔不等系数;ai为预测日的处理后的光伏发电功率数据的实际值;bi为预测日的处理后的光伏发电功率数据的预测值;m代表数据的维数。
[0092]
通过计算,优化前后的误差对比结果如表2所示。
[0093]
表2 预测结果误差分析及比较
[0094][0095]
通过表2的评价指标可知,本发明的一种基于相似日理论和神经网络的光伏发电功率预测方法对传统的基于bp神经网络的光伏发电功率预测方法有优化效果,提高了预测结果的准确性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1