面向金融领域的文档级事件主体对抽取的方法、存储介质及设备
1.本发明涉及文档级事件主体对抽取的方法,属于信息技术领域。
背景技术:
2.事件抽取作为信息抽取的一个重要分支,是从非结构化信息中,抽取出用户所感兴趣以及需要的数据,并以结构化形式保存下来,以供后续的任务以及分析使用,在自动摘要、自动问答、信息检索等领域中有着广泛的使用,在自然语言处理中有着重要的地位。
3.随着市场经济的发展,特别是股市经济的发展,数字化金融文档呈现爆炸式增长。人们对金融事件越来越重视,通过研究分析这些大量的金融事件文档,对于公司感知风险投资决策有着非常重要的意义,然而如果单纯的靠人力从海量的文档中提取有价值的信息,将会花费大量人力时间,而且由于金融事件具有一定的时效性,如果不能及时提取信息,信息将失去价值,因此采用事件抽取的方式自动快速获取大量文档中所包含的信息就显得很有意义。目前事件抽取领域主要的研究方法有三大类,包括基于模式匹配、基于机器学习和基于深度学习的方法。
4.传统的基于模式匹配的方法,是对于某类事件的识别和抽取是在相应的模式的指导下进行,采用各种模式匹配算法将待抽取的文本句和已建立的模板进行匹配。模式匹配的方法在特定领域特定范围内能够取得较高的性能,但具有的问题是移植性较差。例如surdeanu和harabagiu针对开放域的事件抽取系统fsa。
5.基于机器学习的方法识别,就是借鉴文本分类的思想,转换为分类问题,其核心在于分类器的构造以及特征的选取。事件识别包括事件类别的识别以及事件元素的识别,主体的识别包含于事件元素的识别。
6.然而基于机器学习的方法需要投入大量工程用于有效特征的选取,且模型的性能依赖于特征选取的好坏。随着近年来深度学习的快速发展,基于深度学习的事件抽取方法成了研究的方向之一。深度学习是机器学习的技术和研究领域之一,其本质是使用神经网络结构,对人类的神经结构进行模拟,借此模仿人类学习及利用所学知识处理问题的过程。深度学习被应用于对复杂特征的提取、对高维数据的理解和对大样本数据的学习,深度学习的一大优点在于对于输入的数据可以自动学习抽象的特征,较传统的机器学习可以减少特征工程的工作量。因为深度学习在计算机视觉、自然语言处理、自动控制等各个领域取得的巨大突破,以及超越传统算法的表现,使之被越来越多的应用在计算机问题的各个方向。因此,基于深度学习的事件抽取算法应运而生。
7.基于神经网络的方法是将事件识别作为一种有监督多分类任务,可以分为基于流水线的事件识别方法和基于联合模型的事件识别方法。不同于传统离散特征,神经网络方法以连续向量为特征,然后通过神经网络模型学习更抽象的特征。采用神经网络进行端到端的学习,能够有效减少特征工程,省去大量的人力物力。
8.但是,现有的事件抽取方法基本都是基于句子级别进行抽取,通过对输入的句子
进行特征的提取,包括基于词的特征和基于词对的特征,利用这些特征来对事件的触发词以及论元进行识别。基于句子级的事件抽取的方法不能很好的解决现有金融领域内文档的事件抽取的工作,提取事件信息的性能往往不能令人满意。
技术实现要素:
9.本发明是为了解决现有的基于句子级的事件抽取的方法不能很好的应用于金融领域内文档的事件抽取,从而存在提取事件信息的性能较低的问题。
10.面向金融领域的文档级事件主体对抽取的方法,包括以下步骤:
11.步骤一、首先将文档按句进行分割d=[s1;s2;
…
;s
ns
],其中si表示第i个句子,ns为文档中句子的个数;
[0012]
然后将第i个句子基于字通过词典映射成句子id;
[0013]
步骤二、将映射成id的句子si通过第一个字的embedding矩阵得到每个token,即e
si
=[w
i,1
;w
i,2
;
…wi,nw
],其中nw表示第i个句子中共有nw个token;
[0014]
然后输入至第一bert中,取bert输出的最后一层的编码,得到句子中的每个token的编码[h
i,1
;h
i,2
;
…hi,nw
];
[0015]
步骤三、将步骤二中的句子的embedding e
si
=[w
i,1
;w
i,2
;
…wi,nw
]输入至cnn中获取n-gram的特征,将三个卷积核得到的三个向量拼接起来得到特征向量c;
[0016]
步骤四、对于步骤一输入的事件类型,首先对事件类型排序,然后按照排序好的顺序,得到每个事件类型对应的顺序位置,将每个事件类型映射成固定的事件类型id;然后在事件类型的embedding矩阵中获取该事件类型的embedding t;
[0017]
步骤五、获取文档级上下文表示e
global
:
[0018]
首先将文档分割后的每个句子si都按照和步骤一步骤二相同的方式得到每个句子的embedding e
si
=[w
i,1
;w
i,2
;
…wi,nw
],接着经过第二bert得到每个句子的编码向量,文档中有n个句子,那么得到文档所有句子的编码矩阵[h
’1;h
’2;
…
;h’ns
];
[0019]
接着将上述编码矩阵[h
’1;h
’2;
…
;h’ns
]通过maxpooling,得到编码矩阵[c1;c2;
…
;c
ns
];
[0020]
然后经过transformer进行信息的交互,得到d
final
=[c
d1
;c
d2
;
…
;c
dns
];
[0021]
最后将d
final
进行maxpooling,最终得到文档级表示向量e
global
;
[0022]
步骤六、步骤二中得到的句子的编码hi=[h
i,1
;h
i,2
;
…hi,nw
]的每个token的embedding h
i,j
在长度维度上拼接上步骤三、步骤四和步骤五中得到的向量c、t和e
global
,拼接完成后得到h
final
;
[0023]
步骤七、将步骤六中得到的向量经过前馈神经网络改变长度维度,将长度维度变换为序列标注中标签个数的大小;
[0024]
步骤八、将步骤七中得到的向量输入到crf中得到标注结果,再通过标注的得到的标签,根据这些标签找到原文对应的主体对,输出主体对作为结果。
[0025]
进一步地,所述步骤五中在得到编码矩阵[c1;c2;
…
;c
ns
]之后,对于当前抽取的第i个句子,取当前句子的前后各三个句子经过transformer进行信息的交互,接着得到d
final
=[e
si-3
;e
si-2
;
…
;e
i+3
]。
[0026]
进一步地,步骤二所述每个token的向量维度为768。
[0027]
进一步地,步骤三所述cnn的卷积核分别采用(1,768),(3,770),(5,772),得到特征向量c的维度是128。
[0028]
进一步地,步骤四所述的向量t的维度是1*128。
[0029]
进一步地,步骤五所述每个句子的编码向量的维度为len*768,其中len是句子的长度;所有句子的编码矩阵[h
’1;h
’2;
…
;h’ns
]维度为n*len*768。
[0030]
进一步地,步骤五所述编码矩阵[c1;c2;
…
;c
ns
]的维度为n*768;d
final
=[c
d1
;c
d2
;
…
;c
dns
]的维度为n*768;文档级表示向量e
global
的维度为1*768。
[0031]
进一步地,步骤六所述拼接完成后得到h
final
的维度为len*2048。
[0032]
一种存储介质,所述存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现所述的面向金融领域的文档级事件主体对抽取的方法。
[0033]
一种设备,所述设备包括处理器和存储器,所述存储器中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现所述的面向金融领域的文档级事件主体对抽取的方法。
[0034]
有益效果:
[0035]
然而本发明的任务是给定一篇金融文档与预定义的事件类型集,抽取这篇文档中所有相关事件类型的事件主体对。事件主体对中的发起主体和承受主体有时并不位于同一个句子当中,需要对整个文档进行跨句子的识别获取最终结果。因此该任务是一个文档级别的事件抽取任务,单纯采用基于句子的方法不能很好完成任务。本发明在已有的基于句子方法的基础上,考虑利用全局信息达到抽取事件主体对的目标。
[0036]
本方法的目的是针对在金融领域中,对文档进行事件主体对抽取时,以往的方法大多基于句子级,无法考虑文档级上下文的信息,导致抽取的性能欠缺,例如,单独基于句子使用序列标注方法进行抽取时,性能只有63.9%。在添加了文档级上下文向量后,性能上有3.3%的提升。通过在抽取过程中对每个句子的embedding后添加上文档级上下文的表示向量,来使模型在抽取当前句子的时候,能够获取当前句子之外的句子的信息。
[0037]
本方法针对文档进行事件主体对抽取时,一篇文档可能会出现多个事件类型,模型在抽取某个事件类型的事件主体对时,会出现将其他事件类型的事件主体对误作为当前要抽取的事件类型的事件主体对抽取出来,这种错误很大程度上影响了抽取的性能,因此,在抽取的过程中,为了告诉模型当前要抽取的时什么事件类型,将事件类型编码成向量与句子的编码的向量进行拼接,借此给模型加上一个强的先验特征。加上给向量之前,模型的性能是61.1%,加上该特征之后,性能提升至67.2%,提升了6.1个百分点。
附图说明:
[0038]
图1为本发明流程图;
[0039]
图2为本发明模型一操作流程图;
[0040]
图3为本发明模型二操作流程图。
具体实施方式:
[0041]
具体实施方式一:
[0042]
本实施方式为面向金融领域的文档级事件主体对抽取的方法,是一种面向金融领
域的文档级事件主体对抽取方法,基于以往的基于句子抽取的方法,即使用序列标注作为标注的框架,通过结合cnn提取的n-gram的特征,事件类型的先验特征和编码文档得到的文档上下文向量特征,增强模型对文档的信息获取的能力,提高模型在文档范围内抽取事件主体对的能力。
[0043]
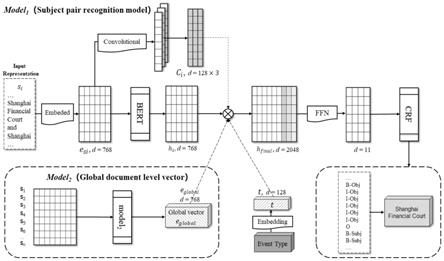
结合图1至图2说明本实施方式,本实施方式所述的一种面向金融领域的文档级事件主体对抽取的方法,具体包括以下步骤:
[0044]
步骤一、输入一篇金融领域的文档和需要抽取的事件类型,首先将文档按句进行分割d=[s1;s2;
…
;s
ns
],其中si表示第i个句子,ns为文档中句子的个数;将第i个句子中的每个字按照字在词典中的顺序位置,通过词典映射成对应的id,例如“我是学生”这句话,在词典中分别查找“我”,“是”,“学”,“生”四个字的顺序位置,假设是145,167,890,6799,那么这句话就会被映射成向量[145,167,890,6799]。
[0045]
步骤二、将映射成id的句子si通过第一个字的embedding矩阵得到每个token即字的embedding,该句表示为e
si
=[w
i,1
;w
i,2
;
…
;w
i,nw
],其中nw表示第i个句子中共有nw个token;本实施方式中,每个token的向量维度为768。
[0046]
然后输入至第一bert中,取第一bert输出的最后一层的编码,得到句子中的每个token的编码[h
i,1
;h
i,2
;
…hi,nw
],本实施方式中每个token向量的维度为768。
[0047]
步骤三、将步骤二中的句子的embedding e
si
=[w
i,1
;w
i,2
;
…wi,nw
]输入至cnn中获取n-gram的特征,本实施方式中卷积核分别采用(1,768),(3,770),(5,772),通过卷积核得到的向量维度是128,将三个卷积核得到的三个向量拼接起来得到128*3的n-gram的特征向量c。
[0048]
步骤四、对于步骤一输入的事件类型,首先对事件类型任意排序,比如按照字典排序,然后按照排序好的顺序,得到每个事件类型对应的顺序位置,这样就可以将每个事件类型映射成固定的事件类型id,即上述的顺序位置;然后在事件类型的embedding矩阵中获取该事件类型的embedding t,所以向量t是模型需要识别的事件类型编码得到的向量,该向量的维度是1*128。
[0049]
步骤五、获取文档级上下文表示e
global
:
[0050]
首先将文档分割后的每个句子si都按照和步骤一步骤二相同的方式得到每个句子的embedding e
si
=[w
i,1
;w
i,2
;
…wi,nw
],注意这里使用的基于字的词典,以及字的embedding矩阵和步骤一步骤二完全一致,接着经过第二bert得到每个句子的编码向量,向量的维度信息为len*768,其中len是句子的长度,实现中设置成100,假设文档中有n个句子,那么得到文档所有句子的编码矩阵[h
’1;h
’2;
…
;h’ns
],维度信息为n*len*768;
[0051]
接着将上述编码矩阵[h
’1;h
’2;
…
;h’ns
]通过maxpooling(最大池化),过滤信息后得到新的编码矩阵[c1;c2;
…
;c
ns
],维度信息为n*768。
[0052]
然后经过transformer进行信息的交互,得到d
final
=[c
d1
;c
d2
;
…
;c
dns
],维度的信息是n*768;
[0053]
最后将d
final
进行maxpooling(最大池化),最终得到文档级表示向量e
global
,维度是1*768;e
global
实际是对全局文档编码得到的向量。
[0054]
本发明的重点在于这里的改进通过对整个文档的句子进行编码,得到了e
global
,后续模型通过融合向量e
global
,能够结合文档级的上下文的信息,使得模型不仅能够关注到当
前句子的信息,还能获取当前句子以外其他句子的信息,借此,在识别主体对的时候,模型能够同时考虑到一个事件中不在同一个句子的发起主体和承受主体,提高了模型的跨句抽取的能力,从而能够提高模型的抽取能力,提高模型的性能。
[0055]
步骤六、步骤二中得到的句子的编码hi=[h
i,1
;h
i,2
;
…hi,nw
]的每个token的embedding h
i,j
在长度维度上拼接上步骤三、步骤四和步骤五中得到的向量c、t和e
global
,拼接完成后得到h
final
,此时的维度是len*2048,len是句子的长度。
[0056]
步骤七、将步骤六中得到的向量经过前馈神经网络改变长度维度,将长度维度变换为序列标注中标签个数的大小。
[0057]
步骤八、将步骤七中得到的向量输入到crf中得到标注结果,再通过标注的得到的标签,根据这些标签找到原文对应的主体对,输出主体对作为结果。
[0058]
crf(conditional random field)的引入是为了解决在进行标注时,没有考虑标签之间相互依赖关系的问题,这一问题会导致部分精度的损失。主体识别任务存在规则上的限制,例如标签中,b标签表示当前对应的字是主体起始的字,i标签表示当前对应的字是主体中间的字,o标签表示当前对应的字不是主体的字,例如假设“哈尔滨工业大学在哈尔滨。”这句话中哈尔滨工业大学是主体,那么对应的正确的标签则是“b i i i i i i o o o o”,由此可见由于b表示一个主体的起始,那么在标注过程中,i标签只能跟在b标签或者i标签的后面,而不能跟在o标签的后面。因此为了避免这种标注错误,从而引入crf(条件随机场)来学习标签之间的关系,而不是各个标签独立的标注。得到标注结果,再通过标注的得到的标签,根据这些标签找到原文对应的主体对,输出主体对作为结果。
[0059]
具体实施方式二:
[0060]
本实施方式为一种面向金融领域的文档级事件主体对抽取的方法,本实施方式与具体实施方式一不同的地方,是本实施方式考虑到在实施时,由于在方式一步骤五中,构建全局文档级的表示是将整篇文档按句分割后,将所有的句子同时输入到模型二中进行编码得到的。因为是将所有的句子全部输入模型中,所以导致了模型在训练过程中,速度较慢,并且batch_size参数不能设置较大,因此针对这个问题,仔细考察了现有的数据后,发现事件的发起主体和承受主体相邻基本不超过三个句子(占比80%左右),因此本实施方式对步骤五进行修改。
[0061]
如图3所示,步骤五所述的获取文档级上下文表示e
global
的过程包括以下步骤:
[0062]
首先,将文档分割后的每个句子si都按照实施方式一中步骤一步骤二相同的方式得到每个句子的embedding e
si
=[w
i,1
;w
i,2
;
…wi,nw
],注意这里使用的基于字的词典,以及字的embedding矩阵和步骤一步骤二完全一致,接着经过第二bert得到每个句子的编码向量,向量的维度信息为len*768,其中len是句子的长度,实现中设置成100,假设文档中有n个句子,那么得到文档所有句子的编码矩阵[h
’1;h
’2;
…
;h’ns
],维度信息为n*100*768;
[0063]
接着将上述编码矩阵[e
s1
;e
s2
;
…
;e
ns
]通过maxpooling(最大池化),过滤信息后得到新的编码矩阵[c1;c2;
…
;c
ns
],维度信息为n*768;
[0064]
然后,对于当前抽取的第i个句子,取当前句子的前后各三个句子经过transformer进行信息的交互,这样就可以缓解一次性输入所有的句子带来的训练速度较慢以及对机器内存要求较高带来的问题,接着得到d
final
=[e
si-3
;e
si-2
;
…
;e
i+3
];
[0065]
最后将d
final
进行maxpooling(最大池化),最终得到文档级表示向量e
global
。
[0066]
其他步骤及参数与具体实施方式一相同。
[0067]
本方法的目的是针对在金融领域中,对文档进行事件主体对抽取时,以往的方法大多基于句子级,无法考虑文档级上下文的信息,导致抽取的性能欠缺,例如,单独基于句子使用序列标注方法进行抽取时,性能只有63.9%。在添加了文档级上下文向量后,性能上有3.3%的提升。通过在抽取过程中对每个句子的embedding后添加上文档级上下文的表示向量,来使模型在抽取当前句子的时候,能够获取当前句子之外的句子的信息。
[0068]
本方法针对文档进行事件主体对抽取时,一篇文档可能会出现多个事件类型,模型在抽取某个事件类型的事件主体对时,会出现将其他事件类型的事件主体对误作为当前要抽取的事件类型的事件主体对抽取出来,这种错误很大程度上影响了抽取的性能,因此,在抽取的过程中,为了告诉模型当前要抽取的时什么事件类型,将事件类型编码成向量与句子的编码的向量进行拼接,借此给模型加上一个强的先验特征。加上给向量之前,模型的性能是61.1%,加上该特征之后,性能提升至67.2%,提升了6.1个百分点。
[0069]
具体实施方式三:
[0070]
本实施方式为一种存储介质,所述存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现如具体实施方式一或二所述的面向金融领域的文档级事件主体对抽取的方法。
[0071]
具体实施方式四:
[0072]
本实施方式为一种设备,所述设备包括处理器和存储器,所述存储器中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现如具体实施方式一或二所述的面向金融领域的文档级事件主体对抽取的方法。
[0073]
本发明还可有其它多种实施例,在不背离本发明精神及其实质的情况下,本领域技术人员当可根据本发明作出各种相应的改变和变形,但这些相应的改变和变形都应属于本发明所附的权利要求的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1