一种基于差分隐私保护的随机森林车流预测方法
1.本发明属于隐私保护数据挖掘领域,具体的说是一种基于差分隐私保护的随机森林车流预测方法。
背景技术:
2.过去几十年里,车量的大量使用使得车流数据日益增加。对于车流数据集的处理,有的研究者使用神经网络进行构建,但是车流数据集大多是二维表格数据,这使得神经网络算法的构建过程及其复杂。有的尝试使用支持向量机算法来进行构建,但是这种算法难以处理规模较大的车流数据集,而且对于车流数据集所构建的众多参数也难以调节。而决策树由于其易理解以及在相对短的时间内能够对大型数据集做出效果良好的决策结果等特点而广受关注。但当车流数据集日益增加时,单棵决策树存在精度瓶颈以及学习有偏差等问题。因此,基于决策树的随机森林算法慢慢成为处理车流数据集最常用的机器学习算法。现有的差分隐私随机森林的分类处理方案,对非叶子节点添加两类噪声,分别是用指数机制选择最优分裂点以及对当前节点样本数进行拉普拉斯加噪,对非叶子节点进行双重加噪,从而造成隐私预算的浪费。而车流数据集中存在大量的用户敏感数据,如果直接发布这些算法可能会造成用户的隐私泄露。差分隐私保护无需考虑攻击者所能掌握的最大背景知识,其对隐私披露风险给出了定量化的表示和证明。而且差分隐私保护的优势是,即使是对于大型的车流数据集也只需通过添加少量噪声就能实现较高级别的隐私保护水平。
3.目前关于差分隐私保护的处理车流数据集的回归随机森林算法比较少,主要原因是隐私预算的分配与预测精度的提升等问题。隐私预算是对一个算法的保护程度的体现,但考虑到算法预测精度的问题,分配给整个随机森林的隐私预算会很少。在整体隐私预算很少的情况下隐私的分配方式决定着整个随机森林算法的预测精度,隐私预算的分配可分为树与树之间的分配以及单棵树之内的分配。对于树与树之间的分配方式,现有方案将车流数据集分配给每棵树时都是采用随机有放回地抽样,这样做会使得分配给整个森林的总隐私预算要平分给每一棵决策树。如果随机森林里训练的树比较多的话,那每棵树分到的隐私预算就会非常少,相应的树训练的结果就会非常差。而对于单棵树内的分配方式,相关方案都是简单的将单棵树的隐私预算平分给非叶子节点和叶子节点。事实上,非叶子节点和叶子节点对于预测精度的影响是不同的。所以平分方式是对隐私预算的浪费,将隐私预算多分配给对预测结果影响较大的节点才能最大化提高车流预测精度。
4.除了隐私分配问题外,车流数据集的处理也能影响车流预测的精度。由于车流数据集大多都不是完整的,它们或多或少存在数据缺失的情况。虽然随机森林算法能处理缺失值,但是这会造成车流预测结果的不稳定。如果像已有方案那样直接删除车流数据里缺失样本,这又会造成车流数据集整体样本量的减少。还有就是车流数据集里连续特征值的处理,已有方案大多采用算法默认的处理方式。这种方式使得车流数据集里离散特征值跟原来的连续特征值并没有什么差别,虽然数据进行了变换,但是对于指数机制选取最优特征值的影响是非常小的。
技术实现要素:
5.本发明是为了解决上述现有技术存在的不足之处,提出一种基于差分隐私保护的随机森林车流预测方法,以期能有效解决车流数据集里敏感信息泄露以及隐私分配缺陷而造成的车流预测能力低的问题,从而能在更好的保护车流数据集里敏感数据的前提下提升车流的预测精度。
6.本发明为达到上述发明目的,采用如下技术方案:
7.本发明一种基于差分隐私保护的随机森林车流预测方法的特点包括以下步骤:
8.步骤1、从交通系统中获取车流数据集并进行预处理;
9.步骤1.1、对车流数据集中的空缺值进行均值填补处理,得到预处理后的车流数据集记为n={[x1,y1],[x2,y2],
…
,[xi,yi],
…
,[xn,yn]},其中,[xi,yi]表示第i个样本组;xi表示第i个车流样本,yi表示第i个车流样本所对应的预测值,n表示预处理后的数据集n中车流量样本的总数,1≤i≤n;令第i个车流样本xi中的特征集合记为中的特征集合记为表示第i个车流样本xi中的第d个特征;d表示车流样本中的特征总数;
[0010]
步骤1.2、对所述第i个车流样本xi中的特征集合中的连续特征进行离散化处理,得到预处理后的特征集合特征进行离散化处理,得到预处理后的特征集合表示离散化后的第d个特征,且第d个特征的离散值集合记为则所有离散化后的特征的离散值所组成的集合记为
[0011]
步骤1.3、令随机森林表示为(tree1,tree2,
…
,tree
t
,
…
,tree
t
);tree
t
表示第t棵树,t表示随机森林中树的棵数;1≤t≤t;
[0012]
将预处理后的数据集n中的n个样本组随机选取个样本组并分配给每棵树;其中,第t棵树tree
t
的根节点分配到的样本组
[0013]
步骤2、确定随机森林中所有树训练所需要的公共参数;
[0014]
步骤2.1、令每棵树分配到的隐私预算均为ε
each_tree
;令每棵树中的非叶节点和叶子节点的总隐私预算分别为δ
×
ε
each_tree
和(1-δ)
×
ε
each_tree
;则任意一个非叶结点隐私预算为其中,h
max
表示所有树的最大树高;δ表示分配比率,且δ∈[0,1];
[0015]
步骤2.2、令每棵树的分裂函数和打分函数均为平方误差函数步骤2.2、令每棵树的分裂函数和打分函数均为平方误差函数是tree
t
的样本组,其中,a表示集合φ中任意一个特征的离散值集合中的一个离散值,且a∈φ;令打分函数经过精确估计后的全局敏感度为δf;
[0016]
初始化t=1;
[0017]
步骤3、对第t棵树tree
t
进行训练,得到具有差分隐私保护的回归树tree
t
′
:
[0018]
步骤3.1、第t棵树tree
t
将隐私预算分给非叶子节点,并将隐私预算(1-δ)
×
ε
each_tree
分给叶子节点;
[0019]
步骤3.2、定义当前第t棵树tree
t
的高度为h,并初始化h=1;
[0020]
步骤3.3、对于第h层中的每一个节点,若第h层中的当前节点node的所有样本的预测值都相同,则将当前节点node置为叶子节点node
leaf
,并执行步骤3.4;否则,使用指数机制分别从特征集合a
′
中选出最优特征a
best
,从集合φ中选出最优特征值a
best
,若对第h层中的当前节点node的每一个样本进行判断,若当前样本在最优特征a
best
处的离散值小于等于a
best
,则将相应样本分配到第h层中的当前节点node的左子节点node
left
上,否则分配到右子节点node
right
上;
[0021]
步骤3.4、计算叶子节点node
leaf
中每个样本的预测值的均值,并使用拉普拉斯噪声每个均值进行加噪,得到加噪后的均值;
[0022]
步骤3.5、将h+1赋值给h后,判断h》h
max
是否成立,若成立,则表示得到具有差分隐私保护的回归树tree
′
t
;否则,返回步骤3.3顺序执行;
[0023]
步骤4、将t+1赋值给t后,判断t》t是否成立,若成立,则表示得到回归森林(tree
′1,tree
′2,
…
,tree
′
t
);否则,返回步骤3顺序执行;
[0024]
步骤5、基于回归森林的车流预测:
[0025]
步骤5.1、将新的车流样本x输入到回归森林中,并得到预测值其中,表示新的车流样本x在第t棵树上的预测值。
[0026]
与现有技术相比,本发明的有益效果在于:
[0027]
1、相比于传统的对车流数据集处理的随机森林算法,本发明提出了一种差分隐私保护的随机森林算法对决策树中所有节点进行了保护,从而使得车流数据集中敏感信息得到了保护。其中,对每棵决策树的非叶子节点采用了指数机制进行特征值保护,对叶子节点采用了拉普拉斯机制进行输出值扰动。通过对隐私预算的分配以及对车流数据集的处理使得车流预测精度在提高的前提下,车流数据集里敏感数据的保护程度也在不断增加。经过差分隐私保护的随机森林算法可以对新的车流样本进行有隐私保护且精度更高的预测,而这些预测结果可被各种交通软件使用从而对用户安排更合理的道路出行方式。
[0028]
2、本发明着重考虑了隐私消耗对每棵树的精度影响,主要是整个随机森林中树与树之间以及单棵树内的隐私分配。对树与树之间,本发明采用差分隐私并行组合理论将整个随机森林的总隐私预算等量分配给每棵决策树,相应的每棵树所分配的车流数据集与其它树的车流数据集也是没有相交的。对单棵树内的隐私分配,本发明将一棵树的总隐私预算更多的分配给叶子节点,较少的分配给非叶子节点。通过对隐私分配的调整,使得整个随机森林算法中的隐私预算利用的更充分,从而增加了车流预测精度。
[0029]
3、本发明还考虑了车流数据集对预测值的影响。首先,对于车流数据集里空缺值部分,我们采用了均值的处理方式,使得车流预测值更稳定。其次,还考虑了车流数据集里连续特征值的离散化,使得车流数据集里敏感的数据在受到保护的前提下提高了指数机制的效用,从而提高了整个随机森林对车流预测的精度。
[0030]
4、本发明还考虑了分裂函数敏感度精确估计的问题,较低的敏感度能够减少噪声的引入,提高了非叶子节点分裂的准确率。通过对非叶子节点只用指数机制保护,对叶子节点只用拉普拉斯保护,减少了隐私预算的浪费,从而提高了整个随机森林对车流预测的精
度。
附图说明
[0031]
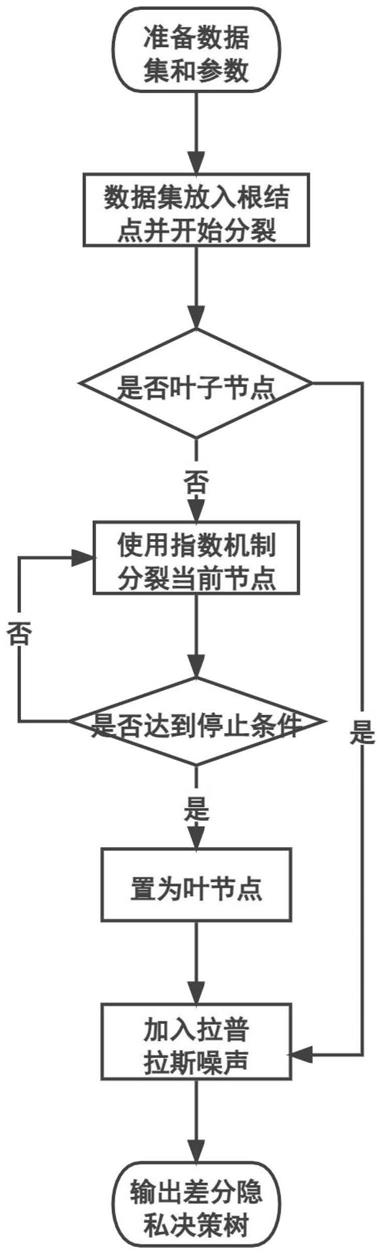
图1为本发明的单棵树训练图;
[0032]
图2为本发明的整个随机森林框架图。
具体实施方式
[0033]
本实施例中,一种基于差分隐私保护的随机森林车流预测方法,包括以下步骤:
[0034]
步骤1、从交通系统中获取车流数据集并进行预处理;可以从交通系统网站获取,也可以从普通网站搜索获取。
[0035]
步骤1.1、考虑到从网上获取的车流数据集可能存在空缺值,而且空缺值对决策树的训练可能会有一点影响,所以要先对车流数据集中的空缺值进行均值填补处理,得到预处理后的车流数据集记为n={[x1,y1],[x2,y2],
…
,[xi,yi],
…
,[xn,yn]},其中,[xi,yi]表示第i个样本组;xi表示第i个车流样本,yi表示第i个车流样本所对应的预测值,n表示预处理后的数据集n中车流量样本的总数,1≤i≤n;令第i个车流样本xi中的特征集合记为中的特征集合记为表示第i个车流样本xi中的第d个特征;d表示车流样本中的特征总数;xi是一个d维向量,它的每个数据代表第i个样本在相应特征处的取值;yi则是一个具体的值,它代表第i个样本的预测值;
[0036]
步骤1.2、对第i个车流样本xi中的特征集合中的连续特征进行离散化处理,例如对某一个连续特征,首先对这个特征所有的连续值进行非降序排序,然后每三个取一次平均;如果连续值的个数不是3的整数倍,那么如果最后剩两个数,那就取最后两个数的平均;如果只剩一个数,那就取这个数作为离散化后最后一个特征值;得到预处理后的特征集合预处理后的特征集合表示离散化后的第d个特征,且第d个特征的离散值集合记为则所有离散化后的特征的离散值所组成的集合记为这种离散化方法相比算法本身的处理方法,不仅能更好的保护用户的隐私数据,还能够提高指数机制的效用,从而提高了决策树的预测精度;
[0037]
步骤1.3、令随机森林表示为(tree1,tree2,
…
,tree
t
,
…
,tree
t
);tree
t
表示第t棵树,t表示随机森林中树的棵数;1≤t≤t;t是随机森林整体的参数,一般定为50,也可以通过实验决定最优的个数;
[0038]
将预处理后的数据集n中的n个样本组随机选取个样本组并分配给每棵树;其中,第t棵树tree
t
的根节点分配到的样本组将总车流数据集均分给每棵树,可使得所有决策树的训练满足差分隐私并行组合理论,使得总隐私预算能等量分配给所有树;这使得每棵树的隐私预算是原来的t倍,从而大大提高每棵决策树的预测能力;
[0039]
步骤2、确定随机森林中所有树训练所需要的公共参数;
[0040]
步骤2.1、令每棵树分配到的隐私预算均为ε
each_tree
;令每棵树中的非叶节点和叶子节点的总隐私预算分别为δ
×
ε
each_tree
和(1-δ)
×
ε
each_tree
;则任意一个非叶结点隐私预算
为其中,h
max
表示所有树的最大树高;δ表示分配比率,且δ∈[0,1];带隐私保护的决策树在训练过程中,非叶子节点和叶子节点对预测值的影响是不同的;非叶子节点隐私预算分配少一点,指数机制选出的最优特征值没那么好,但其它节点的分裂能稍微弥补这个错误;对于叶子节点,如果隐私预算比较少的话,加入的拉普拉斯噪声就会非常大,那么叶子节点的输出值就会和原来的真实值拉开很大的差距;所以,在每棵树的隐私预算应多分配给叶子节点,少分配给非叶子节点,也就是δ一般取0.1;
[0041]
步骤2.2、令每棵树的分裂函数和打分函数均为式(1)所示的平方误差函数步骤2.2、令每棵树的分裂函数和打分函数均为式(1)所示的平方误差函数是tree
t
的样本组,其中,a表示集合φ中任意一个特征的离散值集合中的一个离散值,且a∈φ,令打分函数经过精确估计后的全局敏感度为δf:现有的敏感度界定方案往往都是直接将分裂函数的输出值范围直接定为分裂函数敏感度,这会给非叶子节点分裂时带来极大的误差;基于此,我们对分裂函数的敏感度进行了精确的估计,减少了噪声的引入,提高了车流数据集中车流预测精度。
[0042][0043]nleft
和n
right
表示当前节点分到左节点和右节点的样本集,它们样本总数记为p和q,y
p
表示第p个样本对应的预测值,c
p
表示左节点所有样本在y处取值的均值,yq和cq同理;a是函数输出的最优特征值,并表示为a
best
,其对应的最优特征是a
best
;
[0044]
初始化t=1;
[0045]
步骤3、对第t棵树tree
t
进行训练,如图1所示,得到具有差分隐私保护的回归树tree
t
′
:所需要的参数有数据集隐私预算ε
each_tree
、分裂函数最大树深h
max
;
[0046]
步骤3.1、第t棵树tree
t
将隐私预算分给非叶子节点,并将隐私预算(1-δ)
×
ε
each_tree
分给叶子节点;每棵树训练前,先确定非叶子节点以及叶子节点的隐私预算;
[0047]
步骤3.2、定义当前第t棵树tree
t
的高度为h,并初始化h=1;
[0048]
步骤3.3、对于第h层中的每一个节点,若第h层中的当前节点node的所有样本的预测值都相同,则将当前节点node置为叶子节点node
leaf
,并执行步骤3.4;否则,使用指数机制分别从特征集合a
′
中选出最优特征a
best
,从集合φ中选出最优特征值a
best
,若对第h层中的当前节点node的每一个样本进行判断,若当前样本在最优特征a
best
处的离散值小于等于a
best
,则将相应样本分配到第h层中的当前节点node的左子节点node
left
上,否则分配到右子节点node
right
上;这步主要是非叶子节点的分裂过程,首先判断是不是非叶子节点;只有非叶子节点才利用指数机制选出最优特征a
best
和最优特征值a
best
,其中a
best
∈a
best
,再根据a
best
和a
best
将当前的非叶子节点分裂成左右子节点;如果当前节点已经是叶子节点,那就调到下一步执行;其中,指数机制为:
[0049]
节点node样本集中离散特征为(a
′1,a
′2,
…
,a
′d,
…
,a
′d),离散特征a
′d的所有离散
值可表示为(a1,a2,
…
,am),1≤d≤d,m<<n;然后以概率输出最优特征值a
best
及最优特征a
best
;
[0050]
步骤3.4、计算叶子节点node
leaf
中每个样本的预测值的均值,并使用拉普拉斯噪声对每个均值进行加噪,得到加噪后的均值;这一步主要是对所有叶子节点利用拉普拉斯噪声值进行扰动,均值函数敏感度记为δv:
[0051][0052]
步骤3.5、将h+1赋值给h后,判断h》h
max
是否成立,若成立,则表示得到具有差分隐私保护的回归树tree
′
t
;否则,返回步骤3.3顺序执行;若当前树已达到最大树深,则停止当前树的训练;
[0053]
步骤4、将t+1赋值给t后,判断t》t是否成立,若成立,则表示得到回归森林(tree
′1,tree
′2,
…
,tree
′
t
);否则,返回步骤3顺序执行;若当前树的棵树已达到最大数量t,则停止下一棵树的训练,并将所有训练好的树组合成随机森林,如图2所示;
[0054]
步骤5、基于回归森林的车流预测:
[0055]
步骤5.1、将新的车流样本x输入到回归森林中,并得到预测值其中,表示新的车流样本x在第t棵树上的预测值。可将总数据集的70%作为训练集,剩余30%作为测试集;那么将测试集中任意一个新样本输入到差分隐私保护的随机森林中都会得到一个差分隐私保护的预测结果。
[0056]
综上所述,本方法中隐私预算的分配以及车流数据集的处理都是提高车流预测精度的关键,适当的处理方案能够使得车流数据集里敏感数据的隐私保护水平和车流预测精度达到合理的平衡。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1