一种眼部运动损伤检测阅片方法及系统与流程
1.本发明涉及智慧医疗、医疗健康技术领域,特别是涉及一种眼部运动损伤检测阅片方法及系统。
背景技术:
2.眼部运动损伤是指在运动过程中,来自人和物体对眼部的不同程度的撞击,导致眼部结构发生不同程度的损伤和改变。具体损伤包括眼睑和周围软组织出血和肿胀,严重的可能导致眼睛出血、角膜破损等。在眼部外周未见明显外伤的情况下,需要进一步对眼底照片进行检查,针对难以发现的伤处,需要计算机辅助的阅片系统配合人工核验提高阅片效率和准确率。
技术实现要素:
3.为解决上述问题,本发明提供一种眼部运动损伤检测阅片方法及系统,使得诊断的准确率和可信度更高。
4.本发明采用的技术方案是:一种眼部运动损伤检测阅片方法,其特征在于,包括以下步骤:步骤一:选择医学影像数据来源;影像数据来源包括:调用数据库内的医学影像,或,通过本地上传医学影像;步骤二:选择待诊断影像;包括:由医生或用户对疑似损伤图片进行选择,或,一键选择所有医学影像进行诊断;步骤三:预处理待诊断影像;步骤四:将影像输入基于深度学习的辅助诊断模型;步骤五:输出辅助诊断结果;步骤六:保存诊断结果;步骤七:训练并更新模型。
5.进一步的,所述将影像输入基于深度学习的辅助诊断模型,先通过拉普拉斯金字塔将原始图像分解成不同频率的子带图像,再分别选取高频、中频、低频的子带图像作为原始图像的细节特征、架构特征、区域特征;所述细节特征,包含微小毛细血管等信息;所述架构特征,包含明显血管及视网膜区域信息;所述区域特征,补全细节特征及架构特征缺失的信息。
6.进一步的,所述基于深度学习的辅助诊断模型,共包含4个功能,包括:a1眼底出血诊断、a2视网膜脱落诊断、b1眼底出血区域定位、b2视网膜脱落区域定位;所述模型诊断流程如下:第一,模型诊断输入影像是否为眼底出血:
如果诊断结果为阳性,模型将进一步对出血区域进行标记,用蓝色线段将眼底出血区域划线标记,如果诊断结果为阴性,该影像关于眼底出血的诊断即为“无眼底出血情况”;第二,模型将诊断输入影像是否有视网膜脱落的情况:如果诊断结果为阳性,模型将进一步对视网膜脱落区域进行标记,红色线段将视网膜脱落区域划线标记,如果诊断结果为阴性,该影像关于视网膜脱落的诊断即为“无视网膜脱落情况”。
7.进一步的,所述模型诊断流程还包括:将待诊断图像的细节特征、架构特征、区域特征输入辅助诊断模型,分别得到诊断或标记结果;最终的辅助诊断结果由三种特征对应的输出和各自的权重共同计算得出:其中,x为模型的输出,w为不同频的权重,y为待诊断图像最终的辅助诊断结果;其中,在a1和b1的诊断流程中,较多依赖于细节特征和区域特征,因此在预设权重时,细节特征和区域特征高于架构特征权重;在a2和b2的诊断流程中,较多依赖于架构特征和区域特征,因此在预设权重时,架构特征和区域特征高于细节特征权重。
8.进一步的,所述保存诊断结果,需经医生或用户对辅助诊断结果进行确认,并对错误的辅助诊断结果进行修正,修正后的结果将作为病人最终的影像诊断结果记录在病人的检查报告中。
9.进一步的,所述训练并更新模型,对于新补充的数据,需要对应专家的标记,作为模型的共同输入;还包括在辅助诊断中,系统诊断有误且被医生修改过诊断结果的影像,在由专家确认之后,数据也将进入训练集,并持续训练达到更新的效果,以提升诊断模型和损伤区域分割模型的准确性和泛化能力。
10.一种眼部运动损伤检测阅片系统,包括:数据导入模块,用于导入病人的眼底照片;诊断及定位模块,用于通过诊断定位模型诊断所述眼底照片中是否存在眼部运动损伤,如存在眼部运动损伤,在所述眼底照片中对所述眼部运动损伤的位置进行定位;结果保存模块,用于存储所述诊断及定位模块的诊断及定位结果;模型训练模块,用于根据所述结果保存模块的存储数据对所述诊断定位模型进行训练更新,所述更新后的诊断定位模型用于所述诊断及定位模块的后续使用。
11.进一步的,所述的眼部运动损伤检测阅片系统还包括:数据预处理模块,用于对所述数据导入模块导入的病人的眼底照片进行预处理。
12.所述导入病人的眼底照片,包括:通过医疗信息管理系统远程调取病人的眼底照片,或,从本地上传病人的眼底照片。
13.所述数据预处理模块包括:降噪滤波单元,用于对所述导入的病人的眼底照片进行降噪滤波处理;直方图优化单元,用于对所述导入的病人的眼底照片进行直方图优化处理;
对比度增强单元,用于对所述导入的病人的眼底照片进行对比度增强处理;图像放缩单元,用于对所述导入的病人的眼底照片进行图像放缩处理。
14.所述诊断定位模型包括:损伤诊断模型单元和损伤定位模型单元;所述损伤诊断模型单元基于复数个分类模型进行构建;所述损伤定位模型单元基于复数个分割模型进行构建;所述模型训练模块采用交叉验证的方法进行选择,选择auc最高的模型作为损伤诊断模型,选择iou最高的模型作为损伤定位模型。
15.所述模型训练模块,包括:专家标注单元,用于对所述诊断及定位模块的诊断及定位结果进行专家标注,将所述专家标注后的诊断及定位结果输入所述诊断定位模型进行训练更新;医生修改单元,用于在辅助诊断中,所述诊断及定位模块的诊断及定位结果有误且所述诊断及定位结果被使用医生修改,在由专家确认之后,将所述修改后的诊断及定位结果输入所述诊断定位模型进行训练更新。
16.所述诊断及定位模块包括:子带图像获取单元,用于通过拉普拉斯金字塔将所述眼底照片分解成不同频率的子带图像;损伤确认单元,用于将每一个频率分段的子带图像输入所述损伤诊断模型,通过softmax函数,反馈所述眼底照片损伤的概率,当所述眼底照片损伤的概率大于设定阈值时,确定所述眼底照片中存在眼部运动损伤。
17.定位单元,用于在所述眼底照片中对所述眼部运动损伤的位置进行定位,当诊断结果确定所述眼底照片中存在眼部运动损伤时,基于图像分割算法,对损伤区域像素级分割,将损伤区域可视化标记在所述眼底照片中。
18.进一步的,所述的眼部运动损伤检测阅片系统还包括:显示模块,用于对所述诊断及定位模块的诊断及定位结果进行显示,还用于显示定位前和后的眼底照片。
19.反馈模块,用于将最终确诊结果反馈在病人病历中,和/或,反馈到医疗信息管理系统中。
20.本发明的有益效果是:通过上述技术方案的眼部运动损伤检测阅片方法及系统,可对医生或专业医护人员存疑的影像进行辅助诊断,也可为经验较少的医生提供全部诊断的辅助阅片功能,使得诊断的准确率和可信度更高。
附图说明
21.图1为本发明实施例一种眼部运动损伤检测阅片方法的流程示意图。
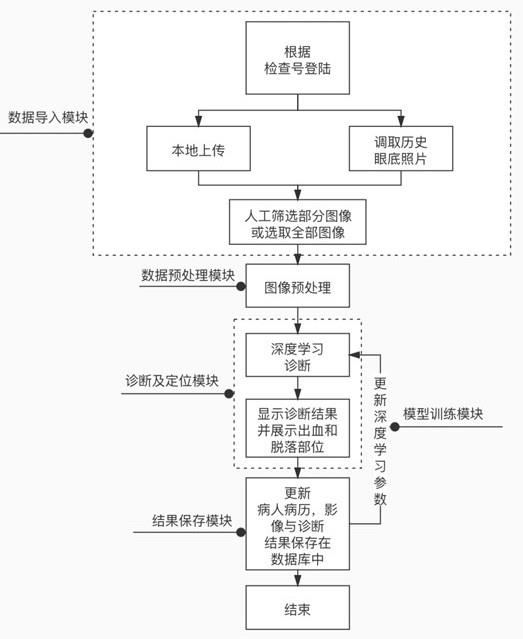
22.图2为本发明实施例一种眼部运动损伤检测阅片方法及系统的流程示意图。
23.图3为本发明实施例一种眼部运动损伤检测阅片系统的系统结构示意图。
24.图4为本发明实施例一种眼部运动损伤检测阅片方法的诊断流程示意图。
具体实施方式
25.在本技术实施例提供的技术方案中,通过在眼部运动损伤检测阅片系统中设置,
数据导入模块,用于导入病人的眼底照片;诊断及定位模块,用于通过诊断定位模型诊断所述眼底照片中是否存在眼部运动损伤,如存在眼部运动损伤,在所述眼底照片中对所述眼部运动损伤的位置进行定位;结果保存模块,用于存储所述诊断及定位模块的诊断及定位结果;模型训练模块,用于根据所述结果保存模块的存储数据对所述诊断定位模型进行训练更新,所述更新后的诊断定位模型用于所述诊断及定位模块的后续使用。可对医生或专业医护人员存疑的影像进行辅助诊断,也可为经验较少的医生提供全部诊断的辅助阅片功能,使得诊断的准确率和可信度更高。
26.下面结合附图对本技术实施例技术方案的主要实现原理、具体实施方式及其对应能够达到的有益效果进行详细的阐述。
27.实施例一参考图1、图2,本发明的眼部运动损伤检测阅片系统在辅助诊断中采用以下步骤进行应用:步骤一:选择医学影像数据来源。数据可根据检查号调用数据库内的病人影像,或通过本地上传对影像进行辅助诊断。
28.步骤二:选择待诊断影像。系统准备“图片选择”和“一键检测”两个功能,当大部分眼底照片不存在损伤时,医生仅需要选择疑似损伤影像进行辅助诊断即可,或一键选择所有影像进行诊断。
29.步骤三:预处理待诊断影像。将眼底照片放缩在规定的尺寸内。
30.步骤四:将影像输入基于深度学习的辅助诊断模型。
31.该模型共包含4个功能,a1眼底出血诊断、a2视网膜脱落诊断、b1眼底出血区域定位、b2视网膜脱落区域定位。诊断模型流程如下:第一,模型首先诊断输入影像是否为眼底出血,如果诊断结果为阳性,模型将进一步对出血区域进行标记,蓝色线段将眼底出血区域划线标记,如果诊断结果为阴性,该影像关于眼底出血的诊断即为“无眼底出血情况”。第二,模型将诊断输入影像是否有视网膜脱落的情况,如果诊断结果为阳性,模型将进一步对视网膜脱落区域进行标记,红色线段将视网膜脱落区域划线标记,如果诊断结果为阴性,该影像关于视网膜脱落的诊断即为“无视网膜脱落情况”。
32.进一步的,所述将影像输入基于深度学习的辅助诊断模型,先通过拉普拉斯金字塔将原始图像分解成不同频率的子带图像,再分别选取高频、中频、低频的子带图像作为原始图像的细节特征、架构特征、区域特征;所述细节特征,包含微小毛细血管等信息;所述架构特征,包含明显血管及视网膜区域信息;所述区域特征,补全细节特征及架构特征缺失的信息。
33.进一步的,所述基于深度学习的辅助诊断模型,共包含4个功能,包括:a1眼底出血诊断、a2视网膜脱落诊断、b1眼底出血区域定位、b2视网膜脱落区域定位;所述模型诊断流程如下:第一,模型诊断输入影像是否为眼底出血:如果诊断结果为阳性,模型将进一步对出血区域进行标记,用蓝色线段将眼底出血区域划线标记,如果诊断结果为阴性,该影像关于眼底出血的诊断即为“无眼底出血情况”;
第二,模型将诊断输入影像是否有视网膜脱落的情况:如果诊断结果为阳性,模型将进一步对视网膜脱落区域进行标记,红色线段将视网膜脱落区域划线标记,如果诊断结果为阴性,该影像关于视网膜脱落的诊断即为“无视网膜脱落情况”。
34.进一步的,所述模型诊断流程还包括:将待诊断图像的细节特征、架构特征、区域特征输入辅助诊断模型,分别得到诊断或标记结果;最终的辅助诊断结果由三种特征对应的输出和各自的权重共同计算得出:其中,x为模型的输出,w为不同频的权重,y为待诊断图像最终的辅助诊断结果;其中,在a1和b1的诊断流程中,较多依赖于细节特征和区域特征,因此在预设权重时,细节特征和区域特征高于架构特征权重;在a2和b2的诊断流程中,较多依赖于架构特征和区域特征,因此在预设权重时,架构特征和区域特征高于细节特征权重。
35.步骤五:输出辅助诊断结果。无论是仅选择几张或一键检测,每一张影像都会得到如下几种反馈结果:第一种,无疑似损伤;第二种,疑似眼底出血(疑似眼底出血区域被标记),无视网膜脱落情况;第三种,无眼底出血情况,疑似视网膜脱落(疑似视网膜脱落区域被标记);第四种,疑似眼底出血(疑似眼底出血区域被标记),疑似视网膜脱落(疑似视网膜脱落区域被标记)。医生可对上述四种情况进行确认,可对辅助诊断有误的结果进行修正,修正后的结果将作为病人最终的影像诊断结果记录在病人的检查报告中。
36.步骤六:保存诊断结果。
37.进一步的,所述保存诊断结果,需经医生或用户对辅助诊断结果进行确认,并对错误的辅助诊断结果进行修正,修正后的结果将作为病人最终的影像诊断结果记录在病人的检查报告中。
38.步骤七:训练并更新模型。为提升诊断模型和损伤区域分割模型的准确性和泛化能力,模型需要持续训练达到更好的效果。对于新补充的数据,需要对应专家的标记,作为模型的共同输入。在辅助诊断中,系统诊断有误且被使用医生修改过诊断结果的影像,在由专家确认之后,数据也将进入训练集,以提升系统诊断准确率。
39.实施例二请参考图2、图3,本技术实施例提供一种眼部运动损伤检测阅片方法及系统,包括:数据导入模块,用于导入病人的眼底照片;诊断及定位模块,用于通过诊断定位模型诊断所述眼底照片中是否存在眼部运动损伤,如存在眼部运动损伤,在所述眼底照片中对所述眼部运动损伤的位置进行定位;结果保存模块,用于存储所述诊断及定位模块的诊断及定位结果;模型训练模块,用于根据所述结果保存模块的存储数据对所述诊断定位模型进行训练更新,所述更新后的诊断定位模型用于所述诊断及定位模块的后续使用。
40.数据预处理模块,用于对所述数据导入模块导入的病人的眼底照片进行预处理。
41.其中的数据导入模块,医生根据病人的检查号登录系统后,可通过医疗信息管理
系统,依据病历号-检查号远程调取病人的眼底照片,或从本地直接上传病人的眼底照片。奔模块的上述设计可降低辅助诊断系统对全封闭医疗信息管理系统的依赖性,本发明的眼部运动损伤检测阅片系统既可嵌入医疗信息管理系统,又可独立于上述管理系统之外。系统同时支持两种辅助诊断方式,包括“图片选择”和“一键检测”两个功能,医生可以对疑似损伤眼底照片进行选择,当大部分眼底照片不存在损伤时,医生仅需要选择疑似损伤眼底照片进行辅助诊断即可,反之则可以一键选择所有眼底照片进行诊断。
42.数据预处理模块,由于本发明的诊断模型要求照片的尺寸一致,使得所有照片在一个对比度适合人肉眼观看的视觉范围内,因此在数据预处理模块对选择的影像进行降噪滤波、直方图优化、对比度增强和图像放缩处理。
43.因此本发明的数据预处理模块至少应当包括以下照片处理单元:1、降噪滤波单元,用于对所述导入的病人的眼底照片进行降噪滤波处理;2、直方图优化单元,用于对所述导入的病人的眼底照片进行直方图优化处理;3、对比度增强单元,用于对所述导入的病人的眼底照片进行对比度增强处理;4、图像放缩单元,用于对所述导入的病人的眼底照片进行图像放缩处理。
44.用于对所述数据导入模块导入的病人的眼底照片进行预处理进一步的,所述的眼部运动损伤检测阅片系统还包括:对于诊断及定位模块,用于通过诊断定位模型诊断所述眼底照片中是否存在眼部运动损伤,如存在眼部运动损伤,在所述眼底照片中对所述眼部运动损伤的位置进行定位。其中本发明的眼部运动损伤,至少包括眼底出血和视网膜脱落,而眼部运动损伤的位置进行定位至少包括眼底出血和视网膜脱落在眼底损伤照片上的定位。
45.本发明的断及定位模块包括一下单元,以分别实现上述用途。
46.子带图像获取单元,用于通过拉普拉斯金字塔将所述眼底照片分解成不同频率的子带图像;损伤确认单元,用于将每一个频率分段的子带图像输入所述损伤诊断模型,通过softmax函数,反馈所述眼底照片损伤的概率,当所述眼底照片损伤的概率大于设定阈值时,确定所述眼底照片中存在眼部运动损伤。
47.定位单元,用于在所述眼底照片中对所述眼部运动损伤的位置进行定位,当诊断结果确定所述眼底照片中存在眼部运动损伤时,基于图像分割算法,对损伤区域像素级分割,将损伤区域可视化标记在所述眼底照片中。
48.具体的,本发明诊断及定位模块依据上述单元的具体步骤是:首先子带图像获取单元通过拉普拉斯金字塔将原始图像分解成不同频率的子带图像。对于每一个频率分段的子带图像再基于多层cnn的眼底出血诊断模型,通过softmax函数,反馈影像为眼底出血的概率。当出血概率大于设定阈值时,模型诊断结果即为阳性,上述阈值的设定根据断定位模型诊断结果以及专家的评判决定。
49.在诊断视网膜脱落时,也是同样的计算流程。当诊断结果为阳性后,进入损伤区域分割模型,实现该功能的模型基于unet, fcn 等图像分割算法,实现损伤区域像素级分割,最终将损伤区域可视化标记在影像中。诊断及定位模块将多尺度变换与深度学习网络相结合,更好得利用了原始图像中低频、中频、高频子带图像中各自的特征,能够提高识别准确率和可信度。
50.上述眼底出血和视网膜脱落的诊断顺序不分先后,也可以同时进行。
51.本发明的结果保存模块,用于存储所述诊断及定位模块的诊断及定位结果,包括图片影像数据及诊断及定位结果均可以保存在专用数据库中,结果保存模块既保证了诊断结果的储存功能,也可以对计算有偏差的新数据进行修正,为模型更新提供更多且高质量的数据。
52.本发明的模型训练模块,用于根据所述结果保存模块的存储数据对所述诊断定位模型进行训练更新,所述更新后的诊断定位模型用于所述诊断及定位模块的后续使用。本发明模型也可以在存储数据保存后在固定间隔时间内基于保存的新数据进行训练。
53.为提升诊断模型和定位模型的准确性和泛化能力,模型需要持续训练达到更新的效果。对于新补充的数据,需要对应专家的标记,作为模型的共同输入。在辅助诊断中,系统诊断有误且被使用医生修改过诊断结果的影像,在由专家确认之后,数据也将进入训练集,以提升系统诊断准确率,具体的,本发明的模型训练模块采用以下处理单元执行上述任务:专家标注单元,用于对所述诊断及定位模块的诊断及定位结果进行专家标注,将所述专家标注后的诊断及定位结果输入所述诊断定位模型进行训练更新;医生修改单元,用于在辅助诊断中,所述诊断及定位模块的诊断及定位结果有误且所述诊断及定位结果被使用医生修改,在由专家确认之后,将所述修改后的诊断及定位结果输入所述诊断定位模型进行训练更新。
54.对应上述模型训练模块,本发明的诊断定位模型至少还包括:损伤诊断模型单元和损伤定位模型单元;所述损伤诊断模型单元基于复数个分类模型进行构建,如vgg11,vgg13,vgg16,vgg19等;所述损伤定位模型单元基于复数个分割模型进行构建,其基本框架为u-net和fcn;所述模型训练模块在模型及其超参数的选择中,采用交叉验证的方法进行选择,选择auc最高的模型作为损伤诊断模型,选择iou最高的模型作为损伤定位模型。
55.为了更好的服务于辅助诊断,本发明的眼部运动损伤检测阅片系统还包括:显示模块,用于对所述诊断及定位模块的诊断及定位结果进行显示,还用于显示定位前和后的眼底照片,将上述结果在显示器或者胶片等显示界面进行显示,从而实现辅助诊断结果的可视化。
56.反馈模块,用于将最终确诊结果反馈在病人病历中,也可以通过网络反馈到医疗信息管理系统中,便于后续医生的调用以及系统的更新改进。
57.实施例三请参考图4,所述模型的诊断流程包括:第一,模型首先诊断输入影像是否为眼底出血:如果诊断结果为阳性,模型将进一步对眼底出血区域进行像素级分割,最终将眼底出血区域进行可视化标记,蓝色线段将眼底出血区域划线标记,如果诊断结果为阴性,该影像关于眼底出血的诊断即为“无眼底出血情况”。
58.第二,模型将诊断输入影像是否有视网膜脱落的情况:如果诊断结果为阳性,模型将进一步对视网膜脱落区域进行像素级分割,最终将视网膜脱落区域进行可视化标记,红
色线段将视网膜脱落区域划线标记,如果诊断结果为阴性,该影像关于视网膜脱落的诊断即为“无视网膜脱落情况”。
59.进一步的,所述模型诊断流程还包括:将待诊断图像的细节特征、架构特征、区域特征输入辅助诊断模型,分别得到诊断或标记结果;最终的辅助诊断结果由三种特征对应的输出和各自的权重共同计算得出:其中,为模型的输出,为不同频的权重,为待诊断图像最终的辅助诊断结果;如图中所示、、、、、,分别为细节特征、架构特征、区域特征在眼底出血诊断及视网膜脱落诊断中的权重。
60.其中,在a1和b1的诊断流程中,较多依赖于细节特征和区域特征,因此在预设权重时,细节特征和区域特征高于架构特征权重;在a2和b2的诊断流程中,较多依赖于架构特征和区域特征,因此在预设权重时,架构特征和区域特征高于细节特征权重。
61.进一步的,上述眼底出血和视网膜脱落的诊断顺序不分先后,也可以同时进行。
62.进一步的,所述将影像输入基于深度学习的辅助诊断模型,先通过拉普拉斯金字塔将原始图像分解成不同频率的子带图像,再分别选取高频、中频、低频的子带图像作为原始图像的细节特征、架构特征、区域特征;所述细节特征,包含微小毛细血管等信息;所述架构特征,包含明显血管及视网膜区域信息;所述区域特征,补全细节特征及架构特征缺失的信息。
63.本领域技术人员在考虑说明书及实践这里公开的发明后,将容易想到本发明的其它实施方案。本技术旨在涵盖本发明的任何变型、用途或者适应性变化,这些变型、用途或者适应性变化遵循本发明的一般性原理并包括本公开未公开的本技术领域中的公知常识或惯用技术手段。说明书和实施例仅被视为示例性的,本发明的真正范围和精神由下面的权利要求指出。
64.应当理解的是,本发明并不局限于上面已经描述并在附图中示出的精确结构,并且可以在不脱离其范围进行各种修改和改变。本发明的范围仅由所附的权利要求来限制以上所述仅为本发明的较佳实施例,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1