一种基于绝对中位差法和标准差法去除异常值的优化算法的制作方法
1.本发明涉及一种优化算法,具体是指一种基于绝对中位差法和标准差法去除异常值的优化算法。
背景技术:
2.异常值在统计学上的全称是疑似异常值,也称作离群点(outlier),异常值的分析也称作离群点分析。异常值是指样本中出现的“极端值”,其数据值看起来异常大或异常小,其分布明显偏离其余的观测值。异常值分析是检验数据中是否存在不合常理的数据,在数据分析中,既不能忽视异常值的存在,也不能简单地把异常值从数据分析中剔除。重视异常值的出现,分析其产生的原因,常常成为发现新问题进而改进决策的契机。而去异常值就是排除一些“极端值”的干扰,只有排除异常值的干扰,才能更好的发现数据之间的规律。异常值的定义方法有很多,一般是先确定一个上下限,超出这个界限的就划为异常值。chanwennt准则规定,如果一个数值偏离观测平均值的概率小于等于1/(2n),则该数据应当舍弃。当数据中心存在异常值时,可能会扭曲统计分析的结果。某些数据由于自身特点,必定会包含“异常值”。
3.同时,正态分布(normal distribution),又名高斯分布(gaussian distribution),最早由棣莫弗(abraham de moivre)在求二项分布的渐近公式中得到。正态分布像一只倒扣的钟。两头低,中间高,左右对称。大部分数据集中在平均值,小部分在两端。在统计上,68
–
95
–
99.7法则(68
–
95
–
99.7 rule)是在正态分布中,距平均值小于一个标准差、二个标准差、三个标准差以内的百分比,更精确的数字是68.27%、95.45%及99.73%。即有68.2%数值位于平均值1个标准差的范围之内,有95.4%的数值位于2个标准差的范围以内,还有99.7%的数值位于3个标准差的范围以内。而现阶段对于满足正态分布的样本中出现异常值的判断处理方法却较为单一,往往容易在去除异常值的同时出现误删的可能,并且还会增加不少计算量和降低判断效率。
技术实现要素:
4.本发明所要解决的技术问题在于克服现有技术的缺陷而提供了判断结果精确、效率高、既不会增加计算量,又在去除异常值的同时减少误删可能的一种基于绝对中位差法和标准差法去除异常值的优化算法。
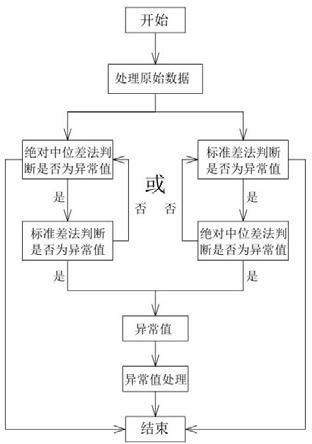
5.本发明的技术问题通过以下技术方案实现:一种基于绝对中位差法和标准差法去除异常值的优化算法,包括如下步骤:步骤一、选择一份满足正态分布的样本,该样本中包含有数值xi样本因子的原始数据;步骤二、对包含有数值xi样本因子的原始数据通过绝对中位差法和标准差法相结合的方式进行判断,即先通过绝对中位差法再通过标准差法的顺序进行异常值判断,或先通过标准差法再通过绝对中位差法的顺序进行异常值判断;
①
先通过绝对中位差法再通过标准差法的顺序进行异常值判断,具体是先通过绝对中位差法判断数值xi样本因子是否为异常值,若否则认定为正常值而结束判断步骤,若是则再通过标准差法进一步判断数值xi样本因子是否为异常值,且标准差法进一步判断数值xi样本因子时,若否则认定为正常值而结束判断步骤或回到绝对中位差法重新判断,若是则直接判断出异常值;
②
先通过标准差法再通过绝对中位差法的顺序进行异常值判断,具体是先通过标准差法判断数值xi样本因子是否为异常值,若否则认定为正常值而结束判断步骤,若是则再通过绝对中位差法进一步判断数值xi样本因子是否为异常值,且绝对中位差法进一步判断数值xi样本因子时,若否则认定为正常值而结束判断步骤或回到标准差法重新判断,若是则直接判断出异常值;步骤三、提取出经过步骤二后判断出的异常值;步骤四、将判断出的异常值从样本中去除;步骤五、完成判断并结束算法步骤。
6.所述的通过绝对中位差法进行异常值判断的步骤为:步骤一、找出所有数值xi样本因子的中位数xmedian;步骤二、计算并得到每个数值xi样本因子与中位数xmedian的绝对偏差值xi-xmedian;步骤三、计算并得到绝对偏差值xi-xmedian的绝对中位差mad;步骤四、确定参数 n,从而确定数值xi样本因子的合理范围为 [xmedian
ꢀ–ꢀ
nmad, xmedian + nmad],并针对超出合理范围的数值xi样本因子做如下调整,超出最大值的用最大值代替,小于最小值的用最小值代替;步骤五、通过确认该绝对中位差mad是否在范围[xmedian
ꢀ–ꢀ
nmad,xmedian + nmad],由此得出否或是的判断。
[0007]
所述的绝对中位差mad符合如下公式:式中,mad——绝对中位差;——第i个数据中的x值;——样本平均值。
[0008]
所述的通过标准差法进行异常值判断的步骤为:步骤一、计算出所有数值xi样本因子的平均值xmedian与标准差σ;步骤二、确定参数 n,从而确定数值xi样本因子的合理范围为 [xmedian
ꢀ–ꢀ
nmad,xmedian + nmad],并针对超出合理范围的数值xi样本因子做如下调整,超出最大值的用最大值代替,小于最小值的用最小值代替;步骤三、通过确认该平均值xmedian与标准差σ是否在范围[xmedian
ꢀ–ꢀ
nmad, xmedian + nmad],由此得出否或是的判断。
[0009]
所述的标准差σ符合如下公式:式中,σ——标准差;
xmedian;步骤三、计算并得到绝对偏差值xi-xmedian的绝对中位差mad;步骤四、确定参数 n,从而确定数值xi样本因子的合理范围为 [xmedian
ꢀ–ꢀ
nmad, xmedian + nmad],并针对超出合理范围的数值xi样本因子做如下调整,超出最大值的用最大值代替,小于最小值的用最小值代替,这里的n即k≈1.4826,具体如下公式所示,步骤五、通过确认该绝对中位差mad是否在范围[xmedian
ꢀ–ꢀ
nmad,xmedian + nmad],由此得出否或是的判断。
[0015]
而上述步骤中涉及的绝对中位差mad,它是定量数据单变量样本变异性的可靠度量。绝对中位差mad定义为与数据中位数的绝对偏差的中位数,绝对中位差法是一种采用计算各观测值与平均值的距离总和的检测离群值的方法,它的一大优势即在于绝对中位差法对样本大小是不敏感的,也即是稳定鲁棒性的一种评价指标,该绝对中位差mad需符合如下公式:式中,mad——绝对中位差;——第i个数据中的x值;——样本平均值。
[0016]
通过标准差法进行异常值判断的步骤为:步骤一、计算出所有数值xi样本因子的平均值xmedian与标准差σ;步骤二、确定参数 n,从而确定数值xi样本因子的合理范围为 [xmedian
ꢀ–ꢀ
nmad,xmedian + nmad],并针对超出合理范围的数值xi样本因子做如下调整,超出最大值的用最大值代替,小于最小值的用最小值代替;步骤三、通过确认该平均值xmedian与标准差σ是否在范围[xmedian
ꢀ–ꢀ
nmad, xmedian + nmad],由此得出否或是的判断。
[0017]
上述步骤中,为了能将绝对中位差mad当作标准差σ 估计的一种一致估计量使用,可通过以下公式:式中,σ——标准差;k——比例因子常量,k值取决于分布类型,对于正态分布的数据,k值为:k=1/(φ^-1(3/4))≈1.4826,也就是标准正态分布z = x / σ 的分位函数的倒数(也称为逆累积分布函数)。数值3/4是为了
±ꢀ
mad \pm mad
±
mad包含标准正态累积分布函数的50%,即从1/4到3/4的范围值,这种形式可以用于概然误差的计算。
[0018]
标准差σ本身可以体现样本因子的离散程度,是基于样本因子的平均值 xmean而定的。在异常值处理过程中,可通过用 xmean
±
nσ来衡量样本因子与平均值的距离。而这种方式被称为标准差法的原因源于最经典的统计学3σ原则即正态分布的数分布在(μ-3σ,μ+3σ)中的概率为99.73%,在3σ外的概率是0.27%。其中μ代表平均值,σ是标准差,3σ去异常值法
其实就是把离平均值距离超过3倍标准差以上的值算作极端值。
[0019]
因此,这种结合了绝对中位差法和标准差法这两种判断方式的优化算法,它有效解决了现有单一算法中在去除异常值的同时容易出现误删正常数值的问题,也避免了各自算法上的不足,在不增加计算量的基础上,更好提升了算法的准确性和效率性。
[0020]
以上所述仅是本发明的具体实施例,本领域技术人员应该理解,任何与该实施例类似的结构设计,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1