一种基于几何约束的自监督深度视觉里程计
本公开涉及基于计算机视觉slam中的位姿估计领域,本公开尤其涉及一种基于几何约束的自监督深度视觉里程获取方法、装置、电子设备及可读存储介质。
背景技术:
1、位姿估计在机器人和无人机的研究中占据重要地位。传统的位姿估计常用轮式编码器,惯性导航装置,gps卫星定位系统等。尽管这些方法已经被广泛使用且在一些特定的场合获得了显著的效果。但是,它们还存在着很大的局限性,例如,在实际使用中,轮式编码器会因为打滑而产生很大误差,惯性导航装置存在严重的累计误差,gps定位系统无法在室内封闭环境中使用。
2、随着计算机视觉技术的发展,用视觉传感器实现位姿估计的方法能够避免传统位姿估计方法存在的这些问题。通过分析视觉传感器图像中的运动变化来估计机器人相对位姿(位置和方向)的过程被称为视觉里程计。视觉里程计可以实时对相机每一刻的位姿进行估计,并把这些估计值发送给后端优化模块以获得更精确的值。本公开属于基于计算机视觉slam中的位姿估计领域。
3、视觉里程计是一种通过视觉传感器获取相机相对位姿的方法,传统的视觉里程计利用几何原理恢复相机的运动,经过了多年的发展,其基本框架已经固定。近几年来,涌现出多种利用深度学习的方法揭示图像和相机运动关系的技术,也取得了显著成效。视觉里程计的现有技术总体分为传统方法和深度学习法的视觉里程计两种。
4、(1)传统方法
5、在介绍具体的视觉里程计技术之前,首先对里程计算法使用的相机数目及其特点进行简单阐述。视觉里程计一般分为单目视觉里程计和双目视觉里程计,单目视觉里程计具有成本低,便携使用等优点,但其最大的弊端就是单目相机无法恢复出图片的深度信息,因此在利用几何方法估计相机位姿时存在着尺度模糊的问题,传统的视觉里程计技术一般都会在使用时加入一定的约束和假设,这使得单目视觉里程计的应用范围一定程度上受到了限制。而双目相机可以通过双目相机的几何模型恢复出图片的深度信息,因此它估计出的相对位姿不存在尺度模糊的问题,但是双目相机对设备的要求较高,需要进行更加复杂的标定,同时双目相机的成本相比单目相机要高。因此单目视觉里程计和双目视觉里程计的选择需要考虑预算及应用场景等多方面因素。
6、下面对传统的视觉里程计技术进行介绍。传统的视觉里程计技术分为两种,特征点法和直接法。
7、moravec最早提出了从连续的图像序列中估计出相机运动的技术,他设计出了moravec角点检测技术用于获取图片特征,并利用该技术实现机器人室内导航。尽管该技术具有一些明显的缺陷,实用性不强,但它仍是后面许多视觉里程计技术的基础。2004年,nister等人设计出了一套用于导航的完整的视觉里程计系统,可以用于估计单目或双目相机的位姿。系统完成了特征检测、特征跟踪、特征匹配和使用特征点间的几何关系对相机位姿进行估计等一系列工作,可以以低延迟的效果实时运行在未知的场景中,真正意义上实现了机器人的室外导航。
8、经过研究者们的不断深入研究,基于特征点法的视觉里程计技术已经使用成熟框架。首先按照设计出的特征模块进行特征检测,然后对相邻图片的特征点进行匹配,使用外点去除算法进行优化,再利用特征点之间的关系进行运动估计,并且可以使用特征点,路标点和相机位姿之间的关系来完成视觉里程计的局部优化。在这个框架中,特征检测中的特征模块作为其重要基础。目前经典的特征检测算法主要有moravec、forstner、harris、shitomasi、susan、fast、sift、surf、mser以及censure等,其中以harris和sift两种算法的应用最为广泛。harris角点是对上文中提的moravec的改进,它对图片的旋转,亮度和视角变化以及噪声影响都具有稳定性,并且计算简单,但它对尺度过于敏感,容易在存在重复的纹理特征的场景中产生误匹配。sift特征点更适合应用于视觉里程计系统中。sift对图片旋转,视角变化,亮度变化和尺度变化都不敏感,而且在tlbba对sift特征进行优化后,可以满足视觉里程计对于实时性的要求。因而很多视觉里程计系统采用了sift特征。除了对特征模块的改善外,研究者对视觉里程计的其他部分的改善也取得了一定的成效。闵海根等提出了一个特征点匹配框架,提出了一种改进的随机抽样一致性外点去除技术,具有更好的抗噪性能,使视觉里程计在动态环境中具有更好的性能。牛文雨等提出了一种基于动态物体检测的视觉里程计,通过将检测到的运动物体区域的特征点剔除,减少图片中的动态物体对估计结果的影响,有效提升了视觉里程计在动态场景下的性能。
9、上述介绍了基于特征点法的视觉里程计中技术的发展,基于特征点法的视觉里程计对噪声不敏感,能够稳定运行,具有较低的成本,已经被广泛使用,比如开源视觉里程计方法libviso就是一种使用特征点法的视觉里程计。但基于特征点法的视觉里程计期望场景能有丰富的纹理,以提取出大量的有效特征,在纹理单一的场景下,该种技术将因为缺乏特征而性能大幅下降。实际上,一张图片包含有丰富的信息,而特征点法只利用了其中的特征点信息,而忽略了其他大部分信息,而视觉里程计中的另一种技术,直接法则是直接利用了图片上的像素信息,因此它也避免了特征点法的上述弊端。下面对使用直接法的视觉里程计进行介绍。
10、使用直接法的视觉里程计是利用图片的像素的亮度信息来计算相机的运动,因此只要场景中存在明暗变化,该方法就能对相机的运动进行估计,而不需要图片中必须能够提取出特征点。但直接法是基于像素灰度值不变的假设上进行的,这项条件会很容易被光照变化等原因破坏,使方法失败。相比之下,特征点法却对光照变化具有鲁棒性,而光照变化是位姿估计中很难避免的因素,所以尽管特征点法和直接法各有其优缺点及适用场景,特征点法仍是目前视觉里程计中的主流技术。
11、随着研究者们的不断深入改善,传统的视觉里程计在一些场景下已经能够达到很好的效果。但其通常对应用场景有极高的要求,对不同的场景可能需要采用不同的技术,并且一般都需要繁琐复杂的计算,这些都是传统技术目前仍未解决的问题。
12、(2)深度学习法
13、随着深度学习的发展,深度神经网络已经广泛应用于各个领域,利用深度学习的技术来研究视觉里程计是一个不可避免的趋势。相对于传统的基于特征的视觉里程计,基于深度学习的技术不再使用手工设计的特征点,也无需特征提取,特征匹配和复杂的几何运算,为视觉里程计的研究提供了新的解决方案。
14、konda在2015年最先提出了一种端到端,基于深度学习的视觉里程计。该里程计模型接收双目图像序列,使用两个结构相同的卷积神经网络分别预测图片序列中每5帧的子序列中相机速度和方向的变化,再联合起来估计出完整的相机的运动路径,经测试该技术能够准确的预测出大部分的方向和速度的变化,同时作者也指出由于视觉里程计存在累积漂移的问题,预测出的相机运动全局轨迹的误差随着时间逐渐在增加。
15、2016年,kendall提出了一种实时鲁棒的六自由度定位系统,该系统使用卷积神经网络从单目rgb图片估计出相机的六自由度姿态信息,室内外均可实时使用,对光照变化,运动模糊,和不同的相机内部特性都具有鲁棒性。
16、2017年,wang等人使用循环卷积神经网络建立了一种新的端到端的单目视觉里程计框架,该框架借助卷积神经网络提取图像特征,循环神经网络则能够对图像的时序信息建模,从而提高模型的位姿估计能力。他们的实验表明,该技术可以和当时最先进的技术相媲美。
17、然而,上文中的深度学习视觉里程计的训练都需要相机的位姿真值,属于有监督的深度学习方法。但通常情况下,由于相机位姿真值的精确度极大程度上影响训练出的里程计的性能,故对位姿真值的获取要求非常严格,为获得精确的真值结果,通常需要多种技术联合对相机位姿进行采集并处理,这个过程成本较高。而基于无监督学习的视觉里程计不再需要相机的位姿真值,减少了视觉里程计训练的成本。
18、zhou在2017年提出了一种基于非监督学习的单目图片的深度和运动的估计技术,该系统分为两个部分,分别估计单视图的深度和多视图的位姿,使用光度损失作为损失函数来估计相机的运动,最终的实验结果表明该模型能够较为准确地预测出相对深度和相对位姿,但它和其他的单目框架一样,存在着尺度模糊问题。li在2017年也提出了无监督学习的单目视觉里程计,该方法能够估计出单目相机的六自由度姿态,不使用相机位姿数据真值对模型进行训练,并且实验表明具有较高的准确率。但该技术的位姿估计网络模型只使用了卷积神经网络用来提取特征,而忽略了相机相对位姿间的相关性,没有利用到图片的序列信息。
技术实现思路
1、为了解决上述技术问题中的至少一个,本公开提供了一种基于几何约束的自监督深度视觉里程获取方法、装置、电子设备及可读存储介质。
2、根据本公开的一个方面,提供一种基于几何约束的自监督深度视觉里程获取方法,包括:
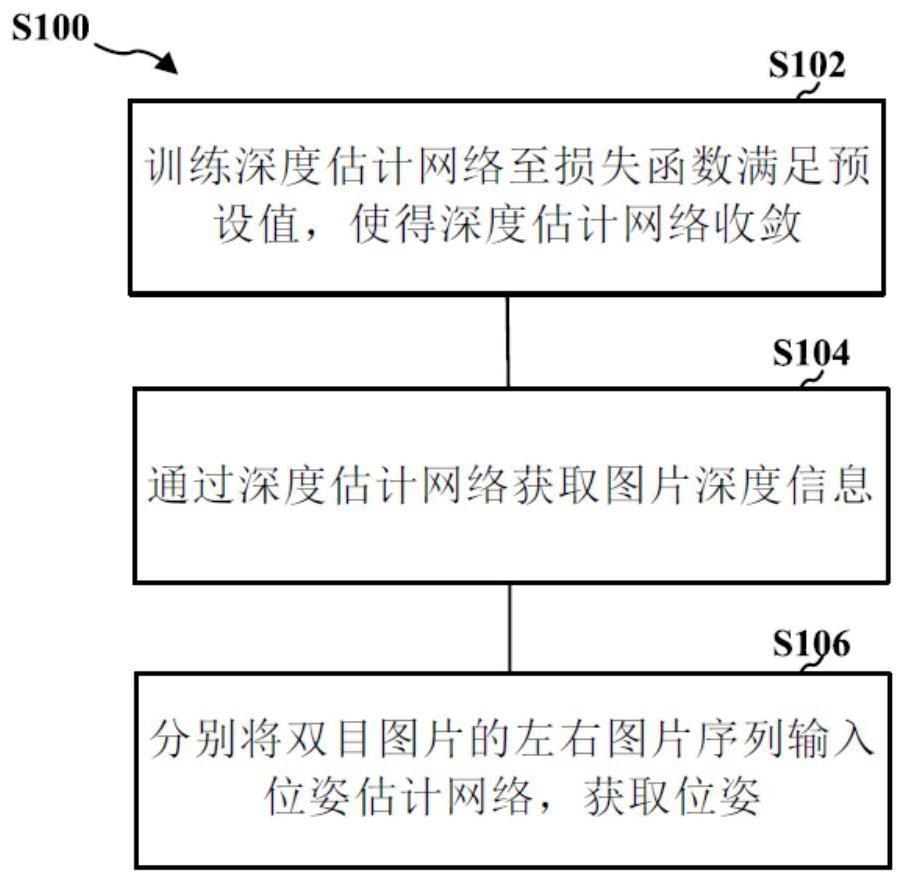
3、训练深度估计网络至损失函数满足预设值,使得深度估计网络收敛;
4、通过深度估计网络获取图片深度信息;
5、分别将双目图片的左右图片序列输入位姿估计网络,获取位姿,所述双目图片的左右图片信息包含所述图片深度信息,所述图片深度信息用于恢复所述位姿的尺度;
6、优选的,所述位姿为六自由度相对位姿。
7、根据本公开至少一个实施方式的基于几何约束的自监督深度视觉里程获取方法,所述位姿估计网络通过卷积神经网络、注意力机制模块、卷积循环神经网络、全连接层依次连接而成;
8、优选的,所述位姿估计网络的全连接层包括dropout层,所述dropout层在训练时以预设概率舍弃部分神经元,起到了平均的作用,减少神经元之间复杂的共适应。
9、根据本公开至少一个实施方式的基于几何约束的自监督深度视觉里程获取方法,分别将双目图片的左右图片序列输入位姿估计网络,获取位姿,包括:
10、将双目图片的左右两个图像输入卷积神经网络,通过卷积神经网络获取图像特征;
11、将所述图像特征输入注意力模型,通过注意力模型获取图像通道细化特征;
12、将所述图像通道细化特征输入所述卷积神经网络,通过所述卷积神经网络获取相对位姿。
13、根据本公开至少一个实施方式的基于几何约束的自监督深度视觉里程获取方法,将所述图像特征输入注意力模型,通过注意力模型获取图像通道细化特征,包括:
14、使用平均和最大池化聚集空间信息,池化方向为图像的高和宽维度,由池化层得到平均和最大空间描述符;
15、将这两种描述符分别传递给全连接层,所述全连接层有2层,其中第一层全连接层有c×r个神经网络单元,第二层全连接层有c个神经网络单元,c是特征图的通道维大小,r是全连接层单元数相对于通道维大小的一个缩小因子;
16、全连接层输出一维张量作为通道注意力掩膜,注意力掩膜和原特征图按通道相乘,将生成通道细化特征;
17、计算过程可以用公式表示为:
18、mc(f)=σ(fc(avgpool(f))+fc(maxpool(f))) (1)
19、
20、其中,各个表达式含义如下:
21、f:输入注意力模型的图像特征;
22、f':通道细化特征;
23、σ:表示sigmoid激活函数;
24、fc(·):表示全连接层处理;
25、表示逐像素相乘;
26、对通道细化特征进行处理,沿通道轴使用平均和最大池化;
27、将池化层生成的平均和最大池化描述符沿通道轴连接得到特征描述符,对特征描述符进行卷积操作后可以得到空间注意图,卷积核大小为7×7,将所述空间注意图和所述通道细化特征相乘,得到最终的空间细化特征;
28、计算过程可以用公式表示为:
29、mc(f')=σ(f7×7(avgpool(f');maxpool(f'))) (3)
30、
31、其中,各个表达式含义如下:
32、σ:表示sigmoid激活函数;
33、f7×7:表示卷积核大小为7×7的卷积操作。
34、根据本公开至少一个实施方式的基于几何约束的自监督深度视觉里程获取方法,所述深度估计网络由编码器、解码器及跳跃连接结构组成,所述跳跃连接结构将不同层的大小相同的特征图在通道维上合并拼接后输入到下层网络,所述跳跃连接结构使反卷积层在恢复尺寸时使用较浅的卷积层特征,使所述解码器恢复图像分辨细节;
35、优选的,所述解码器通过反卷积实现。
36、根据本公开至少一个实施方式的基于几何约束的自监督深度视觉里程获取方法,所述损失函数为:
37、
38、其中,各个表达式含义如下:
39、和分别表示左图和右图空间重构损失;
40、和分别表示时间t和t+1时刻时间重构损失;
41、ldis:表示视差图重构损失;
42、lpos:表示一致性损失;
43、λap:表示空间损失占比;
44、λpic:表示时间损失占比;
45、λdis:表示损失函数各项所占权重;
46、λpos:表示一致性损失占比;
47、其中,空间损失和通过空间重构损失函数计算,空间损失函数计算方法表示为:
48、
49、
50、其中,各个表达式含义如下:
51、表示双目图片的右图结构相似性指数;
52、表示双目图片的左图结构相似性指数;
53、表示由l1范数构建的左图和左图重构图的像素差绝对值均值;
54、表示由l1范数构建的右图和右图重构图的像素差绝对值均值;
55、n:表示图片像素点个数;
56、α:表示结构性相似度占比权重,1-α表示像素差绝对值均值占比权重;
57、其中,结构相似性指数ssim计算方法如下:
58、ssim(x,y)=[l(x,y)]α[c(x,y)]β[s(x,y)]γ (7)
59、
60、
61、
62、其中,ssim计算公式中各个表达式含义如下:
63、x,y:分别表示用于比较的两张图片;
64、l(x,y),c(x,y),s(x,y):分别表示图片的亮度、对比度和结构信息;
65、α,β,γ:均大于0;
66、ux:表示图片x的像素均值;
67、uy:表示图片y的像素均值;
68、表示图片x像素值的方差;
69、表示图片y像素值的方差;
70、δxy:表示x和y的协方差;
71、c1,c2,c3:分别表示用来维持稳定的常数;
72、其中,优选的,α=β=γ=1,c3=0.5c2;
73、其中,l1范数构建的像素差绝对值均值的计算方法表示为:
74、
75、其中,各个表达式含义如下:
76、ii,j和分别表示原图和重构图的像素点(i,j)的像素值;
77、其中,t和t+1时刻的时间重构损失和通过时间重构损失函数计算,计算方法如下:
78、
79、
80、其中,各个表达式含义如下:
81、it:表示时间t时刻的图片;
82、it+1:表示时间t+1时刻的图片;
83、表示基于it的重构图片;
84、表示基于it+1的重构图片;
85、iti,j:表示时间为t时刻的图片中坐标为(i,j)的像素的值;
86、表示时间为t时刻的重构图片中坐标为(i,j)的像素的值;
87、it+1i,j:表示表示时间为t+1时刻的图片中坐标为(i,j)的像素的值;
88、表示时间为t+1时刻的重构图片中坐标为(i,j)的像素的值;
89、n:表示像素点数目;
90、其中,视差图重构损失ldis通过视差损失函数计算,计算方法表示为:
91、
92、其中,各个表达式含义如下:
93、dli,j:表示左图中坐标为(i,j)的像素对应的视差的值;
94、表示左图重构图中坐标为(i,j)的像素对应的视差的值;
95、dri,j:表示右图中坐标为(i,j)的像素对应的视差的值;
96、表示右图重构图中坐标为(i,j)的像素对应的视差的值;
97、n:表示像素点的数目;
98、其中,一致性损失lpos通过一致性损失函数计算,计算方法如下:
99、lpos=λt||tr-tl||+λr||rr-rl|| (14)
100、优选的,设置α=β=γ=1,c3=0.5c2,将式(8)(9)(10)代入(7),则ssim表达式为:
101、
102、根据本公开至少一个实施方式的基于几何约束的自监督深度视觉里程获取方法,所述原图和重构图之间通过各个对应像素点进行重构,包括:
103、对相邻两张图片进行特征匹配,根据匹配好的特征点来恢复两帧之间相机的运动,设相机相邻两帧间的运动为r,t,两个相机中心分别为o1,o2,空间点p的坐标为:
104、p=[x,y,z]t (15)
105、p在图片i1对应的特征点p1:
106、z1p1=kp (16)
107、其中,各个表达式含义如下:
108、p:特征点p1对应的空间点p的三维坐标;
109、p1:特征点p1对应的齐次坐标;
110、z1:在帧i1对应相机的深度值;
111、k:相机内参;
112、当已知z1和k时,可通过式(16)从特征点p1恢复出空间点p的坐标,且坐标尺度确定;
113、p在i2中对应的特征点p2:
114、z2p2=k(rp+t) (17)
115、由式(16)和(17)经过推导可以得出对极约束:
116、
117、式(18)包含两个匹配p1和p2的特征点的空间位置关系,基于式(18)和多个匹配的特征点可以恢复出相机位姿;
118、由式(16)和(17)恢复出p在相邻两帧图片上对应的特征点的关系:
119、z2p2=k(z1rk-1p1+t) (19)
120、其中,式(19)表达式含义如下:
121、式(19)等式右端,在第一帧图片上的特征点p1已知其对应的空间点深度z1,可以利用相机内参矩阵k恢复出其对应空间点p在当前相机坐标下的位置,然后根据相机运动信息r,t可计算出该空间点在第二帧图片对应的相机坐标系下的位置;
122、式(19)等式左端,在第二张图片上的特征点p2,由相机内参矩阵k,深度信息z2和等式右端建立相等关系,p1和p2的关系由此建立;
123、在由空间点在第二帧图片对应的相机坐标系下的空间位置向特征点p2转换时,其对应的深度信息z2已由空间点坐标获得,也就是在建立p1和p2的关系时无需提前知道z2的值,用式(19)中的关系从p1估计出p2,用t表示两帧间运动,写成等式一侧乘以任意非零常数均成立的形式:
124、
125、是特征点p2位置的估计值。
126、根据本公开的又一个方面,提供一种基于几何约束的自监督深度视觉里程获取装置,包括:
127、深度估计网络训练模块,训练深度估计网络至损失函数满足预设值,使得深度估计网络收敛;
128、图片深度信息获取模块,通过深度估计网络获取图片深度信息;
129、位姿获取模块,分别将双目图片的左右图片序列输入位姿估计网络,获取位姿,所述双目图片的左右图片信息包含所述图片深度信息,所述图片深度信息用于恢复所述位姿的尺度;
130、优选的,所述位姿为六自由度相对位姿。
131、根据本公开的又一个方面,提供一种电子设备,包括:
132、存储器,所述存储器存储执行指令;
133、处理器,所述处理器执行所述存储器存储的执行指令,使得所述处理器执行上述任一项所述的获取方法。
134、根据本公开的又一个方面,提供一种可读存储介质,所述可读存储介质中存储有执行指令,所述执行指令被处理器执行时用于实现上述任一项所述的获取方法。
- 还没有人留言评论。精彩留言会获得点赞!