基于深度强化学习的安卓恶意软件检测特征提取方法
1.本发明涉及软件与信息系统安全技术领域,确切地说涉及一种基于深度强化学习的安卓恶意软件检测特征提取方法。
背景技术:
2.随着新一代网络信息技术的不断发展,越来越多的人开始使用互联网,互联网开始影响着生活的方方面面,然而,互联网的发展也加速了恶意软件的传播,恶意软件是指实现了攻击者恶意目的的软件,经常通过互联网传播,是存在损害用户利益的行为是判定软件是否为恶意软件的依据。
3.而随智能手机的不断发展,越来越多的人选择使用智能手机,搭载安卓系统的智能手机始终占据了市场的很大份额,安卓系统的恶意软件能够求取用户隐私信息、获取用户利益、远程控制达到非法个人目的。自2013年以来,安卓操作系统一直占据着移动操作系统市场的统治地位,这个平台的开源性和开放性是的安卓平台成为恶意软件攻击的热门目标。根据trend force最新发布数据,2020年智能手机的总产量为12.5亿部,android占据了78.4%的市场份额。然而,由于广泛分布和开源特性,除了官方android market之外,android应用程序还可以从未知、不受信任和潜在恶意的第三方下载和安装,这使得该平台成为恶意软件攻击的目标。根据360安全于2020年2月28日发布的2019年android恶意软件专项报告显示,2019年该平台在移动端拦截新恶意软件样本约180.9万个,平均每天拦截约5000个新移动恶意软件样本,因此,对于恶意安卓软件的分析研究刻不容缓。
4.现有技术中,机器学习等人工智能方法在恶意安卓软件检测中的应用,解决了传统基于签名的检测技术不能识别未知恶意软件的缺点,减小了恶意软件签名库的更新和维护成本,但安卓系统反编译后提取的静态特征数量庞大,机器学习分类器训练和检测时计算开销大、效率和准确率低下。因此,在将特征集合输入机器学习分类器前,需要利用有效的最优特征子集选择方法进行数据降维,以提高恶意安卓软件检测的效率。
5.在安卓最优特征子集选择中,根据选择指标是否独立于分类器的准确度,特征算法可以分为包装类(wrapper-based)、过滤类(filter-based)两种方法。对于基于过滤类的特征提取方法(如information gain,relief f等),选择指标与分类器的准确率结果无关,而在基于包装类的算法中(如ffsr,wrapper subset eval等),直接使用分类器的精度来评估生成的特征子集并改善选择方法。但是,基于包装类的特征提取方法计算开销大,在数据集庞大时效率低下,但基于过滤类的特征提取方法忽略了分类器反馈的不同特征之间的相关性,从而在处理高维特征向量时可能选择出大量冗余特征。
6.为了在恶意安卓软件检测效率上取得突破,需要有一种新方法利用包装类特征提取方法通过分类器准确率反馈来改善选择方式的特点,同时解决该特征提取方法存在的难以探索有效特征子集组合的问题。
技术实现要素:
7.本发明目的在于针对上述问题,提供一种基于强化学习的特征提取方法、通过除去冗余和无关特征实现数据降维,从而降低机器学习检测器的计算开销、提高恶意安卓软件检测效率的安卓恶意软件检测特征提取方法。
8.本发明提供的这一种基于深度强化学习的安卓恶意软件检测特征提取方法,包括样本获取步骤、深度强化学习模型构建步骤以及模型训练步骤;
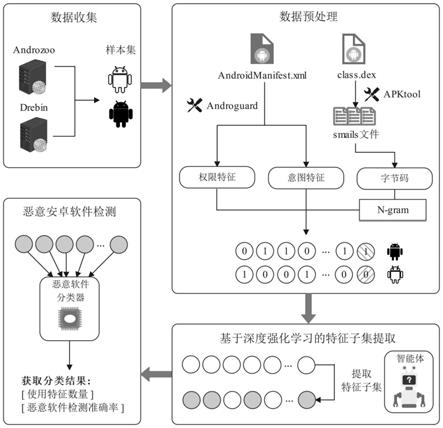
9.所述样本获取步骤,从android平台的androzoo以及drebin数据集中获取若干不同的良性和恶意的apk样本,并通过所述apk样本进行对特征提取和特征向量化处理得到样本集合;
10.进一步的,所述样本获取步骤中,获取apk样本后还需对其进行数据清洗,具体的,是通过androguard工具对所述apk样本进行解析,同时通过apk tool工具对所述apk样本进行反汇编,删除解析失败和反汇编失败的样本。
11.优选地,所述样本获取步骤中,所述特征提取,是通过android manifest.xml文件提取出经过数据清洗后的apk样本的457个重要权限特征和126个意图特征,同时根据反汇编生成的smail格式文件语法特征,将apk样本中method字段基本块所包含的dalvik字节码指令按照设定的转换规则进行转换,然后使用n-gram技术获取样本的n-gram特征集合,含500个n-gram特征。原始特征集合共1083个特征。
12.更为具体的,所述样本获取步骤中,特征向量化处理,是将所述apk样本采用二进制特征向量进行表示,向量中“1”表示权限特征、意图特征或n-gram特征在apk文件中存在,“0”则表示apk文件中不存在权限特征、意图特征和/或n-gram特征。
13.所述深度强化学习模型构建步骤,选择double deep q-learning算法作为深度强化学习模型,选定基于机器学习算法的、用于检测恶意安卓软件的分类器模型,并定义所述深度强化学习模型的学习动作空间与状态空间,设定奖励机制,并初始化所述深度强化学习模型以及其决策网络的超参数;
14.优选地,所述double deep q-learning算法包含两个结构一致、激活函数均使用relu激活函数的前馈深度q网络,分别为当前主网络和目标网络,其中,当前主网络用于训练学习、目标网络用于输出选择动作的q值引导智能体做出决策。
15.进一步的,所述强化学习模型构建步骤中,定义所述深度强化学习模型的学习动作空间与状态空间,深度强化学习模型的行动主要是从安卓原始特征集中选择一个新的特征加入到自身的状态中,具体的:
16.设定在探索模式下,所述深度强化学习模型智能体从样本集合中随机选择一个尚未被选择的特征加入到自身的状态中;
17.设定在利用模式下,所述深度强化学习模型智能体的选择由决策网络引导执行,决策网络结合先验阈值经验和深度强化学习模型的当前状态,从样本集合中选择一个尚未被选择过的、最优的特征加入到自身的状态中;
18.且设定深度强化学习模型每次选择有ε的概率处于探索模式下,有1-ε的概率处于利用模式,其中式中,n是当前训练的轮次,m是设定的总训练轮次,p是一个设定的需要调整的上限。
19.更为优选地,在本技术方案中,所述深度强化学习模型的决策网络为长短期记忆网络,决策网络的输入是深度强化学习模型的状态,输出是一个用于表示每个特征置信度的向量。
20.更为具体的,在本技术方案中,所述深度强化学习模型的决策网络有两个,一个为当前主网络,另一个为目标网络,在经过设定的训练轮次后,当前主网络的参数值将被同步到目标网络中。
21.且在所述强化学习模型构建步骤中,设定奖励机制,具体的,是对深度强化学习模型选择的特征进行恶意软件分类的准确率评价,通过学习环境定义设置深度强化学习模型在探索模式下进行选择的特征总集合,并对深度强化学习模型每次的选择结果进行评估,是将深度强化学习模型在其当前所处的模式下执行选择动作,并返回深度强化学习模型的下一个所处模式,如图2所示。所述分类器模型根据深度强化学习模型的当前模式和本次模式下的选择动作、将深度强化学习模型的检测准确率作为指标返回作为其本次选择动作的奖励,在奖励机制中,为了让智能体能够更好地学到最优特征选择知识,对奖励机制做如下设定:将深度强化学习模型当前所处模式下已选择的特征和进行选择的方式输入到所述分类器模型中,分类器模型利用深度强化学习模型当前选择的特征对样本集合中的样本进行分类,将输出的分类结果准确率作为当前动作的奖励值,并把状态值和输入的状态、动作作为一次经验加入深度强化学习模型的经验回放池中。
22.优选地,所述超参数的初始化,具体的,决策网络的超参数设置为:
23.折扣系数gamma=0.99;
24.q-learning网络的更新间隔为2500步更新一次;
25.单次输入网络的最小样本数量为32个;
26.采用经验回放机制,经验回放池的大小为200,000;
27.开始采用经验回放机制的时机为算法执行了50,000步以后;
28.网络隐藏层神经元个数为256个;
29.所述模型训练步骤,启动所述深度强化学习模型进行学习训练,训练过程中损失深度强化学习模型按照设定数量从其经验回放池中选取学习经验更新其决策网络,当深度强化学习模型观测到在探索模式下和利用模式下选择的特征达到设定数量后结束当前轮次的训练,然后根据设定的训练轮次循环对深度强化学习模型进行学习训练,完成全部轮次的训练后,将识别准确率最高的特征子集作为最终选取的最优特征子集。
30.与现有技术相比,本发明这种技术方案基于强化学习模型能够可以利用已有探索经验快速寻找下一个合适特征的特点,结合了包装类特征提取方法根据分类器准确率进行选择改善的特点、快速寻找最优特征子集的优势,创造性的提出了这种能够快速、高效、准确的识别出安卓系统恶意软件的智能识别方法。采用机器学习模型和高级自学习网络的融合实现自动化智能化的检测,避免了人工特征选择对安卓特征语义的破坏,通过强化学习自动地筛选出对安卓恶意软件检测最有效的特征集合,过滤无关和冗余特征,在保证准确率的同时实现减小计算开销和计算时间。
31.本发明的方法通过强化学习的“探索-利用”策略解决了传统的包装类方法在特征维数巨大时计算时间过长的问题,克服了基于过滤类的特征选择不考虑分类反馈而忽视特征间关联程度的缺陷;使用循环神经网络作为决策网络来处理变长的特征序列数据,具有
可借鉴性,且可以广泛应用于机器学习特征集合数据预数理问题,将数据集更换为其他软件样本中提取的特征,即可应用于不同平台的恶意软件检测。
32.综合而言,本发明方法与其他安卓恶意软件检测特征提取方法相比,充分利用了分类器准确率来改善下一步的特征选择策略,考虑了特征之间的相关性影响;同时又结合强化学习的“利用-探索”策略解决了传统wrapper-based方法在数据集过大时的时间开销问题;最终在保证较高检测准确率的情况下,提升了安卓恶意软件分类器的检测效率。
附图说明
33.本发明的前述和下文具体描述在结合以下附图阅读时变得更清楚,其中:
34.图1是本发明安卓恶意软件检测的总流程示意图;
35.图2是本发明深度强化学习进行软件特征提取的示意图;
36.图3是本发明深度强化学习模型决策网络结构示意图;
37.图4是本发明决策网络和分类器模型检测效果示意图。
具体实施方式
38.下面通过具体的实施例来进一步说明实现本发明目的技术方案,需要说明的是,本发明要求保护的技术方案包括但不限于以下实施例。
39.实施例1
40.作为本发明一种最基本的实施方案,如图1所示,本实施例提供的这一种基于深度强化学习的安卓恶意软件检测特征提取方法,包括样本获取步骤、深度强化学习模型构建步骤以及模型训练步骤,具体设计中充分利用了分类器准确率来改善下一步的特征选择策略,考虑了特征之间的相关性影响;同时又结合强化学习的“利用-探索”策略解决了传统wrapper-based方法在数据集过大时的时间开销问题;最终在保证较高检测准确率的情况下,提升了安卓恶意软件分类器的检测效率。
41.具体的,所述样本获取步骤,是从android平台的androzoo以及drebin数据集中获取若干不同的良性和恶意的apk样本,并通过所述apk样本进行对特征提取和特征向量化处理得到样本集合,样本集合中将良性的和恶意的安卓软件进行特征量化的处理,为后续的自动化识别提供了标准,同时也兼顾了机器学习的特性,提高了学习效率和效果。
42.所述深度强化学习模型构建步骤,选择double deep q-learning算法作为深度强化学习模型,选定基于机器学习算法的、用于检测恶意安卓软件的分类器模型,分类器模型用于根据深度强化模型学习训练过程中的选择结果对样本进行分类,从而根据分类情况直观的评价模型的选择结果准确率,以便后续的调优;定义所述深度强化学习模型的学习动作空间与状态空间,即模型在设定的状态下进行指定方式的选择和处理动作,固定动作模式以便学习训练,设定奖励机制作为本次特征选择动作的反馈,并初始化所述深度强化学习模型以及其决策网络的超参数;double deep q-learning算法使用两个网络计算q-learning的值函数并对其收敛过程进行了证明,在兼顾q-learning算法最大的累计期望奖励的目标前提下克服了q-learning算法由于受到大规模的动作值过估计而出现不稳定和效果不佳等现象。
43.模型训练步骤,启动所述深度强化学习模型进行学习训练,训练过程中损失深度
强化学习模型按照设定数量从其经验回放池中选取学习经验更新其决策网络,当深度强化学习模型观测到在探索模式下和利用模式下选择的特征达到设定数量后结束当前轮次的训练,然后根据设定的训练轮次循环对深度强化学习模型进行学习训练,完成全部轮次的训练后,将识别准确率最高的特征子集作为最终选取的最优特征子集,即得到最佳的识别结果。
44.这种技术方案基于强化学习模型能够可以利用已有探索经验快速寻找下一个合适特征的特点,结合了包装类特征提取方法根据分类器准确率进行选择改善的特点、快速寻找最优特征子集的优势,创造性的提出了这种能够快速、高效、准确的识别出安卓系统恶意软件的智能识别方法。
45.并且采用机器学习模型和高级自学习网络的融合实现自动化智能化的检测,避免了人工特征选择对安卓特征语义的破坏,通过强化学习自动地筛选出对安卓恶意软件检测最有效的特征集合,过滤无关和冗余特征,在保证准确率的同时实现减小计算开销和计算时间。
46.实施例2
47.作为本发明一种最基本的实施方案,如图1所示,本实施例提供的这一种基于深度强化学习的安卓恶意软件检测特征提取方法,包括样本获取步骤、深度强化学习模型构建步骤以及模型训练步骤,具体设计中充分利用了分类器准确率来改善下一步的特征选择策略,考虑了特征之间的相关性影响;同时又结合强化学习的“利用-探索”策略解决了传统wrapper-based方法在数据集过大时的时间开销问题;最终在保证较高检测准确率的情况下,提升了安卓恶意软件分类器的检测效率。
48.具体的,所述样本获取步骤,是从android平台的androzoo以及drebin数据集中获取若干不同的良性和恶意的apk样本,并对apk样本进行数据清洗,具体的,是通过androguard工具对所述apk样本进行解析,同时通过apktool工具对所述apk样本进行反汇编,删除解析失败和反汇编失败的样本。
49.apk样本清洗完成后,需对apk样本进行特征提取,具体的,是通过androidmanifest.xml文件提取出经过数据清洗后的apk样本的457个重要权限特征和126个意图特征,同时根据反汇编生成的smail格式文件语法特征,将apk样本中method字段基本块所包含的dalvik字节码指令按照设定的转换规则进行转换,然后使用n-gram技术获取样本的n-gram特征集合,含500个n-gram特征。原始特征集合共1083个特征。
50.提取得到特征后还需进行特征向量化处理,具体的,是将所述apk样本采用二进制特征向量进行表示,向量中“1”表示权限特征、意图特征和/或n-gram特征在apk文件中存在,“0”则表示apk文件中不存在权限特征、意图特征和/或n-gram特。例如,所述特征提取时提取了457个权限特征、126个意图特征以及在恶意样本中出现频率高500个n-gram特征,特征总集合共计1083个特征,使用二进制特征向量表示对应的apk样本,向量中“1”表示该特征在apk文件中存在,“0”则表示不存在。
51.接下来,所述深度强化学习模型构建步骤,是选择double deep q-learning算法作为深度强化学习模型,并且所述double deep q-learning算法包含两个结构一致、激活函数均使用relu激活函数的前馈深度q网络,分别为当前主网络和目标网络,其中,当前主网络用于训练学习、目标网络用于输出选择动作的q值引导智能体做出决策。
52.然后需要选定基于机器学习算法的、用于检测恶意安卓软件的分类器模型,分类器模型用于根据深度强化模型学习训练过程中的选择结果对样本进行分类,从而根据分类情况直观的评价模型的选择结果准确率,接着需定义所述深度强化学习模型的学习动作空间与状态空间,深度强化学习模型的行动主要是从安卓原始特征集中选择一个新的特征加入到自身的状态中,具体的:
53.设定在探索模式下,所述深度强化学习模型从样本集合中随机选择一个尚未被选择的特征加入到自身的状态中;
54.设定在利用模式下,所述深度强化学习模型的决策网络结合先验阈值经验和深度强化学习模型的当前状态,从样本集合中选择一个尚未被选择过的、最优的特征加入到自身的状态中;
55.且设定深度强化学习模型每次选择有ε的概率处于探索模式下,有1-ε的概率处于利用模式,其中式中,n是当前训练的轮次,m是设定的总训练轮次,p是一个设定的需要调整的上限。
56.并且优选地,在本技术方案中,所述深度强化学习模型的决策网络为长短期记忆网络,如图3所示,决策网络的输入是深度强化学习模型的状态,输出是一个用于表示每个特征置信度的向量。
57.更为优选地,在本技术方案中,所述深度强化学习模型的决策网络有两个,一个为当前主网络,另一个为目标网络,在经过设定的训练轮次后,当前主网络的参数值将被同步到目标网络中。
58.还需设定奖励机制,而所述奖励由当前选择特征输入分类器的准确率确定,具体的如图2所示,是对深度强化学习模型选择的特征进行恶意软件分类的准确率评价,通过学习环境定义设置深度强化学习模型在探索模式下进行选择的特征总集合,并对深度强化学习模型每次的选择结果进行评估,是将深度强化学习模型在其当前所处的模式下执行选择动作,并返回深度强化学习模型中代理人的下一个状态。所述分类器模型根据深度强化学习模型的当前模式和本次模式下的选择动作、将深度强化学习模型的检测准确率作为指标返回作为其本次选择动作的奖励,在奖励机制中,为了让智能体能够更好地学到最优特征选择知识,对奖励机制做如下设定:将深度强化学习模型当前所处模式下已选择的特征和进行选择的方式输入到所述分类器模型中,分类器模型利用深度强化学习模型当前选择的特征对样本集合中的样本进行分类,将输出的分类结果准确率作为当前动作的奖励值,并把状态值和输入的状态、动作作为一次经验加入深度强化学习模型的经验回放池中。
59.完成上述设置后,初始化所述深度强化学习模型以及其决策网络的超参数,将决策网络的超参数初始化为:
60.折扣系数gamma=0.99;
61.q-learning网络的更新间隔为2500步更新一次;
62.单次输入网络的最小样本数量为32个;
63.采用经验回放机制,经验回放池的大小为200,000;
64.开始采用经验回放机制的时机为算法执行了50,000步以后;
65.网络隐藏层神经元个数为256个;
66.最后,所述模型训练步骤,启动所述深度强化学习模型进行学习训练,训练过程中损失深度强化学习模型按照设定数量从其经验回放池中选取学习经验更新其决策网络,当深度强化学习模型观测到在探索模式下和利用模式下选择的特征达到设定数量后结束当前轮次的训练,然后根据设定的训练轮次循环对深度强化学习模型进行学习训练,完成全部轮次的训练后,将识别准确率最高的特征子集作为最终选取的最优特征子集,这里以lstm(long short-term memory)为决策网络,以dt为分类器模型,模型训练完成后检测效果如图4所示,其中横坐标为选择特征数量,纵坐标为准确率,顶部虚线为选择全部特征的准确率,可以看出,采用本方法的识别准确率较高且状态稳定,从含有1083个特征的原始特征总集合中提取6-24个特征用于恶意安卓软件检测准确率均保持在0.90以上,在提取24个特征时达到了最高准确率0.955,对比使用所有特征输入检测,在降低了大量计算开销的情况下保留了较高的准确率。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1