一种基于注意力机制的PM2.5浓度预测的方法
本发明属于人工智能和环境科学领域,具体的说是一种基于注意力机制的pm2.5浓度预测的方法。
背景技术:
1、近些年来,经济将得到了快速发展,但是的经济发展是以资源的超常消耗和生态的严重恶化为代价的。空气污染物超标排放,这些物质对人类健康具有长期性影响,不但严重影响了人们的正常学习和工作,也给社会造成了巨大的损失。
2、空气质量监测站的数据的监测与采集,由于自身存在物理性缺点,易受外界环境因素的干扰,会导致采集的数据失真,数据存在一定的偏差,对于日常数据的异常检测和维护更多的是靠人工去进行。这样耗费大量的人力物力,并且工作效率低,人工检测会存在大量的漏检,错检。
技术实现思路
1、为提高空气质量数据的分析和环境预警能力,本发明提出一种基于attention-lstm的pm2.5污染物小时浓度预测的方法。通过对历史时间序列的空气污染物数据建模,更准确的预测未来pm2.5污染物小时浓度。
2、本发明为实现上述目的所采用的技术方案是:
3、一种基于注意力机制的pm2.5浓度预测的方法,包括以下步骤:
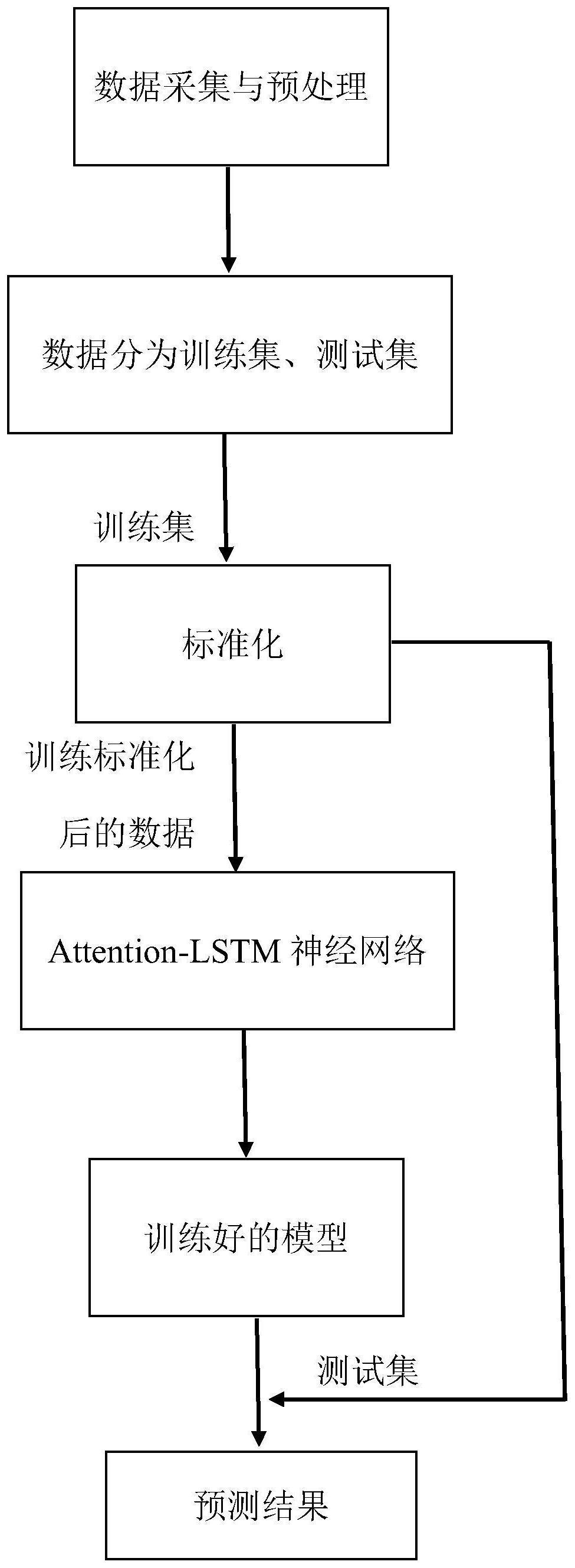
4、获取空气污染物浓度历史小时数据,并对其进行预处理;
5、将预处理后的数据分为训练集和测试集,并对训练集数据进行标准化处理;
6、构建attention-lstm神经网络预测模型,并使用训练集数据对其进行训练;
7、将测试集数据输入到训练好的预测模型中进行预测,得到未来pm2.5污染物的小时浓度。
8、所述预处理包括以下步骤:
9、1)去除数据中除pm2.5污染物小时浓度数据以外的数据;
10、2)使用阈值标记噪声数据,并去除;
11、3)使用k-means算法得到异常点数据,并去除;
12、4)用过去24小时平均数据填充去除的噪声数据和异常点数据。
13、所述使用k-means算法得到异常点数据,具体为:使用拐点法确定k值,即分类的类别数量,在每一个类别中,分别计算每一个数据点到聚类中心的距离,每一类别设置一个阈值,将距离超过阈值的数据点作为异常点数据。
14、所述attention-lstm神经网络预测模型包括顺次连接的输入层、两个lstm层、attention层、全连接层以及输出层。
15、所述使用训练集数据对其进行训练,包括以下步骤:
16、a)将训练集数据输入到attention-lstm神经网络预测模型中;
17、b)根据预设的超参数对模型进行训练,根据模型输出的预测值与实际值的误差,使用反向传播算法调整神经网络预测模型的权值跟偏置,神经网络预测模型训练到预设的次数后,保存神经网络预测模型;
18、c)输入测试集的数据,获得未来pm2.5污染物的小时浓度的预测值所为测试结果;
19、d)调整神经网络预测模型的超参数,重复步骤b)至步骤c),选取得到的所有预测值中与测试集中实际值mse最小的神经网络预测模型作为最终的attention-lstm神经网络预测模型。
20、所述的超参数为:优化器,优化器学习率、每一批次输入数据的数量、权重衰减系数。
21、一种基于注意力机制的pm2.5浓度预测系统,包括:
22、数据获取模块,用于获取空气污染物浓度历史小时数据,并对其进行预处理;
23、数据处理模块,用于将预处理后的数据分为训练集和测试集,并对训练集数据进行标准化处理;
24、模型训练模块,用于构建attention-lstm神经网络预测模型,并使用训练集数据对其进行训练;
25、数据预测模块,用于将测试集数据输入到训练好的预测模型中进行预测,得到未来pm2.5污染物的小时浓度。
26、一种基于注意力机制的pm2.5浓度预测系统,包括存储器和处理器;所述存储器,用于存储计算机程序;所述处理器,用于当执行所述计算机程序时,实现所述的一种基于注意力机制的pm2.5浓度预测的方法。
27、一种计算机可读存储介质,所述存储介质上存储有计算机程序,当所述计算机程序被处理器执行时,实现所述的一种基于注意力机制的pm2.5浓度预测的方法。
28、本发明具有以下有益效果及优点:
29、1.数据处理:使用多种方法对获得的历史序列数据进行处理,识别出更多的异常点,提高了数据质量,有利于后续模型的训练。
30、2.attention-lstm神经网络:由于历史序列数据太长,传统的预测模型会弱化长距离的信息,导致预测效果不好。attention-lstm神经网络能够捕捉到更远的时间序列数据,将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。
技术特征:
1.一种基于注意力机制的pm2.5浓度预测的方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的一种基于注意力机制的pm2.5浓度预测的方法,其特征在于,所述预处理包括以下步骤:
3.根据权利要求2所述的一种基于注意力机制的pm2.5浓度预测的方法,其特征在于,所述使用k-means算法得到异常点数据,具体为:使用拐点法确定k值,即分类的类别数量,在每一个类别中,分别计算每一个数据点到聚类中心的距离,每一类别设置一个阈值,将距离超过阈值的数据点作为异常点数据。
4.根据权利要求1所述的一种基于注意力机制的pm2.5浓度预测的方法,其特征在于,所述attention-lstm神经网络预测模型包括顺次连接的输入层、两个lstm层、attention层、全连接层以及输出层。
5.根据权利要求1所述的一种基于注意力机制的pm2.5浓度预测的方法,其特征在于,所述使用训练集数据对其进行训练,包括以下步骤:
6.根据权利要求5所述的一种基于注意力机制的pm2.5浓度预测的方法,其特征在于,所述的超参数为:优化器,优化器学习率、每一批次输入数据的数量、权重衰减系数。
7.一种基于注意力机制的pm2.5浓度预测系统,其特征在于,包括:
8.一种基于注意力机制的pm2.5浓度预测系统,其特征在于,包括存储器和处理器;所述存储器,用于存储计算机程序;所述处理器,用于当执行所述计算机程序时,实现如权利要求1-6任一项所述的一种基于注意力机制的pm2.5浓度预测的方法。
9.一种计算机可读存储介质,其特征在于,所述存储介质上存储有计算机程序,当所述计算机程序被处理器执行时,实现如权利要求1-6任一项所述的一种基于注意力机制的pm2.5浓度预测的方法。
技术总结
本发明属于人工智能和环境科学领域,具体的说是一种基于注意力机制的PM2.5浓度预测的方法,该方法首先将空气污染物(PM2.5、PM10、SO2等)进行预处理,通过阈值判定、K‑means算法对异常点进行检测,通过均值插值去替换异常值。再将数据集分为训练集,测试集,对训练集进行标准化处理,然后将处理后的数据输入Attention‑LSTM神经网络进行训练,得到训练模型,对未来PM2.5污染物浓度进行预测。本发明弥补了传统方法在时间序列数据方面的缺陷,提高了训练速度以及模型的准确率。
技术研发人员:张镝,王宁,杨柳,杜毅明,武暕,康利荥,白雪,周晓鸥
受保护的技术使用者:中国科学院沈阳计算技术研究所有限公司
技术研发日:
技术公布日:2024/1/13
- 还没有人留言评论。精彩留言会获得点赞!