网络爬虫过滤方法及其设备与流程
1.本技术涉及网络爬虫技术,具体地,利用机器学习技术分析网页与网络爬虫目标的相似性来构建爬虫-过滤方法,以及实施该方法的信息处理设备。
背景技术:
2.随着互联网和移动互联网的飞速发展,产生了海量的数据。为了让用户能够快速和方便地在海量数据中查询和获取信息,以搜索引擎为代表的网络信息获取和检索技术,极大推进了信息的交流和共享进程。以谷歌、百度为代表的商业搜索引擎为例,根据一定的策略,运用特定的信息获取程序即网络爬虫(olston c and najork m.web crawling,foundations andin information retrieval:vol.4:no.3,pp 175-246.http://dx.doi.org/10.1561/1500000017),从整个互联网上搜集信息,建立网页数据库和目录(索引),为用户提供检索服务,并将用户搜索的相关的信息提供给用户。但是,在现阶段,传统商业搜索引擎无法在一个特定领域的提供精确搜索能力,随之出现垂直搜索引擎。垂直搜索引擎为用户提供的并不是上百万甚至上千万网页内容检索,而是提供在小的范围内,极具针对性的特定领域中查找信息的服务。
3.无论是商业搜索引擎海还是垂直搜索引擎,网络爬虫技术是搜索引擎技术的重要组成部分,可以在网络内容的海洋中,自动化寻找并存储网络页面,为“大海捞针”式的信息获取,提供数据基础。
4.图1展示了现有技术的网络爬虫的示意图。
5.网络爬虫是例如一个程序或自动化的脚本,是浏览、收集互联网信息的方式。提供一个或者一组待访问url(统一资源定位符,unified resource locator)(待访问)列表(也称为种子url)供爬虫处理。网络爬虫从待网文url列表中获取url,根据url下载网页,分析网页中的内容与网络资源(例如,图片、视频等)并建立索引,将索引与所下载网页和/或其网络资源相关联地记录在本地存储或网络存储系统中。从而为搜索引擎提供对索引的检索/查询等能力。所下载的网页中通常包括进一步的url,爬虫还从所下载网页中提起其包括的url加入待访问的url列表,以供进一步爬取处理。网络爬虫的目标是要在最短时间收集最多的网页资料。
6.网络爬虫程序有多种类型:
7.(1)通用网络爬虫
8.通用网络爬虫不限于特定主题或领域的网页。他们不断地关注超链接并获取他们遇到的所有网页。
9.(2)用户兴趣爬虫
10.用户兴趣爬虫优先考虑用户的兴趣,给url进行有优先级排序。这类网络爬虫并不会抓取它们遇到的所有链接,而是根据用户提交一个条件或感兴趣的主题,指导优先爬行器有选择地寻找,找出与预定义的主题集相关的网页。
11.(3)隐藏内容爬虫
transformers for language understanding.corr,abs/1810.04805,pages 770
–
778.)已经在自然语言处理中的各大任务中表现非常优异。bert模型能够处理输入的句子,并输出该句子的向量化表示(称为句向量),并且所生成的句向量能够表达句子语音的相似性,具有相近语义的句子,所生成的句向量在向量空间中具有较近的距离。
24.现有技术的图片向量化技术,用于将图片转换为易于被计算机处理的向量。并且,图片向量化技术所生成的向量能够表达图片内容的相似性。具有相似内容图片,被转换为向量后,在向量空间中具有较近的距离。图片向量化表示的思路是使用大型图片数据集(例如imagenet(deng j,dong w,socher r,li l-j,li k,and fei-fei l.2009.imagenet:a large-scale hierarchical image database.page 248
–
255.))来训练深度神经网络得到图片分类模型。然后,使用不含最后的分类器部分的层,提取对应于输入图片的特征向量。所得到的特征向量可以在搜索或相似度匹配任务中有效地表示图片。
25.图3a与图3b展示了图片向量化技术的示意图。
26.经过训练的深度神经网络处理输入的图片,其输出层神经元输出例如图片的分类结果。而利用隐藏层的若干神经元的输出,组合或拼接得到的向量,作为对输入图片向量化所得到的图片向量。这种图片向量反应了图片的内容。在图3a的例子中,选择隐藏层的连接到输出层的多个神经元的输出来构成图片向量。可选地,选择隐藏层的其他一个或多个神经元的输出来构成代表输入到深度神经网络的图片的图片向量。
27.在图3b的例子中,利用经典的图片分类网络vggnet(karen simonyan and andrew zisserman(2014):very deep convolutional networks for large-scale image recognition.arxiv:1409.1556[cs](september 2014).)获取图片向量。vggnet网络包括依次连接的多个卷积层、池化层与全连接层。在用vggnet网络处理输入的图片时,选择全连接层紧前的池化层的输出作为该图片的图片向量,该图片向量具有例如7*7*512维度。
技术实现要素:
[0028]
但是,在现有的网络爬虫技术面临以下挑战:
[0029]
(1)网页内容数据结构复杂网页内容包含大量半结构化和非结构化数据(文字、图片、视频),对于数据的收集、分析、爬取存在一定困难。
[0030]
(2)网络爬虫规模难易控制
[0031]
对于网络内容获取的规模无法提前估计,由于资源的限制,需要在内容爬取覆盖范围和数据库新鲜度之间进行权衡。网络内容爬取爬虫需要绕过无关的和低质量的内容。
[0032]
(3)网页内容理解能力不足
[0033]
网页之间是通过url进行关联,下一步需要访问的网络资源是否与内容主题相关,缺少分析和判断,对于网页内容理解不足。
[0034]
为了解决上述一个或多个技术问题并获得上述一个或多个技术效果,提供了根据本技术的多种实施例。
[0035]
根据本技术的第一方面,提供了根据本技术第一方面的第一网络爬虫爬取网络的方法,包括:从url缓存获取第一类url,爬取第一类url对应的网页并提取一个或多个第二类url添加到预加载缓存;从预加载缓存获取第二类url,预加载第二类url对应的网页并根据预加载的第二类url对应的网页生成网页向量;若生成的网页向量同根据爬取目标生成
的目标向量的距离小于指定阈值,将所述第二类url作为第一类url添加到所述url缓存。
[0036]
根据本技术第一方面的第一网络爬虫爬取网络的方法,提供了根据本技术第一方面的第二网络爬虫爬取网络的方法,还包括:若生成的网页向量同根据爬取目标生成的目标向量的距离不小于指定阈值,将被预加载的所述第二类url,而不将其作为第一类url添加到所述url缓存。
[0037]
根据本技术第一方面的第一或第二网络爬虫爬取网络的方法,提供了根据本技术第一方面的第三网络爬虫爬取网络的方法,其中响应于url缓存中存在第一类url,重复执行所述网络爬虫爬取网络的方法;响应于预加载缓存中存在第二类url,重复执行所述从预加载缓存获取第二类url,预加载第二类url对应的网页并根据预加载的第二类url对应的网页生成网页向量的步骤,以及若生成的网页向量同根据爬取目标生成的目标向量的距离小于指定阈值,将所述第二类url作为第一类url添加到所述url缓存的步骤。
[0038]
根据本技术第一方面的第一或第二网络爬虫爬取网络的方法,提供了根据本技术第一方面的第四网络爬虫爬取网络的方法,还包括:获取url种子并添加到所述url缓存;以及获取爬取目标并生成目标向量,其中,将爬取目标的一个或多个词和/或一个或多个句子的文本向量化生成目标向量,和/或将爬取目标的一个或多个图片输入深度神经网络,并从深度神经网络的非输入层也非输出层的中间层神经元获取输出生成图片向量作为目标向量。
[0039]
根据本技术第一方面的第四网络爬虫爬取网络的方法,提供了根据本技术第一方面的第五网络爬虫爬取网络的方法,其中预加载第二类url对应的网页并根据预加载的第二类url对应的网页生成网页向量,包括:从预加载的第二类url对应的网页中提取一个或多个文本块;根据所述一个或多个文本块的每个计算文本块的向量;计算所述所述一个或多个文本块的每个文本块的向量的统计值,作为预加载的第二类url对应的网页的网页文本内容向量;从预加载的第二类url对应的网页中提取一个或多个图片;根据所述一个或多个图片的每个计算图片向量;计算所述一个或多个图片的每个的图片向量的统计值,作为预加载的第二类url对应的网页的网页图片内容向量;根据所述网页文本内容向量与所述网页图片内容向量得到所述预加载的第二类url对应的网页的网页向量。
[0040]
根据本技术第一方面的第五网络爬虫爬取网络的方法,提供了根据本技术第一方面的第六网络爬虫爬取网络的方法,其中文本块包括一个或多个句子;所述根据所述一个或多个文本块的每个计算文本块的向量,包括:对于所述根据所述一个或多个文本块的每个文本块,获取构成当前文本块的一个或多个句子;将所述一个或多个句子的每个输入给bert模型实例,以得到同输入的句子对应的句向量;计算所述一个或多个句子的每个的句向量的统计值,作为当前文本块的向量。
[0041]
根据本技术第一方面的第六网络爬虫爬取网络的方法,提供了根据本技术第一方面的第七网络爬虫爬取网络的方法,其中将所述根据所述一个或多个文本块的第i个文本块bi所对应的向量记为v
bi
,bi=(si1,si2,
…
,sij,
…
,sini)表示文本块bi包括多个句子,句子sij是文本块bi的第j个句子,句子sij的句向量记为v
sij
,ni是文本块bi中包括的句子数量,ni、i与j为正整数1《=j《=ni。
[0042]
根据本技术第一方面的第七网络爬虫爬取网络的方法,提供了根据本技术第一方
面的第八网络爬虫爬取网络的方法,其中将所述预加载的第二类url对应的网页的网页文本内容向量记为p
text
,其中n是所述预加载的第二类url对应的网页中的文本块数量,n是正整数,1《=i《=n。
[0043]
根据本技术第一方面的第八网络爬虫爬取网络的方法,提供了根据本技术第一方面的第九网络爬虫爬取网络的方法,其中将所述预加载的第二类url对应的网页的网页图片内容向量记为p
image
,其中m是所述预加载的第二类url对应的网页中的图片数量,m是正整数,vi
p
是所述预加载的第二类url对应的网页中的第p个图片的图片向量,其中p是正整数,1《=p《=m;以及其中所述预加载的第二类url对应的网页的网页向量v
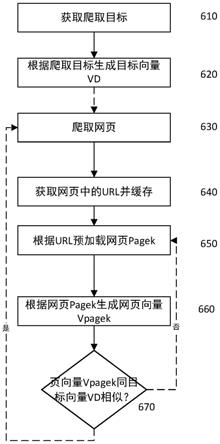
page
=(p
text
,p
image
);或者所述预加载的第二类url对应的网页的网页向量v
page
=p
text
+p
image
。
[0044]
根据本技术的第二方面,提供了根据本技术第二方面的第一信息处理设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的程序,其特征在于,所述处理器执行所述程序时实现根据本技术第一方面的第一至第九网络爬虫爬取网络的方法之一。
附图说明
[0045]
当连同附图阅读时,通过参考后面对示出性的实施例的详细描述,将最佳地理解本技术以及优选的使用模式和其进一步的目的和优点,其中附图包括:
[0046]
图1展示了现有技术的网络爬虫的示意图。
[0047]
图2展示了现有技术的深度神经网络结构的示意图。
[0048]
图3a与图3b展示了图片向量化技术的示意图。
[0049]
图4展示了根据本技术实施例的计算句子相似度的流程图。
[0050]
图5a展示了计算网页文本内容向量的流程图。图5b展示了计算网页图片内容向量的流程图。
[0051]
图6是根据本技术实施例的网络爬虫爬取网络数据的流程图。
具体实施方式
[0052]
下面详细描述本技术的实施例,所述实施例的示例在附图中示出,其中自始至终相同或类似的标号表示相同或类似的元件或具有相同或类似功能的元件。下面通过参考附图描述的实施例是示例性的,仅用于解释本技术,而不能解释为对本技术的限制。
[0053]
图4展示了根据本技术实施例的计算句子相似度的流程图。句子相似度是根据本技术实施例中,网络爬虫理解并过滤待爬取的url的基础。
[0054]
参看图4,通过利用例如bert模型的经过预训练的深度神经网络模型处理句子,以将句子转换为句向量。句子是例如爬虫从网页的文本中获取的句子。为比较两个句子(记为句子a与句子b),提供两个经过预训练的bert模型的实例(这两个bert模型的实例可经由相同或不同的预训练过程得到,并具有相同或不同的模型参数),将句子a与句子b分别输入对应的bert模型实例,从bert模型实例的输出得到同句子a对应的句向量u以及同句子b对应的句向量v。计算句向量u与句向量v的距离,作为句子a与句子b的相似度。可以理解地,在图4的例子中,句向量u与句向量v的距离越小,代表句子a与句子b的相似度越大。
[0055]
本领域技术人员将理解,可利用其他现有技术或将来产生的深度神经网络技术或其他自然语言处理技术来获取句子之间的相似度,而不限于使用bert模型。
[0056]
根据本技术的实施例,还提供根据网页生成网页向量的方法(也称为page2vec算法)。网页通常包括文本与图片。根据本技术的实施例,网页向量由网页文字内容向量与网页图片内容向量组合得到。图5a展示了计算网页文本内容向量的流程图。图5b展示了计算网页图片内容向量的流程图。
[0057]
网页的文本内容通常包括多个部分,例如,由html(超文本标记语言)的“《head》”标签所标记的头部,由“《body》”标签所标记的正文部分,类似地,“《iframe》”、“《div》”等标签也通常标记了带有文本内容的区域。一般地,将网页的文本内容视作由多个文本块组成。通过例如html的标签识别文本块。依然作为举例,将网页中的文本的各段落作为文本块。将网页中的第i个文本块记作bi,i是正整数。
[0058]
文本块由一个或多个句子组成。一般地,文本块bi=(s1,s2,
…
,sn),表示文本块bi包括n个句子,n为正整数,其中sj代表该文本块中的第j个句子,1《=j《=n。将文本块bi所对应的向量记为v
bi
,句子sj的句向量记为v
sj
,根据本技术的实施例,即文本块的向量为该文本块所包括的所有句子的句向量的平均值。
[0059]
将网页page的网页内容向量记为p
text
。网页page包括n个文本块,记为page=(b1,b2,
…
,bn),其中bi代表网页page中的第i个文本块,1《=i《=n。根据本技术的实施例,即网页内容向量为该网页所包括的所有文本块的向量的平均值。
[0060]
参看图5a,为生成网页page的网页文本内容向量(p
text
),从网页page中提取一个或多个文本块(bi)(510)。为计算文本块bi的向量v
bi
,从文本块bk中提取句子sj(520),以及计算所提取句子sj的句向量v
sj
(530)。
[0061]
文本块bi包括一个或多个句子。根据本文块bi所包括的一个或多个句子的句向量生成该文本块的向量v
bi
(540)。例如,通过将文本块bi的所有句子的句向量的平均值作为文本块的向量,还通过计算每个句子sj的向量v
sj
的和、加权平均值或其他统计值来得到文本块bi的向量v
bi
。
[0062]
根据网页page所包括的一个或多个文本块的向量,生成该网页的网页文本内容向量(p
text
)(550)。例如通过计算每个文本块bi的向量v
bi
的平均值来得到网页文本内容向量(p
text
)。可选地,通过计算每个文本块bi的向量v
bi
的和、加权平均值或其他统计值来得到网页文本内容向量(p
text
)。
[0063]
在可选的实施方式中,位于网页不同位置的文本块,在计算网页文本内容向量时具有各自的权重。例如,位于网页中央的文本块具有相对高的权重,而位于网页头部/标题栏的文本块也具有相对高的权重,而位于网页的页脚或侧边的文本块则具有相对低的权重。
[0064]
网页通常也包括图片。通过html的例如“《img》”标签识别网页中的图片。所属领域技术人员也熟知其他从网页中获取图片的方法。
[0065]
根据本技术的实施例,利用网页所包括的图片的图片向量(记为vi)生成网页图片内容向量(p
image
)。作为举例,将网页所包括的所有图片的图片向量(vi)的平均值作为该网
页的网页图片内容向量(p
image
),其中m是正整数,代表网页中的图片数量,vi
p
代表网页中第p个图片的图片向量,1《=p《=m,p是正整数。
[0066]
可选地,通过计算网页的一个、多个或全部图片的图片向量(vi)的和、加权平均值或其他统计值来得到该网页的网页图片内容向量(p
image
)。
[0067]
在依然可选的实施方式中,位于网页不同位置的图片,在计算网页图片内容向量时具有各自的权重。例如,位于网页中央的图片具有相对高的权重,而位于网页头部/标题栏的图片也具有相对高的权重,而位于网页的页脚或侧边的图片则具有相对低的权重。
[0068]
参看图5b,为生成网页page的网页图片内容向量(p
image
),从网页page中提取一个或多个图片(560)。计算提取的每个图片的图片向量(vi)(570)。通过例如图3a或图3b展示的方法或现有技术的其他方法根据图片生成图片向量(vi)。根据提取的所有图片计算网页page的图片内容向量(580)。
[0069]
根据本技术的实施例,根据从网页page中获得的网页文本内容向量(p
text
)与网页图片内容向量(p
image
),生成网页向量(记为v
page
)。作为一个例子,连接网页文本内容向量(p
text
)与网页图片内容向量(p
image
)得到网页向量(v
page
=(p
text
,p
image
)),作为又一个例子,网页文本内容向量(p
text
)与网页图片内容向量(p
image
)相加得到网页向量(v
page
=p
text
+p
image
)。
[0070]
进一步地,根据本技术的实施例,通过计算两个网页向量的距离来评估对应的两个网页的相似度。两个网页向量的距离越小,代表这两个网页向量所代表的网页的相似度越高。
[0071]
图6是根据本技术实施例的网络爬虫爬取网络数据的流程图。
[0072]
为了提高网络爬虫的收获率(hr,harvest ratio)(behl a banati h thukral a,mendiratta v.2011.a social semantic focused crawler.pages 273
–
283.),降低海量网页与多样化的网页内容对网络爬虫爬取结果的干扰,根据本技术实施例的网络爬虫,在爬取网页期间,对从网页提取出的待爬取url进行过滤,只选取网络爬虫感兴趣的网页进行爬取,而不爬取同爬取目标无关的网页。网络爬虫感兴趣的网页是同爬取目标相似度较高的网页。
[0073]
作为举例,收获率被认为是满足要求的网页抓取的比例。具体定义是:hr=r/p,hr∈(0,1),r是爬取到的同爬取目标相关的网页的数量,p是爬取的所有网页的数量。从而hr表示在爬取到的全部网页中同爬取目标相关的网页的占比,其大小反映了网络爬虫的爬取效果。
[0074]
进一步地,由于网页中内容与url混合在一起,对网页的爬取过程涉及识别网页内容,建议索引、网页地址和/或网页快照等资源的记录信息,引入了计算与存储资源的开销。因而希望在爬虫爬取网页之前识别网页同爬取目标的相似度。为此目的,还引入了根据从网页中获取的url对应的进一步网页的预加载机制。在对网页的预加载过程中,仅识别预加载的网页与爬取目标的相似度而不对网页进行分析、建立索引等操作,从而网页预加载过程的计算、存储、功耗、时间等开销小于对网页的爬取过程。
[0075]
参看图6,根据本技术实施例的网络爬虫,获取爬取目标(610),根据给定的爬取目标与种子url开启爬取过程。爬取目标是例如一个或多个主题词(例如,足球、购物),一个或
computer science),在不同初始种子url下,按照不同目标爬取目标进行网页爬取,每个目标爬取1000个网页,并计算收获率(hr)。
[0083]
(1)初始url种子
[0084]
分别选取腾讯(www.qq.com)和新浪(www.sina.com.cn)作为url种子。
[0085]
(2)爬取目标
[0086]
分别选取“购物”、“足球”两个爬取目标。
[0087]
下表1是选择腾讯(www.qq.com)作为初始url种子页。分别对“购物”和“足球两个爬取目标进行爬取的结果。表格中,hr指标代表收获率。
[0088][0089]
表1
[0090]
下表2是选择新浪讯(www.sina.com.cn)作为初始url种子页。分别对“购物”和“足球两个爬取目标进行爬取的结果。
[0091][0092]
表2
[0093]
通过比对本技术实施例的网络爬虫、focus算法和url过滤算法在不同url种子和爬取目标下的收获率结果,很明显看到,本技术实施例的网络爬虫的hr结果高于其他算法。
[0094]
虽然当前申请参考的示例被描述,其只是为了解释的目的而不是对本技术的限制,对实施方式的改变,增加和/或删除可以被做出而不脱离本技术的范围。
[0095]
这些实施方式所涉及的、从上面描述和相关联的附图中呈现的教导获益的领域中的技术人员将认识到这里记载的本技术的很多修改和其他实施方式。因此,应该理解,本技术不限于公开的具体实施方式,旨在将修改和其他实施方式包括在所附权利要求书的范围内。尽管在这里采用了特定的术语,但是仅在一般意义和描述意义上使用它们并且不是为了限制的目的而使用。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1