一种服务特定领域的稀缺资源语言模型建模方法及建模系统
本发明属于人工智能语言信息处理和语音识别,具体地说,涉及一种服务特定领域的稀缺资源语言模型建模方法及建模系统。
背景技术:
1、语音识别(speech recognition)是指利用计算机对得到的语音信号进行处理,通过 分析和识别,把人类的语音信号转变为相应的文字或者命令的计算机处理过程。由于语音信号的动态时变性、瞬时性和随机性,单靠声学层面的分析处理和匹配,无法得 到较好的识别结果。因此,需要在语音信号处理的基础上,结合相关语言知识进行约 束和处理,以提高系统的处理准确率,因此,一般语音识别系统包括声学模型和语言 模型。语言模型用于刻画自然语言中的内在规律,提供字或词之间的上下文和语义信 息,是语音识别系统的重要组成部分。
2、在语言模型的建模过程中,占主导地位的依然是基于统计规则的n-gram建模技术。其中,n-gram建模技术具有很好的建模能力,实现也相对简单,当语料充足时, 能够训练出性能很好的模型,并且发展出性能良好的数据平滑技术,适用实际应用的 需要。同时为了克服n-gram建模技术的弱点,研究者已经提出了基于神经网络 (neural network)的语言模型,更好描述词语之间的关联关系。神经网络语言模型 也需要对语料的统计学习,作为知识来源基础的语料,在神经网络语言模型建模中, 也具有重要意义。因此,如果能够针对语言模型应用的特定领域进行语料的收集整理 和训练建模,无疑会提高语言模型的建模效率和性能。
3、语言智能处理技术的快速发展,进一步拓展了语言信息技术应用的语种,从原来的汉语、英语等资源富集的语种拓展到越南语、哈萨克语等稀缺资源的语种。随着信 息技术与社会生活的深度融合,稀缺资源,更多体现为专家资源的稀缺,即缺乏相应 语种的语言专家,能够根据应用的需要对获取的初始语言资源进行一定程度的加工, 进而提高语言模型的建模效率和性能,专家资源的稀缺在针对特定领域进行语言建 模时,表现的更为显著。
4、另一方面,汉语、英语等资源富集语种已经有较好的语言资源积累和成果积累。特别是汉语,本国相关研发人员能够较好有效平衡专家资源的问题。因此,构建一种 以汉语或者其他富集资源语言为参考的、面向稀缺资源语言、服务特定领域的语言建 模方法和系统具有实用价值和重要意义。
5、另外,近年来在文本处理方面主题语义分析取得长足进展,以统计分布为基础,形成了利用语言资源研究语义内容的新模式。其中基于潜在狄利克雷分配(latentdirichlet allocation,lda)分布的主题分析模型在研究中得到广泛应用,这也为在涉 及稀缺资源语种的语言模型建模中引入语义信息提供了新思路。
6、综上所述,现有的语言模型难于应对服务特定领域的稀缺资源语种语言模型构建,获取稀缺资源语料的语义信息的准确度低,无法识别稀缺资源语料中的特定领域 信息,服务特定领域具体应用性能差。
技术实现思路
1、为解决现有技术存在的上述缺陷,本发明提出了一种服务特定邻域的稀缺资源语言模型建模方法,通过该方法建立的稀缺语言模型,在特定领域,针对特定的稀缺 资源语料,能够准确地获取该稀缺资源语料的主题语义信息;另外,该方法利用主题 语义处理方法,获取稀缺资源语言语料的主题语义信息,进而使用主题语义信息选择 特定领域的语料进行语言模型建模,提升稀缺资源语种语言模型的建模效率和语言 模型的处理性能。
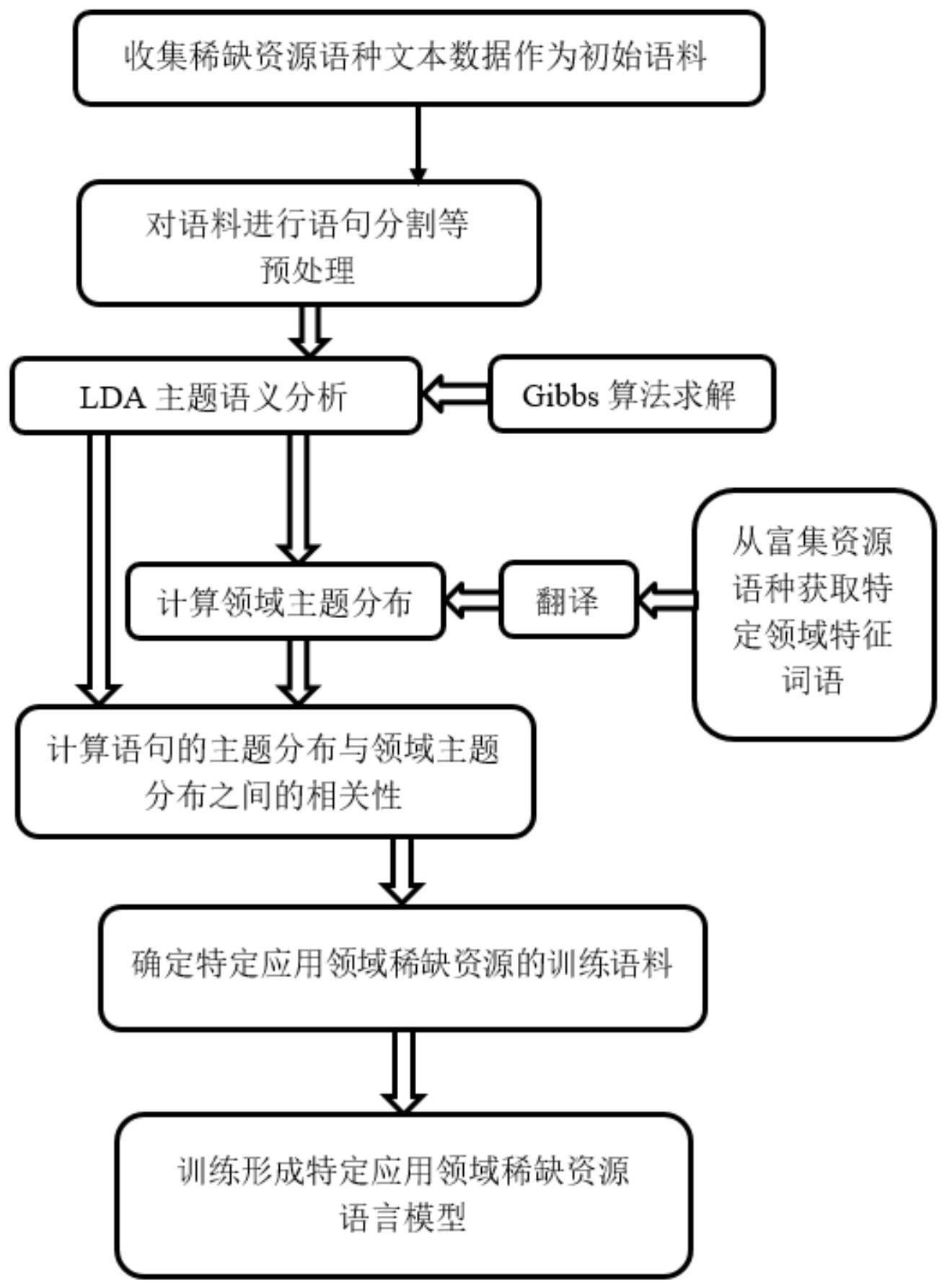
2、本发明提供了一种服务特定领域的稀缺资源语言模型建模方法,该方法包括:
3、步骤1)收集稀缺资源文本作为初始语料,对该初始语料进行预处理,得到预处 理后的文本;以语句为单位,对预处理后的文本进行分割,保留语句的顺序关系和段 落信息,得到由多个分割语句组成的预处理后的语句集合;
4、步骤2)对预处理后的语句集合,结合gibbs算法,得到语句-主题分布和主题-词语分布;
5、步骤3)在预先收集的富集资源语种文本中,对特定领域选择领域特征词语,得 到选定的领域特征词;
6、步骤4)将选定的领域特征词语翻译成稀缺语种的词语,得到翻译后的领域特征词语;
7、步骤5)利用翻译后的领域特征词语,结合步骤2)得到的主题-词语分布,计算 并得到领域主题分布;
8、步骤6)计算每个分割语句的语句-主题分布与领域主题分布之间的相关度;
9、步骤7)判断每个分割语句的相关度是否超过预设的阈值,将满足条件的语句入选稀缺资源特定领域的语言模型训练语料;
10、步骤8)根据语言表述的连贯性,进一步筛选步骤7)得到的语言模型训练语料, 得到最终的语言模型训练语料;
11、步骤9)利用步骤8)得到的最终的语言模型训练语料,对稀缺资源语言模型进 行训练,得到稀缺资源语言模型。
12、作为上述技术方案的改进之一,所述步骤2)具体包括:
13、预处理后的语句集合表示为由m个分割语句构成,记为 s={s1,…,sm,...,sm},,其中第m个分割语句sm是长度为n的词语序列,记为 sm=(w1,…,wn,...,wn),其中,wn表示词语序列中的第n个词语;
14、为分割语句中的某个词语在[1…k]的k个主题分布中随机分配一个主题,构成 初始的markov链,重复上述过程,对于分割语句中的所有词语分配一个对应的主题, 获取markov链的下一个状态,经过多次迭代,markov链达到稳定状态;
15、利用gibbs抽样方法,得到主题-词语分布:
16、
17、和语句-主题分布:
18、
19、其中,为主题-词语分布的估计值,为从主题j中抽取新词记号wn的概率 估计;cvk和cmk分别为维数为v×k和m×k的数量矩阵;其中,v为词语的总数; 为词语w-n属于主题j的频次;为对应词语wn属于主题j的值,设定为 0.02;为词语wv属于主题j的频次;βv,j为对应词语wv属于主题j的值,设定 为0.02;
20、其中,为语句-主题分布的估计值,为在语句sm从主题j抽取新词的概率估计;为特定的分割语句sm中指定给主题j的词语个数;αm,j为对应分割语句sm属于主题j的值;为特定的分割语句sm中指定给主题k的词语个数;αm,k为对应分割语句sm属于主题k的值。
21、作为上述技术方案的改进之一,所述步骤3)具体包括:
22、步骤3-1)收集富集资源语种文本,并将其作为训练语料,并从中选择涉及特定 领域内容的文本,作为提取领域特征词的基础;
23、步骤3-2)计算词语的信息增益值g(h),该信息增益值为不考虑任何词语特征 时文档的熵和考虑了词语特征后文档的熵的差值:
24、
25、其中,e(s)为不考虑任何词语特征时文档的熵;e(sh)为考虑了词语特征后 文档的熵;p(cj)为cj类文档在训练语料中的出现概率;p(h)为训练语料中包含 词语特征词h的文档的概率;p(cj|h)为文档包含词语特征词h时且属于cj类文 档的条件概率;为训练语料中不包含词语特征词h的文档的概率;为文档不包含词语特征词h时且属于cj类文档的条件概率;m表示对训练语料分类 的总数,m=2,将训练语料分为特定领域和非特定应用领域两类;
26、步骤3-3)重复步骤3-2),计算训练语料中的每个涉及特定领域内容的文本内 的所有词语作为特征词语的信息增益值,并按照信息增益值从大到小的顺序对每个 涉及特定领域内容的文本的内的所有词语进行排序,根据经验选取前500到1万个 词语,作为选定的领域特征词。
27、作为上述技术方案的改进之一,所述步骤5)具体包括:
28、翻译得到的稀缺资源语种中的领域特征词序列,记为翻译后的领域特征词语,且其表示为e={e1,…,en,…,en};其中,en表示领域特征词序列中的第n个领 域特征词语,n表示领域特征词语的总数;以en在主题-词语分布的估计值作 为词语的主题分布向量
29、
30、其中,zi表示领域特征词语en在第i个主题上的分布值;zk为领域特征词语en在第k个主题上的分布值;
31、领域主题分布dt为:
32、dt=[t1,...,ti,...,tk]
33、其中,ti表示特定应用领域在第i个主题上的分布值;tk为特定应用领域在第k 个主题上的分布值;
34、
35、其中,zij表示领域特征词语ej在第j个主题上的分布值。
36、作为上述技术方案的改进之一,所述步骤6)具体包括:
37、假设预处理后的语句集合s={s1,...,si,...,sm},其中,m为语句个数,si为预处理后的语句集合中的第i个分割语句;以si在语句-主题分布作为词语的lda向 量的数值表示:
38、si=[y1,...,yj,...,yk]
39、其中,yj表示si在第j个主题上的分布值;
40、采用夹角余弦的方法,计算语句-主题分布与领域主题分布之间的相关度c(si):
41、
42、其中,yj为si在语句-主题分布中的第j个主题的分量值;tj为领域主题分布中 的第j个主题的分量值;
43、重复上述过程,得到每个分割语句的语句-主题分布与领域主题分布之间的相关度。
44、作为上述技术方案的改进之一,所述步骤7)具体包括:
45、判断每个语句的相关度是否超过预设的阈值,
46、如果某个语句的相关度大于预设的阈值,则将满足条件的语句入选稀缺资源特定领域的语言模型训练语料;
47、如果某个语句的相关度小于或等于预设的阈值,则删除该语句。
48、作为上述技术方案的改进之一,所述步骤8)具体包括:
49、步骤8-1)如果所选取的分割语句位于段首,则不选择该分割语句之前的文本;
50、如果所选取的分割语句不是位于段首,则选取该分割语句之前的一个文本作为候补的语料,并将其入选稀缺资源特定领域的语言模型训练语料中;
51、步骤8-2)如果所选取的分割语句位于段尾,则不选择该分割语句之后的文本;
52、如果所选取的分割语句不是位于段尾,则选取该分割语句之后的一个文本作为候补的语料,并将其入选稀缺资源特定领域的语言模型训练语料中;
53、步骤8-3)根据上述步骤8-1)和步骤8-2),对步骤7)得到的语言模型训练语料 进行再次筛选,并进行去重处理,得到最终的语言模型训练语料;
54、具体地,将上述两个得到的候补的语料进行去重处理,如果已经在步骤7)得到 的训练语料中,则不重复计入;将去重后的候补的语料归入训练语料中。
55、作为上述技术方案的改进之一,所述步骤9)具体包括:
56、采用n-gram语言模型的建模方法,具体n取值为2、3或者4:
57、2-gram语言模型:
58、p(s)=p(w1w2...wn)=p(w1)p(w2|w1)...p(wn|wn-1)
59、其中,p(s)表示分割语句s的生成概率;p(w1w2...wn)为稀缺资源语言模型的 训练语料中的第n个词语wn出现的概率;p(w1)为w1在整个最终的语言模型训练语 料中的出现概率;p(w2|w1)为在语料库中在w1出现的条件下,且w2出现的条件概 率;p(wn|wn-1)为在语料库中在wn-1出现的条件下,且wn出现的条件概率;
60、3-gram语言模型:
61、p(s)=p(w1w2...wn)=p(w1)p(w2|w1)...p(wn|wn-1wn-2)
62、其中,p(wn|wn-1wn-2)为在语料库中在wn-1和wn-2同时出现的条件下,且wn出现的条件概率;
63、4-gram语言模型:
64、p(s)=p(w1w2...wn)=p(w1)p(w2|w1)...p(wn|wn-1wn-2wn-3)
65、其中,p(wn|wn-1wn-2wn-3)为在语料库中在wn-1、wn-2和wn-3同时出现的条件 下,且wn出现的条件概率;
66、其中,wn-1为距离第n个词语wn的前1个词语;wn-2为距离第n个词语wn的 前2个词语;wn-3为距离第n个词语wn的前3个词语;
67、上面2、3、4-gram语言模型的公式中,采用最大似然法,利用最终的语言模型 训练语料,估计最终的语言模型训练语料中的词语wn出现的概率p(wn)和条件概率 p(wn|wn-1wn-2...w1),出现概率p(wn)的具体公式如下:
68、
69、其中,f(wn)为词语wn在训练语料出现的频次;f(wn)为训练语料中总的词频 数;wn为最终的语言模型训练语料所涉及词语的总集合;
70、条件概率的计算公式如下:
71、
72、其中,f(w1w2...wn)为词语w1w2...wn在训练语料中共现的频次;f(w1w2...wn-1)为词语w1w2...wn-1在训练语料中共现的频次;
73、最后,通过在最终的语言模型训练语料上,计算得到关于词语wn的出现概率 p(wn)和条件概率p(wn|wn-1)、p(wn|wn-1wn-2)和p(wn|wn-1wn-2wn-3),进而得 到了作为稀缺资源语言模型的2-gram语言模型、3-gram语言模型和/或4-gram语 言模型,形成了服务特定领域的稀缺资源语言模型。
74、本发明还提供了一种服务特定邻域的稀缺资源语言模型建模装置,该装置包括:
75、预处理模块,用于收集稀缺资源文本作为初始语料,对该初始语料进行预处理,得到预处理后的文本;以语句为单位,对预处理后的文本进行分割,保留语句的顺序 关系和段落信息,得到由多个分割语句组成的预处理后的语句集合;
76、lda分析模块,用于对预处理后的语句集合,结合gibbs算法,得到语句-主题 分布和主题-词语分布;
77、计算领域主题分布模块,用于在预先收集的富集资源语种文本中,对特定领域选择领域特征词语,得到选定的领域特征词;并将选定的领域特征词语翻译成稀缺语种 的词语,得到翻译后的领域特征词语;利用翻译后的领域特征词语,结合得到的主题-词语分布,计算并得到领域主题分布;
78、领域语料选择模块,用于计算每个分割语句的语句-主题分布与领域主题分布之间的相关度;判断每个分割语句的相关度是否超过预设的阈值,将满足条件的语句入 选稀缺资源特定领域的语言模型训练语料;根据语言表述的连贯性,进一步筛选得到 的语言模型训练语料,得到最终的语言模型训练语料;和
79、领域语言模型训练模块,用于利用得到的最终的语言模型训练语料,对稀缺资源语言模型进行训练,得到稀缺资源语言模型。
80、本发明还提供了一种服务特定领域的稀缺资源语言模型建模的电子设备,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述 处理器执行所述计算机程序时实现所述的方法。
81、本发明与现有技术相比的有益效果是:
82、1、本发明的方法能够利用语言大数据较好应对稀缺资源语言模型建模的困难。针对特定领域稀缺资源语言模型建模,特别是专家资源稀缺的困难,本发明的方法提 供了有效可行的建模方法;直接利用语言大数据进行建模,服务特定领域应用,有助 于提高建模效率和模型性能;借助主题语义分析技术对稀缺资源语言数据进行分析, 挖掘其中语义信息,为关涉特定领域稀缺资源语言建模提供丰富的线索;
83、2、本发明的方法能够利用语言大数据较好应对稀缺资源语言模型建模中缺乏无语义信息支撑处理、缺少专家资源服务语料分类标注的困难,针对特定领域稀缺资源 语言模型建模,本发明的方法提供了有效可行的实现方案建模方法;直接利用语言大 数据进行建模,服务特定领域应用,有助于提高建模效率和模型性能;借助主题语义 分析技术对稀缺资源语言数据进行分析,挖掘其中语义信息,为服务特定领域稀缺资 源语言建模提供丰富的语义信息;
84、3、本发明的方法引入主题语义分析对稀缺资源语言语料进行分析,获取相应的语义信息,结合富集资源语言的领域特征词知识,选择涉及特定领域的稀缺资源语言 语料实现语言模型建模,服务特定领域语言信息处理应用;
85、4、本发明的方法为特定领域稀缺资源(特别是专家资源稀缺)语种语言模型建 模提供了有效可行的实现方案;
86、5、利用涉及特定领域的稀缺资源语言语料进行语言模型建模,服务特定领域应用,有助于提高建模效率和模型性能;
87、6、借助主题语义分析技术对稀缺资源语言语料进行语义分析,可以深入挖掘语料中语义信息,实现对语义信息的综合利用,有效获取特定领域稀缺资源语料,奠定 语言模型建模的基础。
- 还没有人留言评论。精彩留言会获得点赞!