基于膨胀卷积的高光谱图像分类方法
1.本发明涉及高光谱图像分类方法。
背景技术:
2.在过去的几十年,高光谱技术得到快速发展,且广泛应用于许多领域。例如植被、估 算土壤盐度、地球勘探等[1]-[5]。
[0003]
高光谱图像(hsis)是具有很大研究活力的领域,同样也得到了遥感领域的广泛关注 [6]。在hsis的研究早期,很多基于光谱的特征提取方法被相继提出,包括支持向量机 (svm)[7]、多项逻辑回归[8]-[9]以及动态或随机子空间[10]-[11]。此外,一些基于特征 提取或降维的方法也被人们所关注,例如主成分分析(pca)[12]、独立成分分析(ica) [13]以及线性判别分析(lda)[14]。但以上这些基于像素级分类器获得的分类结果并不 令人满意。为了对高光谱图像较好的分类,一些有效的空谱特征表示方法被提出[15]-[16]。 其中,基于空间和光谱特征提取的经典方法包括通过多种形态来提取空间特征的扩展形态 学轮廓法(emps)[17]、多核学习[18][19]。在[20]-[22],稀疏表示模型考虑了相邻的空 间信息。另外,在[23]-[25],根据纹理的相似性,将hsis分割成多个超像素来探索空间 的一致性。尽管这些基于空间与光谱特征提取的方法较为有效,但在样本的类间相似性较 高,类内差异较大的情况下,这些方法很难提供较好的分类性能。因此,获得更具判别能 力的特征,是进一步提高分类性能的关键。
[0004]
随着大数据时代的到来,深度学习在过去几年快速发展,且被应用在多个领域,如图 像处理[26]、自然语言处理[27]等。在深度学习发展早期,自动堆叠编码器(sae)[28] 和递归自动编码器(raes)[29]被提出且获得了良好的性能。然而,由于该方法只能处 理1-d向量,这就导致hsis的空间信息被破坏。随后,在[30],限制性玻尔兹曼机(therestricted boltzmannmachine)和深度置信网络被用来提取特征和像素分类,保留了hsis的 大部分特征信息。此外,一些基于2-d cnn的方法被相继提出,包括r-vcanet[31]、2-d cnn[32]等等。为了更好的表示数据,一般将hsis视为三维立方体。因此,用基于2-d cnn 的方法去处理hsis,会导致cnn中的卷积变得复杂。为了弥补2-d cnn的不足,一些 3-d cnn的方法被提出。在[33],lee and kwon提出了一种上下文深度cnn(cdcnn), 这种方法能够联合提取高光谱图像的空谱信息。但随着网络加深,很有可能出现休斯现象 (hughes)[34]。为了缓解这个问题,he等人在2016提出了新的网络结构resnet[35]。 此外,zhong等人提出了一种基于空间光谱的残差网络(ssrn)[36]。paoletti等人提出 了金字塔残差网络(pyresnet)[37],该方法在cnn中加入附加链路,且在所有的conv 层逐渐增加特征图的维度。在[38],一种基于密集连接卷积神经网络(densenet)被提出, 通过在网络中引入密集的连接,使得特征传播加强,且获得了较好的分类性能。由于尺度 单一的卷积核获取特征不够丰富,许多基于多尺度卷积核的方法被用来提取丰富的特征, 从而使得高光谱图像分类性能改善[39]-[41]。最近,提出了一些用于高光谱图像分类的新 方法。例如,roy等人提出一种2-d cnn与3-dcnn结合来降低3d-cnn复杂度的方法 (hybrid-sn)[42]。在[43],meng
等人提出了一种双混合链路网络,能够提取高光谱图 像中更具判别能力的特征。同时,roy等人提出一种基于注意力的自适应光谱与空间核改 进的残差网络(a2s2k-resnet)[44],该方法采用自适应卷积核来扩大感受野,从而提取 更有效的特征。虽然标准卷积能够提供较好的图像分类性能,但往往会带来大量的参数和 计算量。因此,在[45],cui等人提出一种新的网络结构(litedepthwisenet),通过将标 准卷积分解为深度卷积和点态卷积,大大降低了训练参数的数量。ma等人提出了一种端 到端的深度反卷积网络[46],该网络采用非池化和反卷积的方法来恢复池化操作丢失的特 征信息,从而保留了hsis的大部分原始信息。在[47],yu等人提出一种基于多尺度上下 文聚合的膨胀卷积网络。同样地,为了解决池化层导致分辨率和覆盖范围损失的问题, pan等人提出了一种基于膨胀卷积的语义分割网络(dssnet)[48],这说明膨胀卷积对高 光谱图像处理具备一定的潜力。
[0005]
近年来,注意力机制在计算机视觉中也展现出巨大的潜力。在认知科学中,人类更倾 向于注意更重要的信息,且忽视其他信息。注意力机制可以看作是人类视觉的模仿,并在 计算机视觉的多个领域中得到广泛应用[49]-[51]。wang等人提出了一种挤压和激励模块 (se)[52]嵌入在resnet网络中。在[53],ma等人提出了一种双分支多注意力网络 (dbma)来提取重要的空间与光谱信息。同样地,li等人提出了一种双注意网络(danet) [54],且获得了较好的分类效果。为了进一步的提高hsis的分类性能,li等人又提出了 双分支双注意力网络(dbda)[55]。但由于注意力机制的空间注意力与通道注意力通常 是相互分离的,所以cui等人提出了一种新的双三重注意力网络(dtan)[56],该网络 通过捕获跨维的交互式信息实现对高光谱图像的有效分类。
[0006]
尽管现有基于深度学习的方法能有效提取高光谱图像特征,高光谱图像分类依然面临 着很多的挑战。例如,有限的训练样本[57]、巨大的计算成本[58],以及训练精度的下降 [59]-[60]。
技术实现要素:
[0007]
本发明的目的是为了解决现有利用深度学习进行高光谱图像分类方法中存在有限的 训练样本、巨大的计算成本,以及训练精度的下降的问题,而提出基于膨胀卷积的高光谱 图像分类方法。
[0008]
基于膨胀卷积的高光谱图像分类方法具体过程为:
[0009]
步骤一、采集高光谱图像数据集x和相对应的标签向量数据集y;
[0010]
步骤二、建立fecnet网络;
[0011]
所述fecnet网络为基于类反馈注意力机制的膨胀卷积网络;
[0012]
fecnet网络包括fecnet网络包括:输入层、第一三维卷积层、第一批归一化层bn 层、膨胀卷积单元、类反馈机制sfb、第二三维卷积层、第二批归一化层bn层、第二 relu激活层、光谱注意力块sab、第三批归一化层bn层、第三relu激活层、第三 dropout、第三全局最大池化层、fc、softmax和输出层;
[0013]
步骤三、将高光谱图像数据集x和相对应的标签向量数据集y输入到建立的fecnet 网络中,进行迭代优化,得到最优fecnet网络;
[0014]
步骤四、向最优fecnet网络中输入待测高光谱图像进行分类结果预测。
[0015]
本发明的有益效果为:
维膨胀卷积图;图4为标准卷积与膨胀卷积计算量和参数量关系图,(a)为参数量之间 的关系,(b)为计算量之间的关系;图5为本发明设计的膨胀卷积模块(ecb)图;图 6为光谱注意力机制模块(sab)图;图7为类反馈机制结构(sfa)图;图8为sfb 结构图;
[0024]
图9为ip场景的真实地物图,(a)为真实地物,(b)为ip数据集的标签;
[0025]
图10为up场景的真实地物图,(a)为真实地物,(b)为up数据集的标签;
[0026]
图11为ksc场景的真实地物图,(a)为真实地物,(b)为ksc数据集的标签;
[0027]
图12为sv场景的真实地物图,(a)为真实地物,(b)为sv数据集的标签;
[0028]
图13为ht场景的真实地物图,(a)为真实地物,(b)为ht数据集的标签;
[0029]
图14为ip数据集的分类结果(样本比例为3%)图,(a)为真实地物,(b)为 svm(68.76%),(c)为ssrn(90.25%),(d)为cdcnn(64.86%),(e)为pyresnet(85.65%), (f)为dbma(87.95%),(g)为dbda(93.58%),(h)为hybird-sn(82.18%),(i)为 a2s2k-resnet(92.55%),(j)为dssnet(48.32%),(k)为ecnet(95.33%),(l)为 fecnet(95.81%);
[0030]
图15为up数据集的分类结果(样本比例为0.5%)图,(a)为真实地物图,(b) 为svm(82.06%),(c)为ssrn(92.50%),(d)为cdcnn(87.94%),(e)为pyresnet(83.01%), (f)为dbma(91.80%),(g)为dbda(96.01%),(h)为hybird-sn(82.09%),(i)为 a2s2k-resnet(86.81%),(j)为dssnet(57.9%),(k)为ecnet(97.12%),(l)为fecnet(97.50%);
[0031]
图16为ksc数据集的分类结果(样本比例为5%)图,(a)为真实地物图,(b) 为svm(87.96%),(c)为ssrn(94.52%),(d)为cdcnn(89.33%),(e)为pyresnet(96.97%), (f)为dbma(94.12%),(g)为dbda(96.76%),(h)为hybird-sn(79.72%),(i)为 a2s2k-resnet(98.34%),(j)为dssnet(83.4%),(k)为ecnet(99.12%),(l)为 fecnet(99.27%);
[0032]
图17为sv数据集的分类结果(样本比例为0.5%)图,(a)为真实地物图,(b) 为svm(86.98%),(c)为ssrn(92.04%),(d)为cdcnn(88.36%),(e)为pyresnet(92.73%), (f)为dbma(92.95%),(g)为dbda(93.74%),(h)为hybird-sn(87.78%),(i)为 a2s2k-resnet(95.15%),(j)为dssnet(69.4%),(k)为ecnet(97.41%),(l)为 fecnet(97.85%);
[0033]
图18为ht数据集的分类结果(样本比例为2%)图,(a)为真实地物图(b)为 svm(84.12%)。(c)为ssrn(88.09%),(d)为cdcnn(74.64%),(e)为pyresnet(80.09%), (f)为dbma(90.73%),(g)为dbda(92.17%),(h)为hybird-sn(89.31%),(i)为 a2s2k-resnet(92.18%),(j)为dssnet(52.61%),(k)为ecnet(92.90%),(l)为 fecnet(93.43%);
[0034]
图19为比较输入的不同空间大小图;
[0035]
图20a为所有方法ip数据集的oa比较图;图20b为所有方法在up数据集上不同 训练样本比例的oa比较图;图20c为所有方法在up数据集上不同训练样本比例的oa 比较图;图20d为所有方法在up数据集上不同训练样本比例的oa比较图;图20e为所 有方法在up数据集上不同训练样本比例的oa比较图。
具体实施方式
[0036]
具体实施方式一:本实施方式基于膨胀卷积的高光谱图像分类方法具体过程为:
[0037]
步骤一、采集高光谱图像数据集x和相对应的标签向量数据集y;
[0038]
步骤二、建立fecnet网络;
[0039]
所述fecnet网络为基于类反馈注意力机制的膨胀卷积网络;
[0040]
fecnet网络包括fecnet网络包括:输入层、第一三维卷积层(1
×1×
7)、第一批 归一化层bn层、膨胀卷积单元、类反馈机制sfb、第二三维卷积层(1
×1×
7)、第二批 归一化层bn层、第二relu激活层、光谱注意力块sab、第三批归一化层bn层、第三 relu激活层、第三dropout、第三全局最大池化层、fc、softmax和输出层;
[0041]
步骤三、将高光谱图像数据集x和相对应的标签向量数据集y输入到建立的fecnet 网络中,进行迭代优化,得到最优fecnet网络;
[0042]
步骤四、向最优fecnet网络中输入待测高光谱图像进行分类结果预测。
[0043]
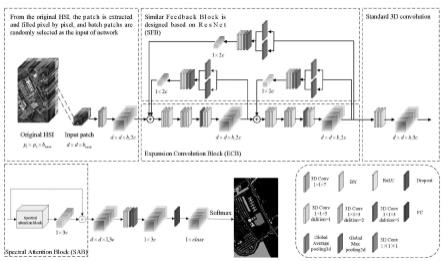
本发明构建的fecnet框架的流程图如图1所示。它主要由几个组件构成:膨胀卷积 块(ecb)、光谱注意力块(sab),以及类反馈机制(sfb)。特别地,设计的fecnet 网络与ecnet相比不同的是,fecnet加入了sfb。其中,采用ecb获取更具上下文信 息的特征,在相同卷积感受野的情况下,与标准卷积相比,该模块所需要的训练参数更少。 为了更好的提取重要的特征,且抑制无用的特征,sab模块用来强调波段的有效性。为 了进一步充分提高浅层特征与深层特征的表示能力,采用sfb模块将深层特征融合到浅 层特征,进行再次特征提取。
[0044]
fecnet网络的结构层次图主要由三个模块构成:基于resnet思想的类反馈机制模块 (sfb),能够扩大卷积感受野的膨胀卷积模块(ecb)及具有强调功能的光谱注意力模 块(sab)。此外,为了更有效地分类,将原始输入hsi进行逐像素样本处理并作为网 络的输入(左上角),网络的最后对获取的深层特征通过简单的分类结构进行分类。特别 地,所设计的ecnet不具备fecnet的类反馈机制模块(sfb)。
[0045]
提出的方法ecnet
[0046]
ecnet结构主要由膨胀卷积模块(ecb)和注意力机制模块(sab)构成。为了较好 的描述本文提出的ecb模块,将先对二维膨胀卷积及三维膨胀卷积的原理进行简单介绍, 然后将详细介绍ecnet中的组件ecb以及sab。
[0047]
1)二维及三维膨胀卷积
[0048]
近年来,卷积神经网络cnn由于其强大的特征提取能力,在深度学习领域得到广泛 应用。然而,由于传统的标准卷积其自身的局限性,多种不同的卷积方式得到衍生。其中, 膨胀卷积因其能够获取更大感受野的优点,在深度学习中也得到了广泛应用。
[0049]
为了说明二维膨胀卷积与标准卷积的区别,以3
×
3卷积核为例,二维膨胀卷积过程 如图2所示(其中,p
×
p表示空间大小)。从感受野大小的角度分析,感受野随着膨胀卷 积的扩张率的增大而增大;从计算复杂度的角度分析,膨胀卷积与标准卷积相比,在相同 卷积感受野的情况下(不包括扩张率为1),膨胀卷积训练所需的参数比标准卷积少,且 随着扩张率的增大,两者所需参数差异越大。为了更一般地表示二维膨胀卷积关系,假设 卷积核的大小为r
×
r,扩张率为d,等效卷积核大小为r'
×
r',则
[0050]
r'=r+(r-1)(d-1)
ꢀꢀ
(1)
[0051]
可以看出,当扩张率为1时,膨胀卷积与标准卷积结果一致;当扩张率为2时,膨胀 卷积的卷积核为3
×
3与标准卷积的卷积核为5
×
5的感受野一致;同理,当扩张率为3时, 膨胀卷积的卷积核为3
×
3与标准卷积的卷积核为7
×
7的感受野一致。因此,感受野的一般 的表达式为
[0052]ri+1
=ri+(r'-1)siꢀꢀ
(2)
[0053]
其中,ri为第i层的感受野,r
i+1
为第i+1层的感受野,si为前面i层的所有步长的乘 积。
[0054]
图2为二维膨胀卷积图,图2中从左到右,膨胀卷积的扩张率分别为1,2和3。三 角形表示注入的空洞点,且值为0。
[0055]
图3为三维膨胀卷积图,图3中从左到右,膨胀卷积的扩张率分别为1,2和3。深 色点表示扩展率为1时,卷积核对应位置的值,而浅色点表示注入的空洞点,且值为0。
[0056]
与二维膨胀卷积不同的是,三维膨胀卷积的原理及相应关系建立在三维空间上,如图 3所示。同样地,为了说明三维膨胀卷积的工作过程,图示采用的卷积核大小为3
×3×
3。 三维膨胀卷积与三维标准卷积的关系依然遵循二维卷积的规律。从感受野大小的角度来 看,感受野依然随着扩展率的增大而增大;从计算复杂度的角度来看,膨胀卷积与标准卷 积在相同卷积感受野的情况下(不包括扩张率为1),膨胀卷积训练所需的参数依然比标 准卷积少,且随着扩张率的增大,两者所需参数差异越大。
[0057]
具体实施方式二:本实施方式与具体实施方式一不同的是,所述步骤二中类反馈机制 sfb包括第一sfa、第二sfa、第三sfa;
[0058]
所述第一sfa包括:第四全局最大池化层、第四全局平均池化层、第五全局平均池 化层、第五三维卷积层(1
×1×
1)、第五批归一化层bn层、第五relu激活层;
[0059]
所述第二sfa包括:第六全局最大池化层、第六全局平均池化层、第七全局平均池 化层、第七三维卷积层(1
×1×
1)、第七批归一化层bn层、第七relu激活层;
[0060]
所述第三sfa包括:第八全局最大池化层、第八全局平均池化层、第九全局平均池 化层、第九三维卷积层(1
×1×
1)、第九批归一化层bn层、第九relu激活层。
[0061]
其它步骤及参数与具体实施方式一相同。
[0062]
具体实施方式三:本实施方式与具体实施方式一或二不同的是,所述步骤二中膨胀卷 积单元包括第一膨胀卷积模块ecb和第二膨胀卷积模块ecb;
[0063]
所述第一膨胀卷积模块ecb包括:第十膨胀卷积层(扩展率为1,卷积核大小1
×1×
3)、 第十批归一化层bn、第十relu激活层、第十一膨胀卷积层(扩展率为2,卷积核大小 1
×1×
3)、第十一批归一化层bn、第十一relu激活层、第十二膨胀卷积层(扩展率为 3,卷积核大小1
×1×
3)、第十二批归一化层bn、第十二relu激活层;
[0064]
所述第二膨胀卷积模块ecb包括:第十三膨胀卷积层(扩展率为1,卷积核大小 1
×1×
3)、第十三批归一化层bn、第十三relu激活层、第十四膨胀卷积层(扩展率为 2,卷积核大小1
×1×
3)、第十四批归一化层bn、第十四relu激活层、第十五膨胀卷积 层(扩展率为3,卷积核大小1
×1×
3)、第十五批归一化层bn、第十五relu激活层。
[0065]
其它步骤及参数与具体实施方式一或二相同。
[0066]
具体实施方式四:本实施方式与具体实施方式一至三之一不同的是,所述fecnet 网络连接关系为:
[0067]
输入层连接第一三维卷积层,第一三维卷积层连接第一批归一化层bn,第一批归一 化层bn连接第一膨胀卷积模块ecb,第一膨胀卷积模块ecb的输出分别连接第一sfa 和第二膨胀卷积模块ecb;
平均池化层的输入,第五全局平均池化层的输出连接第五三维卷积层(1
×1×
1),第五三 维卷积层的输出连接第五批归一化层bn层,第五批归一化层bn层的输出连接第五relu 激活层;
[0085]
所述第二膨胀卷积模块ecb的输出分别作为第二sfa的输入、第三sfa的输入和第 二三维卷积层的输入;具体过程为:
[0086]
第二膨胀卷积模块ecb的输出分别连接第二sfa中的第六全局最大池化层和第六全 局平均池化层,第六全局最大池化层的输出和第六全局平均池化层的输出共同作为第七全 局平均池化层的输入,第七全局平均池化层的输出连接第七三维卷积层(1
×1×
1),第七 三维卷积层的输出连接第七批归一化层bn层,第七批归一化层bn层的输出连接第七 relu激活层;
[0087]
第二膨胀卷积模块ecb的输出分别连接第三sfa中的第八全局最大池化层和第八全 局平均池化层,第八全局最大池化层的输出和第八全局平均池化层的输出共同作为第九全 局平均池化层的输入,第九全局平均池化层的输出连接第九三维卷积层(1
×1×
1),第九 三维卷积层的输出连接第九批归一化层bn层,第九批归一化层bn层的输出连接第九 relu激活层。
[0088]
其它步骤及参数与具体实施方式一至六之一相同。
[0089]
具体实施方式八:本实施方式与具体实施方式一至七之一不同的是,所述第二relu 激活层的输出作为光谱注意力块sab的输入;
[0090]
光谱注意力块sab的输出和第二relu激活层的输出共同作为第三批归一化层bn 的输入;具体过程为:
[0091]
第二relu激活层的输出作为光谱注意力块sab的输入,光谱注意力块sab对第二 relu激活层的输出进行变形,变形后进行转置得到x1;光谱注意力块sab对第二relu 激活层的输出进行变形,得到x2;光谱注意力块sab对第二relu激活层的输出进行变 形,得到x3;对x1和x2进行矩阵乘法,矩阵乘法后输入激活函数层f(
·
),得到g;g 的输出、x2的输出和x3的输出进行矩阵乘法,矩阵乘法后进行变形,将变形后输出与第 二relu激活层的输出进行矩阵相加,输出图像;
[0092]
sab组件:在神经网络当中,注意力机制能够动态管理信息流和特征,从而改善学 习效果。该机制过滤掉无关刺激,并帮助网络处理长期的依赖关系。为了关注有用特征, 本文在网络中设计了一个光谱注意力机制模块(sab)。下面内容将详细介绍所设计的 sab的工作过程。
[0093]
sab结构如图6所示。可以看出,光谱注意力机制是通过理解光谱通道之间的关系, 且将每个输入元素设置为0至1的阈值,该阈值能够体现该元素在特征中的重要程度或者 依赖程度。具体地说,假设输入为p∈rd×d×k(其中,d
×
d为空间大小,k为通道数量), 为方便计算不同位置之间的依赖关系,首先将输入进行相关变形或转置得到x1,x2及x3, 将x1和x2进行矩阵乘法及f(
·
);
[0094]
所述激活函数层f(
·
)=softmax(
·
)
ꢀꢀ
(9)
[0095]
f(
·
)表示激活函数层,该函数能够将注意力图整理成每个通道加权之和为1的概率 分布,记为g∈rk×k[0096][0097]
这里,g
ji
为第i个通道对第j个通道的权重系数,即第i个通道对第j个通道的重要 程度,xn(n=1,2,...,k)表示x的第n个通道。设α为注意力参数(若α=0时,注意力机 制不工作)
[0098][0099]
这里,yn(n=1,2,...,k)表示y∈rd×d×k的第n个通道。
[0100]
其它步骤及参数与具体实施方式一至七之一相同。
[0101]
具体实施方式九:本实施方式与具体实施方式一至八之一不同的是,所述第十膨胀卷 积层(扩展率为1,卷积核大小1
×1×
3)、第十一膨胀卷积层(扩展率为2,卷积核大小 1
×1×
3)、第十二膨胀卷积层(扩展率为3,卷积核大小1
×1×
3)、第十三膨胀卷积层(扩 展率为1,卷积核大小1
×1×
3)、第十四膨胀卷积层(扩展率为2,卷积核大小1
×1×
3)、 第十五膨胀卷积层(扩展率为3,卷积核大小1
×1×
3)中每个膨胀卷积层的参数量和计算 量如下
[0102]fexp
=r2mnh'w'
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(7)
[0103]fexp
=hwr2mnh'w'
ꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀꢀ
(8)
[0104]
其中,f
exp
表示膨胀卷积的参数量,f
exp
表示膨胀卷积的计算量,r2表示卷积核的 空间大小,m为输入的特征图数量,n为输出的特征图数量,h为输入特征图的高度, w为输入特征图的宽度,h'为输出特征图的高度,w'为输出特征图的宽度。
[0105]
ecb组件
[0106]
在深度学习中,卷积是非常有效的特征提取方法。具体地说,设输入为x∈rh×w×
l
(其 中,h,w和l分别为输入的高度,宽度和通道数量),输出为y∈r
h'
×
w'
×
l'
,则输入经 过卷积运算之后
[0107]
y=x*w+b
ꢀꢀ
(4)
[0108]
这里,w∈rr×r×m×n为加权张量(其中,r
×
r为卷积核的空间大小,m,n分别为输入和输 出的特征图数量),b为偏置项;为了进一步比较膨胀卷积与标准卷积,假设膨胀卷积的 扩展率为d,则标准卷积的参数量和计算量如下
[0109]fstd
=(r+2(d-1))2mnh'w'
ꢀꢀꢀ
(5)f
std
=hw(r+2(d-1))2mnh'w'
ꢀꢀ
(6)
[0110]
这里,f
std
表示标准卷积的参数量,f
std
表示标准卷积的计算量。由上述介绍可知,膨胀 卷积是在不降低图像分辨率,也不增加额外参数和计算量的情况下,扩大卷积感受野。膨 胀卷积的参数量和计算量如下
[0111]fexp
=r2mnh'w'
ꢀꢀꢀꢀ
(7)f
exp
=hwr2mnh'w'
ꢀꢀꢀꢀ
(8)
[0112]
可见,标准卷积是膨胀卷积的一个特殊形式。其中,f
exp
表示膨胀卷积的参数量,f
exp
表示膨胀卷积的计算量。
[0113]
为了更直观地表示在标准卷积感受野与膨胀卷积的等效感受野一致的情况下,标准卷 积与膨胀卷积计算量和参数量的区别,图4给出了两者的关系。从图中4可以看出,随
着 感受野的增大,膨胀卷积的计算量和参数量均不变化,而标准卷积的计算量和参数量呈指 数型增长。
[0114]
对于高光谱图像,提取丰富的多尺度信息能够大幅改善分类的性能。然而,在进行网 络设计时,依然存在着一些矛盾,如感受野和计算复杂度之间的矛盾,大的感受野和小的 感受野之间的矛盾。为了比较好地解决以上矛盾,本发明采用膨胀卷积作为提出网络的主 要特征提取方法。设计的ecb如图5所示。该模块主要有三部分组成,分别为膨胀卷积 层,批归一化层(bn),以及激活函数单元(relu)。其中,膨胀卷积层表示为“卷积 核大小-输出特征图数量-扩张率”。例如,第一膨胀卷积层1
×1×
3-c-1表示卷积核大小为 1
×1×
3,输出特征图数量为c,扩张率为1。
[0115]
为了进一步体现膨胀卷积的优势,设计中采用多个膨胀卷积层串行连接的方式来搭建 网络。根据膨胀卷积的原理,这种方式能够使得感受野最大化。简单地说,当前层的感受 野大小是该层扩张的感受野叠加上一层的感受野。由于本发明提出的卷积核空间大小为 1
×
1,故卷积核为1
×1×
3的三维膨胀卷积的感受野计算原理与二维膨胀卷积的原理类似。
[0116]
设计的ecnet采用两个ecb串行连接,且ecb中三个膨胀卷积层的扩张率分别为1, 2和3。
[0117]
ecnet的改进方法fecnet:在ecnet的基础上引入类反馈模块(sfb),该模块由 多个类反馈机制(sfa)密集连接构成。
[0118]
在深度学习中,由于浅层特征包含更多的位置及细节信息,而深层特征包含更强的语 义信息。浅层特征的提取能够有助于深层特征的提取,而深层特征也可以为浅层特征提供 反馈。因此,将深层的多尺度特征与浅层特征融合,是提高高光谱图像分类性能的一个重 要手段。因此,本文设计了sfa,该机制通过深层特征以一种注意图的方式反馈给浅层 特征,浅层特征与反馈注意图融合,从而实现深层特征与浅层特征的深度融合。以下将详 细介绍sfa的结构。
[0119]
sfa的具体结构如图7所示。假设中间输入x0为2c个rd×d×b(其中,d
×
d为立方体 的空间大小,b为通道数量),x0经过一个最大池化层和平均池化层之后生成两个映射, 分别x1和x2。为了平衡局部信息与全局不变性,将所得到的x1和x2进行级联操作得到 x3。然后,将结果经过一个全局平均池化层得到x。最后,x与k卷积得到校正矩阵y, 即
[0120]
y=g(x)=xk+b
ꢀꢀ
(4)
[0121]
上式中,g(
·
)表示卷积函数,m和n分别表示卷积核的行和列,b表示卷积的偏置项。在 sfb中,x={x|x1,x2,...,x
4c
}∈r1×1×
4c
,k={k|k1,k2,...,k
2c
}∈r1×1×
2c
,b=[b1,b2,...,b
2c
]
t
, y∈r1×
2c
。
[0122]
为了充分地反馈后面层的语义信息,sfa被密集连接,构成sfb,如图8所示。这种 密集连接方法是受到resnet思想的启发,该方法将深层特征反馈给前面所有层。深层特 征经过sfb模块得到反馈的校正矩阵,该矩阵能够表示深层特征的语义信息,将所得到 的校正矩阵加载到浅层的特征中,使得浅层特征能够得到深层特征相关的权重初值。这种 类反馈模块能够很好地结合深层与浅层特征信息,且形成深层特征与浅层特征的直接相关 性,这对于特征的有效提取非常有利。
[0123]
其它步骤及参数与具体实施方式一至八之一相同。
[0124]
具体实施方式十:本实施方式与具体实施方式一至九之一不同的是,所述第十膨胀卷 积层扩展率为1,卷积核大小为1
×1×
3;第十一膨胀卷积层扩展率为2,卷积核大小为 1
×1×
3;第十二膨胀卷积层扩展率为3,卷积核大小为1
×1×
3;第十三膨胀卷积层扩展率 为1,卷积核大小为1
×1×
3;第十四膨胀卷积层扩展率为2,卷积核大小为1
×1×
3;第十 五膨胀卷积层扩展率为3,卷积核大小为1
×1×
3;第一三维卷积层卷积核大小为1
×1×
7; 第二三维卷积层卷积核大小为1
×1×
7;第五三维卷积层卷积核大小为1
×1×
1;第七三维卷 积层卷积核大小为1
×1×
1;第九三维卷积层卷积核大小为1
×1×
1。
[0125]
其它步骤及参数与具体实施方式一至九之一相同。
[0126]
采用以下实施例验证本发明的有益效果:
[0127]
实施例一:
[0128]
为验证提出的ecnet和改进的fecnet的有效性,在五个hsi数据集上进行了大量的 实验。
[0129]
a、实验数据描述:实验采用四种普遍使用的公开数据集和一种更高分辨率的数据集, 包括印度松树(ip)、帕维亚大学(up)、肯尼迪航空中心(ksc),萨利纳斯山谷(sv) 以及休斯顿大学(ht)数据集。数据集的彩色复合图像,地物真实分类图以及每一类的 详细信息如图9-13所示。
[0130]
1)ip:印度松树数据集是1992年6月由机载可见红外成像光谱仪(aviris)传感器 捕获而来。数据集的空间大小为145
×
145,波段数为220,波长范围为0.2-2.4微米。其中, 除去吸水和低信噪比的波带数(波段为108-112,150-163和220),还剩下200个波段可 用于实验。该图像的真实地物类别为16(如图9所示)。2)up:帕维亚大学数据集是 由反射光学光谱成像系统(rosis-3)传感器获得。该数据集包含9个真实地物类别,图 像大小为610
×
340,且空间分辨率为1.3m,具有115个波段,波长范围为0.43-0.86微米。 除13个噪声波段外,还剩下103个波段被用于实验(如图10所示)。3)ksc:肯尼迪 航空中心数据集的获取工具与ip数据集一样,是1996年在弗罗里达州使用aviris传感 器捕获而来。该图像的空间大小为512
×
614,除去吸水带,还剩下176个波段可用于实验。 图像的空间分辨率为20m,光谱范围包括400-2500纳米。该图像包含13个不同的土地覆 盖类别(如图11所示)。4)sv:萨利纳斯山谷数据集也是由aviris传感器收集的。该 数据集的特点是不同地物覆盖类别规律性分布。图像包含16个地物类别且空间大小为 512
×
217,除去吸水波段(108-112,154-167和224),还剩下204个波段用于实验(如 图12所示)。5)ht:休斯顿大学数据集是2012年6月在休斯顿大学校园由紧凑型机载 光谱成像仪(casi)传感器获取。这个场景的空间大小为349
×
1905,且波段数为114, 波长范围为380-1050纳米。该图像包含15个地物覆盖类别(如图13所示)。
[0131]
b、实验设置:本发明提出的网络批处理大小和训练轮次分别设置为16和200,且采 用adam算法进行优化。在实验过程中,学习率的设置范围为0.001,0.005,0.0001,0.0005 和0.00005,通过对每一个学习率进行多次实验,最终将学习率设置为0.0005。设计的网 络采用pytorch框架设计与实现。所有的数据结果都是30次实验结果的平均值,且都在 相同的配置下实现的。其中,实验的硬件平台是intel(r)core(tm)i9-9900k cpu、 nvidia geforce rtx 2080ti gpu和32gbram,实验软件平台基于windows10vscode操作系统,包括cuda10.0、pytorch 1.2.0和python 3.7.4。
[0132]
为了评估不同方法的分类性能,使用整体精度(oa)、平均精度(aa)和卡帕系数 (kappa)作为评价指标。
[0133]
c、分类结果:为了验证本文方法ecnet和fecnet在高光谱图像分类中的有效性, 所提出方法与两类不同的方法进行比较:一类是经典方法svm,另一类是8种基于深度 学习的方法,包括ssrn,cdcnn,pyresnet,dbma,dbda,hybrid-sn,a2s2kresnet和 dssnet。
[0134]
svm是一种基于径向基函数(rbf)的光谱分类器。cdcnn是一种深度上下文cnn, 通过联合单个像素向量的空间光谱关系最优地探索局部上下文。pyresnet是一种resnet 的改进,它在普通的cnn中加入附加链路,且在所有的conv层逐渐增加特征图的维度。 与上述方法不同的是,dbma与dbda设计了双分支结构,且分别用来提取空间和光谱 特征。hybrid-sn是一种3d-cnn和2d-cnn混合模型,该模型分别使用3d-cnn与 2d-cnn提取光谱和空间特征。a2s2kresnet使用自适应光谱与空间核改进了resnet,通 过端到端的训练捕获更具鉴别特征的空间光谱特征。dssnet是一种基于膨胀卷积的分割 网络,旨在解决池化操作可能会导致分辨率和覆盖面积损失的问题。
[0135]
由于不同的空间输入大小对分类性能的影响较大,为了公平比较,将所有方法的输入 空间大小设置为9
×
9。此外,ip、up、ksc、sv及ht数据集的训练样本百分比设为3%、 0.5%、5%、0.5%及2%。
[0136]
ip数据集的结果:表ⅰ和图14给出了ecnet与fecnet方法与其他方法比较的数值和 可视化结果。在表ⅰ可以看到,ecnet和fecnet的三个指标oa、aa和kappa均高于其 他方法。其中,fecnet获得最佳的oa(95.81%)、aa(93.48%)和kappa(95.22%), 而ecnet获得的oa、aa和kappa仅比fecnet的结果低0.48%、0.41和0.54%。此外, 与其他方法相比,ecnet的oa比其他比较方法高出26.57%(svm)、5.08%(ssrn)、 30.47%(cdcnn)、9.68%(pyresnet)、7.38%(dbma)、1.75%(dbda)、13.15% (hybrid-sn)、2.78%(a2s2k-resnet)以及47.01%(dssnet)。图14是可视化结果。 由于原始ip数据集不同类别之间混合严重,很多先进的比较方法分类结果不够理想,比 如hybrid-sn和dssnet。同样,从图14的分类图可以看出,svm、ssrn、cdcnn、 pyresnet和dssnet的分类图存在较多的噪声。此外,dbda、dbda、hybrid-sn以及 a2s2k-resnet也存在很多错误的分类。然而,本发明提出的方法ecnet和fecnet得到 了很好的分类结果图,如图13。
[0137]
表ⅰ使用3%训练样本的ip数据集分类结果
[0138][0139][0140]
图14为ip数据集的分类结果(样本比例为3%)图,(a)为真实地物,(b)为 svm(68.76%),(c)为ssrn(90.25%),(d)为cdcnn(64.86%),(e)为pyresnet(85.65%), (f)为dbma(87.95%),(g)为dbda(93.58%),(h)为hybird-sn(82.18%),(i)为 a2s2k-resnet(92.55%),(j)为dssnet(48.32%),(k)为ecnet(95.33%),(l)为 fecnet(95.81%);
[0141]
up数据集的结果:表ⅱ和图15给出了具体的分类结果。up数据集有9个类别,比 ip数据集少了7个,up光谱波段数约是ip的一半,但从分类结果来看,up数据集更易 于分类。从表ⅱ可以看出,基于双分支结构的dbma和dbda在up数据集上获得的结 果比ssrn、cdcnn、
pyresnet、hybrid-sn以及dssnet的结果要好。然而,本文提出 的ecnet与fecnet的oa、aa和kappa比上述比较方法更高。ecnet与fecnet两个 方法当中,ecnet的三个指标oa、aa和kappa稍低于fecnet。从分类图来看,如图 15所示,标签分类错误较多的方法是svm、pyresnet、a2s2k-resnet以及dssnet。从 表ⅲ的分类结果也能得到相同的结论。然而,采用本文方法ecnet和fecnet得到的分类 结果图效果最好,特别是红色框内的类别,如图15的(k)和(l)。
[0142]
表ⅱ使用0.5%训练样本的up数据集分类结果
[0143][0144][0145]
图15为up数据集的分类结果(样本比例为0.5%)图,(a)为真实地物图,(b) 为svm(82.06%),(c)为ssrn(92.50%),(d)为cdcnn(87.94%),(e)为pyresnet(83.01%), (f)为dbma(91.80%),(g)为dbda(96.01%),(h)为hybird-sn(82.09%),(i)为 a2s2k-resnet(86.81%),(j)为dssnet(57.9%),(k)为ecnet(97.12%),(l)为 fecnet(97.50%);
[0146]
ksc数据集的结果:表ⅲ和图16分别给出了所有方法分类结果。通过表ⅲ可以看到, 与表ⅱ中up数据集的分类结果相比,ksc数据集的分类结果有较大的改善,这得益于 ksc数据集内包含的噪声较少,以及ksc数据集的空间分辨率比up更高。此外,更值 得注意的是,本文提出的ecnet和fecnet依然得到了最高的oa、aa和kappa值。其 中,fecnet的oa、aa和kappa依然稍高于ecnet。而ecnet与其他的比较方法相比, ecnet的oa高出11.16%(svm)、4.60%(ssrn)、9.79%(cdcnn)、5.15%(pyresnet)、 5.00%(dbma)、2.36%(dbda)、19.40%(hybrid-sn)、0.78%(a2s2k-resnet) 以及15.72%(dssnet)。不同方法对ksc数据
集的分类结果见图16。oak/broadleaf(c5) 是ksc数据集中难以分类的类别。为了更易于观察,将分类结果图的部分区域放大,如 图16的红色框标记处。可以看出,对于那些用于比较的方法,除了a2s2k-resnet的c5 分类效果较好,svm、ssrn、cdcnn、pyresnet、dbma、dbda、hybrid-sn以及 dssnet的c5类别几乎全被错误分类。然而,与上述比较方法相比,ecnet与fecnet 分类效果更好。
[0147]
表ⅲ使用5%训练样本的ksc数据集分类结果
[0148][0149][0150]
图16为ksc数据集的分类结果(样本比例为5%)图,(a)为真实地物图,(b) 为svm(87.96%),(c)为ssrn(94.52%),(d)为cdcnn(89.33%),(e)为pyresnet(96.97%), (f)为dbma(94.12%),(g)为dbda(96.76%),(h)为hybird-sn(79.72%),(i)为 a2s2k-resnet(98.34%),(j)为dssnet(83.4%),(k)为ecnet(99.12%),(l)为 fecnet(99.27%);
[0151]
sv数据集的分类结果:每个方法的分类结果如表ⅳ和图17。从表ⅳ可以看出,对于 grapes-untrained(c8),本发明的方法ecnet和fecnet能得到较好的分类结果,而其他 方
法对该类别的分类效果较差,这说明对于较难分类的类别,本文提出方法依然能有效地 提取特征,进一步说明了提出方法具有较强的鲁棒性。此外,与其他比较方法相比,ecnet 的oa高出10.43%(svm)、5.37%(ssrn)、9.05%(cdcnn)、4.68%(pyresnet)、 4.46%(dbma)、3.67%(dbda)、9.63%(hybrid-sn)、2.26%(a2s2k-resnet)以 及28.01%(dssnet)。所有方法的可视化结果如图17所示。可以看出,ecnet与fecnet 的分类图比其他分类图更加平滑,这证明了在类别比较相似且土地覆盖具有规律性的数据 集中,本文提出方法更具有优越性。
[0152]
表ⅳ使用0.5%训练样本的sv数据集分类结果
[0153]
[0154][0155]
图17为sv数据集的分类结果(样本比例为0.5%)图,(a)为真实地物图,(b) 为svm(86.98%),(c)为ssrn(92.04%),(d)为cdcnn(88.36%),(e)为pyresnet(92.73%)。 (f)为dbma(92.95%),(g)为dbda(93.74%),(h)为hybird-sn(87.78%),(i)为 a2s2k-resnet(95.15%),(j)为dssnet(69.4%),(k)为ecnet(97.41%),(l)为 fecnet(97.85%);
[0156]
ht数据集的分类结果:表
ⅴ
和图18给出了所有方法的分类结果。从图18中的(a)、 (k)和(l)可以看出,ecnet和fecnet的分类图与真实地物图的视觉效果基本一致。 从表
ⅴ
可以看出,提出方法在ht数据集上能提供最高的oa、aa和kappa。其中,fecnet 与其他比较方法中三种指标最高的a2s2k-resnet相比,fecnet的oa、aa和kappa分 别高出1.25%、0.37%和1.34%。
[0157]
表
ⅴ
使用2%训练样本的ht数据集分类结果
[0158][0159]
图18为ht数据集的分类结果(样本比例为2%)图,(a)为真实地物图,(b)为 svm(84.12%),(c)为ssrn(88.09%),(d)为cdcnn(74.64%),(e)为pyresnet(80.09%), (f)为dbma(90.73%),(g)为dbda(92.17%),(h)为hybird-sn(89.31%),(i)为 a2s2k-resnet(92.18%),(j)为dssnet(52.61%),(k)为ecnet(92.90%),(l)为 fecnet(93.43%)。
[0160]
综上分析,本发明提出的ecnet和fecnet方法,在五个数据集上均得到了最好的分 类结果,这充分证明了提出方法具有很强的泛化能力。在类别较多且分布不均的ip数据 集和分辨率更高的ht数据集,ecnet和fecnet依然能够获得比其他方法更好的分类精 度。此外,在类别比较相似的sv数据集与波段较少的up数据集,我们的方法能够将比 较难区分的类别实现高精度分类。
[0161]
提出方法的分析
[0162]
将对本发明所提出方法的参数进行分析,且选择模型中适合的参数。
[0163]
1)提出方法各模块的贡献:为了验证本文提出方法中各模块的有效性,对各模块进行 了消融实验,结果如表ⅵ所示。从表中可以看出,与标准cnn相比,提出的ecb能提 供更高的oa值,这表明通过膨胀卷积来扩大光谱特征提取的感受野比较有效。此外,我 们在ecb的基础上加入了sfb模块,该模块能将深层特征反馈给浅层特征,使得浅层特 征能够进行自我调节。实验结果表明,sfb能够进一步提高分类性能。对于数据集ip与 ht,当网络加入ecb与sfb模块后,分类效果改善更加明显。
[0164]
表ⅵ提出方法采用不同模块的oa值比较(%)
[0165][0166]
2)比较不同的输入大小:参数的设置能够影响分类性能,而输入的空间大小对网络的 分类性能影响较大。为了进一步验证不同输入大小对性能的影响,选择空间输入大小为5
ꢀ×
5、7
×
7、9
×
9、11
×
11以及13
×
13进行实验。图19给出了fecnet方法的输入空间 大小比较结果。从图19可以看出:第一,当输入的空间尺寸较小,训练所获得的oa值 相对较低。第二,对于ip、up、ksc数据集,oa在达到较优性能后,随着空间大小的 增加,oa值变化不大。而对于sv与ht数据集,oa先上升后下降。第三,对于数据集 ip、up和ksc在空间尺寸为9
×
9的时候取得最优的性能。虽然sv和ht在空间尺寸为 9
×
9时没能获得最优分类性能,但也取得了次优的分类性能。因此,本次实验所有数据 集采用的输入空间大小为9
×
9。
[0167]
3)不同方法的运行时间和参数量比较:表ⅶ给出了所有方法的训练时间和参数量的 比较结果。由于pyresnet在cnn中加入附加链路,且在所有的conv层逐渐增加特征图 的维度,这就导致该模型训练需要的参数较大。ecnet与fecnet基于膨胀卷积建立模型, 使得网络所需要的参数相对较少。同样地,ecnet与fecnet与基于双分支的dbma和 dbda相比,两者所需的训练参数与时间相差不大,但是ecnet与fecnet的性能更好。 虽然基于膨胀卷积的dssnet参数量与ecnet和fenet相差不大,但训练时间较长,特 别是ip和sv数据集。综上分析,与所有方法相比,ecnet与fecnet在五个数据集上训 练所需的参数较少,且运行时间也比较适中。
[0168]
表ⅶ所有比较的方法与提出方法训练所需运行时间(s)和参数
[0169]
[0170][0171]
4)不同方法在不同训练样本比例的oa比较:所有方法在五个数据集中不同训练样本比例下的oa比较结果如图20所示。这里,纵坐标表示整体精度oa,横坐标表示训练样本比例。从图20可以看出,ecnet与fecnet在所有样本比例中的oa,均比其他方法得到的oa更高,这说明本文提出方法不仅在小样本下能够实现高精度分类,在大样本下依然能够保持最佳的分类性能,进一步证明了提出方法的有效性。
[0172]
图20a为所有方法ip数据集的oa比较图;图20b为所有方法在up数据集上不同训练样本比例的oa比较图;图20c为所有方法在up数据集上不同训练样本比例的oa比较图;图20d为所有方法在up数据集上不同训练样本比例的oa比较图;图20e为所有方法在up数据集上不同训练样本比例的oa比较图。
[0173]
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
[0174]
[1]l.liang,l.di,l.zhang,m.deng,z.qin,s.zhao,andh.lin,“estimationofcroplaiusinghyperspectralvegetationindicesandahybridinversionmethod,”remotesens.environ.,vol.165,pp.123
–
134,aug.2015.[2]x.yangandy.yu,“estimatingsoilsalinityundervariousmoistureconditions:anexperimentalstudy,”ieeetrans.geosci.remotesens.,vol.55,no.5,pp.2525
–
2533,may2017.[3]n.yokoya,j.c.-w.chan,andk.segl,“potentialofresolutionenhancedhyperspectraldataformineralmappingusingsimulatedenmapandsentinel-2images,”remotesens.,vol.8,no.3,pp.172
–
189,feb.2016.[4]s.li,r.dian,l.fang,andj.m.bioucas-dias,“fusinghyperspectralandmultispectralimagesviacoupledsparsetensorfactorization,”ieeetrans.imageprocess.,vol.27,no.8,pp.4118
–
4130,aug.2018.[5]s.zhang,j.li,z.wu,anda.plaza,“spatialdiscontinuity-weightedsparseunmixingofhyperspectralimages,”ieeetrans.geosci.remotesens.,vol.56,no.10,pp.5767
–
5779,oct.2018.[6]p.ghamisi,n.yokoya,j.li,w.liao,s.liu,j.plaza,b.rasti,anda.plaza,“advancesinhyperspectralimageandsignalprocessing:acomprehensiveoverviewofthestateoftheart,”ieeegeosci.remotesens.mag.,vol.5,no.4,pp.37
–
78,dec.2017.[7]f.melganiandl.bruzzone,“classificationofhyperspectralremotesensingimageswithsupportvectormachines,”ieeetrans.geosci.remotesens.,vol.42,no.8,pp.1778
–
1790,aug.2004.[8]j.li,j.m.bioucas-dias,anda.plaza,“semisupervisedhyperspectralimagesegmentationusingmultinomiallogisticregressionwithactivelearning,”ieeetrans.geosci.remotesens.,vol.48,no.11,pp.4085
–
4098,nov.2010.[9]j.li,j.m.bioucas-dias,anda.plaza,“spectral
–
spatialhyperspectralimagesegmentationusingsubspacemultinomiallogisticregressionandmarkovrandom
fields,”ieeetrans.geosci.remotesens.,vol.50,no.3,pp.809
–
823,mar.2012.[10]b.duandl.zhang,“random-selection-basedanomalydetectorforhyperspectralimagery,”ieeetrans.geosci.remotesens.,vol.49,no.5,pp.1578
–
1589,may2011.[11]b.duandl.zhang,“targetdetectionbasedonadynamicsubspace,”patternrecog.,vol.47,no.1,pp.344
–
358,jan.2014.[12]g.licciardi,p.r.marpu,j.chanussot,andj.a.benediktsson,“linearversusnonlinearpcafortheclassificationofhyperspectraldatabasedontheextendedmorphologicalprofiles,”ieeegeosci.remotesens.lett.,vol.9,no.3,pp.447
–
451,may2012.[13]a.villa,j.a.benediktsson,j.chanussot,andc.jutten,“hyperspectralimageclassificationwithindependentcomponentdiscriminantanalysis,”ieeetrans.geosci.remotesens.,vol.49,no.12,pp.4865
–
4876,dec.2011.[14]t.v.bandos,l.bruzzone,andg.camps-valls,“classificationofhyperspectralimageswithregularizedlineardiscriminantanalysis,”ieeetrans.geosci.remotesens.,vol.47,no.3,pp.862
–
873,mar.2009.[15]p.ghamisietal.,“newfrontiersinspectral-spatialhyperspectralimageclassification:thelatestadvancesbasedonmathematicalmorphology,markovrandomfields,segmentation,sparserepresentation,anddeeplearning,”ieeegeosci.remotesens.mag.,vol.6,no.3,pp.10
–
43,sep.2018.[16]l.he,j.li,c.liu,ands.li,“recentadvancesonspectral-spatialhyperspectralimageclassification:anoverviewandnewguidelines,”ieeetrans.geosci.remotesens.,vol.56,no.3,pp.1579
–
1597,mar.2018.[17]j.a.benediktsson,j.palmason,andj.r.sveinsson,“classificationofhyperspectraldatafromurbanareasbasedonextendedmorphologicalprofiles,”ieeetrans.geosci.remotesens.,vol.43,no.3,pp.480
–
491,mar.2005.[18]g.camps-valls,l.gomez-chova,j.munoz-mar~
′
1,j.vila-frances,
′
andj.calpe-maravilla,“compositekernelsforhyperspectralimageclassification,”ieeetrans.geosci.remotelett.,vol.3,no.1,pp.93
–
97,jan.2006.[19]ma.fauvel,j.chanussot,andj.a.benediktsson,“aspatial
–
spectralkernel-basedapproachfortheclassificationofremote-sensingimages,”patternrecog.,vol.45,no.1,pp.381
–
392,jan.2012.[20]y.chen,n.m.nasrabadi,andt.d.tran,“hyperspectralimageclassificationusingdictionary-basedsparserepresentation,”ieeetrans.geosci.remotesens.,vol.49,no.10,pp.3973
–
3985,oct.2011.[21]l.fang,s.li,x.kang,andj.a.benediktsson,“spectral
–
spatialhyperspectralimageclassificationviamultiscaleadaptivesparserepresentation,”ieeetrans.geosci.remotesens.,vol.52,no.12,pp.7738
–
7749,dec.2014.[22]l.fang,c.wang,s.li,andj.a.benediktsson,“hyperspectralimageclassificationviamultiple-feature-basedadaptivesparserepresentation,”ieeetrans.instrum.meas.,vol.66,no.7,pp.1646
–
1657,jul.2017.[23]s.li,t.lu,l.fang,x.jia,andj.a.benediktsson,“probabilisticfusionofpixel-levelandsuperpixel-levelhyperspectralimageclassification,”ieeetrans.geosci.remote
sens.,vol.54,no.12,pp.7416
–
7430,dec.2016.[24]t.lu,s.li,l.fang,x.jia,andj.a.benediktsson,“fromsubpixeltosuperpixel:anovelfusionframeworkforhyperspectralimageclassification,”ieeetrans.geosci.remotesens.,vol.55,no.8,pp.4398
–
4411,aug.2017.[25]l.fang,n.he,s.li,p.ghamisi,andj.a.benediktsson,“extinctionprofilesfusionforhyperspectralimagesclassification,”ieeetrans.geosci.remotesens.,vol.56,no.3,pp.1803
–
1815,mar.2018.[26]a.plazaetal.,“recentadvancesintechniquesforhyperspectralimageprocessing,”remotesens.environ.,vol.113,no.1,pp.110
–
122,sep.2009.[27]a.bordes,x.glorot,j.weston,andy.bengio,“jointlearningofwordsandmeaningrepresentationsforopen-textsemanticparsing,”inproc.int.conf.art.intell.stat,2012,pp.127
–
135.[28]b.rastietal.,“featureextractionforhyperspectralimagery:theevolutionfromshallowtodeep,”ieeegeosci.remotesens.mag.,vol.8,no.4,pp.60
–
88,dec.2020.[29]x.zhang,y.liang,c.li,n.huyan,l.jiao,andh.zhou,“recursiveautoencoders-basedunsupervisedfeaturelearningforhyperspectralimageclassification,”ieeegeosci.remotesens.lett.,vol.14,no.11,pp.1928
–
1932,nov.2017.[30]t.li,j.zhang,andy.zhang,“classificationofhyperspectralimagebasedondeepbeliefnetworks,”inproc.ieeeint.conf.imageprocess.,oct.2014,pp.5132
–
5136.[31]b.pan,z.shi,andx.xu,“r-vcanet:anewdeep-learning-basedhyperspectralimageclassificationmethod,”ieeej.sel.topicsappl.earthobserv.remotesens.,vol.10,no.5,pp.1975
–
1986,may2017.[32]x.cao,f.zhou,l.xu,d.meng,z.xu,andj.paisley,“hyperspectralimageclassificationwithmarkovrandomfieldsandaconvolutionalneuralnetwork,”ieeetrans.imageprocess.,vol.27,no.5,pp.2354
–
2367,may2018.[33]h.leeandh.kwon,“goingdeeperwithcontextualcnnforhyperspectralimageclassification,”ieeetrans.imageprocess.,vol.26,no.10,pp.4843
–
4855,oct.2017.[34]g.hughes,“onthemeanaccuracyofstatisticalpatternrecognizers,”ieeetransactionsoninformationtheory,vol.14,no.1,pp.55-63,1968.[35]k.he,x.zhang,s.ren,andj.sun,“deepresiduallearningforimagerecognition,”inproc.ieeeconf.comput.vis.patternrecognition.(cvpr),jun.2016,pp.770
–
778.[36]z.zhong,j.li,z.luo,andm.chapman,“spectral
–
spatialresidualnetworkforhyperspectralimageclassification:a3-ddeeplearningframework,”ieeetrans.geosci.remotesens.,vol.56,no.2,pp.847
–
858,feb.2018.[37]m.e.paoletti,j.m.haut,r.fernandez-beltran,j.plaza,a.j.plaza,andf.pla,“deeppyramidalresidualnetworksforspectral-spatialhyperspectralimageclassification,”ieeetrans.geosci.remotesens.,vol.57,no.2,pp.740
–
754,feb.2019.[38]g.huang,z.liu,l.vandermaaten,andk.q.weinberger,“denselyconnectedconvolutionalnetworks,”inproc.ieeeconf.comput.visionpatternrecognit.,jul.2017,pp.2261
–
2269.[39]p.duan,x.kang,s.li,andp.ghamisi,"noise-robusthyperspectralimageclassificationviamulti-scaletotalvariation,"
ieeejournalofselectedtopicsinappliedearthobservationsandremotesensing.,vol.12,no.6,pp.1948-1962,jun.2019.[40]s.fang,d.quan,s.wang,l.zhang,andl.zhou,"atwo-branchnetworkwithsemi-supervisedlearningforhyperspectralclassification,"inigarss2018-2018ieeeinternationalgeoscienceandremotesensingsymposium.,jul.2018:ieee,pp.3860-3863.[41]b.-s.liuandw.-l.zhang,"multi-scaleconvolutionalneuralnetworksaggregationforhyperspectralimagesclassification,"in2019symposiumonpiezoelectrcity,acousticwavesanddeviceapplications(spawda).,jan.2019:ieee,pp.1-6.[42]s.k.roy,g.krishna,s.r.dubey,andb.b.chaudhuri,“hybridsn:exploring3-d
–
2-dcnnfeaturehierarchyforhyperspectralimageclassification,”ieeegeosci.remotesens.lett.,vol.17,no.2,pp.277
–
281,feb.2020.[43]z.meng,l.jiao,m.liang,andf.zhao,“hyperspectralimageclassificationwithmixedlinknetworks,”ieeej.sel.topicsappl.earthobserv.remotesens.,vol.14,pp.2494
–
2507,2021.[44]roysk,mannas,songt,etal.attention-basedadaptivespectral-spatialkernelresnetforhyperspectralimageclassification[j].ieeetransactionsongeoscienceandremotesensing,2020:1-13.[45]cuib,dongxm,zhanq,etal.litedepthwisenet:anextremelightweightnetworkforhyperspectralimageclassification[j].2020.[46]max,fua,wangj,etal.hyperspectralimageclassificationbasedondeepdeconvolutionnetworkwithskiparchitecture[j].ieeetransactionsongeoscienceandremotesensing,2018,pp:1-11.[47]f.yuandv.koltun,“multi-scalecontextaggregationbydilatedconvolutions,”2015,arxiv:1511.07122.[online].available:http://arxiv.org/abs/1511.07122.[48]panb,xux,shiz,etal.“dssnet:asimpledilatedsemanticsegmentationnetworkforhyperspectralimageryclassification”.ieeegeoscienceandremotesensingletters,2020,pp(99):1-5.[49]a.vaswanietal.,“attentionisallyouneed,”inproc.adv.neuralinf.process.syst.,2017,pp.5998
–
6008.[50]h.jie,s.li,s.gang,h.jie,s.li,ands.gang,“squeeze-andexcitationnetworks,”inproc.ieeeconf.comput.visionpatternrecognit.,jun.2018,pp.7132
–
7141.[51]q.wang,b.wu,p.zhu,p.li,w.zuo,andq.hu,“eca-net:efficientchannelattentionfordeepconvolutionalneuralnetworks,”inproc.ieeeconf.comput.visionpatternrecognit.,jun.2020,pp.11534
–
11542.[52]s.woo,j.park,j.-y.lee,andi.s.kweon,“cbam:convolutionalmoduleattentionmodule,”inproc.eur.conf.comput.vision,2018,p.17.[53]w.ma,q.yang,y.wu,w.zhao,andx.zhang,“double-branchmultiattentionmechanismnetworkforhyperspectralimageclassification,”remotesens.,vol.11,no.11,p.1307,jun.2019.[online].available:https://www.mdpi.com/2072-4292/11/11/1307.[54]j.fuetal.,“dualattentionnetworkforscenesegmentation,”inproc.ieee/cvfconf.comput.vis.patternrecognit.(cvpr),jun.2019,pp.3146
–
3154.[55]r.li,s.zheng,c.duan,y.yang,andx.wang,“classificationofhyperspectralimagebased
ondouble-branchdual-attentionmechanismnetwork,”remotesens.,vol.12,no.3,p.582,feb.2020.[online].available:https://www.mdpi.com/2072-4292/12/3/582.[56]y.cui,z.yu,jhan,s.gao,andl.wang,“dual-tripleattentionnetworkforhyperspectralimageclassificationusinglimitedtrainingsamples”ieeegeoscienceandremotesensingletters,2021.[57]d.erhan,y.bengio,a.courville,p.-a.manzagol,p.vincent,ands.bengio,“whydoesunsupervisedpre-traininghelpdeeplearning?”journalofmachinelearningresearch,vol.11,no.feb,pp.625-660,2010.[58]m.z.alom,t.m.taha,c.yakopcic,s.westberg,p.sidike,m.s.nasrin,m.hasan,b.c.vanessen,a.a.awwal,andv.k.asari,"astate-of-the-artsurveyondeeplearningtheoryandarchitectures,”electronics,vol.8,no.3,p.292,2019.[59]m.z.alom,t.m.taha,c.yakopcic,s.westberg,p.sidike,m.s.nasrin,m.hasan,b.c.vanessen,a.a.awwal,andv.k.asari,"astate-of-the-artsurveyondeeplearningtheoryandarchitectures,”electronics,vol.8,no.3,p.292,2019.[60]y.bengio,p.simard,andp.frasconi,"learninglong-termdependencieswithgradientdescentisdifficult,ieeetransactionsonneuralnetworks,vol.5,no.2,pp.157-166,1994.
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1