一种基于视觉的水面油污检测方法与流程
1.本技术涉及实体识别技术领域,尤其涉及一种基于视觉的水面油污检测方法。
背景技术:
2.水面油污是严重影响水体质量的重要方面,严重威胁水体中动植物的生存,污染土壤和水源,危害人体健康,必须要对油污进行实时检测,一旦检测到存在油污需要第一时间采取必要措施进行消除。除会对环境产生二次污染的四氯化碳外,油污检测还可以采用传感器方法,传感器方法一般采用可与油污产生化学反应的物质,一旦产生化学反应后,或触发机械组件产生报警,或产生光电信号后计算油含量,从而进行报警,这类装置一般结构比较复杂,成本较高,且部署点位较多,要求较高,相比之下采用视觉的方法成本低,部署方便。
3.基于视觉的水面油污检测技术又可以分为三种方式:
4.1.图像分类方法。图像分类是根据各自在图像信息中所反映的不同特征,把不同类别的目标区分开来的图像处理方法。该方法可解决“有没有油污”的问题,仅给出图像或画面中是否包含油污区域,但无法给出存在油污区域情况下,油污区域在图像或画面中的具体位置。
5.2.目标检测方法。目标检测的任务是找出图像中所有感兴趣的目标(物体),确定它们的类别和位置。该方法解决“有没有油污,如果有油污,在哪里”的问题,即不仅给出图像或画面中是否包含油污区域,同时给出存在油污区域的位置与范围,只是该范围一般以矩形的方式呈现。
6.3.目标分割。目标分割是指将图像细分为多个图像子区域的过程。对于水面油污检测问题,目标分割方法可在目标检测结果的基础上,对油污区域范围进一步精确化,给出油污区域的不规则边缘信息,而非矩形区域。
7.在以上三种方式中,图像分类方法因不能提供水面油污区域的位置相关信息,故难以满足要求;目标分割方法能够给出较为具体的水面油污边缘信息,但该类方法存在标注复杂、边缘信息精度稍低等问题。相比之下,目标检测方法实施较为简洁,提供的结果已能满足要求,且精度相对较高,因此采用目标检测方法。目标检测类方法又大体上分为基于传统图像处理的方法与基于深度学习的方法。基于传统图像处理的方法一般需要深入研究水面油污的特点,以及与正常水面的区分特征,从而制定相应的检测规则或寻找水面油污不随光照、角度、范围等变化的鲁棒特征,从而利用边缘提取、二值化等图像基本处理过程与组合、空间变换等进行油污区域检测。这种方式在鲁棒性、精度方面存在较大的改善空间,而水面油污区域与正常水面在颜色方面可以区分,但受光线、角度等应先较大,易混淆,且油污区域范围为柔性的,且随水流影响较大,具有动态性特征。因此,基于传统图像处理的方法在这方面具有一定的局限性。基于深度学习的方法,主要依靠神经网络、卷积、池化、损失函数优化、分类器等进行准确、鲁棒特征提取,能够较好的区分背景与前景,并对目标类型进行检测与分类。该方法虽然对数据或样本的依赖性较强,但通过多种途径获取样本、
长时间积累样本等方式则不构成关键性问题,仅需要解决正负样本不均衡、样本的特征分布与模型泛化能力、模型精度和实时性等问题。
技术实现要素:
8.有鉴于此,本技术实施例提供了一种基于视觉的水面油污检测方法,能够准确检测水面油污区域的精度和实时性,提高实用性。
9.为解决上述技术问题,本说明书实施例是这样实现的:
10.本说明书实施例提供的一种基于视觉的水面油污检测方法,包括:
11.获取样本图像并进行标注,所述样本图像包括原本图像和基于所述原本图像扩充的数据;
12.对所述样本图像进行预处理;
13.采用目标检测模型对处理后的样本图像进行特征提取,所述目标检测模型使用yolov3-darknet53(目标检测中常用的一种网络,其中yolov3是目标检测的一种算法,yolo是“you only look once”的首字母,v3表示第三版,darknet是一个深度学习框架,darkenet53是yolov3网络中的一部分,53表示网络有53层)作为主干特征提取网络,并加入了spp层;
14.根据提取的特征预测油污区域结果,保存预测模型;
15.根据测试精度、资源占用和推理速度对所述预测模型进行优化;
16.采用优化后的预测模型进行水面油污检测。
17.可选的,采用上下翻转、镜像、平移、旋转的方式对原本图像进行扩充。
18.可选的,对所述样本图像进行预处理,具体包括:
19.统一所述样本图像的尺寸并进行归一化处理;
20.随机选取四张照片使用mosaic增强,再对mosaic增强的图片进行mixup增强。
21.可选的,所述目标检测模型在网络中使用残差的跳层连接,使用卷积代替池化进行降采样;所述spp层将提取的特征传入不同感受野的池化层,并将处理后的特征拼接成一个新的特征。
22.可选的,所述根据提取的特征预测油污区域结果,具体包括:
23.针对检测任务,采用解耦头代替耦合头,采用三个分支分别预测位置、目标置信度与分类概率;
24.设定模型训练轮次阈值,模型训练完设定次数后,评估一次训练性能,根据模型评估指标规则选取最优模型。
25.可选的,根据提取的特征预测油污区域结果,还包括:
26.将测试样本输入至所述预测模型,对输出结果通过置信度阈值筛选,保留置信度与类别信息之积大于置信度阈值的结果;将该结果通过nms阈值筛选去除重叠的候选区域,对每个预测框的类别置信度排序,获取最大置信度以及对应的标签作为最终油污区域检测结果。
27.可选的,根据测试精度、资源占用和推理速度对所述预测模型进行优化,具体包括:
28.根据测试精度、资源占用和推理速度,利用tensorrt、网络裁剪与量化技术,对优
化后的预测模型进行轻量化处理。
29.可选的,在特征提取过程中采用anchorfree技术。
30.可选的,使用pascalvoc或coco两种数据集标注格式进行标注。
31.可选的,所述获取样本图像并进行标注,具体包括:
32.首先利用labelimg对扩充前的正样本进行人工标注,然后利用python环境下的imgaug模块对扩充的图像自动进行标注。
33.本说明书实施例采用的上述至少一个技术方案能够达到以下有益效果:
34.1、通过对样本进行标注、筛选、上采样与下采样并进行扩充,充分利用mosic与mixup等方法,解决了模型所需的样本问题。
35.2、针对水面油污检测的单目标检测问题,通过对模型在特征提取层、分类器结构设计,采用anchor-free、multi positives、simota等技术,提高方法的检测精度、速度等。
附图说明
36.此处所说明的附图用来提供对本技术的进一步理解,构成本技术的一部分,本技术的示意性实施例及其说明用于解释本技术,并不构成对本技术的不当限定。在附图中:
37.图1为本发明提供的方法应用的装置结构图;
38.图2为实施例一提供的基于视觉的水面油污检测方法的流程示意图;
39.图3为实施例二提供的基于视觉的水面油污检测方法的流程示意图。
具体实施方式
40.为使本技术的目的、技术方案和优点更加清楚,下面将结合本技术具体实施例及相应的附图对本技术技术方案进行清楚、完整地描述。显然,所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本技术保护的范围。
41.本发明所采用的技术方案是:在需要进行水面油污区域检测的场所安装一台相机,并配备光照调节组件,将油污检测装置与相机根据现场情况通过有线、无线等方式相连接,实时获取水面视频或画面图像,利用边缘计算的思想与基于视觉的水面油污检测的方法进行检测,一旦检测到水面存在油污,即通过网络向后台报警,报警信息包括两种类型,一是文字报警,传输内容少,传输速度快;二是图像报警,将油污区域在图像中进行标识,传递给后台,可视化强。同时,装置具备防水、防尘、防震等功能,且考虑了野外续航能力的问题,在电池容量、外接电源、算法资源占用、数据传输等方面进行了多方面的优化。并且,具备模型升级能力。
42.以下结合附图,详细说明本技术各实施例提供的技术方案。
43.本发明提供的基于视觉的水面油污检测方法需要有一下功能进行支撑。如图1所示,需要相机、检测装置和后台系统。具体的,
44.检测装置上配置相机视频采集模块,可以为有线网络、无线网络、usb等多种连接方式,且获取视频具有速度快,延时短的特点。
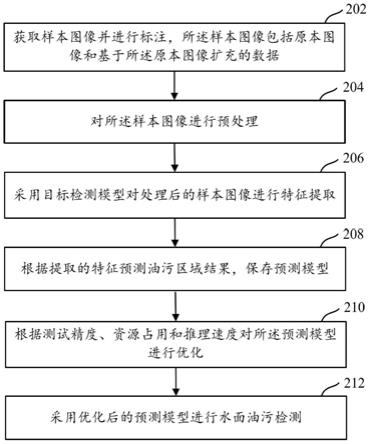
45.考虑了室外部署,维护成本高的问题,通过采用异常处理、冗余、故障检测、自动运行与重启等手段,保证检测装置与后台系统运行的高可靠性,降低维护工作量与成本;
46.检测装置与后台系统保持长连接状态,并采用心跳机制检测网络与连接状态,实时与后台系统进行油污区域的数据传输,并根据后台指令调整检测机制与数据传输机制。
47.预测模型配置在检测装置上,提供模型在线更新功能。模型是决定水面油污检测性能重要因素,在装置运行过程中不断采集样本,为模型更新提供数据支撑,同时装置自动检测后台服务器的模型更新情况并按时、定期自动下载,并在自动更新失败的情况下支持手动更新。
48.其中,检测装置采用结构封装与散热方式,并配备电池;装置具有网络接口、usb接口、wifi模块与4g模块、航插接口,支持与相机的多种连接方式,以及与后台系统的数据传输;装置具有防水、防尘、防摔等功能,达到i p66等级;
49.检测装置采用瑞芯微rk3399pro芯片,合理利用cpu、gpu与npu;装置实现了从相机连接、视频采集、油污检测、告警信息传输等全流程处理,针对续航、检测时间、检测频率等方面进行了优化处理,并全面考虑了视频采集异常、处理过程异常、处理结果异常、数据传输异常等全面异常情况的处理。
50.实施例一
51.图2为实施例一提供的基于视觉的水面油污检测方法的流程示意图。如图2所示,该流程可以包括以下步骤:
52.步骤102:获取样本图像并进行标注,所述样本图像包括原本图像和基于所述原本图像扩充的数据;
53.步骤102,首先利用labelimg对扩充前的正样本进行人工标注,然后利用python环境下的imgaug模块对扩充的图像自动进行标注。
54.其中,可以采用上下翻转、镜像、平移、旋转的方式对原本图像进行扩充。
55.其中,还可以使用pascalvoc或coco两种数据集标注格式进行标注。
56.步骤104:对所述样本图像进行预处理;
57.可选的,对所述样本图像进行预处理,具体可以包括:
58.统一所述样本图像的尺寸并进行归一化处理;
59.随机选取四张照片使用mosaic增强,再对mosaic增强的图片进行mixup增强。
60.mosaic丰富了检测数据集,随机缩放增加了很多小目标,让网络的鲁棒性更好,增加了训练过程中batch的数量,减少了batch对gpu的要求。mixup处理在丰富数据集的同时,在基本无额外计算法开销的情况下加强了网络的泛化性和精确性。
61.步骤106:采用目标检测模型对处理后的样本图像进行特征提取,所述目标检测模型使用yolov3-darknet53作为主干特征提取网络,并加入了spp层;
62.可选的,所述目标检测模型在网络中使用残差的跳层连接,使用卷积代替池化进行降采样;所述spp层将提取的特征传入不同感受野的池化层,并将处理后的特征拼接成一个新的特征。
63.可选的,在特征提取过程中采用anchor free技术,避免了anchor based对anchorbox进行聚类分析增加的工作量与成本。
64.步骤108:根据提取的特征预测油污区域结果,保存预测模型;
65.具体的,可所述根据提取的特征预测油污区域结果,可以包括:
66.针对检测任务,采用解耦头代替耦合头,采用三个分支分别预测位置、目标置信度
与分类概率;使用了解耦头思想,解耦头有更好的收敛速度与精度,同时网络也可以更方便的和某些算法任务进行结合。
67.设定模型训练轮次阈值,模型训练完设定次数后,评估一次训练性能,根据模型评估指标规则选取最优模型。
68.上面是初次测试结果,还可以包括以下步骤,得到最终预测结果:
69.将测试样本输入至所述预测模型,对输出结果通过置信度阈值筛选,保留置信度与类别信息之积大于置信度阈值的结果;将该结果通过nms阈值筛选去除重叠的候选区域,对每个预测框的类别置信度排序,获取最大置信度以及对应的标签作为最终油污区域检测结果。
70.步骤110:根据测试精度、资源占用和推理速度对所述预测模型进行优化;
71.具体的,根据测试精度、资源占用和推理速度,利用tensorrt、网络裁剪与量化技术,对优化后的预测模型进行轻量化处理。
72.步骤112:采用优化后的预测模型进行水面油污检测。
73.实施例二
74.图3为实施例二提供的基于视觉的水面油污检测方法的流程示意图。如图3所示,该流程可以包括以下步骤:
75.步骤1:样本采集与扩充。通过采集视频或拍照的方式采集样本,可选用上下翻转、镜像、平移、旋转对数据集进行扩充。假设每类样本数量为m的情况下,可以考虑将数量扩充数量为cm左右。其中,c根据实际样本规模来确定。在扩充时避免图像的重复生成,原始数据应与扩充数据有差异。
76.本实施例中,未包含油污的样本较多,约为3000张,包含油污的样本较少,约为500张。为达到样本均衡,将未包含油污的样本扩充一倍为6000张,将包含油污的样本扩充同样为6000张。
77.步骤2:样本标注。可使用pascalvoc与coco两种数据集标注格式,这里采用pascalvoc格式。使用labelimg进行标注,标注过程中,有无区域大小和位置适当,类型准确无误,区域全部标注,无止漏标误标情况。
78.在本实施例中,首先利用labelimg对扩充前的正样本进行人工标注,然后利用python环境下的imgaug模块对扩充的图像自动进行标注,以节省工作量与时间。
79.步骤3:样本表示。获取已经标注的训练数据集,对所述训练数据集中的每一条数据进行预处理,得到图像集合i=i1,i2,
…
,im,其中m表示图像数量。为提高检测性能,引入正负样本类型,正样本是指包含油污的图像,负样本是指不包含油污的图像,令f=f1,f2,
…
,fm表示正负样本的标识,
80.fi=1表示正样本,fi=0表示负样本,i=1,2,
…
,m。第i个样本中的油污区域集合表示为ri=[r
i1
,
…
,r
in
],其中n表示油污区域的数量,r
ij
=[xj,yj,wj,hj],其中(xj,yj)表示图像中第j个油污区域的中心点坐标,wj表示图像中第j个油污区域的宽度,hj表示图像中j个油污区域的高度。
[0081]
在本案例中,正样本为6000张,负样本为6000张,油污区域为6000个。每个油污区域坐标与范围按图像中的实际信息提供。
[0082]
步骤4:数据预处理。读取图像后,首先对图像进行resize与归一化处理,然后进行
数据增强。数据增强的流程是先随机选取四张照片使用mosaic增强,再对mosaic增强的图片进行mixup增强。mosaic数据增强试将4张图片按照随机缩放、随机裁剪、随机翻转的方式处理。将处理的四张图随机排布到一张原图大小的空图上,确定每张图片的范围,裁剪掉图片范围之外的部分。mixup是将两张图片随机透明化,然后按照加权的方式将两图线性相加。
[0083]
在本案例中,图像均缩放为640
×
480大小并进行归一化,然后按上述关于mosaic和mixup的要求进行数据增强。
[0084]
步骤5:特征提取。预处理完成后的图片传输给目标检测模型。使用yolov3-darknet53作为主干特征提取网络,并加入了spp层(空间金字塔池化)。在网络中使用残差的跳层连接,并且为降低池化带来的梯度负面效果,使用卷积代替池化进行降采样。spp将提取的特征传入不同感受野的池化层,并将处理后的特征拼接成一个新的特征,增加了网络的不变性以及特征的表达能力。
[0085]
在本案例中,利用python语言与tensorflow框架对过程进行实现。
[0086]
步骤6:特征处理。将提取到的特征传输给neck结构(特征处理模块),neck结构将提取到的特征处理成更适合prediction(预测模块)预测的结构。
[0087]
在本案例中,利用python语言与tensorflow框架对过程进行实现。
[0088]
步骤7:油污区域预测。prediction模块接受提取到的特征,根据这些特征预测出油污区域结果。针对检测任务,耦合头用一个分支预测了位置、目标置信度、与分类概率。解耦头则有三个分支分别对应了上述三个任务,使得网络有更好的表达能力。解耦头有更好的收敛速度与精度,同时网络也可以更方便的和某些算法任务进行结合。
[0089]
在本案例中,首先,计算候选框与gtb(ground truth box,真实框)的iou(intersection over union,交并比,是两个区域重叠部分面积占二者总面积的比例),挑选k个iou值最大的候选框,将iou值相加,假设iou值的和四舍五入取整为s,则为该gtb(groundtruthbox,真实框)分配s个候选框(将候选框的类别损失与位置损失相乘得到总的损失,将损失从小到大排序选取前s个候选框)。然后,每个gtb选取cost值最小的预测框为正样本,其余为负样本。当该gtb分配的候选框中与其他gtb有重复时。则对比该候选框在两个gtb上的cost值,预测框分配给值更小的gtb。
[0090]
步骤8:保存模型。模型每训练几个轮次,评估一次训练性能,针对测试样本map50、map50:90(map:mean average precision,平均精度均值,map50:iou阈值为0.5时的ap测量值,map50:90:iou阈值在[0.5,0.9]范围内设置为多个值,计算多个map,然后再求平均,得到的就是map50:90)与ap(ap:average precision,平均精度)值,根据模型评估指标规则选取最优模型。
[0091]
在本案例中,训练轮次设置为300次。判断每次迭代的map50:90是否增长决定最优模型的更新。同时保存最后训练轮次的模型。
[0092]
步骤9:模型推理。首先将测试图像resize并归一化。然后对模型的输出结果通过置信度阈值筛选,保留置信度与类别信息之积大于置信度阈值的结果。将该结果通过nms(non maximum suppression,非极大值抑制)阈值筛选去除重叠的候选区域,对每个预测框的类别置信度排序,获取最大置信度以及对应的标签作为最终油污区域检测结果。
[0093]
在本案例中,利用200张正样本与1000张负样本进行测试,误检率与漏检率低于
1%。
[0094]
步骤10:获取模型的精度、资源占用、推理速度等数据,利用tensorrt、网络裁剪与量化技术,在不降低模型性能或降低幅度较小的情况下,对模型进行轻量化处理,并部署到检测装置上。
[0095]
在本案例中,主要通过tensorrt技术对模型进行加速处理,加速后速度提升约15%,精度下降1%。
[0096]
本说明书中的各个实施例均采用递进的方式描述,各个实施例之间相同相似的部分互相参见即可,每个实施例重点说明的都是与其他实施例的不同之处。尤其,对于系统实施例而言,由于其基本相似于方法实施例,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
[0097]
以上所述仅为本技术的实施例而已,并不用于限制本技术。对于本领域技术人员来说,本技术可以有各种更改和变化。凡在本技术的精神和原理之内所作的任何修改、等同替换、改进等,均应包含在本技术的权利要求范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1