基于地统计加权随机森林的地球化学变量空间预测方法
1.本发明涉及地质勘查领域,具体是基于地统计加权随机森林的地球化学变量空间预测方法。
背景技术:
2.勘查地球化学手段在过去几十年的找矿工作中发挥了举足轻重的作用。随着露头矿和浅表矿逐渐被发现殆尽,找矿难度日益增大,如何在复杂地质条件下挖掘有用的地球化学信息,已经成为缓解目前矿产资源紧缺形势的重要途径。地球化学分布模式是原生和次生地质过程、人类活动等长期共同作用的结果。受区域地质背景、矿体埋深、矿化类型及规模、风化强度以及地球化学景观等的影响,地球化学元素在表生介质中呈现十分复杂的变异特征,导致地球化学异常识别结果存在很大的不确定性,从而增加了勘查风险,限制了勘查地球化学手段的找矿成效。因此,准确模拟地球化学元素含量的空间分布,并刻画其不确定性显得尤为重要。
3.随机森林由于具有模型简单、准确度高、可解释性强等优点,在地球化学元素含量空间分布模拟中具有较大应用潜力。然而,经典随机森林算法潜在假设样本是独立同分布的,并未考虑元素含量分布的空间异质性和空间相关性特征,从而增加了模拟结果的不确定性。针对上述问题,不少国内外研究尝试改进随机森林算法。如:国外一些学者提出采用考虑空间依赖性的方法,其将观测点的欧氏距离图层作为预测因子之一,该方法操作简单、间接考虑了观测值之间的空间关联,但没有直接考虑空间异质性和观测值分布的空间结构特征。中国专利公布号cn112163731a于2021年01月01日公开了发明创造名称为“一种基于加权随机森林的专变用户电费回收风险识别方法”的发明专利申请,其针对非空间科学问题,“加权”是对随机森林中决策树的贡献进行加权,并不涉及地理位置的概念。中国专利公布号cn104391970a于2015年03月04日公开了发明创造名称为“一种属性子空间加权的随机森林数据处理方法”的发明专利申请,其通过加权属性子集构建决策树,再将其整合形成随机森林模型,该方法针对超高维数据有效处理问题,采用信息增益法为属性加权,并不涉及观测变量在地理空间上的相关性。中国专利公布号cn113033599a于2021年06月25日公开了发明创造名称为“面向露头地质体岩层分层的空间随机森林算法”的发明专利申请,其同时考虑岩层体元的空间特征和属性特征构建空间决策树模型,该处的“空间特征”主要包括地质体体元中心坐标及其产状信息,并未涉及地学变量的空间相关性特征。
4.综上所述,现有研究没有同时考虑地学现象的空间相关性和异质性提出行之有效的改进方案,采用现有方案模拟地球化学元素含量空间分布的精度较低。
技术实现要素:
5.本发明的目的在于解决现有模拟地球化学元素含量空间分布精度较低的问题,提供了一种基于地统计加权随机森林的地球化学变量空间预测方法,其应用时同时考虑地学现象的空间相关性和异质性,能提升预测精度。
6.本发明的目的主要通过以下技术方案实现:基于地统计加权随机森林的地球化学变量空间预测方法,包括以下步骤:
7.s1、获取训练随机森林模型所需的训练数据,所述训练数据包括输入变量和模型输出变量,输入变量包括地质要素和遥感要素,地质要素包括从区域地质数据提取的岩性类别数据和从区域地质数据提取的线环构造矢量数据转换的断裂密度,遥感要素包括地形坡度和植被覆盖度,模型输出变量为已知地球化学元素含量观测数据;其中,输入变量和输出变量采用栅格格式存储;
8.s2、根据输入变量与已知地球化学元素含量观测数据之间的相关系数及输入变量之间的相关性筛选输入变量作为预测因子,将已知地球化学元素含量观测数据与预测因子作为训练样本;
9.s3、基于训练样本训练随机森林模型,并采用训练好的随机森林模型对待预测位置的地球化学元素含量进行预测。
10.进一步的,所述步骤s1中将线环构造矢量数据转换为断裂密度的转换公式为:
[0011][0012]
其中,i表示栅格的行,j表示栅格的列,ρ
ij
为第i行第j列栅格的断裂密度,l
ij
为对应栅格内线性断裂和环形断裂的总长度,s为栅格的面积;
[0013]
所述步骤s1中岩性类别数据为将区域地质数据中的岩性分布数据转换的类别变量,即
[0014]cij
∈{ck,k=1,2,
…
n}
[0015]
其中,n为岩性类别总数,ck表示n种岩性类别中的第k种岩性,c
ij
代表栅格位置(i,j)处的岩性类别。
[0016]
进一步的,所述步骤s1还包括对遥感数据进行辐射校正处理,并利用以下公式计算归一化植被指数:
[0017][0018]
其中,i表示栅格的行,j表示栅格的列,ndvi
ij
为栅格位置(i,j)处的植被指数,为近红外波段处的反射率,为红光波段处的反射率。
[0019]
进一步的,所述步骤s1还包括以下已知地球化学元素含量观测数据处理步骤:
[0020]
迭代剔除位于区间[μ
m-3σm,μm+3σm]之外的已知观测值,其中,μm为第m个元素的均值,σm为迭代过程中第m个元素的标准差;
[0021]
对低于检测限的观测值用相应元素检测限的一半代替;
[0022]
对缺失值用对应元素的均值补全;
[0023]
采用中心对数比变换法对已知多元地球化学元素含量观测数据进行处理,处理公式如下:
[0024][0025]
其中,xm和zm分别代表第m个元素变换前后的值,d代表元素个数。本发明采用对数
比变换法,能消除闭合效应。
[0026]
进一步的,所述步骤s1在获取训练随机森林模型所需的训练数据后还包括以下步骤:
[0027]
采用待预测区域掩膜文件对栅格数据进行裁剪,并统一数据的坐标系。
[0028]
进一步的,所述步骤s2中根据输入变量与已知地球化学元素含量观测数据之间的相关系数及输入变量之间的相关性筛选输入变量包括以下步骤:
[0029]
计算各个输入变量与已知地球化学元素含量观测数据之间的相关系数并剔除弱相关性输入变量,再计算各个输入变量之间的相关性,任意两个输入变量之间相关性大于设定阈值时保留其一。
[0030]
进一步的,所述计算各个输入变量与已知地球化学元素含量观测数据之间的相关系数、计算各个输入变量之间的相关性均包括以下步骤:对于连续型数据,计算pearson相关系数,对于离散型数据,计算spearman秩相关系数;
[0031]
计算各个输入变量与已知地球化学元素含量观测数据之间的相关系数时若相关系数绝对值|r|《0.3,则剔除该属性特征。
[0032]
进一步的,所述步骤s3包括以下步骤:
[0033]
s31、定义模拟栅格图层和滑动窗口半径序列,以及确定随机森林模型中决策树的数目和决策树节点划分时属性的数目;
[0034]
s32、按照从左到右,从上到下的顺序遍历栅格单元,对于当前需预测地球化学元素含量值的栅格位置,利用紧凑度指数确定最佳滑动窗口半径;
[0035]
s33、计算空间邻域观测点的空间权重:提取最佳窗口内的训练样本,通过全局变差函数模型和克立格方程组求解训练样本的权重;
[0036]
s34、训练地统计加权随机森林模型:采用地统计加权的均方根误差函数作为改进的目标函数,训练随机森林回归模型;
[0037]
s35、预测地球化学元素含量未知点处的取值:将待预测位置s处的预测因子值输入步骤s34训练好的随机森林模型,预测地球化学元素含量值;
[0038]
s36、重复步骤s32~步骤s35,遍历结束即得完整的地球化学元素含量空间分布图。本发明采用滑动窗口技术表征地球化学元素含量分布的空间异质性,定义滑动窗口半径序列,用于之后借助紧凑度指数动态确定最佳滑动窗口尺寸。如此,本发明将当前栅格位置处的预测因子作为随机森林模型的输入,即可预测地球化学元素含量值。重复步骤s32~步骤s35,遍历结束,即得完整的地球化学元素含量空间分布图。
[0039]
进一步的,所述步骤s31中定义滑动窗口半径序列为ε1≤ε2≤
…
ε
t
,滑动窗口采用方形窗口,当窗口半径为ε
t
(1≤t≤t)时,滑动窗口的大小为(2ε
t
+1)
×
(2ε
t
+1);
[0040]
所述步骤s32中利用紧凑度指数确定最佳滑动窗口半径包括以下步骤:
[0041]
对于当前需预测地球化学元素含量值的栅格位置s,计算滑动窗口半径为ε
t
时的紧凑度指数,紧凑度指数计算公式如下:
[0042][0043]
其中,c
t
代表落入半径为ε
t
窗口内的地球化学观测样本集合,n
t
是样本数目,yj′
和yk′
代表地球化学样本;若相邻两个窗口内样本几乎来自同一个统计分布总体,则d
t
和d
t+1
差
别不大;若样本明显来自两个不同统计总体,则di和d
i+1
在整个变化趋势中会出现突变,计算相邻紧凑度指数d
t
(t=1,2,
…
t)之差d
t+1-d
t
,设差值最大时滑动窗口对应的半径为ε
t
,则优选出的最佳半径为ε*(s)=ε
t
;
[0044]
所述步骤s33计算空间邻域观测点的空间权重包括以下步骤:
[0045]
获取位置s处最佳窗口内的训练样本
[0046]
{(x1(s
l
′
),x2(s
l
′
),
…
,xk(s
l
′
);y(s
l
′
)),l
′
=1,2,
…
l
′
{(l
′
《l),计算各个样本所处位置s
l
′
(l
′
=1,2,
…
l
′
)与位置s的欧氏距离,计算公式为:
[0047][0048]
将计算得到的欧氏距离代入利用全局样本拟合的变差函数模型γ(h);
[0049]
求解克立格方程组,公式为:
[0050][0051]
上式共包含l
′
+1个方程,式中未知数为λ
l
′
(l
′
=1,2,
…
l
′
)和μ共l
′
+1个,其中μ为拉格朗日算子,求解该方程组得到的λ
l
′
即为邻域观测点的权重;
[0052]
所述步骤s34训练地统计加权随机森林模型包括以下步骤:
[0053]
对于每个回归决策树,采用改进的目标损失函数进行训练,公式为:
[0054][0055]
其中,
[0056][0057][0058]
x代表构建决策树的切分属性或因子,v代表构建决策树相应属性的切分点,y
left
和y
right
分别代表左子节点和右子节点所包含的地球化学观测样本点取值集合,ya和yb分别代表左右子节点集合中的样本值,n
left
和n
right
分别代表左子节点和右子节点中观测样本的数目。
[0059]
进一步的,所述步骤s2与步骤s3之间还包括以下步骤:将训练样本分为训练数据集和验证数据集,所述步骤s3基于训练数据集训练随机森林模型;所述步骤s3之后还包括以下步骤:提取验证数据集中各验证样本所处位置处的地球化学变量预测值,建立验证样本观测值与预测值数据对(y
g,eval
,y
g,obs
)(g=1,2,
…neval
)的线性回归模型,得到决定系数r2,据此定量评价随机森林模型的预测效果;其中,y
g,eval
代表第g个点处地球化学变量的模型预测值,y
g,obs
代表第g个点处地球化学变量的参考值,n
eval
代表验证点的个数。如此,本发明基于构建好的训练数据集训练随机森林模型,并借助训练好的模型对未采样栅格的地球化学元素含量进行预测。借助测试数据集对得到的元素含量预测结果进行验证分析,并将
模型输出的特征重要性进行空间制图,可作为后续分析的重要参考。
[0060]
综上所述,本发明与现有技术相比具有以下有益效果:(1)现有经典随机森林回归算法在构建决策树时,预测值的计算方式是求取叶子节点内所有样本观测值的平均值。由于地学变量观测样本存在一定程度的空间相关性,本发明通过地统计方法为叶子节点内样本进行加权,预测得到的目标位置变量取值更加准确,元素含量分布结果更能反映地质地球化学过程的空间变异特征。
[0061]
(2)现有经典随机森林算法只在研究区构建一个全局随机森林模型,难以顾及地球化学元素含量空间分布的变异特征。本发明将滑动窗口技术与随机森林模型相结合,同时借助紧凑度指数确定任意局部位置的最佳滑动窗口尺寸,能够更好地捕捉局部地球化学分布模式的尺度。
[0062]
(3)本发明同时考虑空间异质性和空间相关性特征,对地学变量的空间分布进行预测,并提供度量其不确定性的指标,有助于提高元素含量的预测精度。
附图说明
[0063]
此处所说明的附图用来提供对本发明实施例的进一步理解,构成本技术的一部分,并不构成对本发明实施例的限定。在附图中:
[0064]
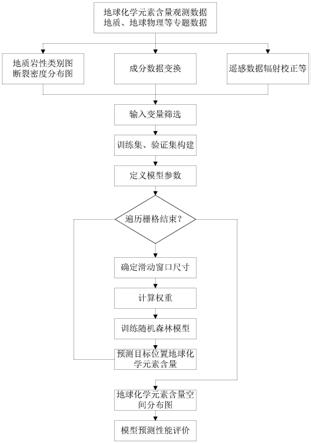
图1为本发明一个具体实施例的流程图;
[0065]
图2为本发明一个具体实施例的预测方法示意图。
具体实施方式
[0066]
为使本发明的目的、技术方案和优点更加清楚明白,下面结合实施例和附图,对本发明作进一步的详细说明,本发明的示意性实施方式及其说明仅用于解释本发明,并不作为对本发明的限定。
[0067]
实施例:
[0068]
如图1所示,基于地统计加权随机森林的地球化学变量空间预测方法,包括以下步骤:s1、获取训练随机森林模型所需的训练数据,其中,训练数据包括输入变量和模型输出变量,输入变量和输出变量采用栅格格式存储,输入变量包括地质要素和遥感要素,地质要素包括从区域地质数据提取的岩性类别数据和从区域地质数据提取的线环构造矢量数据转换的断裂密度,遥感要素包括地形坡度和植被覆盖度,模型输出变量为已知地球化学元素含量观测数据;s2、根据输入变量与已知地球化学元素含量观测数据之间的相关系数及输入变量之间的相关性筛选输入变量作为预测因子,将已知地球化学元素含量观测数据与预测因子作为训练样本;s3、基于训练样本训练随机森林模型,并采用训练好的随机森林模型对待预测位置的地球化学元素含量进行预测。
[0069]
本实施例中输入变量即为模型训练所需的输入要素,模型输出变量即为模型的响应变量,本实施例针对地球化学元素含量预测问题,区域地质数据可从全国地质资料馆获取,收集1:5万或1:20万水系沉积物区域勘查地球化学数据,该数据多以原始数据表格(如excel)或矢量格式存储(如mapgis),基本包含常量元素化合物及微量元素含量数据。本实施例统一以栅格数据格式(如tiff)存储,从区域地质数据提取的线环构造矢量数据转换的断裂密度为连续型变量,从区域地质数据中提取岩性类别数据,用无序类别变量表示。遥感
数据可从地理空间数据云网站获取,提取地形坡度、植被覆盖度,用连续型变量表示。本实施例的输出变量是具有完整空间分布的已知地球化学元素含量观测数据,模型训练时输入,其只有部分位置有值,地球化学元素含量未知点(即待预测位置)处的取值采用训练好的随机森林模型预测。
[0070]
本实施例在具体实施时,为了进一步提升精度,输入变量不局限于地质要素和遥感要素,还可提取其它与地球化学元素含量有关的地质、地球物理等专题数据,并对这些数据进行预处理,如可对航磁数据进行航磁化极处理。本实施例的地质要素不局限于岩性类别和断裂密度,遥感要素不局限于地形坡度和植被覆盖度。
[0071]
输入变量和输出变量属于类别变量或连续变量,因此,需要对收集的数据进行适当处理和变换。为便于存储与进一步建模分析,数据统一采用栅格格式存放。为此,需构建能够覆盖研究区的矩形栅格,根据所收集数据的精度和研究目的,设置合适的栅格单元大小。
[0072]
本实施例的步骤s1在获取训练随机森林模型所需的训练数据后还包括以下步骤:离群值剔除、缺失值插补和成分数据变换等预处理,再采用待预测区域掩膜文件对栅格数据进行裁剪,并统一数据的坐标系。其中,掩膜文件为以矢量或栅格格式存储的研究区边界文件。本实施例应用时,若存在数据的坐标系不一致问题,采用现有的arcgis软件将其进行变换统一,通过统一数据的坐标系,便于不同空间数据的对比和运算。
[0073]
本实施例步骤s1中将线环构造矢量数据转换为断裂密度的转换公式为:
[0074][0075]
其中,i表示栅格的行,j表示栅格的列,ρ
ij
为第i行第j列栅格的断裂密度,l
ij
为对应栅格内线性断裂和环形断裂的总长度,s为栅格的面积;线环构造矢量数据为区域地质数据中的断裂矢量数据,本实施例经转换后可得到地质岩性类别图。
[0076]
本实施例步骤s1中岩性类别数据为将区域地质数据中的岩性分布数据转换的类别变量,即
[0077]cij
∈{ck,k=1,2,
…
n}
[0078]
其中,n为岩性类别总数,ck表示n种岩性类别中的第k种岩性,c
ij
代表栅格位置(i,j)处的岩性类别。如此,本实施例经转换后可得到断裂密度分布图。
[0079]
所述步骤s1还包括对遥感数据进行辐射校正处理,并利用以下公式计算归一化植被指数:
[0080][0081]
其中,i表示栅格的行,j表示栅格的列,ndvi
ij
为栅格位置(i,j)处的植被指数,为近红外波段处的反射率,为红光波段处的反射率。
[0082]
本实施例的步骤s1还包括以下已知地球化学元素含量观测数据处理步骤:针对已知地球化学元素含量观测数据,首先采用阈值法对目标元素含量的离群值进行剔除,本实施例的剔除方式为迭代剔除位于区间[μ
m-3σm,μm+3σm]之外的已知观测值,其中,μm为第m个元素的均值,σm为迭代过程中第m个元素的标准差;
[0083]
对低于检测限的观测值用相应元素检测限的一半代替;
[0084]
对缺失值用对应元素的均值补全;
[0085]
由于地球化学元素含量数据属于闭合数据,即所有元素或化合物的含量值的和为一常数,不能够直接用于欧氏距离等的计算,因此,需采用对数比变换方法消除闭合效应,因此,本实施例采用中心对数比变换法对已知多元地球化学元素含量观测数据进行处理,处理公式如下:
[0086][0087]
其中,xm和zm分别代表第m个元素变换前后的值,d代表元素个数。
[0088]
本实施例步骤s2中根据输入变量与已知地球化学元素含量观测数据之间的相关系数及输入变量之间的相关性筛选输入变量包括以下步骤:计算各个输入变量与已知地球化学元素含量观测数据之间的相关系数并剔除弱相关性输入变量,在基本不影响模型精度的同时使模型尽可能简单;再计算各个输入变量之间的相关性,任意两个输入变量之间相关性大于设定阈值时保留其一,以避免由于存在强的多重共线性导致模型结果不可靠。保留下来的输入要素和已知地球化学元素含量观测数据作为模型的最终输入数据集,即作为训练样本。本实施例计算各个输入变量与已知地球化学元素含量观测数据之间的相关系数、计算各个输入变量之间的相关性均包括以下步骤:对于连续型数据,计算pearson相关系数,对于离散型数据,计算spearman秩相关系数。计算各个输入变量与已知地球化学元素含量观测数据之间的相关系数时若相关系数绝对值|r|《0.3,则剔除该属性特征。本实施例应用时,若存在某两个或多个输入变量之间的相关系数大于设定阈值(本实施例设为0.85),则剔除部分输入变量,保证各个输入变量之间的相关性不高于设定阈值,以避免多重共线性问题导致模型结果不可靠。
[0089]
本实施例的骤s2与步骤s3之间还包括以下步骤:将训练样本分为训练数据集和验证数据集,步骤s3基于训练数据集训练随机森林模型。本实施例的步骤s3之后还包括以下步骤:提取验证数据集中各验证样本所处位置处的地球化学变量预测值,建立验证样本观测值与预测值数据对(y
g,eval
,y
g,obs
)(g=1,2,
…neval
)的线性回归模型,得到决定系数r2,据此定量评价随机森林模型的预测效果;其中,y
g,eval
代表第g个点处地球化学变量的模型预测值,y
g,obs
代表第g个点处地球化学变量的参考值,n
eval
代表验证点的个数。
[0090]
本实施例采用随机抽样方式划分为训练集和验证数据集,训练数据集用于模型训练,验证数据集用于模型性能验证,具体方式为:设经过上述处理得到的预测因子集合为k为预测因子数目,s=(i
″
,j
″
)代表空间位置,xk(s)代表第k(k=1,2,
…
k)个预测因子在位置s上的取值,g代表研究区域,代表二维实数空间;地球化学元素含量值为{y(s1),y(s2),
…
y(s
l
)},其中s
l
(l=1,2,
…
l)代表地球化学样本的空间位置,提取位置s
l
处的预测因子,构成数据集d={(x1(s
l
),x2(s
l
),
…
,xk(s
l
);y(s
l
)),l=1,2,
…
l。采用随机抽样方式按照7:3的比例将d划分为训练数据集和验证数据集d=d
train
∪d
eval
。
[0091]
本实施例的步骤s3包括以下步骤:s31、定义模拟栅格图层和滑动窗口半径序列,以及确定随机森林模型中决策树的数目和决策树节点划分时属性的数目;s32、按照从左到
右,从上到下的顺序遍历栅格单元,对于当前需预测地球化学元素含量值的栅格位置,利用紧凑度指数确定最佳滑动窗口半径;s33、计算空间邻域观测点的空间权重:提取最佳窗口内的训练样本,通过全局变差函数模型和克立格方程组求解训练样本的权重;s34、训练地统计加权随机森林模型:采用地统计加权的均方根误差函数作为改进的目标函数,训练随机森林回归模型;s35、预测地球化学元素含量未知点处的取值:将待预测位置s处的预测因子值输入步骤s34训练好的随机森林模型,预测地球化学元素含量值;s36、重复步骤s32~步骤s35,遍历结束即得完整的地球化学元素含量空间分布图。本实施例定义模拟栅格图层时,栅格单元大小与前述构建能够覆盖研究区的矩形栅格保持一致,并将已知地球化学观测点数据赋值给最邻近栅格单元,作为后续模拟的条件数据。这里采用滑动窗口技术表征地球化学元素含量分布的空间异质性。因此,需事先定义滑动窗口半径序列,合适的窗口尺寸应该能够反映地球化学元素含量变异的空间范围,同时窗口内数据量应足够用于统计推断。由于随机森林模型的性能依赖于两种随机机制:一是随机森林中每棵决策树所使用的训练数据是从原始训练数据集随机抽样获得的一个子集,二是构建决策树时用于节点划分的属性来源于从属性集合随机抽取的子集,因此,需兼顾随机森林性能及运算时间复杂度,定义合适的决策树数目和决策树节点划分时属性的数目。
[0092]
本实施例采用滑动窗口技术表征地球化学变量分布的空间异质性,定义滑动窗口半径序列为ε1≤ε2≤
…
ε
t
,t为滑动窗口的个数,之后将借助紧凑度指数动态确定最佳滑动窗口尺寸,滑动窗口采用方形窗口,滑动窗口半径以栅格单元为单位。如图2所示,当窗口半径为ε
t
(1≤t≤t)时,滑动窗口的大小为(2ε
t
+1)
×
(2ε
t
+1)。本实施例步骤s32中利用紧凑度指数确定最佳滑动窗口半径包括以下步骤:按照从左到右,从上到下的顺序遍历栅格单元,对于当前需预测地球化学元素含量值的栅格位置s,计算滑动窗口半径为ε
t
时的紧凑度指数,紧凑度指数计算公式如下:
[0093][0094]
其中,c
t
代表落入半径为ε
t
窗口内的地球化学观测样本集合,n
t
是样本数目,yj′
和yk′
代表地球化学样本;随着窗口半径不断变化,d
t
取值也在不断发生变化,若相邻两个窗口内样本几乎来自同一个统计分布总体,则d
t
和d
t+1
差别不大;若样本明显来自两个不同统计总体,则di和d
i+1
在整个变化趋势中会出现突变,计算相邻紧凑度指数d
t
(t=1,2,
…
t)之差d
t+1-d
t
,设差值最大时滑动窗口对应的半径为ε
t
,则优选出的最佳半径为ε
*
(s)=ε
t
。本实施例步骤s33计算空间邻域观测点的空间权重包括以下步骤:获取位置s处最佳窗口内的训练样本{(x1(s
l
′
),x2(s
l
′
),
…
,xk(s
l
′
);y(s
l
′
)),l
′
=1,2,
…
l
′
}(l
′
《l),计算各个样本所处位置s
l
′
(l
′
=1,2,
…
l
′
)与位置s的欧氏距离,计算公式为:
[0095][0096]
将计算得到的欧氏距离代入利用全局样本拟合的变差函数模型γ(h);
[0097]
求解克立格方程组,公式为:
[0098][0099]
上式共包含l
′
+1个方程,式中未知数为λ
l
′
(l
′
=1,2,
…
l
′
)和μ共l
′
+1个,其中μ为拉格朗日算子,求解该方程组得到的λ
l
′
即为邻域观测点的权重。
[0100]
本实施例步骤s34训练地统计加权随机森林模型包括以下步骤:对于每个回归决策树,采用改进的目标损失函数进行训练,公式为:
[0101][0102]
其中,
[0103][0104][0105]
x代表构建决策树的切分属性或因子,v代表构建决策树相应属性的切分点,y
left
和y
right
分别代表左子节点和右子节点所包含的地球化学观测样本点取值集合,由划分属性xk及该属性切分点v
kw
所得,ya和yb分别代表左右子节点集合中的样本值,n
left
和n
right
分别代表左子节点和右子节点中观测样本的数目。该步骤和经典随机森林算法的不同之处在于:和的计算不再是简单地求取算数平均数,而是地统计加权的平均数,权重反映了地学变量空间分布的相关性特征。
[0106]
本实施例采用地统计方法为随机森林中各决策树叶子节点样本进行加权,改进随机森林的损失函数,更好地反映地学变量的空间相关性特征。将滑动窗口技术与随机森林相结合,同时借助紧凑度指数动态确定最佳滑动窗口尺寸,更好地反映地学变量的空间变异性特征,能提升预测精度。
[0107]
以上所述的具体实施方式,对本发明的目的、技术方案和有益效果进行了进一步详细说明,所应理解的是,以上所述仅为本发明的具体实施方式而已,并不用于限定本发明的保护范围,凡在本发明的精神和原则之内,所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1