一种基于三维虚拟地理场景的单目相机目标检测与空间定位方法与流程
1.本发明涉及三维目标检测与空间定位技术领域,具体涉及一种基于三维虚拟地理场景的单目相机目标检测与空间定位方法。
背景技术:
2.智慧城市、感知国土、时空信息云平台等智能化地理空间应用快速建设,促进人工智能技术与地理应用深度结合,其中,三维目标检测与空间定位成为重要的方向。而传统三维目标检测的各种方法主要依赖于深度相机或多目视觉,对硬件条件要求高,难以推广到智慧城市、感知国土、时空信息云平台应用中。如何在单目相机条件下检测目标对象并计算出其地理空间坐标,其很大程度上约束了目标检测算法走向智能地理空间分析和应用。现有三维目标检测与空间定位均需依赖多目相机或雷达点云,已获得目标对象的深度信息,从而实现定位计算,该方式对硬件条件具有较高要求,难以适用于集成单目相机实现三维目标检测和空间定位应用,如:智慧城市系统中依托交管摄像头定位过境车辆位置。随着三维地理信息技术的发展,物理世界已逐步可以采用三维地理场景孪生表达,即得到了三维虚拟地理场景。在三维虚拟地理场景中,可以模拟真实物理世界的地形、地貌、建筑特征,并具有多lod特征。三维虚拟地理场景是一种新的信息源,其为突破单目相机无法实现目标对象的空间定位难点问题,提供了新理念,其可近似克服视深信息无法计算的难题。通过三维虚拟地理场景中目标检测与空间定位方法,实现人工智能目标检测技术、三维地理信息技术、视频监控技术三者结合应用,突破单目相机无法实现目标对象的空间定位难点问题,可有效解决现有智慧城市、感知国土、时空信息云平台等智能化地理空间应用目标对象“定位难”问题,具有巨大的实用价值。
技术实现要素:
3.1、解决的技术问题
4.本发明的为了解决三维虚拟地理场景中的目标检测与空间定位问题,本发明提供一种基于三维虚拟地理场景的单目相机目标检测与空间定位方法,该方法首先通过三维虚拟地理场景和实时监控视频画面构建实景融合场景展示,获取实景融合的场景图像,然后基于深度学习模型进行实景融合图像的目标检测,获取检测目标的像素值,最后根据目标像素值利用三维虚拟地理场景的地理空间坐标解算方法实现像素坐标到地理空间坐标的转换。
5.2、技术方案
6.为实现以上目的,本发明通过以下技术方案予以实现:
7.一种基于三维虚拟地理场景的单目相机目标检测与空间定位方法,包括如下步骤:
8.1、基于三维虚拟地理场景构建实景融合,实现视频与三维场景融合展示。
9.(1)室外场景建模,根据所需的dem数据、影像数据和建筑物模型数据构建大范围的虚拟三维场景,室内模型构建,利用室内不动产测绘数据,建立起3dmax模型,同时基于激光扫描技术,构建室内激光点云模型,根据激光点云对室内模型的精度进行调整,构建高精度的室内三维虚拟场景。
10.(2)在三维场景中的三维场景虚拟相机具有内方位元素和外方位元素,其中内方位元素通常是已知的,而外方位元素需要进行标定。通过视频画面与三维场景画面在视场角一致的情况下进行特征匹配,获得三维场景虚拟相机的外方位元素,同时根据三维虚拟相机在三维场景中的位置实现相机的标定。通过标定的虚拟相机外方位元素,初始化虚拟相机。
11.(3)通过监控设备厂商提供的实时rtsp视频流,进行视频流解帧,获取不同时间段的视频帧图像。将图像按照三维虚拟场景当前的相机姿态进行投射,实现视频与三维场景融合,包括基于地形影像和基于三维模型场景的实景融合画面,最后通过场景出图,获取含目标物的视频与三维场景融合的图像作为目标检测模型的输入数据。
12.2、基于深度学习模型进行含视频的实景融合图像的目标检测,获取检测目标的像素值。
13.(1)定义目标检测的样本,需要对研究对象及其分类进行明确阐述,对其识别规则进行分析和整理,形成对研究对象的统一认识。首先需要确定检测目标的类型,规定其为正样本数据,同时采集大量与检测目标相近或相反的图像,通过进行种类的划定,确定负样本数据。
14.(2)训练样本数据预处理,解决数据格式不一致或不满足需求、数据噪声大、数据可信度差、数据质量低、数据命名混乱等问题。
15.①
数据标准化:输入到深度卷积神经网络中进行训练的样本数据常常是海量数据,可能存在由于采集时间不同、方式不同或者路径不同等带来的各种各样的问题,无疑就会对后续训练产生影响,因此在剔除错误数据的基础上,需要统一组织和管理数据,对批量的样本图像进行统一标准化处理,明确数据的属性信息。
16.②
数据降噪:数据最终是以标签的形式输入到网络中的,这些标签一般由大量的人工进行采集,除了错打的现象外,不可能进行逐个检查并进行校正,然而这些标签的质量对模型学习的效果至关重要,但也是必须要面对的噪音之一。
17.③
数据增强:为了防止由于数据规模有限导致的模型训练过程中样本不收敛或者训练生成的模型识别能力差等问题,可以采用深度学习领域常用的数据增强方法,在已有数据的基础上进行样本扩增,常用方法是对原图进行翻转变换、随机修剪、色彩抖动、平移变换、尺度变换等操作。
18.④
数据归一化:数据归一化就是将训练数据集中某一列数值特征的值缩放到0和1之间,其目的是让不同维度之间的特征在数值上有一定比较性,同时加快梯度下降求最优解的速度,大大提高分类的准确性。
19.⑤
标签采集:不同的深度学习模型在训练时输入网络的数据格式有所不同。yolo模型训练时需要输入的数据是image(原始图像)和 annotation(图像标签),分别对应图像格式和xml文件格式,且一一对应,通过人工采集标签的方式获得。
20.(3)目标检测模型训练,使用tensorflow深度学习开发框架,构建darkflow地理目
标识别与空间定位系统,其中地理目标识别阶段主要基于主流目标识别模型yolo训练获得。
21.模型训练的过程中需要不断调整模型网络的参数,而参数的调整依据主要是模型训练过程输出的一些参数。在一个批次的训练结束之后,yolo模型根据该批次的所有训练情况进行综合分析,获得这一批次后的综合训练结果。模型训练的过程需要大量的时间,为了尽快实现模型的收敛,同时防止训练过度,根据上述模型训练过程的输出参数,需要及时对网络中重要参数进行调整,重要参数及其调整策略归纳如下:
22.①
学习率(learning rate):学习率结合梯度下降算法主要用于实现模型的快速收敛,训练发散的情况下可以适当降低学习率。
23.②
批量(batch):每一次迭代送到网络的图片数量,叫做批量。该参数使网络以较少的迭代次数完成一轮预测。在固定最大迭代次数的前提下,batch值增大会延长训练时间,但能够更好地寻找到模型梯度下降的方向。增大batch虽然有利于提高内存利用率,但也因此会出现显存不够的问题。显存允许的情况下,如果训练过程出现nan 错误提示,可以适当增加batch大小,同时调整动量参数为0.99。通常该值的选取需要反复试验,过大或过小都不利于模型的有效训练,过小时容易训练不收敛,过大时则会陷入局部最优。
24.③
细分(subdivision):subdivision和batch通常成对出现,使得每一个批量的图片首先分成subdivision份数,然后一份一份的送入网络运行,最后将所有份一起打包整合为一次迭代。这样有利于降低对显存的占用。
25.④
学习策略(step,scales):step表示训练步数,scales表示学习率变化的比率,二者组合使用。
26.⑤
随机参数(random):random的可选值有1和0,代表一个开关。该值设置为1时,模型在训练的时候每一批量的图片会随机调整为320-640(32整倍数)尺寸的图片输入到模型中,设置为0则表明所有图片调整为默认尺寸输入网络。
27.(4)使用模型进行目标检测并输出结果,将视频图像的输入到训练好的模型进行目标检测,使用不同颜色的矩形框对检测到的目标物进行标识,并计算矩形框的四条边的像素值范围,最后将标识后的图像和像素值作为结果返回。
28.3、基于三维虚拟地理场景的地理空间坐标解算方法实现像素坐标到地理空间坐标的转换。
29.(1)求解逆透视变换矩阵
30.①
定义坐标系。立体视觉等方向常常涉及到四个坐标系:世界坐标系、相机坐标系、图像坐标系、像素坐标系。
31.②
像素坐标系转换至图像坐标系。像素坐标系和图像坐标系都在成像平面上,只是各自的原点和度量单位不一样。图像坐标系的原点为相机光轴与成像平面的交点。图像坐标系的单位是mm,属于物理单位,而像素坐标系的单位是pixel,我们平常描述一个像素点都是几行几列,dx和dy表示每一列和每一行分别代表多少mm,即1pixel=dx mm。
32.③
图像坐标系转换至相机坐标系。相机坐标系到图像坐标系属于透视投影关系,从2d到3d。此时投影点p的单位还是mm,并不是 pixel,需要进一步转换到像素坐标系。
33.④
相机坐标系转换至世界坐标系。相机坐标系到世界坐标系,即 o
c-xcyczc→ow-x
wywzw
,属于刚体变换,即物体不会发生形变,只需要通过旋转矩阵r和偏移向量t进行转换。
34.以上四个步骤,得到从世界坐标系到像素坐标系的总公式为:
[0035][0036]
旋转矩阵r为:
[0037][0038]
偏移向量t为:
[0039][0040]
(2)根据逆透视变换矩阵,结合目标检测结果的像素值和构建三维实景融合场景获取的虚拟相机外参解算目标点的世界坐标,即为目标点的地理空间坐标。
附图说明
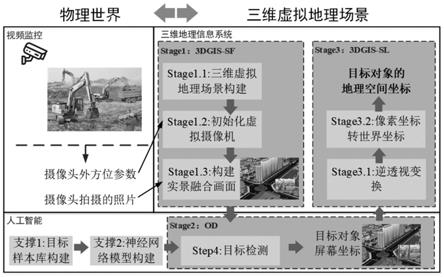
[0041]
图1为本发明技术流程图。
[0042]
图2为本发明中目标检测与空间定位的示意图。
[0043]
图3为本发明中虚拟相机外方位线元素示意图。
[0044]
图4为本发明中视频在三维场景中的投射示意图。
[0045]
图5为本发明中标准化后样本数据命名规范。
[0046]
图6为本发明中基于yolo的目标检测原理图。
[0047]
图7为本发明中基于逆透视变换的坐标系转换示意图。
[0048]
图8为本发明中坐标轴旋转变换示意图。
[0049]
图9为本发明中基于单目相机的目标检测与空间定位效果图。
具体实施方式
[0050]
为使本发明的实施目的、技术方案和优点更加清楚,下面将结合本发明实施方式中的附图,对本发明实施方式中的技术方案进行清楚、完整地描述,显然,所描述的实施方式是本发明一部分实施方式,而不是全部的实施方式。基于本发明中的实施方式,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0051]
结合技术流程图,一种基于三维虚拟地理场景的单目相机目标检测与空间定位方法,包括如下步骤:
[0052]
1、三维场景中的目标检测和空间定位属于三维重构领域,它的理论与技术是计算
机视觉最重要的热点问题之一,基于单幅图像的三维重构由于缺乏足够的几何信息而难以达到预期效果,因此本文通过构建三维模型与真实视频画面融合的三维虚拟场景提供单幅图像的几何信息。
[0053]
(1)三维虚拟场景构建包括地形和模型,针对室外场景,根据所需的dem数据、影像数据和建筑物模型数据构建大范围的虚拟三维场景,室内模型构建,利用室内不动产测绘数据,建立起3dmax 模型,同时基于激光扫描技术,构建室内激光点云模型,根据激光点云对室内模型的精度进行调整,构建高精度的室内三维虚拟场景。
[0054]
(2)在三维场景中的三维场景虚拟相机具有内方位元素和外方位元素,其中内方位元素通常是已知的,而外方位元素需要进行标定。外方位元素则主要面向摄影像片与物方空间坐标系之间的方位关系。确定摄像机在摄影瞬间连同成像平面在内的相关坐标系与物方空间坐标系形成的几何关系数据,叫做像片的外方位元素。像片的外方位元素分线元素和角元素,总共有6个。线元素即摄像机摄影中心的物方空间坐标,一般定义为(xs,ys,zs)(图3)。另外3个是角元素,用以确定像片在物方空间坐标系中的姿态。典型的用来表达像片角定向的方式有三种:a-v-κ转角系统、转角系统、转角系统。通过视频画面与三维场景画面在视场角一致的情况下进行特征匹配,获得三维场景虚拟相机的外方位元素,同时根据三维虚拟相机在三维场景中的位置进行相机的标定。同时通过标定的虚拟相机外方位元素,初始化虚拟相机,获取相机的真实姿态。
[0055]
(3)通过监控设备厂商提供的实时rtsp视频流,进行视频流解帧,获取不同时间段的视频帧图像。将图像按照三维虚拟场景当前的相机姿态进行投射,实现视频与三维场景融合(如图4),包括基于地形影像和基于三维模型场景的实景融合画面。基于地形影像的融合通过影像和视频的明显特征进行匹配,获得视频贴地面的融合效果。基于三维模型场景的融合是根据视频与场景中的模型进行贴合,获得视频贴模型的融合效果,最后通过场景出图,获取含目标物的视频与三维场景融合的图像作为目标检测模型的输入数据。
[0056]
2、基于深度学习模型进行含视频的实景融合图像的目标检测,获取检测目标的像素值,在对图像数据进行标签采集之前,首先需要对研究对象及其分类进行明确阐述,对其识别规则进行分析和整理,形成对研究对象的统一认识。通过获取的图像数据,划分正负样本,同时对正样本进行了详细的特征描述。
[0057]
(1)正负样本定义
[0058]
模型检测性能最直接相关的因素是样本定义,即首先需要对识别的目标进行正负样本的界定,使打标签人员对采集的目标有统一的认识,减少采集误差。首先需要确定检测目标的类型,规定其为正样本,同时采集大量与检测目标相近或相反的图像,通过进行种类的划定,并确定其为负样本。对采集的数据进行了标签数量的估计,判断是否达到了模型训练收敛的规模。
[0059]
(2)训练样本数据预处理
[0060]
训练样本的规模及多样性是影响卷积神经网络模型识别精度的重要因素,为了基于yolo算法训练出能够准确检测并识别图像中确定目标的深度学习模型,需要对训练样本数据进行预处理。数据预处理(data preprocessing)是任意一种对原始数据进行某些操作,用来为下一个步骤做准备的处理过程。根据经验,原始数据存在的问题一般有:数据格式不一致或不满足需求、数据噪声大、数据可信度差、数据质量低、数据命名混乱等。因此,
利用深度学习领域的数据预处理方法,对样本数据作了如下预处理:
[0061]
①
数据标准化:输入到深度卷积神经网络中进行训练的样本数据常常是海量数据,可能存在由于采集时间不同、方式不同或者路径不同等带来的各种各样的问题,无疑就会对后续训练产生影响,因此在剔除错误数据的基础上,需要统一组织和管理数据,对批量的样本图像进行统一标准化处理,明确数据的属性信息。标准化后的数据格式为jpg、通道数为3、位深度24、数据规范命名如图5所示(xml文件名与jpg命名对应),能够被神经网络有效访问。
[0062]
②
数据降噪:数据最终是以标签的形式输入到网络中的,这些标签一般由大量的人工进行采集,除了错打的现象外,不可能进行逐个检查并进行校正,然而这些标签的质量对模型学习的效果至关重要,但也是必须要面对的噪音之一。
[0063]
③
数据增强:为了防止由于数据规模有限导致的模型训练过程中样本不收敛或者训练生成的模型识别能力差等问题,可以采用深度学习领域常用的数据增强方法,在已有数据的基础上进行样本扩增,常用方法是对原图进行翻转变换、随机修剪、色彩抖动、平移变换、尺度变换等操作。
[0064]
④
数据归一化:数据归一化就是将训练数据集中某一列数值特征的值缩放到0和1之间,其目的是让不同维度之间的特征在数值上有一定比较性,同时加快梯度下降求最优解的速度,大大提高分类的准确性。本次在数据标签采集完毕后,训练深度学习模型之前,将原有的矩形框中心点的表示形式(xc,yc,w,h)归一化至0-1之间。假设一个建设施工用地的识别框的左上角和右下角坐标分别为(x1,y1)、(x2,y2),图像的宽和高分别为w、h,则归一化内容有:
[0065]
归一化中心点xc坐标计算公式:((x2+x1)/2.0)/w
[0066]
归一化中心点yc坐标计算公式:((y2+y1)/2.0)/h
[0067]
归一化目标框宽度的计算公式:(x
2-x1)/w
[0068]
归一化目标框高度计算公式:(y
2-y1)/h
[0069]
(5)标签采集:不同的深度学习模型在训练时输入网络的数据格式有所不同。yolo模型训练时需要输入的数据是image(原始图像)和annotation(图像标签),分别对应图像格式和xml文件格式,且一一对应,通过人工采集标签的方式获得。本次人工标签采集主要是根据上述已经明确的建设施工用地示例进行目标的采集,对规模数据的每一张图像采用labelimg工具提取出真实目标信息,即获得建设施工用地目标或挖掘机目标的矩形框左上角和右下角像素坐标,同时标示出目标的类别,最终获得每个图像对应的xml文件,内容示例如表1。
[0070]
表1模型训练输出参数
[0071][0072]
(3)目标检测模型训练
[0073]
使用tensorflow深度学习开发框架,构建darkflow地理目标识别与空间定位系统。其中地理目标识别阶段主要基于主流目标识别模型 yolo训练获得(如图6)。在训练建设施工用地模型时,需要输入的参数包括网络结构、初始权重和训练样本文件,命令如下:
[0074]
python flow
‑‑
model cfg\yolo-2c.cfg
‑‑
load bin\yolo.weights
‑‑
train
ꢀ‑‑
gpu 1.0
–
dataset.\training\images
‑‑
annotation.\training\annotation
[0075]
flow是模型训练的程序入口,gpu的启用参数是1.0,dataset和 annotation分别用于加载预处理后的监控图像数据和采集标签得到的 xml数据,model用于加载模型网络,load用于加载初始训练权重。
[0076]
在识别目标的种类(2个)和类型定义(construction、excavator) 明确的基础上,需要根据需求修改yolo模型的部分网络参数,将网络构建中的类型数目(classes)和输出的结果数(filters)根据模型训练前已经定义的标签类别重新赋值,模型训练时还需要读取定义好的标签文件,因此,需要将标签在labels.txt标签文件中进行更改。模型训练时,为了使模型尽快收敛,一般赋予模型一个初始权重,该初始权重可以根据网络的版本从
yolo官方网站进行获取。
[0077]
模型训练的过程中需要不断调整模型网络的参数,而参数的调整依据主要是模型训练过程输出的一些参数。在一个批次的训练结束之后,yolo模型根据该批次的所有训练情况进行综合分析,获得这一批次后的综合训练结果,例如训练过程的一条语句为:
[0078]
17889:0.457854,0.432366avg,0.000100rate,2.545074seconds, 468640images
[0079]
该语句中的参数及其含义如表2。语句中包含的loss和avg loss 是对训练过程中预测到的中心点坐标、边界框宽高、识别置信度 (confidence score)及目标识别类型的信息损失进行综合计算获得的值,分别称为损失函数和平均损失函数。二者可以作为分析本次训练效果最重要的参数,其值均越小越好,一般认为平均损失函数低于1.0时模型基本收敛,如果训练样本充足,参数调整合理,可以达到更低的信息损失,获得更好的识别效果。
[0080]
表2模型训练输出参数
[0081][0082]
模型训练的过程需要大量的时间,为了尽快实现模型的收敛,同时防止训练过度,根据上述模型训练过程的输出参数,需要及时对网络中重要参数进行调整,重要参数及其调整策略归纳如下:
[0083]
①
学习率(learning rate):学习率结合梯度下降算法主要用于实现模型的快速收敛,训练发散的情况下可以适当降低学习率。例如,在训练时,初始化该参数为0.1。随着模型的loss值不断下降模型开始收敛,当loss值出现上下波动或波动较小的情况时,调整学习率为 0.005,在loss值降为1.0以下且波动较小时模型基本收敛。
[0084]
②
批量(batch):每一次迭代送到网络的图片数量,叫做批量。该参数使网络以较少的迭代次数完成一轮预测。在固定最大迭代次数的前提下,batch值增大会延长训练时间,但能够更好地寻找到模型梯度下降的方向。增大batch虽然有利于提高内存利用率,但
也因此会出现显存不够的问题。显存允许的情况下,如果训练过程出现nan 错误提示,可以适当增加batch大小,同时调整动量参数为0.99。通常该值的选取需要反复试验,过大或过小都不利于模型的有效训练,过小时容易训练不收敛,过大时则会陷入局部最优。
[0085]
③
细分(subdivision):subdivision和batch通常成对出现,使得每一个批量的图片首先分成subdivision份数,然后一份一份的送入网络运行,最后将所有份一起打包整合为一次迭代。这样有利于降低对显存的占用,例如,如果该参数为2,意即一次选择批量的一半图片送入网络。
[0086]
④
学习策略(step,scales):step表示训练步数,scales表示学习率变化的比率,二者组合使用。本次模型训练过程设置learning rate 的初始值为0.001,step设置为1000,8000,14000,scales为10,.1,.1,意即在0-1000次迭代期间学习率为初始的0.001。在1000-8000次迭代期间学习率自动计算为初始的10倍即0.01。在8000-14000次迭代期间学习率为当前值的0.1倍即0.001。在14000到最大迭代期间调整学习率为当前值的0.1倍即0.0001。随着迭代数增加,降低学习率的方法可以使模型更有效的学习,也就是更好的降低训练时的信息损失。
[0087]
⑤
随机参数(random):random的可选值有1和0,代表一个开关。该值设置为1时,模型在训练的时候每一批量的图片会随机调整为320-640(32整倍数)尺寸的图片输入到模型中,设置为0则表明所有图片调整为默认尺寸输入网络。本次训练过程应用的网络为 yolov2的darknet-19网络,采用输入到网络中的图像大小为 608*608。
[0088]
(4)使用模型进行目标检测并输出结果,将视频图像的输入到训练好的模型进行目标检测,使用不同颜色的矩形框对检测到的目标物进行标识,并计算矩形框的四条边的像素值范围,最后将标识后的图像和像素值作为结果返回。
[0089]
3、基于三维虚拟地理场景的地理空间坐标解算方法包括求解逆透视变换矩阵,通过逆透视变换矩阵实现从像素坐标系到世界坐标系的转换,可以将二维屏幕图像中的像素坐标转换成地理空间坐标,最后进行应用。
[0090]
(1)求解逆透视变换矩阵
[0091]
①
定义坐标系。立体视觉等方向常常涉及到四个坐标系(如图7 (a)):世界坐标系、相机坐标系、图像坐标系、像素坐标系,四大坐标系介绍如下:
①
世界坐标系:o
w-x
wywzw
,其以带有小圆点的圆心为原点ow,xw水平向右,yw向下,zw由右手法则确定。
②
相机自坐标系:o
c-xcyczc,以相机的光心为原点,x轴与y轴与图像的x轴与y轴平行,z轴为相机光轴。
③
图像坐标系:o-xy,以ccd 图像平面的中心为坐标原点,x轴和y轴分别平行于图像平面的两条垂直边。
④
像素坐标系:uv,以ccd图像平面的左上角顶点为原点,x轴和y轴分别平行于图像坐标系的x轴和y轴。
[0092]
②
像素坐标系转换至图像坐标系。像素坐标系和图像坐标系都在成像平面上,只是各自的原点和度量单位不一样。图像坐标系的原点为相机光轴与成像平面的交点(如图7(b))。图像坐标系的单位是 mm,属于物理单位,而像素坐标系的单位是pixel,我们平常描述一个像素点都是几行几列,dx和dy表示每一列和每一行分别代表多少 mm,即1pixel=dx mm。
[0093][0094]
③
图像坐标系转换至相机坐标系。相机坐标系到图像坐标系属于透视投影关系,从2d到3d。此时投影点p的单位还是mm,并不是 pixel,需要进一步转换到像素坐标系,如图7(c)所示,可以得到如下关系:
[0095][0096]
整理可得:
[0097][0098][0099][0099][0100]
④
相机坐标系转换至世界坐标系。相机坐标系到世界坐标系,即 o
c-xcyczc→ow-x
wywzw
,属于刚体变换,即物体不会发生形变,只需要通过旋转矩阵r和偏移向量t进行转换。从相机坐标系到世界坐标系,涉及到旋转和平移(其实所有的运动也可以用旋转矩阵和平移向量来描述)。绕着不同的坐标轴旋转不同的角度,得到相应的旋转矩阵,如图8所示,绕z轴旋转θ示意图:
[0101][0102][0103]
同理,绕x轴和y轴旋转和,可得到:
[0104][0105][0106]
于是可以得到旋转矩阵r=r1r2r3,如图7(d)所示,p点在世界坐标系中的位置(xw,yw,zw):
[0107][0108][0109][0110]
以上四个步骤,得到从世界坐标系到像素坐标系的总公式为:
[0111][0112]
旋转矩阵r为:
[0113][0114]
偏移向量t为:
[0115]
[0116]
(3)根据逆透视变换矩阵,结合目标检测结果的像素值和构建三维实景融合场景获取的虚拟相机外参解算目标点的世界坐标,即为目标点的地理空间坐标。
[0117]
综上所述,本发明的一种基于三维虚拟地理场景的单目相机目标检测与空间定位方法,该方法首先通过构建三维虚拟地理场景,集成多种三维数据模型,包括dem数据、影像数据、室内外三维模型数据,然后通过对三维虚拟相机进行标定,利用相机外方位元素初始化虚拟相机,根据实时监控视频画面构建实景融合场景展示,获取实景融合的场景图像,接着训练深度学习样本,构建目标检测yolo模型,对输入的实景融合图像进行目标检测,获取检测目标的像素值并输出,最后根据输出的目标像素值,通过逆透视变化将像素坐标转换至地理空间坐标,实现基于三维虚拟地理场景的单目相机目标检测与空间定位。
[0118]
实施例
[0119]
为了体现出本文方法的实际用益价值,以自然资源监测监管领域中塔基视频监管疑似违法建设行为作为实验的基本场景,选取南京江心洲区域作为实验区,高塔摄像头作为基本实验视频源。构建三维虚拟地理环境的基本形式为基于4d产品方式构建三维虚拟地理场景,输入的数据包括nasa earth data 12.5m空间分辨率的dem数据,高分遥感影像数据选取天地图遥感影像数据。利用测绘方法对摄像头的位置进行采集,将数据导入到supermap平台,解析视频画面与三维场景融合构建三维实景融合场景。
[0120]
本实例实现对塔基监控图像的目标识别与空间定位,研究应用的数据是塔基监控图像,将开工疑似违法开工迹象定义为:挖掘机、工程车辆、建筑材料等,以此作为模型训练的正样本。通过对样本训练获得基于yolo的建设用地的目标检测模型,根据模型将目标物检测并输出场景像素值,最后利用逆透视矩阵进行空间位置的解算,实现工程车辆的空间定位。结果如图9所示,对渣土车进行识别和定位。本实例中,摄像头内方位元素及视频调取url地址,均有视频厂商提供。
[0121]
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施方式,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1