一种基于传递式视觉关系检测的视频描述生成方法与流程
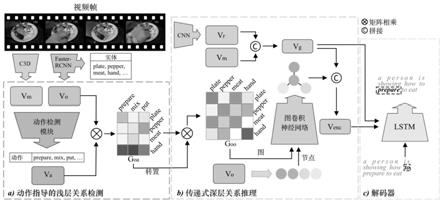
1.本发明涉及一种针对视频描述生成(video captioning,vc)的深度神经网络,尤其涉及一种检测视觉实体-动作之间的浅层联系并传递构造深层视觉实体关系图以及依靠视觉实体关系图细化视频特征的建模方法。
背景技术:
[0002]“跨媒体”统一表达是一个计算机视觉与自然语言处理研究领域之间的交叉方向,旨在打通不同媒体(如视频和文本)之间的“语义鸿沟”,建立统一的语义表达。基于跨媒体统一表达的理论方法,衍生出一些目前热门的研究方向,如视频描述生成(video captioning)、视频-文本跨媒体检索(video-text cross-media retrieval)、视觉关系检测(visual relation detection)以及视频内容的自动问答(video questionanswering,videoqa)等。视频描述生成的目标是给定一段视频使用一句或几句自然语言对其内容进行概述;视频-文本的跨媒体检索旨在给定一段视频从数据库中找到最匹配的文本描述,或给定一个文本描述寻找最匹配的视频;视觉关系检测的目标在于输入一段视频,模型检测视频中关键实体之间的联系;视频内容自动问答的目标在于输入一段视频和一个自然语言描述的问题,算法自动输出一个自然语言描述的答案。
[0003]
随着近年来深度学习的迅速发展,使用深度神经网络框架,如编码器-解码器(encoder-decoder)框架进行端到端(end-to-end)地建模成为目前计算机视觉、自然语言处理方向上的主流研究方向。在视频描述生成算法中,如何在不依赖外部知识库(knowledge base)、不借助大规模预训练模型(pre-trained model),仅在编码器部分将视频的特征表示进行深层建模条件下,使特征表示中包含更深层次的语义内容,从而输入解码器中直接输出准确、流畅的自然语言描述是一个值得深入探索的研究问题。
[0004]
在实际应用方面,视频描述生成算法具有非常广泛的应用场景。基于图像的描述生成系统已经被广泛应用在新闻自动成稿、医学报告生成、图片审核等实际场景中。随着视频平台(如抖音和youtube)以及互联网技术的快速发展,目前基于视频的文本描述生成逐渐成为计算机视觉(computer vision)中热门研究方向之一。这项技术可以帮助我们更简单、快速地理解视频内容,以便于进行后续的审核、分类等操作。
[0005]
综上所述,基于编码器-解码器结构的视频描述生成算法是一个值得深入研究的方向,本课题拟从该任务中几个关键的难点问题切入,解决目前方法存在的问题,并最终形成一套完整的视频描述生成系统。
[0006]
由于自然场景下的视频内容复杂,实体数量多,实体间关系复杂,自然语言描述的问题自由度高,这使得视频描述生成算法面临巨大挑战。具体而言,主要存在以下两方面的难点:
[0007]
(1)如何检测视频中多个实体之间的视觉关系:视觉关系检测问题是计算机视觉中一个经典且基础的问题,在图像级别数据中的应用已经比较成熟,常用的方法有目标检测,动作检测,或使用场景图来表示等。此外,基于场景图生成的模型,在很多计算机视觉领
域,如图像描述生成、图像内容问答、图像检索中都发挥了非常好的效果,但是由于视频级别的数据存在时序上实体冗余、动作复杂等问题,如何检测视频中包含的视觉关系并从中筛选关键的关系是一个很大挑战。因此,在视频级别的数据中进行视觉关系检测是一个值得深入研究的方向。
[0008]
(2)如何利用视觉关系细化视频的特征表示:视频描述生成算法中解码器的输入仅包括编码器输出的视频特征表示。要正确地描述视频内容,需要视觉特征中包含视频的全局内容(global content)以及关键实体(key object)和关键动作(key action)的特征表示。目前许多视频描述生成算法利用外部知识库和预训练模型共同构建视觉特征表示,但是由于外部知识库包含过多常识性信息、预训练模型包含与本任务无关的数据集信息,会引入噪声使模型训练困难。因此,如何让编码器在不借助外部知识库或者预训练模型,仅利用视觉关系细化视频特征表示,是视频描述生成算法中的难点问题,同时也是影响算法结果性能至关重要的环节。
技术实现要素:
[0009]
本发明的目的是针对现有技术的不足,提供一种基于传递式视觉关系检测的视频描述生成方法。
[0010]
本发明解决其技术问题所采用的技术方案包括如下步骤:
[0011]
给定视频v和相应的文本描述c构成视频-描述对v,c作为训练集,提出传递式视觉关系检测模块,传递式视觉关系检测模块包括动作指导的浅层关系检测模块和传递式深层关系推理模块。
[0012]
步骤(1)、数据预处理:对视频提取特征,对文本描述构建字典;
[0013]
对视频v的预处理:先将所有视频进行抽帧并将每一帧缩放到统一的尺寸大小,再分别使用不同的深度神经网络2d-cnn、c3d和faster-rcnn提取得到视频的特征vr、vm和vo。
[0014]
对于文本描述c的预处理:
[0015]
1、提取描述中含有的动词,构建动词词嵌入(embedding)ea:首先使用开源工具提取描述中的主谓宾三元组,选择其中的谓语作为该描述包含的动词,根据数据集中所有的动词构建动词词嵌入。
[0016]
2、构建描述词嵌入ec:对数据集中的所有描述进行分词并统计每个词的出现次数,丢弃出现次数少于设定阈值的单词,根据剩下所有的单词构建描述词嵌入。
[0017]
步骤(2)、动作指导的浅层关系检测(action-guided shallow relationship detection)模块;
[0018]
其流程如图1中a)部分所示,考虑到视频中的动作都是由实体发起,因此该模块利用视频的三维特征和实体特征提取了视频动作表示,并使用非线性映射层(non-linear mapping layer)将动作表示映射至维度为动词字典大小的向量,向量中每个值代表对应动词的概率,根据该向量选择二十个概率最高的动词ai(i=1,...,20)作为该视频包含的动词。根据视频中包含的实体与动词,构建实体-动作(object-action)关系图g
oa
。
[0019]
步骤(3)、传递式深层关系推理(transitive deep-level relationship reasoning)模块与解码器模块;
[0020]
其流程如图1中b)部分所示,将实体-动作关系图与其转置图进行矩阵相乘操作,
从而利用实体与动作之前的关系传递式地构造实体与实体之间的关系。矩阵相乘的输出作为深层实体-实体(object-object)关系图g
oo
,之后将实体-实体关系图视为图(graph),实体特征视为节点(node),利用图卷积神经网络(gcn)细化节点的特征表示,将实体之间的关系编码入实体特征表示中。最后根据细化后的实体特征表示与全局特征共同构造视频的编码特征v
enc
,并作为解码器的输入。本文中使用的解码器为lstm,每一个时间步t的输入为上一个时间步的隐层特征h
t-1
、上一个时间步生成的单词编码ecy
t-1
、动词编码va和视频编码特征v
enc
,输出为当前时间步的隐层特征h
t
和生成的单词概率分布p
θ
(y
t
),最后根据概率分布生成当前时间步的单词。
[0021]
步骤(4)、模型训练
[0022]
根据预测的动词和描述与该视频的实际动词和描述之间的差异计算负对数似然损失(negative log likelihood),并利用反向传播算法(back-propagation,bp)对上述定义的神经网络的模型参数进行训练,直至整个网络模型收敛。
[0023]
步骤(1)所述的数据预处理即对视频进行特征提取和词嵌入构建:
[0024]
1-1.对于视频v,使用现有的深度神经网络分别提取二维特征三维特征和实体特征其中dr、dm和do分别是二维、三维和实体特征的尺寸,n是视频中实体的数量。
[0025]
1-2.对于文本描述c,首先使用nltk的开源工具提取描述中的主谓宾(subject-predicate-object)结构,其中谓语作为该描述也是该视频包含的真实动词a
*
被提取出来构造动词词嵌入ea:
[0026][0027]
其中是第i个动词的词嵌入,i为该动词在词嵌入中的索引值,dw为词嵌入的尺寸。
[0028]
随后将所有描述进行分词并统计每个词出现的次数,丢弃出现次数小于2的单词之后作为视频的真实描述y
*
,提取剩下所有的单词构建描述词嵌入ec:
[0029][0030]
其中是第i个单词的词嵌入,j为该单词在词嵌入中的索引值。
[0031]
步骤(2)所述的动作指导的浅层关系检测(action-guided shallow relationship detection)模块,该模块包括叙述动作检测模块(action detection module)、以及利用动作和实体特征表示利用矩阵相乘得到浅层实体-动作关系图,具体过程如下:
[0032]
2-1.动作检测模块中,首先设参数变量1.动作检测模块中,首先设参数变量其中为映射矩阵,d为输出维度,注意力特征v
att
可通过如下公式进一步计算得到:
[0033][0034]
得到f
att
之后,使用一层前馈(feed-forward)网络计算注意力特征,具体公式如下:
[0035]vatt
=layernorm(f
att
+w
down
(σ(w
upfatt
)))
ꢀꢀꢀ
(公式4)
[0036]
其中和分别为上采样和下采样映射矩阵,d
up
为采样维度,σ为relu激活函数。随后将注意力特征与三维特征映射至同一空间后进行拼接,具体公式如下:
[0037]va
=[f
map
(v
att
);f
map
(vm)]
ꢀꢀꢀ
(公式5)
[0038]
公式(5)中的va为动作表示,f
map
(x)为映射函数,该映射函数由一层全连接层加上权重之后通过一层relu激活函数后得到,具体公式如下
[0039]fmap
(x)=σ(w
x
x+b
x
)
ꢀꢀꢀ
(公式6)
[0040]
其中w
x
和b
x
为映射矩阵和权重向量。得到动作表示后,将其映射至维度为动作词表大小的向量,并将向量中每个值转化为概率值,并通过概率值的大小选择视频的动作,具体公式如下:
[0041][0042]
其中是映射矩阵,la为动词字典的尺寸。根据公式(7)计算动词词表中每一个动词的概率选择其中概率最高的20个动词利用动词词嵌入计算动词特征。词特征计算公式如下:
[0043][0044]
其中为动词特征,da为动词特征的维度。
[0045]
2-2.得到动词特征之后,结合实体特征计算得到浅层实体-动作关系图,计算公式如下:
[0046][0047]
其中为浅层实体-动作关系图,该图中的值均为0和1之间的实数,并且通过正则化使每个实体与同一动词存在联系的概率值相加为1;wv和w
l
用来将实体和动词特征映射到同一空间的映射矩阵。
[0048]
步骤(3)所述的传递式深层关系推理(transitive deep-level relationship reasoning)模块与解码器具体如下:
[0049]
3-1.为了把浅层实体-动作关系图g
oa
中实体与动词之间的联系转化为实体与实体之间的联系,将步骤(2)中生成的g
oa
和它自身的转置进行矩阵相乘,然后进行正则化之后得到深层实体-实体关系图,计算公式如下:
[0050][0051]
其中为深层实体-实体关系图,该图中的每个值表示对应位置实体之间的关联度。之后为每个实体筛选出五个最相关的实体保留关联值,其余不相关实体的关联度均设置为0,从而得到筛选后的深层关联图
[0052]
3-2.得到深层关系图后,利用图卷积神经网络(gcn)根据深层关系图中的值对实体特征进行细化,使相关联实体之间的特征进行交互,计算公式如下:
[0053]
[0054]
其中为细化后的实体特征,wg为图卷积神经网络中可学习矩阵。得到细化特征后,我们利用公式(3)和公式(4)计算编码器特征v
enc
,其中将公式(3)中的q、k和v分别为wg′vg
、和代替,其中vg为vr与vm拼接而成的全局特征,wg′
、和均为映射矩阵。
[0055]
3-3.得到编码器特征之后,利用lstm网络生成文本描述。在每一个时间步t,lstm的输出为隐层特征h
t
和解码特征o
t
,然后根据解码特征计算出当前时间步生成的单词y
t
。lstm的输入是由上一个时间步t-1输出的隐层特征h
t-1
、单词y
t-1
和视频特征计算得到。其中lstm输入部分的计算公式如下:
[0056][0057]
其中w
t
为由上一时间步得到的隐层特征、单词和动词特征计算得到的文本特征,其中α1与α2为α中的两个值。
[0058]
然后将文本特征与全局特征和编码器特征进行拼接构成lstm的输入。lstm部分的计算公式具体如下:
[0059]
{o
t
,h
t
}=lstm([w
t
;vg;v
enc
],h
t-1
)
ꢀꢀꢀ
(公式13)
[0060]
得到解码特征{o
t
,h
t
}后,使用一个映射矩阵将其维度大小映射至描述词嵌入的大小,将其归一化后得到当前时间步生成单词的概率分布,计算公式如下:
[0061][0062]
其中为当前时间步生成单词的概率分布,为映射矩阵。最后,得到概率分布之后可以根据从中选择出概率最大的单词作为当前时间步的单词输出y
t
,计算公式如下:
[0063][0064]
步骤(4)所述的训练模型,具体如下:
[0065]
4-1.将步骤(2)产生的动词概率分布同步骤(1)中提取的真实动词a
*
输入到负对数似然损失函数中,得到损失值具体公式如下:
[0066][0067]
4-2.将步骤(3)产生的概率分布同步骤(1)产生的真实描述输入到负对数似然损失函数中,得到损失值具体公式如下:
[0068][0069]
4-3.根据计算得到的损失值和计算最终的损失,计算公式如下:
[0070][0071]
其中λ为预先设置好的超参数。最后利用反向传播算法(back-propagation,bp)调整网络中的参数。
[0072]
本发明有益效果如下:
[0073]
本发明提出一种针对视频描述生成任务的深度神经网络架构,以解决如上两个难点问题。1、提出一种传递式视觉关系检测模块,实现浅层实体-动作关系和深层实体-实体关系的检测;2.提出一种基于图卷积神经网络,利用视觉关系细化视频特征表示的模型,使编码器特征中同时包含全局内容、关键实体和关键动作的信息。
附图说明
[0074]
图1为本发明流程图。
具体实施方式
[0075]
下面对本发明的详细参数做进一步具体说明。
[0076]
如图1所示,本发明提供一种针对视频描述生成(video captioning,vc)的深度神经网络框架。
[0077]
步骤(1)所述的数据预处理及对视频提取特征,针对文本描述构建字典,具体如下:
[0078]
这里使用msr-vtt和msvd数据集作为实验数据。
[0079]
1-1.对于视频数据,这里使用现有的归一化深度残差网络(inceptionnetv2)模型抽取视频帧特征,使用三维卷积神经网络(c3d)模型抽取视频动态特征,使用目标识别卷积神经网络(faster-rcnn)模型抽取视频帧中的实体特征。具体的,将视频裁帧缩放到统一尺寸,逐帧输入到归一化深度残差网络中,并将得到的特征进行平均池化操作得到二维特征相似的,将视频帧一同输入到三维卷积神经网络中并进行平均池化操作得到三维特征对于实体特征,在每个视频帧上检测10个实体抽取特征,一共检测10个视频帧,并将所有的实体特征进行拼接,最终得到实体特征
[0080]
1-2.对于文本描述,首先使用nltk的开源工具提取描述中的主谓宾结构并抽取其中的谓语作为视频的动词,随后将出现次数少于2次的动词进行删除,剩下的动词利用glove构建动词词嵌入msr-vtt数据集中的动词词嵌入长度la为2615,msvd中为1338。
[0081]
随后将所有描述进行分词并统计每个词出现的次数,删除出现次数小于2的单词,剩下的单词构建描述词嵌入msr-vtt数据集中的描述词嵌入长度lc为10536,msvd中为4064。
[0082]
步骤(2)所述的动作指导的浅层关系检测(action-guided shallow relationship detection)模块,具体如下:
[0083]
2-1.对于输入特征和分别使用映射矩阵和将其分别映射到512维向量。在前馈网络中,采样维度d
up
为2048。映射函数f
map
(x)中(x)中和为映射矩阵和权重向量。在动词特征中,动词特征维度da为512。
[0084]
2-2.使用矩阵相乘操作对动词特征和实体特征进行相乘,其中
和是用来将实体和动词特征映射到同一空间的映射矩阵。生成的浅层关系图的大小为100
×
20。
[0085]
步骤(3)所述的传递式深层关系推理(transitive deep-level relationship reasoning)模块与解码器模块具体如下:
[0086]
3-1.根据浅层关系图生成的深层关系图的大小为100
×
100。
[0087]
3-2.得到深层关系图后,利用图卷积神经网络(gcn)根据深层关系图中的值对实体特征进行细化,其中为图卷积网络中的可学习矩阵。在计算编码器特征的公式中,为全局特征,和均为映射矩阵。
[0088]
3-3.得到编码器特征之后,利用lstm网络生成文本描述,其中隐层特征h
t
和解码特征o
t
的特征维度为512维,生成的概率分布向量的维度与对应词嵌入的维度一致,和均为映射矩阵。得到解码器特征后,计算单词概率分布,其中l为对应数据集的词嵌入维度。
[0089]
步骤(4)所述的训练模型,具体如下:
[0090]
对于步骤(2)和步骤(3)产生的预测动词向量与描述向量,将其与该问题的正确答案做比较,通过定义的负对数似然损失函数计算得出预测值与实际正确值之间的差异并形成损失值,之后根据该损失值利用反向传播算法(back-propagation,bp)调整整个网络的参数值,直到网络收敛,其中λ为0.2。
[0091]
表1是本文所述的方法在msrvtt和msvd数据集中的四个评价指标得分。其中bleu@4、rouge-l和meteor表示文章准确度,cider表示文章的流畅度。saat与gru-eve均为现有较为出色的方法,在msr-vtt数据集上的方法在所有指标上均超过了这两个方法,在msvd数据集上,gru-eve方法在meteor指标上略高于本发明的方法,但是其他指标均远远低于的方法。
[0092][0093]
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1