视频召回方法与流程
1.本发明涉及自然语言处理技术领域,具体来说涉及一种视频召回方法。
背景技术:
2.随着带有智能语音的电视产品融入人们的生活,使用语音点播影视视频的用户也越来越多。但因为不同用户方言、表述能力等不同、语音识别有错误率等问题,通常不能识别出标准的影片名字,对视频检索造成了很大困难。目前根据用户表述和语音识别结果的发音基本一致的特点,利用其拼音特征可以识别出发音相似的影片名字,但其只考虑了发音的相似性,没有考虑到用户的表达习惯例如表述简称,如“你是我的城池营垒”只说“城池营垒”,以及表述异位,如“好声音2021”表述为“2021好声音”,造成视频无法正确检索。
技术实现要素:
3.本发明旨在解决现有视频检索存在不准确的问题,提出一种视频召回方法。
4.本发明解决上述技术问题所采用的技术方案是:视频召回方法,包括以下步骤:
5.步骤1、将影视数据库中的所有片名文本进行读法预处理后,提取拼音特征,所述拼音特征包括全值特征和分字特征,所述全值特征为片名文本对应的不带声调的全值拼音,所述分字特征包括片名文本对应的带声调的全值拼音、不带声调排序后的全值拼音以及不带声调的相邻字拼音列表;
6.步骤2、根据提取的拼音特征分别创建拼音全值召回数据库和分字拼音召回数据库,所述拼音全值召回数据库的key为片名文本的全值特征,value为全值特征相同的片名文本列表,所述分字拼音召回数据库的key为片名文本的不带声调的相邻字拼音列表的元素,value为有该元素的片名特征列表,所述片名特征包括:片名文本及其对应的带声调的全值拼音和不带声调排序后的全值拼音;
7.步骤3、当接收到用户输入的语音文本后,根据预设识别算法从语音文本中提取可能为片名文本的待纠正文本,并对待纠正文本进行与步骤1相同的读法预处理和拼音特征提取,得到待纠正文本所有读法对应的拼音特征;
8.步骤4、根据待纠正文本各读法对应的拼音特征并分别基于拼音全值召回数据库和分字拼音召回数据库进行全值特征召回和分字特征召回,得到全值特征召回结果和分字特征召回结果;
9.步骤5、若全值特征召回结果中有片名,则将该片名作为视频召回结果,否则,确定分字特征召回结果中各片名的相似度,并根据所述相似度确定视频召回结果。
10.进一步地,所述确定分字特征召回结果中各片名的相似度之前还包括:
11.获取分字特征召回结果中各片名文本对应的不带声调的相邻字拼音列表与用户输入的语音文本对应的不带声调的相邻字拼音列表之间的共有子串数量,若所述共有子串数量小于第一预设阈值,则抛弃对应的片名,所述第一预设阈值根据待纠正文本的长度确定。
12.进一步地,所述确定分字特征召回结果中各片名的相似度之前还包括:
13.获取分字特征召回结果中各片名文本与待纠正文本的文本长度差,若所述文本长度差大于第二预设阈值,则抛弃对应的片名。
14.进一步地,所述确定分字特征召回结果中各片名的相似度之前还包括:
15.获取用户输入的语音文本对应的带声调的全值拼音,根据所述语音文本对应的带声调的全值拼音和分字特征召回结果中的带声调的全值拼音计算分字特征召回结果中各片名文本对应的第一拼音编辑距离评分,若所述第一拼音编辑距离评分小于第三预设阈值,则抛弃对应的片名,所述第一拼音编辑距离评分的计算公式如下:
16.l
pn
=lev(n
pn
,t
pn
);
17.式中,l
pn
为第一拼音编辑距离评分,lev()为编辑距离算法,n
pn
为分字特征召回结果中的带声调的全值拼音,t
pn
为语音文本对应的带声调的全值拼音。
18.进一步地,确定分字特征召回结果中各片名的相似度的方法还包括:
19.计算分字特征召回结果中各片名文本对应的排序后的第二拼音编辑距离评分;
20.获取用户输入的语音文本对应的不带声调的相邻字拼音列表长度、分字特征召回结果中各片名文本对应的共有子串数量以及分字特征召回结果中共有子串数量的最大值;
21.根据第一拼音编辑距离评分、第二拼音编辑距离评分、语音文本对应的不带声调的相邻字拼音列表长度、分字特征召回结果中各片名文本对应的共有子串数量以及分字特征召回结果中共有子串数量的最大值计算分字特征召回结果中各片名文本对应的共有子串系数;
22.根据第一拼音编辑距离评分、第二拼音编辑距离评分和共有子串系数计算分字特征召回结果中各片名的相似度。
23.进一步地,所述第二拼音编辑距离评分的计算方法如下:
24.若分字特征召回结果中片名文本对应的第一拼音编辑距离评分大于第四预设阈值,则将对应片名文本对应的第一拼音编辑距离评分作为该片名文本对应的第二拼音编辑距离评分;
25.若分字特征召回结果中片名文本对应的第一拼音编辑距离评分小于或等于第四预设阈值,则获取用户输入的语音文本对应的不带声调排序后的全值拼音,根据所述语音文本对应的不带声调排序后的全值拼音和分字特征召回结果中的不带声调排序后的全值拼音计算分字特征召回结果中各片名文本对应的第二拼音编辑距离评分;
26.所述第二拼音编辑距离评分计算公式如下:
[0027][0028]
式中,l
pr
为第二拼音编辑距离评分,n
pr
为分字特征召回结果中的不带声调排序后的全值拼音,t
pr
为语音文本对应的不带声调排序后的全值拼音,r为第四预设阈值。
[0029]
进一步地,所述共有子串系数的计算公式如下:
[0030][0031]
式中:sr为共有子串系数,l
pn
为第一拼音编辑距离评分,l
pr
为第二拼音编辑距离评分,t
pl
为语音文本对应的不带声调的相邻字拼音列表长度,sn为分字特征召回结果中片名文本对应的共有子串数量,s
n_max
为分字特征召回结果中共有子串数量的最大值。
[0032]
进一步地,所述片名对应的相似度similarity计算公式如下:
[0033][0034]
进一步地,步骤5中,若全值特征召回结果中的片名不止一个,则获取全值特征召回结果中各片名文本对应的带声调的全值拼音和用户输入的语音文本对应的带声调的全值拼音,并根据所述全值特征召回结果中各片名文本对应的带声调的全值拼音和用户输入的语音文本对应的带声调的全值拼音计算全值特征召回结果中各片名文本对应的第三拼音编辑距离评分,将第三拼音编辑距离评分最大值对应的片名作为视频召回结果。
[0035]
进一步地,步骤5中,根据所述相似度确定视频召回结果的方法包括:
[0036]
确定出相似度最大值,若所述相似度最大值大于第五预设阈值,则将相似度最大值对应的片名作为视频召回结果,否则,视频召回结果为空。
[0037]
本发明的有益效果是:本发明所述的视频召回方法,通过多个维度的分字拼音特征进行相似片名的视频召回,提高了用户检索视频时采用简称或异位表述时的识别正确率,提高了用户语音使用的智能交互体验。
附图说明
[0038]
图1为本发明实施例所述的视频召回方法的一种流程示意图;
[0039]
图2为本发明实施例所述的视频召回方法的另一种流程示意图。
[0040]
图3为本发明实施例所述的视频召回的结构示意图;
具体实施方式
[0041]
下面将结合附图对本发明的实施方式进行详细描述。
[0042]
本发明所述的视频召回方法,包括以下步骤:步骤1、将影视数据库中的所有片名文本进行读法预处理后,提取拼音特征,所述拼音特征包括全值特征和分字特征,所述全值特征为片名文本对应的不带声调的全值拼音,所述分字特征包括片名文本对应的带声调的全值拼音、不带声调排序后的全值拼音以及不带声调的相邻字拼音列表;步骤2、根据提取的拼音特征分别创建拼音全值召回数据库和分字拼音召回数据库,所述拼音全值召回数据库的key为片名文本的全值特征,value为全值特征相同的片名文本列表,所述分字拼音召回数据库的key为片名文本的不带声调的相邻字拼音列表的元素,value为有该元素的片名特征列表,所述片名特征包括:片名文本及其对应的带声调的全值拼音和不带声调排序后
的全值拼音;步骤3、当接收到用户输入的语音文本后,根据预设识别算法从语音文本中提取可能为片名文本的待纠正文本,并对待纠正文本进行与步骤1相同的读法预处理和拼音特征提取,得到待纠正文本所有读法对应的拼音特征;步骤4、根据待纠正文本各读法对应的拼音特征并分别基于拼音全值召回数据库和分字拼音召回数据库进行全值特征召回和分字特征召回,得到全值特征召回结果和分字特征召回结果;步骤5、若全值特征召回结果中有片名,则将该片名作为视频召回结果,否则,确定分字特征召回结果中各片名的相似度,并根据所述相似度确定视频召回结果。
[0043]
具体而言,本发明首先根据影视数据库中的所有片名分别建立拼音全值召回数据库和分字拼音召回数据库,其中,拼音全值召回数据库通过片名对应的拼音特征中的全值特征建立,分字拼音召回数据库通过片名对应的拼音特征中的分字特征建立,其中,全值特征为片名文本对应的不带声调的全值拼音,字与字之间用
“‑”
隔开,全值特征用于召回读音完全一致的片名。分字特征包括三个部分:(1)带声调的全值拼音;声调用数字表示,用于计算原始文本与目标片名的相似度;(2)不带声调排序后的全值拼音;用于计算排序后的原始文本与排序后的目标片名的相似度,为表述异位的特征;(3)不带声调的相邻字拼音列表;当文本字数为1时,为单字拼音;字数为2时,为单字拼音+相邻两字拼音;字数为3时,为单字拼音+相邻两字拼音+相邻三字拼音;字数为4时,为前两字单字拼音+相邻两字拼音+相邻三字拼音;字数大于4时,为相邻两字拼音+相邻三字拼音,用于分字特征召回,找到与待纠正文本相似的片名。
[0044]
在需要根据用户输入的语音进行视频检索时,对用户输入的语音文本进行读法预处理后提取拼音特征,并根据提取的拼音特征中的全值特征在拼音全值召回数据库中进行召回,根据提取的拼音特征中的分字特征在分字拼音召回数据库中进行召回,如果全值特征召回结果中有片名,则将该片名作为视频召回结果,如果全值特征召回结果中没有片名,则确定分字特征召回结果中各片名的相似度,并根据所述相似度确定视频召回结果,最终向用户输出视频召回结果。
[0045]
实施例
[0046]
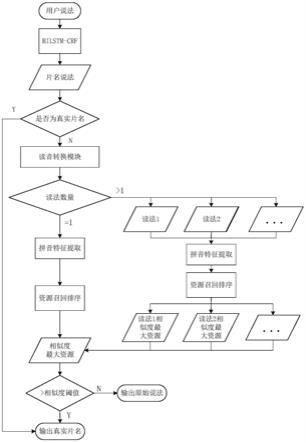
本发明实施例所述的视频召回方法,如图1所示,包括以下步骤:
[0047]
步骤1、将影视数据库中的所有片名文本进行读法预处理后,提取拼音特征,所述拼音特征包括全值特征和分字特征,所述全值特征为片名文本对应的不带声调的全值拼音,所述分字特征包括片名文本对应的带声调的全值拼音、不带声调排序后的全值拼音以及不带声调的相邻字拼音列表;
[0048]
其中读法预处理主要用于处理数字,先将文本中连续的数字提取出来,再按照单个数字读和整体数字等读法转化成中文,再嵌入原始文本。
[0049]
由于带年份的片名数据众多,为了在数据层面减小召回压力,根据大多数人的常用习惯,如果两种读法读音长度差大于等于2,则默认是单个数字读的读法(2000除外)。例如:“2012”的单个数字读法为“二零一二”,整体数字读法为“两千零一十二”,长度差等于2,则默认为前一种读法。“2002”的单个数字读法为“二零零二”,整体数字读法为“两千零二”,长度相同,则默认有两种读法。再例如,567既可能读做“五六七”,也可能读作“五百六十七”,如果用户读法和数据库数据不一致则会对相似度造成影响,因此需要统一。将文本中连续的数字提取出来,再按照单个数字读和整体数字等读法转化成中文,再嵌入原始文本。
这样可以处理片名中阿拉伯数字和中文数字不同导致的相似度损失。
[0050]
其中,拼音特征分为全值特征和分字特征。
[0051]
全值特征为文本的不带声调的全值拼音,字与字之间用
“‑”
隔开。全值特征用于召回读音完全一致的片名。例如:“司藤”的全值特征为“si-teng”。
[0052]
分字特征分为三个部分。
[0053]
(1)带声调的全值拼音,声调用数字表示,用于计算原始文本与目标片名的相似度。例如:“司藤”的带声调的全值特征为“si1-teng2”,“2021创造营”带声调的全值特征为“er4-ling2-er4-yi1-chuang4-zao4-ying2”。
[0054]
(2)不带声调排序后的全值拼音,用于计算排序后的原始文本与排序后的目标片名的相似度。例如:“司藤”的不带声调排序后的全值特征为“si-teng”,“2021创造营”不带声调排序后的全值特征为“chuang-er-er-ling-yi-ying-zao”。
[0055]
(3)不带声调的相邻字拼音列表,用于分字特征召回。当字数为1时,为单字拼音;字数为2时,为单字拼音+相邻两字拼音;字数为3时,为单字拼音+相邻两字拼音+相邻三字拼音;字数为4时,为前两字单字拼音+相邻两字拼音+相邻三字拼音;字数大于4时,为相邻两字拼音+相邻三字拼音。相邻字拼音之间用
“‑”
隔开。
[0056]
例如:“司藤”的不带声调的相邻字拼音列表为[“si-teng”,“si”,“teng”],“2021创造营”的不带声调的相邻字拼音列表为[“er-ling-er”,“ling-er-yi”,“er-yi-chuang”,“yi-chuang-zao”,“chuang-zao-ying”,“er-ling”,“ling-er”,“er-yi”,“yi-chuang”,“chuang-zao”,“zao-ying”]。
[0057]
步骤2、根据提取的拼音特征分别创建拼音全值召回数据库和分字拼音召回数据库,所述拼音全值召回数据库的key为片名文本的全值特征,value为全值特征相同的片名文本列表,所述分字拼音召回数据库的key为片名文本的不带声调的相邻字拼音列表的元素,value为有该元素的片名特征列表,所述片名特征包括:片名文本及其对应的带声调的全值拼音和不带声调排序后的全值拼音;
[0058]
通过步骤1得到视频数据库中所有片名文本对应的全值特征和分字特征后,利用现有的key-value型数据库,并根据所有片名文本对应的全值特征构建拼音全值召回数据库,根据所有片名文本对应的分字特征构建分字拼音召回数据库。
[0059]
(1)拼音全值召回数据库。field为片名文本的拼音全值特征,value为全值特征相同的片名文本列表。
[0060]
例如:key为“si-teng”,其对应value为“["司藤"]”;key为“wu-jian-dao”,其对应value为“["武间道","无间盗","无间道"]”。
[0061]
(2)分字拼音召回数据库。key为片名中的不带声调的相邻字拼音列表的元素,value为有该元素的片名特征列表。value中存储的片名特征包括片名文本、带声调的全值拼音、不带声调排序后的全值拼音,按顺序以“_”分隔。
[0062]
例如:field为“si-teng”,其对应value为“["2014腾讯t派夏令营腾讯的海量之道_er4-ling2-yi1-si4-teng2-xun4-t-pai4-xia4-ling4-ying2-teng2-xun4-de5-hai3-liang4-zhi1-dao4_dao-de-er-hai-liang-ling-ling-pai-si-t-teng-teng-xia-xun-xun-yi-ying-zhi","司藤_si1-teng2_si-teng"]”。
[0063]
步骤3、当接收到用户输入的语音文本后,根据预设识别算法从语音文本中提取可
能为片名文本的待纠正文本,并对待纠正文本进行与步骤1相同的读法预处理和拼音特征提取,得到待纠正文本所有读法对应的拼音特征;
[0064]
具体而言,可以根据预设的实体识别算法bilstm-crf将语音文本中可能为片名文本的待纠正文本提取出来,并通过与步骤1相同的方法得到待纠正文本的可能读法以及每种读法对应的拼音特征。
[0065]
步骤4、根据待纠正文本各读法对应的拼音特征并分别基于拼音全值召回数据库和分字拼音召回数据库进行全值特征召回和分字特征召回,得到全值特征召回结果和分字特征召回结果;
[0066]
可以理解,本实施例对步骤3中得到的每个读法单独进行片名召回,每次召回均分别在拼音全值召回数据库和分字拼音召回数据库中召回。
[0067]
步骤5、若全值特征召回结果中有片名,则将该片名作为视频召回结果,否则,确定分字特征召回结果中各片名的相似度,并根据所述相似度确定视频召回结果。
[0068]
具体地,对一种读法的全值特征召回和分字特征召回分别处理,先处理全值特征召回。
[0069]
全值特征召回:如果召回了片名,则视作完全匹配,相似度为1,不用考虑分字特征召回结果,如果全值召回的片名只有一个,则将该片名作为视频召回结果,否则,获取全值特征召回结果中各片名文本对应的带声调的全值拼音和用户输入的语音文本对应的带声调的全值拼音,并根据所述全值特征召回结果中各片名文本对应的带声调的全值拼音和用户输入的语音文本对应的带声调的全值拼音计算全值特征召回结果中各片名文本对应的第三拼音编辑距离评分,将第三拼音编辑距离评分最大值对应的片名作为视频召回结果。如果全值特征召回没有召回到片名,则再根据分字特征召回结果来确定视频召回结果。
[0070]
分字特征召回:分为粗筛和精排。
[0071]
如图2和图3所示,本实施例中,粗筛包括三个维度的过滤:
[0072]
(1)共有子串数量。当共有子串数大于第一预设阈值时,该片名才符合该维度的筛选条件,其过滤方法如下:获取分字特征召回结果中各片名文本对应的不带声调的相邻字拼音列表与用户输入的语音文本对应的不带声调的相邻字拼音列表之间的共有子串数量,若所述共有子串数量小于第一预设阈值,则抛弃对应的片名,所述第一预设阈值根据待纠正文本的长度确定。
[0073]
(2)文本长度差。当文本长度差小于第二预设阈值时,该片名才符合该维度的筛选条件。其过滤方法如下:获取分字特征召回结果中各片名文本与待纠正文本的文本长度差,若所述文本长度差大于第二预设阈值,则抛弃对应的片名。
[0074]
(3)第一拼音编辑距离评分。当第一拼音编辑距离评分大于第三阈值时,该片名才符合该维度的筛选条件,其过滤方法如下:获取用户输入的语音文本对应的带声调的全值拼音,根据所述语音文本对应的带声调的全值拼音和分字特征召回结果中的带声调的全值拼音计算分字特征召回结果中各片名文本对应的第一拼音编辑距离评分,若所述第一拼音编辑距离评分小于或等于第三预设阈值,则抛弃对应的片名,所述第一拼音编辑距离评分的计算公式如下:
[0075]
l
pn
=lev(n
pn
,t
pn
);
[0076]
式中,l
pn
为第一拼音编辑距离评分,lev()为编辑距离算法,n
pn
为分字特征召回结
果中的带声调的全值拼音,t
pn
为语音文本对应的带声调的全值拼音。
[0077]
本实施例中,精排主要涉及三个维度:第一拼音编辑距离评分、第二拼音编辑距离评分、共有子串系数。通过精排确定出分字特征召回结果中各片名的相似度,具体方法包括:
[0078]
计算分字特征召回结果中各片名文本对应的排序后的第二拼音编辑距离评分;
[0079]
获取用户输入的语音文本对应的不带声调的相邻字拼音列表长度、分字特征召回结果中各片名文本对应的共有子串数量以及分字特征召回结果中共有子串数量的最大值;
[0080]
根据第一拼音编辑距离评分、第二拼音编辑距离评分、语音文本对应的不带声调的相邻字拼音列表长度、分字特征召回结果中各片名文本对应的共有子串数量以及分字特征召回结果中共有子串数量的最大值计算分字特征召回结果中各片名文本对应的共有子串系数;
[0081]
根据第一拼音编辑距离评分、第二拼音编辑距离评分和共有子串系数计算分字特征召回结果中各片名的相似度。
[0082]
其中,所述第二拼音编辑距离评分的计算方法如下:
[0083]
若分字特征召回结果中片名文本对应的第一拼音编辑距离评分大于第四预设阈值,则将对应片名文本对应的第一拼音编辑距离评分作为该片名文本对应的第二拼音编辑距离评分;
[0084]
若分字特征召回结果中片名文本对应的第一拼音编辑距离评分小于或等于第四预设阈值评分,则获取用户输入的语音文本对应的不带声调排序后的全值拼音,根据所述语音文本对应的不带声调排序后的全值拼音和分字特征召回结果中的不带声调排序后的全值拼音计算分字特征召回结果中各片名文本对应的第二拼音编辑距离评分;
[0085]
所述第二拼音编辑距离评分计算公式如下:
[0086][0087]
式中,l
pr
为第二拼音编辑距离评分,n
pr
为分字特征召回结果中的不带声调排序后的全值拼音,t
pr
为语音文本对应的不带声调排序后的全值拼音,r为第四预设阈值。
[0088]
所述共有子串系数的计算公式如下:
[0089][0090]
式中:sr为共有子串系数,l
pn
为第一拼音编辑距离评分,l
pr
为第二拼音编辑距离评分,t
pl
为语音文本对应的不带声调的相邻字拼音列表长度,sn为分字特征召回结果中片名文本对应的共有子串数量,s
n_max
为分字特征召回结果中共有子串数量的最大值。
[0091]
所述片名对应的相似度similarity计算公式如下:
[0092][0093]
在根据以上方法得到分字特征召回结果中各片名的相似度后,确定出相似度最大值,若所述相似度最大值大于第五预设阈值,则将相似度最大值对应的片名作为视频召回结果,否则,视频召回结果为空。
[0094]
综上所述,本实施例所述的视频召回方法利用用户说法对应的多个维度分字的拼音特征进行相似片名召回,对召回片名拼音与用户说法拼音进行编辑距离的相似度、共有子串系数、基于编辑距离的异位相似度计算得到最终的相似度,选取相似度最高的片名作为结果,提高了用户在影片名字表述简称和表述异位时视频召回的准确性。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1