一种TRIE和LOUDS结合的超集索引结构构建方法
一种trie和louds结合的超集索引结构构建方法
技术领域
1.本发明涉及一种trie和louds结合的超集索引结构构建方法,属于集合及字符串处理技术领域。
背景技术:
2.集合超集查询在决策支持系统、发布订阅系统、数据挖掘等众多领域应用广泛,如在发布订阅系统中,用户可以注册他们的关键词,系统可部署一个超集查询算法来对每个到来的对象执行超集查询,以获取订阅该对象的用户。在决策支持系统中,系统可以通过超集查询获取和某个求职者能力匹配的职位。
3.trie是最常见的高效超集查询结构,但其空间存储效率不高,存储大规模集合数据时,往往需要较大的存储空间。因此,需要对其进行压缩,而louds是已知的目前空间压缩效率最高的trie结构,可有效降低空间开销。故将trie和louds结合,对频繁访问的上层和存储空间开销高的下层分别用trie和louds表示,可使得构建的索引结构同时具有高的时间和空间效率。
技术实现要素:
4.本发明要解决的技术问题是提供一种trie和louds结合的超集索引结构构建方法,使得构建的索引结构同时具有高的时间和空间效率,从而解决上述问题。
5.本发明的技术方案是:一种trie和louds结合的超集索引结构构建方法,包括数据预处理阶段、索引结构构建阶段和超集查询阶段。数据预处理阶段将原始集合数据集中的集合和元素进行映射和排序。索引结构构建阶段构建上部为trie、下部为louds的混合索引结构。超集查询阶段则给定一个查询,在构建的混合索引结构上检索为给定查询的子集的所有集合。
6.具体步骤为:
7.step1:对初始集合数据集中的集合和元素进行映射和排序。
8.step2:构建trie和louds结合的索引结构。
9.step3:在构建的索引结构中执行超集查询。
10.所述step1具体为:
11.step1.1:统计数据集中各元素出现的频率,然后按频率降序将元素排列。
12.step1.2:将每个集合中的元素替换为其在频率降序中的下标,并将集合内的元素按值大小升序排序。
13.step1.3:将按元素值升序排序后的所有集合按照集合大小升序排序。
14.step1.4:对排序后的集合从0开始依次编号,记集合s的编号为s.id,记最终处理的数据集为d,|d|为数据集中集合的数量。
15.所述step1.3中的集合大小比较方法具体为:
16.step1.3.1:对特定的两个集合s和t,循环变量i从0到min(|s|,|t|)-1,循环执行
step1.3.2至step1.3.3,其中|s|和|t|分别表示s和t中的元素数量,min(|s|,|t|)表示|s|和|t|的最小值。
17.step1.3.2:若s[i]》t[i],则s》t。若s[i]《t[i],则s《t。否则表示s[i]=t[i],继续比较下一元素。其中s[i]和t[i]分别表示s和t的第i个元素。
[0018]
step1.3.3:若s和t的前min(|s|,|t|)个元素均相等,则继续判断|s|》|t|是否成立,如成立,则s》t,如|s|《|t|,则s《t,否则s=t。
[0019]
所述step2具体为:
[0020]
step2.1:为数据集中各集合的前d个元素构建trie索引,后文中d也称为分割深度。
[0021]
step2.2:为各集合的第d个元素之后的元素构建层级louds索引。
[0022]
step2.3:将层级louds结构合并为单层louds结构。在未加说明的情况下,本发明所指louds结构均指单层louds结构。
[0023]
所述step2.1具体为:
[0024]
step2.1.1:建立一个空的根节点root,令当前访问的节点current=root,记root的深度为0。
[0025]
step2.1.2:对每一个集合s∈d,循环执行step2.1.3至step2.1.6。
[0026]
step2.1.3:循环变量i从0到min(|s|-1,d-1),循环执行step2.1.4到step2.1.6。
[0027]
step2.1.4:若在current的孩子中查不到标签为s[i]的节点,则在current节点下添加一个标签为s[i]的孩子节点n,令current=n。若在current的孩子中已存在标签s[i]的节点n,则直接令current=n。
[0028]
step2.1.5:若i=|s|-1,则称n为终结点,即对应某个集合最后一个元素的节点,记n.esets为二元组《startid,count》,其中n.esets表示所有终结于节点n的全体集合,startid表示第一个和s完全相同的集合的id,count表示和s完全相同的集合数量。
[0029]
step2.1.6:若i=d-1,表明n为trie中最后一层的节点,若此时|s|》d,则称n为关节点,关节点是连接上层的trie和下层的louds的纽带。对关节点按其插入trie的顺序从0开始依次编号。
[0030]
step2.1.7:令c表示最终构建的trie中关节点的总数。
[0031]
所述step2.2具体为:
[0032]
step2.2.1:所述层级louds结构为每层构建1个整型数组elements、3个位数组notleaf、startofchild和endofset,还包括一个存储二元组《startid,count》的数组esets。
[0033]
step2.2.2:对当前插入的集合s,循环执行step2.2.3至step2.2.7。
[0034]
step2.2.3:循环变量i从d至|s|-1,循环执行step2.2.4至step2.2.7。
[0035]
step2.2.4:将s[i]插入到第i-d层的elements数组中,记s[i]插入到elements的位置为p。
[0036]
step2.2.5:若i!=|s|-1,将第i-d层的notleaf的位置p置为1。
[0037]
step2.2.6:若s[i]为其父节点的第一个孩子,则将第i-d层的startofchild的位置p置为1。
[0038]
step2.2.7:若i=|s|-1,则将第i-d层的endofset的第p位置为1,并构造二元组《
startid,count》插入到第i-d层的esets中,同trie节点的esets,startid表示第一个和s完全相同的集合的id,count表示和s完全相同的集合数量。
[0039]
所述step2.3具体为:
[0040]
step2.3.1:从层级louds的第0层开始,将各层的elements依次拼接构成最终的数组,为方便起见,在不引起歧义的情况下,将最终的数组仍称作elements。
[0041]
step2.3.2:按同样的方式拼接层级louds的notleaf、startofchild、endofset和esets等数组,构成最终单层louds的notleaf、startofchild、endofset和esets数组。
[0042]
step2.3.3:最终构成的单层elements、notleaf、startofchild、endofset和esets即为超集查询所用的单层louds结构。
[0043]
所述step3具体为:
[0044]
step3.1:给定一个查询的集合q,置i=0,当前节点current=root。
[0045]
step3.2:从current节点的孩子中依次检测q[j](i≤j≤|q|-1)是否存在,如果存在,记q[j]对应的节点为n。
[0046]
step3.3:若n.esets非空,将n.esets加入到结果集r中。
[0047]
step3.4:若n有孩子,则置current=n,i=j+1后,转step3.2,继续在trie中搜索;
[0048]
step3.5:若n为关节点,则获取关节点编号pno后转入louds中搜索。
[0049]
step3.6:在startofchild数组中获取第pno+1个1的位置p1和下一个为1的位置p2,若下一个为1不存在,则p2为数组的最大长度减1。
[0050]
step3.7:在elements数组的p1和p2-1位置之间,依次检测q[k](j+1≤k≤|q|-1)是否存在,存在则获取其在elements中的位置p。
[0051]
step3.8:若endofset[p]位置的值为1,则在endofset中统计从0到p之间(包含p)的1的个数c1,然后将esets[c1-1]对应的二元组插入到结果集r中。
[0052]
step3.9:若notleaf[p]位置的值为1,则在notleaf中统计从0到p之间(包含p)的1的个数c2,置pno=c2+c后,转step3.6,继续在louds中搜索。
[0053]
step3.10:查询结束,r中所存为最终超集查询的结果。
[0054]
本发明可充分利用trie的查询高效性及louds的高空间压缩性,可使得频繁被访问的上部有快的查询速度,而较少被访问的下部有高的压缩性能。
[0055]
本发明的有益效果是:本发明针对索引结构不同部分不同的需求,将查询效率高的trie和存储效率高的louds结合,具有如下优点:
[0056]
1、高的查询效率,多数超集查询在上层查询效率高的trie中进行。
[0057]
2、高的空间压缩率,大多数存储空间的开销集中在下层,通过louds高效压缩。
[0058]
3、上下两部分通过关节点来连接,从trie过渡到louds自然、便捷。
附图说明
[0059]
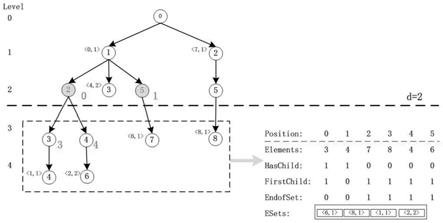
图1是本发明trie和louds混合结构示意图;
[0060]
图2是本发明层级louds示意图;
[0061]
图3是本发明查询时间对比图;
[0062]
图4是本发明索引空间对比图;
[0063]
图5本发明是查询和空间综合代价对比图。
[0096]
1 2 3 4
[0097]
1 2 4 6
[0098]
1 2 4 6
[0099]
1 3
[0100]
1 3
[0101]
1 5 7
[0102]2[0103]
2 5 8
[0104]
step1.4:对排序后的集合从0开始依次编号,记集合s的编号为s.id,记最终处理的数据集为d,|d|为数据集中集合的数量;
[0105]
本实施例中,对集合编号后得到的集合数据集d如下所示,集合前的第一个数字为集合id;
[0106]
0 1
[0107]
1 1 2 3 4
[0108]
2 1 2 4 6
[0109]
3 1 2 4 6
[0110]
4 1 3
[0111]
5 1 3
[0112]
6 1 5 7
[0113]
7 2
[0114]
8 2 5 8
[0115]
所述step1.3的集合大小比较方法具体为:
[0116]
step1.3.1:对特定的两个集合s和t,循环变量i从0到min(|s|,|t|)-1,循环执行step1.3.2至step1.3.3,其中|s|和|t|分别表示s和t中的元素数量,min(|s|,|t|)表示|s|和|t|的最小值;
[0117]
step1.3.2:若s[i]》t[i],则s》t;若s[i]《t[i],则s《t;否则表示s[i]=t[i],继续比较下一元素;其中s[i]和t[i]分别表示s和t的第i个元素;
[0118]
step1.3.3:若s和t的前min(|s|,|t|)个元素均相等,则继续判断|s|》|t|是否成立,如成立,则s》t,如|s|《|t|,则s《t,否则s=t;
[0119]
本实施例中,例如s={1,2,4,6},t={1,2,3,4},先比较第一个元素,因1和1相等,再比较第2个元素,2和2相等,继续比较第3个元素,因4大于3,故s》t;
[0120]
所述step2具体为:
[0121]
step2.1:为数据集中各集合的前d个元素构建trie索引,后文中d也称为分割深度;
[0122]
step2.2:为各集合的第d个元素之后的元素构建层级louds索引;
[0123]
step2.3:将层级louds结构合并为单层louds结构,在未加说明的情况下,本专利所指louds结构均指单层louds结构;
[0124]
本实施例中,假设d=2;
[0125]
所述step2.1具体为:
[0126]
step2.1.1:建立一个空的根节点root,令当前访问的节点current=root,记root的深度为0;
[0127]
step2.1.2:对每一个集合s∈d,循环执行step2.1.3至step2.1.6;
[0128]
step2.1.3:循环变量i从0到min(|s|-1,d-1),循环执行step2.1.4到step2.1.6;
[0129]
step2.1.4:若在current的孩子中查不到标签为s[i]的节点,则在current节点下添加一个标签为s[i]的孩子节点n,令current=n;若在current的孩子中已存在标签s[i]的节点n,则直接令current=n;
[0130]
step2.1.5:若i=|s|-1,则称n为终结点,即对应某个集合最后一个元素的节点,记n.esets为二元组《startid,count》,其中n.esets表示所有终结于节点n的全体集合,startid表示第一个和s完全相同的集合的id,count表示和s完全相同的集合数量;
[0131]
step2.1.6:若i=d-1,表明n为trie中最后一层的节点,若此时|s|》d,则称n为关节点,关节点是连接上层的trie和下层的louds的纽带;对关节点按其插入trie的顺序从0开始依次编号;
[0132]
本实施例中,初始时root为一个空节点,current=root;
[0133]
下面以前两个集合为例说明索引构建过程;
[0134]
对id为0的集合s={1},在i=0时,因在root的孩子中查不到标签为1的节点,故直接在根节点root下建立一个新的子节点n,并令current=n;
[0135]
因i=|s|-1=0,则n为终结点,设置n.esets=《0,1》,表示和s相同的集合起始id为0,数量为1;
[0136]
对id为0的集合s={1,2,3,4},i=0时,因root下找到标签为1的节点n,直接令current=n;
[0137]
因i≠|s|-1,则n不是终结点,i≠d-1,则n也不是关节点,置i=1后循环到step2.1.3继续执行;
[0138]
此时在current下找不到标签为2的节点n,则在current下添加一个标签为2的孩子节点n,令current=n;
[0139]
因i≠|s|-1,则n不是终结点,因i=d-1且|s|》d则n是关节点,转到louds中继续插入s的剩余元素3和4;
[0140]
step2.1.7:令c表示最终构建的trie中关节点的总数;
[0141]
本实施例中,最终创建的索引结构中包含c=2个关节点,编号分别为0和1,如图1所示,关节点表示背景为黄色的节点;
[0142]
所述step2.2具体为:
[0143]
step2.2.1:层级louds结构的核心在于为每层构建1个整型数组elements、3个位数组notleaf、startofchild和endofset,此外需要一个存储二元组《startid,count》的数组esets;
[0144]
step2.2.2:对当前插入的集合s,循环执行step2.2.3至step2.2.7;
[0145]
step2.2.3:循环变量i从d至|s|-1,循环执行step2.2.4至step2.2.7;
[0146]
step2.2.4:将s[i]插入到第i-d层的elements数组中,记s[i]插入到elements的位置为p;
[0147]
step2.2.5:若i!=|s|-1,将第i-d层的notleaf的位置p置为1;
[0148]
step2.2.6:若s[i]为其父节点的第一个孩子,则将第i-d层的startofchild的位置p置为1;
[0149]
step2.2.7:若i=|s|-1,则将第i-d层的endofset的第p位置为1,并构造二元组《startid,count》插入到第i-d层的esets中,同trie节点的esets,startid表示第一个和s完全相同的集合的id,count表示和s完全相同的集合数量;
[0150]
本实施例中,继续插入集合s的剩余元素3和4;
[0151]
当i=d=2时,将s[2]=3插入到第0层的elements数组中,得其在第0层的elements的位置为p=0;
[0152]
因i≠|s|-1,置第0层的notleaf[p]=1;
[0153]
因s[2]为前缀{1,2}的第一个孩子,故置第0层的startofchild[p]=1;
[0154]
当i=3时,将s[3]=4插入到第1层的elements数组中,得其在第1层的elements的位置为p=0;
[0155]
因s[3]为前缀{1,2,3}的第一个孩子,故置第1层的startofchild[p]=1;
[0156]
因i=|s|-1,则将第1层的endofset的第0位置为1,将二元组《1,1》插入到第1层的esets中;
[0157]
第2个集合插入完毕,依次类推,直至所有集合均索引完毕,最终层级louds结构各数组如图2所示,图中l0和l1分别对应层级louds的第0层和第1层;
[0158]
所述step2.3具体为:
[0159]
step2.3.1:从层级louds的第0层开始,将各层的elements依次拼接构成最终的数组,为方便起见,在不引起歧义的情况下,将最终的数组仍称作elements;
[0160]
step2.3.2:按同样的方式拼接层级louds的notleaf、startofchild、endofset和esets等数组,构成最终单层louds的notleaf、startofchild、endofset和esets数组;
[0161]
step2.3.3:最终构成的单层elements、notleaf、startofchild、endofset和esets即为超集查询所用的单层louds结构;
[0162]
本实施例中,将层级loud合并成单层louds后,最终构造的混合索引结构如图1所示,图中节点左边的二元组为该节点对应的esets,右边的数字为关节点的编号,下层向右的箭头表示将左侧虚线框内trie的下部替换为右侧的单层louds;
[0163]
所述step3具体为:
[0164]
step3.1:给定一个查询的集合q,置i=0,当前节点current=root;
[0165]
step3.2:从current节点的孩子中依次检测q[j](i≤j≤|q|-1)是否存在,如果存在,记q[j]对应的节点为n;
[0166]
step3.3:若n.esets非空,将n.esets加入到结果集r中;
[0167]
step3.4:若n有孩子,则置current=n,i=j+1后,转step3.2,继续在trie中搜索;
[0168]
step3.5:若n为关节点,则获取关节点编号pno后转入louds中搜索;
[0169]
step3.6:在startofchild数组中获取第pno+1个1的位置p1和下一个为1的位置p2,若下一个为1不存在,则p2为数组的最大长度减1;
[0170]
step3.7:在elements数组的p1和p2-1位置之间,依次检测q[k](j+1≤k≤|q|-1)是否存在,存在则获取其在elements中的位置p;
[0171]
step3.8:若endofset[p]位置的值为1,则在endofset中统计从0到p之间(含p)的1
的个数c1,然后将esets[c1-1]对应的二元组插入到结果集r中;
[0172]
step3.9:若notleaf[p]位置的值为1,则在notleaf中统计从0到p之间(含p)的1的个数c2,置pno=c2+c后,转step3.6,继续在louds中搜索;
[0173]
step3.10:查询结束,r中所存为最终超集查询的结果。
[0174]
本实施例中,给定一个查询集合q={1,2,4,6},初始时i=0,当前节点current=root;
[0175]
对j从i到2,从root分别检索元素q[j],得到元素1(对应j=0)和2(对应j=1)在根节点的孩子中;
[0176]
对root的标签为1的孩子n,因n.esets非空,故其对应的esets《0,1》加入到结果集r中;
[0177]
因n有孩子,置current=n后,转step3.2,继续检测得到第二层标签为2和3的孩子存在于current的孩子中;
[0178]
对第二层标签为2的孩子n,因n.esets为空且为关节点,则获取其关节点编号pno=0后转入到louds中继续查找;
[0179]
在louds的startofchild数组中获取第pno+1=1个1的位置p1=0和第pno+2=2个1的位置,得p2=2;
[0180]
然后在elements的p1和p2-1之间,即位置0和1之间,查找q[2]和q[3]是否存在,得到q[2]=4存在,其在elements中的位置p=1;
[0181]
因notleaf[p]为1,则在notleaf中统计从0到p之间统计1的个数为c2=2,则置pno=c2+c=2+2=4后,转step3.6,继续在louds中搜索;
[0182]
在louds的startofchild数组中获取第pno+1=5个1的位置p1=0,因第6个1不存在,p2置为数组的最大长度减1,即5;
[0183]
然后在elements的p1和p2-1之间,即位置5和5之间,查找得到q[3]=6存在,其在elements中的位置p=5;
[0184]
因endofset[p]位置的值为1,则在endofset中统计从0到p之间(含p)的1的个数c1=4,然后将esets[c1-1]=《2,2》对应的二元组插入到结果集r中;
[0185]
对root的标签为2的孩子n,因n.esets非空,故其对应的esets《7,1》加入到结果集r中;
[0186]
因n有孩子,置current=n后,转step3.2,继续检测得到第二层标签为4和6的孩子均不存在于current的孩子中;
[0187]
查询结束,最终得查询结果为r={《0,1》,《2,2》,《7,1》},即q是集合0、2、3和7的超集。
[0188]
本发明可通过以下实验结果进一步说明。
[0189]
实验环境:cpu为intel i7
–
7700cpu@3.60ghz,内存为16gb,操作系统为ubuntu 18.0464-bit,编译环境为code blocks 16.01,gcc 7.5.0。
[0190]
实验数据:本发明采用的数据集为dblp数据集,该数据集包含781514条集合数据,每一个集合数据包含作者和标题信息,集合中独立元素数量为517326,集合最大长度为219,最小长度为3,平均长度为14。从数据集中随机抽取5000个集合作为查询。查询时间、索引存储空间及时间空间综合代价分别如图3、图4和图5所示,其中时间空间综合代价为对查
询时间和存储空间分别进行归一化(分别除以最大查询时间和最大存储空间)后得到的查询代价和存储代价之和。每个图左右两端的数据点分别代表louds(完全louds结构,对应分割深度为0)和trie(完全trie,对应分割深度为无穷大)对应的实验结果。
[0191]
实验结果分析:
[0192]
从实验可见,查询时间随着分割深度的增大逐步降低,而存储空间的开销则随着分割深度的增大逐步增加。trie对应最大存储空间的情形,而louds对应最大查询时间的情形。时间和空间综合代价则约在分割深度为4时达到最优,从而表明本发明将trie和louds结合的优势所在。
[0193]
以上结合附图对本发明的具体实施方式作了详细说明,但是本发明并不限于上述实施方式,在本领域普通技术人员所具备的知识范围内,还可以在不脱离本发明宗旨的前提下作出各种变化。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1