一种高带宽低延时算法处理的FPGA硬件实现方法与流程
一种高带宽低延时算法处理的fpga硬件实现方法
技术领域:
1.本发明属于电子信息技术领域,可应用于声纳传输处理设备的研制与开发中,具体而言是一种高带宽低延时算法处理的fpga硬件实现方法。
背景技术:
2.随着声纳系统工程以及探测技术的发展,国内外对声纳探测的精度要求越来越高,因此声纳系统工程存在大规模数据传输。大数据量的声纳数据将会存在性能和时延的问题,从而导致基阵数据传输拥塞、实时性低,影响了声纳技术的发展。
技术实现要素:
3.本发明所要解决的技术问题是,提供一种高带宽低延时算法处理的fpga硬件实现方法,该方法解决了基阵传输性能时延低等问题,适用于大数据量且有特定算法的数据处理fpga实现,该方法在计算架构上实现了边缘化计算方式,可以降低处理平台的计算压力,减少传输链路的数据带宽,并且所涉及的计算方法还具有实时性高,提升传输带宽,减少运算资源的优点。
4.本发明的技术解决方案是,提供一种高带宽低延时算法处理的fpga硬件实现方法,包括以下步骤,
5.首先根据声信号处理的算法特点,进行算法归类;并流水设计每类算法处理单元,完成对输入数据处理;
6.然后算法处理模块计算并输出写ram使能、地址和数据;使用计数器对算法处理模块的输入数据进行计数(输入使能有效时计数,在一帧结束后清零计数器);根据每类算法的数据规律,使用计数器将数据输入计算单元,并输出算法处理后的使能信号,地址信息以及数据;
7.以及根据每类算法输出的使能信号,进行判断是否ram有写冲突,若ram 无写冲突(输出使能信号均为不同时刻数据),则采用一个ram进行存储;若ram 有写冲突,则判断算法分类的个数,根据算法分类个数多少结合上述两种写冲突管理模式,选择合适的写冲突管理模式。
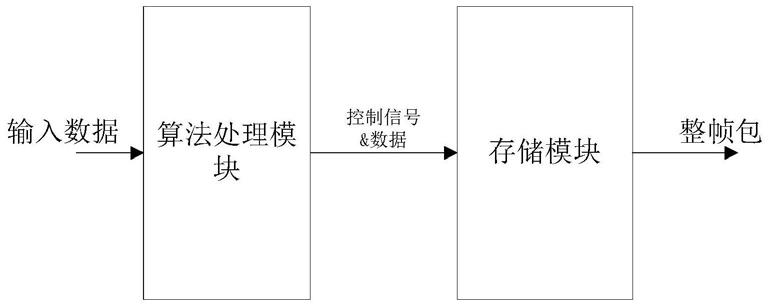
8.作为优选的技术方案,fpga硬件架构包括算法处理模块和存储模块,其中,算法处理模块根据算法特点,流水设计算法算子,满足数据处理带宽同时也节省运算资源;存储模块匹配数据输入和输出之间的带宽,同时保证数据包整帧的输出,以减少输出时延。
9.作为优选的技术方案,输入数据经过算法处理模块,将特定算法进行硬化,并根据输出结构,通过地址控制写入对应的存储模块,最终整帧输出。本方法的数据流为输入数据经过算法处理模块,将特定算法进行硬化,并根据输出结构,通过地址控制写入对应的存储模块,最终整帧输出,如图1所示。若先将数据存储,再进行计算,则数据输出带宽降低,数据传输时延长,且不能够整帧处理。因此本方法的fpga架构能够提升带宽,降低传输时延。
10.算法特点符合输出数据在一定时间内有一定规律。此方法支持输出数据有一种或
多种规律的算法。若算法均为同一规律,则根据算法提取乘加除等算子,设计算子流水处理单元;若算法为不同规律,则进行分类,每一类作为一个算法处理单元,每个处理单元按照算法同一规律的方式进行提取算子,以及设计流水处理方式。
11.作为优选的技术方案,写冲突管理模式有两种,根据算法分类个数多少选择其中一种或两种写冲突管理模式的组合。存储模块处理多种类别算法时,根据算法会出现同时写入ram的情况,引起写入冲突。根据不同的冲突管理,本发明提出两种处理方法。
12.其中一种写冲突管理模式如下,通过分析每类算法的时序规律,将冲突的算法进行分类,并根据分类的类别数量选择对应数量的存储单元使用相同数量的ram进行存储,每一类算法存储分别控制一个ram读写,最后讲上述ram通过深度进行拼接输出。如果可以分为两类则将存储单元使用两个ram进行存储,每一类算法存储分别控制ram读写,最终两个ram通过深度进行拼接输出;如果可以分为四类则将存储单元使用四个ram进行存储,同时使用相同方法进行存储和拼接输出。ram拼接的方式有两种,一种是ram深度拼接,一种是ram宽度拼接。根据不同应用场景,选择不同的拼接模式。
13.对于数据存储冲突类别较少,可使用上述的冲突管理方式,但如果冲突类别较多,上述方式会存在浪费bram资源的情况。
14.进一步的,本发明提出另一种写冲突管理模式,对读写使能和地址的冲突管理模式,具体如下,根据每类算法冲突时序,对于同时需要写入ram的时序,设定优先特定算法的原则,写入此算法数据至ram中,再延时写入后续算法地址的方式进行冲突管理。通过此方式保证ram没有读写冲突问题。所有数据写入ram之后,顺序读出ram数据,并输出计算完成数据。
15.上述两种存储模块的冲突管理模式,在使用中可以灵活结合,可以使用其中一种或者混合使用,达到最优方案。
16.采用以上技术方案后与现有技术相比,本发明具有以下优点:提供了一种高带宽低时延的数据传输方法,提高声纳数据传输效率;提供了边缘化计算结构,降低了传输数据带宽;还提供多种算子处理方案,提升方案支持的广泛性;并且提出存储模块冲突管理以及ram拼接多样性,提升方案灵活度;同时流水设计算子单元,降低设计资源,优化布线算法运行时间。
附图说明:
17.图1是本发明fpga设计框图。
18.图2是本发明数据计算ram拼接图中的。
19.图3是本发明数据时序图。
20.图4是本发明数据计算fpga硬件实现的方法流程图。
具体实施方式:
21.下面结合附图和具体实施方式对本发明作进一步说明:
22.实施例
23.某设备输入1路数据,时钟频率624khz,位宽16bit,总帧数(通道数)96 个,数据输入顺序x1,x25,x49,x73,x2,x26,x50,x74...x24,x48,x72, x96;
24.数据处理输出为
25.通道1-24:ch1=(x1+x2)/2,ch2=(x3+x4)/2...ch24=(x47+x48)/2;
26.通道25-48:ch25=x49,ch26=x50...ch48=x72;
27.通道49-60:ch49=(x1+x2+x3+x4)/4,ch50=(x5+x6+x7+x8)/4... ch60=(x45+x46+x47+x48)/4;
28.通道61-72:ch61=(x49+x50)/2,ch62=(x51+x52)/2...ch72=(x71+x72)/2;
29.通道73-96:ch73=x73,ch74=x74...ch96=x96。
30.根据高带宽低时延fpga设计架构,数据先通过算法计算模块,再入存储模块。此例子将算法分为5类,每类算法设计计算单元。第1类算法是通道 ch1-ch24,计算单元包括一个加法器和一个移位器;第2类算法是通道 ch25-ch48,计算单元是一组寄存器;第3类算法是通道ch49-ch60,计算单元包括三个加法器和一个移位器;第4类算法是通道ch61-ch72,计算单元包括一个加法器和一个移位器;第5类算法是通道ch73-ch96,计算单元是一组寄存器。分类结束后,设计算法计算单元,并将计算结果写入存储模块。数据存储的关键问题为冲突管理。一种从输入数据的时间上进行管理,另一种则从输入数据的存储单元上进行管理。存储单元管理可以通过拼接ram的方式,其中包括位宽拼接和深度拼接。图2中(a)是深度拼接ram。输入为两组ram的写端口分别进行控制ram。读数据时,根据地址顺序自上而下读数据,即为先读ram1后读 ram2。图2中(b)是位宽拼接ram。输入控制与深度拼接ram一致,但是读数据时,根据地址顺序从ram1和ram2中各自读取,即为偶数地址读ram1奇数读ram2 顺序读取。根据5类算法时序图,具体如图3,第1类和第3类、第2类和第4 类需要同时写入ram,由此可以使用深度拼接ram的方式。第1类和第2类写入一个ram,第3类、第4类和第5类写入另一ram。因此本实例的冲突管理方式为存储单元管理,具体为单元深度拼接ram的方式。所有数据计算并写入存储单元,进行整帧输出,完成计算存储处理。
31.依照上述实施例,总结本方案处理流程,具体如图4,首先根据声信号处理的算法特点,进行算法归类。流水设计每类算法处理单元,完成对输入数据处理。然后算法处理模块计算并输出写ram使能、地址和数据。使用计数器对算法处理模块的输入数据进行计数(输入使能有效时计数,在一帧结束后清零计数器)。根据每类算法的数据规律,使用计数器将数据输入计算单元,并输出算法处理后的使能信号,地址信息以及数据。根据每类算法输出的使能信号,进行判断是否ram有写冲突。若ram无写冲突(输出使能信号均为不同时刻数据),则采用一个ram进行存储。若ram有写冲突,则判断算法分类的个数,根据算法类别个数多少结合两种写冲突管理模式,选择合适的写冲突管理模式。可以使用其中一种方式或者两种方式混合使用。
32.其中一种写冲突管理模式如下,通过分析每类算法的时序规律,将冲突的算法进行分类,并根据分类的类别数量选择对应数量的存储单元使用相同数量的ram进行存储,每一类算法存储分别控制一个ram读写,最后讲上述ram通过深度进行拼接输出。如果可以分为两类则将存储单元使用两个ram进行存储,每一类算法存储分别控制ram读写,最终两个ram通过深度进行拼接输出;如果可以分为四类则将存储单元使用四个ram进行存储,同时使用相同方法进行存储和拼接输出。ram拼接的方式有两种,一种是ram深度拼接,一种是ram宽度拼接。根据不同应用场景,选择不同的拼接模式。
33.对于数据存储冲突类别较少,可使用上述的冲突管理方式,但如果冲突类别较多,
上述方式会存在浪费bram资源的情况。
34.进一步的,本发明提出另一种写冲突管理模式,对读写使能和地址的冲突管理模式,具体如下,根据每类算法冲突时序,对于同时需要写入ram的时序,设定优先特定算法的原则,写入此算法数据至ram中,再延时写入后续算法地址的方式进行冲突管理。通过此方式保证ram没有读写冲突问题。所有数据写入ram之后,顺序读出ram数据,并输出计算完成数据。
35.本发明提出了一种高带宽低延时算法处理的fpga硬件实现方法,解决了基阵数据大数据带宽传输和时延,并且还具有特定的算法计算功能。本发明在计算架构上实现了边缘化计算方式,可以降低处理平台的计算压力,减少传输链路的数据带宽,本发明涉及的计算方法还具有实时性高,提升传输带宽,减少运算资源的优点。
36.以上仅就本发明较佳的实施例作了说明,但不能理解为是对权利要求的限制。凡是利用本发明说明书及附图内容所做的等效结构或等效流程变换,均包括在本发明的专利保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1