一种基于相对显著性检测的图像重定向方法
1.本发明属于计算机视觉、图像处理等技术领域,具体地说是一种基于相对显著性检测的图像重定向方法。
背景技术:
2.图像重定向是指对数字图像大小进行调整,以此来适配不同显示终端的长宽比。随着互联网和5g技术的迅速发展,各种数码产品不断涌现,无论是技术方面还是用户体验方面都在不断提升。除了设备性能不断优化外,显示屏幕也在逐渐改进以满足人们的不同需求,例如高清电视、平板电脑、扩展显示屏、手机、智能手表等,由于这些设备的应用范围不同,它们的显示屏幕长宽比也是不同的。市场上主流的分辨率有4:3、16:9、18.5:9等,面对不同大小的显示终端,如何让同一幅图像适配不同的显示屏成为了现阶段亟待解决的技术问题。
3.早期的图像重定向方法存在图像压缩或拉伸痕迹明显、内容显示不完全的问题。2007年avidan和shamir首次提出基于内容感知的图像重定向方法来提高重定向图像的视觉质量,该方法首先获取图像在视觉上的重要区域,再根据重要度图进行重定向操作,将由于长宽比改变所产生的形变尽可能发生在非重要区域,以此来保护图像主体内容。中国专利cn109447970a公开了一种基于能量转移和均匀缩放的图像重定向方法,获取的重要度图由图像的显著图、梯度图以及人脸图组成,这类方法大多利用图像的低层特征获取重要度图,当图像主体和背景较为复杂时,获取的重要度图不能准确反映出图像重要区域,在实际应用中表现不佳,容易造成图像变形。
4.深度学习方法利用神经网络强大的学习能力来学习图像的高级语义特征,在一定程度上弥补了低层特征的缺陷,这让深度学习在图像重定向领域中逐渐占据主导地位。2017年cho等人首次将卷积神经网络应用于图像重定向方向,在《ieee international conference on computer vision》发表论文“weakly-and self-supervised learning for content-aware deep image retargeting”,通过输入原图像和目标比例,获取图像的注意力图从而引导网络学习从原图像到目标网格的逐像素移位映射,得到目标图像,实现了一种端到端的内容感知图像重定向框架。之后,基于卷积神经网络获取图像重要度图来引导图像重定向的方法被大量提出,研究者常常借助显著目标检测方法识别场景中最吸引人的区域来获取视觉重要区域,cn111161340a公开了一种基于深度特征提取的图像重定向方法,利用前景分割的全卷积网络提取图像重要度图,由于该方法对于目标面积大或数量多的图像,重要度图的检测结果准确度不高,因而重定向质量不高。现有的显著目标检测方法大多针对二元分割问题进行建模,不同的目标对象具有相同的显著值,这适用于单目标的场景图像,然而,对于复杂场景图像,当图像中包含多个显著目标时,人类注意力会优先聚焦于最显著的目标,其次关注到第二显著目标,以此类推,因为人类视觉系统会自动判断一个目标是否比另一个目标更显著,形成相对显著性。因此,面对复杂的多目标场景,使用二元分割显著目标检测方法获取的视觉重要度图无法区分不同目标的重要程度,甚至出现
漏检误检的情况,造成重定向图像中部分重要内容无法得到保护。
技术实现要素:
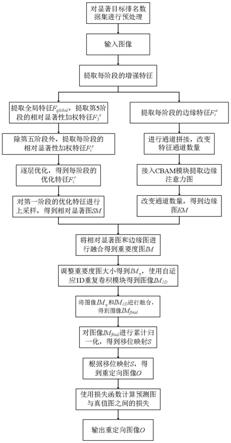
5.针对现有技术的不足,本发明所要解决的技术问题是,提出一种基于相对显著性检测的图像重定向方法,该方法由三部分组成,包括相对显著图提取、图像边缘检测以及基于重要度图的重定向操作。首先通过多特征聚合的相对显著性分层监督模块以及显著等级引导的优化模块提取相对显著图,相对显著性分层监督模块以监督的方式对每阶段的特征进行加权,学习相对显著性特征,而显著等级引导的优化模块将预测问题转化为等级分类问题,先利用卷积模块生成每类显著等级的类别概率,再经过卷积层和激活函数生成每一个像素的注意力掩码,得到优化特征;接着,为了得到更好的重定向结果,利用边缘检测模块提取边缘图,并与相对显著图进行线性融合得到重要度图;最后学习输入图像到目标图像的移位映射,在输入图像上通过移位图实现图像重定向。本发明能够有效保护输入图像的主体区域以及整体结构,克服现有技术重定向后图像存在变形、扭曲的问题,获得更好的视觉效果。
6.本发明解决该技术问题所采用的技术方案是:
7.一种基于相对显著性检测的图像重定向方法,其特征在于,具体步骤如下:
8.第一步,对显著目标排名数据集进行预处理,得到原始图像;
9.第二步,利用预训练的resnet50网络对原始图像进行特征提取,得到每阶段的增强特征;
10.第2.1步,将原始图像输入到预训练的resnet50网络中,提取主干特征ci,i∈[1,5],预训练的resnet50网络的每个阶段都会提取一个主干特征,i表示预训练的resnet50网络的第i阶段;
[0011]
第2.2步,使用卷积核大小为1
×
1的卷积层改变主干特征ci的通道数量,得到特征ci′
;
[0012]
第2.3步,将特征ci′
经过两个卷积核大小为3
×
3的卷积层、批量归一化和relu激活函数后,再与特征ci′
进行元素级相加,得到第i阶段的增强特征fi,每阶段都会生成一个增强特征;
[0013]
第三步,获取原始图像的相对显著图;
[0014]
第3.1步,将第5阶段的增强特征f5利用全局上下文模块进行特征提取,得到全局特征f
global
;
[0015]
第3.2步,利用相对显著性分层监督模块对第5阶段的增强特征f5进行特征提取,得到第5阶段的相对显著性加权特征f
5s
;
[0016]
第3.3步,除第5阶段外,其余各个阶段的增强特征fi,i∈[1,4]分别利用多特征聚合模块提取每个阶段的聚合特征f
iagg
,i∈[1,4];
[0017]
第3.4步,将各阶段的聚合特征利用相对显著性分层监督模块,提取各阶段的相对显著性分层表示rssri,i∈[1,4]和一维相对显著图rsi,i∈[1,4];将一维相对显著图与对应的聚合特征进行元素级相乘相加,得到各阶段的相对显著性加权特征f
is
,i∈[1,4];
[0018]
第3.5步,使用显著等级引导的优化模块对各阶段的相对显著性加权特征进行逐层优化,得到每阶段的优化特征f
ir
,i∈[1,5];
[0019]
第3.6步,对第1阶段的优化特征f
1r
进行上采样,得到相对显著图sm;
[0020]
第四步,使用边缘检测模块获取边缘图em;
[0021]
第五步,图像重定向;
[0022]
第5.1步,将相对显著图sm和边缘图em按照式(19)进行融合,得到重要度图im;
[0023]
im=(1-α)sm+αem (19)
[0024]
其中,α∈[0,1]是网络参数,由网络自己学习得到,用于平衡相对显著图sm和边缘图em对重要度图im的贡献;
[0025]
第5.2步,将重要度图im的尺寸调整到目标大小,得到图像im
η
,使用自适应1d(一维)重复卷积模块对图像im
η
进行处理,得到图像im
1d
;
[0026]
第5.3步,将图像im
η
和图像im
1d
按照公式(24)进行融合,得到图像im
final
;然后按照公式(25)对图像im
final
进行累计归一化,得到输入图像到目标图像的移位映射s;
[0027]
im
final
=λim
η
+im
1d (24)
[0028][0029]
其中,λ是图像im
η
和im
1d
之间的平衡参数,本实施例中λ设置为1;sum(
·
)表示在图像宽度维度上进行求和,cumsum(
·
)表示在图像宽度维度上进行累计求和;w、w
′
分别为尺寸调整前、后的图像宽度,h为图像高度;
[0030]
第5.4步,根据移位映射s,利用式(26)对输入图像i执行重定向操作,得到重定向图像o,输出重定向图像o;
[0031]
o=warp(i,s) (26)
[0032]
其中,warp(
·
,s)表示利用移位映射s对图像进行重定向操作;
[0033]
至此,完成了基于相对显著性检测的图像重定向。
[0034]
与现有技术相比,本发明的有益效果是:
[0035]
(1)本发明提出了一种基于相对显著性检测的图像重定向方法,具体是利用多特征聚合的相对显著性分层监督模块以及显著等级引导的优化模块检测图像显著区域,得到相对显著图,不同的显著目标具有不同得重要程度,用来模拟人类视觉注意力的分配情况,其中,多特征聚合的相对显著性分层监督模块将每阶段的低层、高层和全局特征进行融合得到互补的融合特征,再以监督的方式对特征进行加权,学习相对显著性特征,显著等级引导的优化模块将预测问题转化为等级分类问题,利用卷积模块生成每类显著等级的类别概率,再经过卷积层和激活函数生成每一个像素的注意力掩码,得到优化特征;另外,为保证图像整体结构不发生扭曲,提取了边缘图,最后将相对显著图与边缘图融合作为引导图像重定向的重要度图,采用自适应1d重复卷积模块改进原有的重定向方法学习原图像到目标图像的逐像素移位图进行图像重定向。
[0036]
(2)cho等人的论文“weakly-and self-supervised learning for content-aware deep image retargeting”提出了一种端到端的内容感知图像重定向方法,通过输入原图像和目标比例,获取图像的注意力图来引导网络学习从原图像到目标网格的逐像素移位映射,得到重定向图像,但是由于该方法的1d重复卷积模块人为定义卷积核的大小,因此不能输入任意大小的图像。本发明对该模块进行了改进,设计的自适应1d重复卷积模块既能满足属于同一列的像素拥有相同的移位值,保证重定向后的图像不发生扭曲变形,也
能输入任意大小的图像。
[0037]
(3)cn109447970a公开了一种基于能量转移和均匀缩放的图像重定向方法,该方法的步骤是对输入图像进行预处理、提取rgb图像的重要度图,由图像的显著图、梯度图以及人脸图组成、根据累积能量矩阵确定最佳裁剪线、重要度图更新、移除最佳裁剪线、评价裁剪后的图像变形程度等,该方法能保证图像的视觉主体不发生严重的扭曲变形,但是,获取的重要度图是由手工特征组成,缺乏了对图像高级语义信息的理解,当图像主体和背景较为复杂时,该方法的处理效果并不友好,并且采用线裁剪的算法需要的时间相对较长。本发明与cn109447970a相比,考虑了图像的语义信息并利用多特征聚合的相对显著性分层监督模块以及显著等级引导的优化模块得到图像相对显著图,针对多目标的复杂图像,本发明为不同的显著目标分配不同的显著值,能够提供较准确的视觉重要度图,并且时间复杂度不高。
[0038]
(4)cn111161340a公开了一种基于深度特征提取的图像重定向方法,该方法的步骤是训练用于前景分割的全卷积神经网络、提取图像不同尺度的特征图、线性组合所述特征图得到重要度图、网格变形,该方法考虑到图像的语义信息,采用前景分割的全卷积神经网络将图像中的显著前景与背景进行分割,获取重要度图,但是该方法依赖于前景分割网络,对于重要目标太大或者分散在背景的多目标图像,往往不能完全把显著区域分割出来。本发明与cn111161340a相比,将相对显著图提取模块获取的相对显著图与边缘提取模块获取的边缘图结合得到重要度图来引导图像变形,既保护图像的显著目标,也能保证图像整体结构不发生扭曲。
[0039]
(5)cn111915489a公开了一种基于监督深度网络学习的图像重定向方法,该方法构建了一个新的重定向任务的数据集,包括:选择并确定原始输入图像、执行重定向操作、为重定向后的图像评估分数、选择评分最高的对应图像作为原图像的真值图、形成数据集,并设计了一个基于u-net的生成对抗网络,分批次地使用新构建的数据集对网络进行训练,但是该方法是从原始图像上重构目标图像,图像的亮度和颜色会有轻微的不同。本发明与cn111915489a相比,网络学习的是原图像到目标图像的逐像素移位图,再使用四相邻像素再原图像上执行线性插值操作得到重定向图像,因此,图像色彩和颜色会保持原样。
附图说明
[0040]
图1是本发明的整体流程图;
[0041]
图2是本发明的多特征聚合模块与相对显著性分层监督模块的流程图;
[0042]
图3是本发明的显著等级引导的优化模块的流程图;
[0043]
图4是本发明的自适应1d重复卷积模块的流程图;
[0044]
图5是本发明实施例重定向结果示例图。
具体实施方式
[0045]
下面结合具体实施例和附图对本发明的技术方案进行详细描述,但并不以此限定本技术的保护范围。
[0046]
本发明为一种基于相对显著性检测的图像重定向方法(简称方法,参见图1-4),具体步骤如下:
[0047]
第一步,对显著目标排名数据集assr进行预处理,得到原始图像、真值图的相对显著性分层表示标签、显著等级标签以及边缘真值图;
[0048]
第1.1步,给定输入图像i,使用双线性插值方法按比例将图像大小调整为h
×
w,得到原始图像;其中h表示图像高度,w表示图像宽度,本实施例中h=240,w=320;
[0049]
第1.2步,对真值图g进行相对显著性分层,即依次删除真值图中属于显著等级最低的目标,每次删除都得到一个真值图的分层,直到真值图g中只剩显著等级最高的目标,生成真值图g的相对显著性分层表示标签gs;每张真值图g的相对显著性分层表示标签gs由n个真值图g的分层集合构成,即gs={g1,g2,
…
,gn,
…
,gn},n表示数据集划分的显著等级数量,本实施例中n=5;g1显示所有的显著等级目标,gn显示显著等级最高的目标,每个gn显示n-n+1个显著等级目标;
[0050]
第1.3步,按照数据集给定的像素值将所有图像划分为六类,即将像素值为0的图像划分为类0,像素值为255的图像划分为类1,像素值为229的图像划分为类2,像素值为204的图像划分为类3,像素值为178的图像划分为类4,像素值为153的图像划分为类5,得到真值图的显著等级标签gr,r=0,1,
…
,5表示类别;
[0051]
第1.4步,通过边缘检测方法生成图像的边缘真值图ge,边缘检测方法参见文献“dynamic feature integrationfor simultaneous detectionofsalient object,edge,and skeleton”;
[0052]
第二步,利用预训练的resnet50网络对原始图像进行特征提取,得到每阶段的增强特征;
[0053]
第2.1步,将第1.1步得到的原始图像输入到预训练的resnet50网络中,提取主干特征ci,i∈[1,5],预训练的resnet50网络的每个阶段都会提取一个主干特征,i表示预训练的resnet50网络的第i阶段;
[0054]
第2.2步,通过式(1)对第i阶段提取的主干特征ci使用卷积核大小为1
×
1的卷积层改变通道数量,使每层通道维度实现统一,得到特征ci′
;
[0055]ci
′
=conv1×1(ci) (1)
[0056]
式(1)中,conv1×1(
·
)表示卷积核大小为1
×
1的卷积层;
[0057]
第2.3步,将特征ci′
经过两个卷积核大小为3
×
3的卷积层、批量归一化和relu激活函数后,再与特征ci′
进行元素级相加,得到第i阶段的增强特征fi,每阶段都会生成一个增强特征;fi的表达式为:
[0058][0059]
式(2)中,conv3×3(
·
)表示卷积核大小为3
×
3的卷积层,b表示批量归一化,r表示relu激活函数,表示元素级相加操作;
[0060]
第三步,获取原始图像的相对显著图;
[0061]
第3.1步,将第5阶段的增强特征f5利用全局上下文模块进行特征提取,得到全局特征f
global
;全局上下文模块的具体操作如式(3)-(5)所示;
[0062]
branchk=bconv1×1(f5),k=1 (3)
[0063][0064]
[0065]
其中,branchk,k∈[1,4]表示四个平行的卷积操作分支,表示卷积核大小为3
×
3、空洞率为2k-1的卷积层,convu×v(
·
)表示卷积核大小为u
×
v的卷积层;concat(
·
)表示通道拼接操作,relu(
·
)表示激活函数;
[0066]
第3.2步,利用式(6)的相对显著性分层监督模块对第5阶段的增强特征f5进行特征提取,得到第5阶段的相对显著性加权特征
[0067][0068]
式(6)中,rsss(
·
)为相对显著性分层监督模块;相对显著性分层监督模块的具体操作如式(7)-(9)所示:即第5阶段的增强特征f5先通过卷积核大小为3
×
3的卷积层,得到第5阶段的相对显著性分层表示rssr5,该相对显著性分层表示学习不同层级的显著目标;第5阶段的相对显著性分层表示rssr5经过卷积核大小为3
×
3的卷积层、批量归一化、relu激活函数、卷积核大小为1
×
1的卷积层和relu激活函数生成一维相对显著图rs5,在一维相对显著图rs5中不同的显著目标具有不同的权重值;最后将一维相对显著图rs5与第5阶段的增强特征f5通过元素级相乘相加的方式进行加权,得到第5阶段的相对显著性加权特征f
5s
;
[0069]
rssr5=conv3×3(f5)
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0070]
rs5=rconv1×1(rbconv3×3(rssr5))
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0071][0072]
式(9)中,表示元素级相乘操作;
[0073]
第3.3步,除第5阶段外,其余各个阶段的增强特征fi,i∈[1,4]分别利用多特征聚合模块提取每个阶段的聚合特征f
iagg
,i∈[1,4];多特征聚合模块的具体操作如式(10)-(12)所示:多特征聚合模块的输入包括增强特征fi、前一阶段的相对显著性加权特征以及全局特征f
global
,将增强特征fi作为低层特征,前一阶段的相对显著性加权特征作为高层特征;首先将高层特征和全局特征f
global
分别经过两个卷积核大小为3
×
3的卷积层、批量归一化、relu激活函数和上采样操作后,再分别与经过两个卷积核大小为3
×
3的卷积层、批量归一化和relu激活函数后的低层特征进行元素级相乘,得到高层与低层结合的融合特征m
ilh
,i∈[1,4]以及全局与低层结合的融合特征m
ilg
,i∈[1,4];然后将两个融合特征进行级联,再经过卷积核大小为3
×
3的卷积层、批量归一化和relu激活函数生成聚合特征f
iagg
,i∈[1,4];
[0074][0075][0076][0077]
其中,up(
·
)表示上采样操作;
[0078]
第3.4步,将上述第3.3步提取的各阶段的聚合特征利用相对显著性分层监督模块,提取各阶段的相对显著性分层表示rssri,i∈[1,4]和一维相对显著图rsi,i∈[1,4];将一维相对显著图与对应的聚合特征进行元素级相乘相加,得到各阶段的相对显著性加权特征f
is
,i∈[1,4],具体操作如式(13)所示:
[0079]fis
=rsss(f
iagg
),i∈[1,4] (13)
[0080]
第3.5步,使用显著等级引导的优化模块对每阶段的相对显著性加权特征进行逐层优化,得到每阶段的优化特征f
ir
,i∈[1,5];显著等级引导的优化模块的具体操作如式(14)、(15)所示,除第5阶段外,该模块的输入特征为每个阶段的相对显著性加权特征f
is
,i∈[1,4]以及前一阶段的优化特征i∈[1,4];首先将两个输入特征进行级联操作,然后利用卷积核大小为1
×
1的卷积层改变通道数量,将改变通道数量后的特征与相对显著性加权特征和前一阶段的优化特征再次进行级联操作,利用卷积核大小为1
×
1的卷积层改变通道数量,得到各阶段互补的融合特征f
ifuse
,i∈[1,4];由于预训练的resnet50网络值包含5个阶段,因此第5阶段互补的融合特征为第5阶段的相对显著性加权特征,即然后根据式(15)对各阶段互补的融合特征f
ifuse
进行显著等级重加权操作,即各阶段互补的融合特征f
ifuse
经过卷积核大小为3
×
3的卷积层、批量归一化、relu激活函数和卷积核大小为3
×
3的卷积层,生成每类显著等级的类别概率,得到预测的显著等级ri;再接入卷积核大小为1
×
1的卷积层和sigmoid激活函数生成每个像素的注意力掩码,再与各自阶段互补的融合特征f
ifuse
进行元素级相乘相加,得到每阶段的优化特征f
ir
,i∈[1,5];
[0081][0082][0083]
式(15)中,sigmoid(
·
)表示激活函数;
[0084]
第3.6步,利用式(16)对第1阶段的优化特征f
1r
进行上采样,得到与原始图像大小一致的相对显著图sm;
[0085]
sm=rbconv1×1(deconv3×3(rbconv1×1(deconv3×3(rbconv1×1(f
1r
))))) (16)
[0086]
式(16)中,deconv3×3(
·
)为卷积核大小为3
×
3的反卷积操作;
[0087]
第四步,使用边缘检测模块获取边缘图;边缘检测模块包含提取边缘特征和边缘注意力图;
[0088]
第4.1步,将上述第2.3步生成的每阶段的增强特征经过卷积核大小为1
×
1的卷积层、relu激活函数、卷积核大小为3
×
3的卷积层、relu激活函数和上采样操作,提取每阶段的边缘特征,具体操作如式(17)所示;
[0089]fie
=up(rconv3×3(rconv1×1(fi))),i∈[1,5] (17)
[0090]
其中,f
ie
表示第i阶段的边缘特征;
[0091]
第4.2步,将第4.1步生成的所有阶段的边缘特征进行通道拼接,再使用卷积核大小为1
×
1的卷积层改变特征通道数量,然后接入到cbam(convolutional blockattention module)模块中,提取边缘注意力图,最后使用卷积核大小为1
×
1的卷积层将通道数变为1,得到边缘图em,具体操作如式(18)所示:
[0092]
em=conv1×1(cbam(conv1×1(concat(f
ie
)))),i∈[1,5] (18)
[0093]
式(18)中,cbam(
·
)为本技术领域公知的注意力提取模块;
[0094]
第五步,图像重定向;
[0095]
第5.1步,将上述第3.6步获取的相对显著图sm和上述第4.2步获取的边缘图em按照式(19)进行融合,得到重要度图im,其中α∈[0,1]是网络参数,由网络自己学习得到,用于平衡相对显著图sm和边缘图em对重要度图im的贡献;
[0096]
im=(1-α)sm+αem (19)
[0097]
第5.2步,将重要度图im的尺寸调整到目标大小,得到图像im
η
;如式(20),调整图像宽度时,当重定向比例为η∈[0,1],则图像im
η
的目标大小为h
×w′
,w
′
=w
×
η,w
′
为调整后的宽度;调整图像高度时,将重要度图im旋转90度,与调整图像宽度同理得到图像im
η
;使用自适应1d(一维)重复卷积模块对图像im
η
进行处理,使得满足图像中同一列的像素具有相同的移位值,该自适应1d重复卷积模块首先将图像im
η
在高度维度上进行分列操作,得到w
′
个h维的列向量vw′
,w
′
∈[1,w
′
],并对每个列向量进行卷积核大小为1
×
1卷积操作,得到卷积后的列向量再将卷积后的结果与原始列向量进行点乘,对点乘后的向量进行级联操作得到一维向量,最后将得到的一维向量重复h次,得到同一列像素拥有相同移位值的图像im
1d
,此时图像大小依然是h
×w′
,具体操作如式(21)-(23)所示:
[0098]
im
η
=resize(im,(h,w
′
)),w
′
=w
×
η,η∈[0,1]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(20)
[0099]vw
′
=chunk(im
η
,h),w
′
∈[1,w
′
]
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(21)
[0100][0101][0102]
其中,resize(
·
)表示图像大小调整操作,chunk(
·
,h)表示在高度维度上进行分列操作,mul(
·
)表示点乘操作,dup(
·
,h)表示重复一维向量h次;
[0103]
第5.3步,将上述第5.2步得到的图像im
η
和im
1d
按照公式(24)进行融合,得到图像im
final
;然后按照公式(25)对图像im
final
进行累计归一化,得到输入图像到目标图像的移位映射s;
[0104]
im
final
=λim
η
+im
1d (24)
[0105][0106]
其中,λ是图像im
η
和im
1d
之间的平衡参数,本实施例中λ设置为1;sum(
·
)表示在图像宽度维度上进行求和,cumsum(
·
)表示在图像宽度维度上进行累计求和;
[0107]
第5.4步,根据第5.3步得到的移位映射s,利用式(26)对输入图像i执行重定向操作,得到重定向图像o,输出重定向图像o;
[0108]
o=warp(i,s) (26)
[0109]
其中,warp(
·
,s)表示利用移位映射s对图像进行重定向操作;
[0110]
第六步,通过损失函数计算上述过程中输出的预测图与真值图之间的损失;
[0111]
第6.1步,计算相对显著性提取模块中预测图与真值图之间的损失,包括:
[0112]
1)均方差损失分别表示相对显著性分层监督模块对各阶段的增强特征进行特征提取,生成的相对显著性分层表示以及一维相对显著图与对应真值图之间的损失,如式(27)、(28)所示;
[0113][0114][0115]
其中,rssri、rsi分别表示第i层的相对显著性分层表示和一维相对显著图,g表示
真值图,xy表示图像像素点位置;
[0116]
2)多分类交叉熵损失表示显著等级引导的优化模块在第i阶段预测的显著等级ri与真值图的显著等级标签gr之间的损失,如下公式(29)所示:
[0117][0118]
3)均方误差l
final
表相对显著图sm与真值图g之间的损失,如下公式(30)所示:
[0119][0120]
4)总体显著损失l
sal
如下公式(31)所示:
[0121][0122]
其中,δ1、δ2、δ3、δ4分别表示上述各个损失的平衡参数,本实施例中δ1、δ2、δ3设置为1,δ4设置为10;
[0123]
第6.2步,二元交叉熵损失l
edge
表示边缘图em与边缘真值图ge之间的损失,如下公式(32):
[0124][0125]
第6.3步,结构损失l
struc
表示利用移位映射来推断输入图像i和重定向图像o之间的对应关系,如下公式(33)所示:
[0126][0127]
其中:fj(
·
)表示经过vgg16模型第一组卷积的前两层卷积层输出的结果,vgg16模型为本技术领域公知的网络结构;
[0128]
第6.4步,最终损失函数如下公式(34)所示:
[0129]
l=ω1l
sal
+ω2l
edge
+ω3l
struc (34)
[0130]
其中:ω1、ω2、ω3分别表示总体显著损失、二元交叉熵损失和结构损失的平衡系数,本实施例中ω1设置为0.1,ω2、ω3设置为1。
[0131]
至此,完成了基于相对显著性检测的图像重定向。
[0132]
图5显示了利用本发明的基于相对显著性检测的图像重定向方法生成的重定向结果图,图中第一列为测试的原始图像(image),第二列为相对显著性检测模块生成的相对显著图(sm),第三列为生成的边缘图(em),第四列为改变图像宽度为原始宽度的0.75(重定向比例η=0.75)时获取的重定向结果,第五列为改变图像宽度为原始宽度的0.5(重定向比例η=0.5)时获取的重定向结果。
[0133]
本发明针对多目标场景图像的重定向问题,设计的相对显著性分层监督模块以及显著等级引导的优化模块,为不同的显著目标分配不同的显著值来模拟人类视觉注意力的优先级分配情况,将相对显著图与边缘图进行融合,以引导图像变形,能够使图像的整体结构不发生扭曲,有助于生成效果好的重定向图像。
[0134]
本发明未述及之处适用于现有技术。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1