一种基于机器学习的岩性识别方法与流程
1.本发明属于岩性识别技术领域,具体涉及一种基于机器学习的岩性识别方法。
背景技术:
2.岩性是指岩石颜色、成分、结构、构造等特征的总和,岩性识别是指通过一些特定的方法来认识和区别岩性的过程,如何刻画、认识地下岩性分布历来都是地质学中的重要问题。尤其是在矿山爆破工程中,需要对岩石性质进行识别,避免发生安全事故。
3.爆破岩层岩性识别,目前有实验室方法、现场测试方法,还有一部分是利用微测井方法测出地震波反演获得岩性数据,使用的人工智能算法需要大量的样本支撑学习,且对关键核心参数未做优化处理,出现识别精度不高、样本数据缺乏的问题,并且上述方法步骤复杂,工作量大,并且硬件成本投入大,导致在实际工程中实用性低。
技术实现要素:
4.为了解决现有技术存在的识别精度不高,样本数据缺乏,步骤复杂,工作量大,硬件成本投入大以及实用性低问题,本发明目的在于提供一种基于机器学习的岩性识别方法。
5.本发明所采用的技术方案为:
6.一种基于机器学习的岩性识别方法,包括如下步骤:
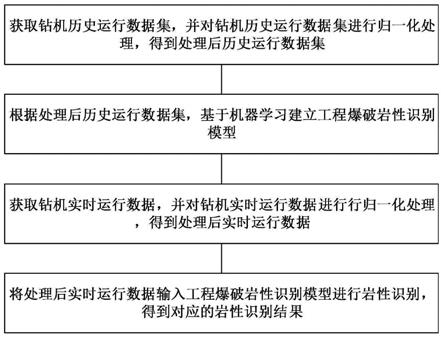
7.获取钻机历史运行数据集,并对钻机历史运行数据集进行归一化处理,得到处理后历史运行数据集;
8.根据处理后历史运行数据集,基于机器学习建立工程爆破岩性识别模型;
9.获取钻机实时运行数据,并对钻机实时运行数据进行行归一化处理,得到处理后实时运行数据;
10.将处理后实时运行数据输入工程爆破岩性识别模型进行岩性识别,得到对应的岩性识别结果。
11.进一步地,钻机的运行数据包括钻进速度、回转速度、风压、加压压力以及回转压力差。
12.进一步地,归一化处理的公式为:
13.y=a+q(x-x
min
)
14.式中,y为归一化处理后的数据;a为归一化区间下限值;x为归一化处理前的数据;x
min
为样本数据中的最小值;q为归一化系数。
15.进一步地,根据处理后历史运行数据集,基于机器学习建立工程爆破岩性识别模型,包括如下步骤:
16.将处理后历史运行数据集分为训练数据集和测试数据集;
17.将训练数据集输入ssa算法优化svr模型进行训练,得到初始的工程爆破岩性识别模型;
18.将测试数据集输入初始的工程爆破岩性识别模型进行优化,得到最优的工程爆破岩性识别模型。
19.进一步地,ssa算法优化svr模型,包括如下步骤:
20.初始化ssa算法的种群参数,得到初始化种群;
21.根据初始化种群,获取ssa算法的最优适应度函数值;
22.基于最优适应度函数值的ssa算法进行训练,得到svr模型的最优惩罚系数和最优高斯核函数宽度;
23.将训练数据集输入设置有最优惩罚系数和最优高斯核函数宽度的svr模型进行训练,得到初始的工程爆破岩性识别模型。
24.进一步地,初始化ssa算法的种群参数,包括如下步骤:
25.设定搜索空间;
26.确定搜索空间食物和麻雀位置;
27.确定搜索空间上、下限;
28.根据搜索空间、搜索空间食物、麻雀位置以及搜索空间上下限,得到初始化种群。
29.进一步地,初始化种群的公式为:
30.xn×d=rand(n
×
d)
×
(ub-lb)+lb
31.式中,xn×d为初始化种群的位子;rand(*)为随机函数;n
×
d为搜索空间范围;n为种群规模;d为优化问题的维度;ub、lb分别为搜索空间上、下限。
32.进一步地,获取ssa算法的最优适应度函数值,包括如下步骤:
33.根据适应度对当前种群进行排序,得到初始的发现者、加入者以及捕食者及其对应的位置信息;
34.更新发现者、加入者以及捕食者的位置信息及其对应的适应度;
35.若当前迭代次数大于次数阈值,则将当前的最佳适应度作为最优适应度函数值进行输出并结果当前获取方法,否则返回上一步骤。
36.进一步地,工程爆破岩性识别模型的公式为:
[0037][0038]
式中,f(x)为工程爆破岩性识别模型输出值;k(xi,xj)为高斯函数;xi,xj分别为第i,j个特征值;为分别位于边界下、边界上的拉格朗日系数;b为偏置值;i为样本指示量;n为特征维度总数。
[0039]
本发明的有益效果为:
[0040]
本发明提供一种基于机器学习的岩性识别方法,根据钻机参数和人工智能方法相结合实时获取钻进过程中岩性参数,简化了识别步骤,减少了工作量,并且无需其它昂贵的硬件设备,降低了成本投入,并且机器学习的算法不仅提高了识别效率,也提高了识别的准确率,实现精细化钻孔装药、精细化爆破,还可以将岩性识别结果反馈给钻机,实现高效作业。
[0041]
本发明的其他有益效果将在具体实施方式中进一步进行说明。
附图说明
[0042]
图1是本发明中基于机器学习的岩性识别方法的方法流程图。
具体实施方式
[0043]
下面结合附图及具体实施例对本发明做进一步阐释。
[0044]
实施例1:
[0045]
如图1所示,本实施例提供一种基于机器学习的岩性识别方法,包括如下步骤:
[0046]
获取钻机历史运行数据集,并对钻机历史运行数据集进行归一化处理,得到处理后历史运行数据集;
[0047]
钻机的运行数据包括钻进速度、回转速度、风压、加压压力以及回转压力差,如表1的钻机历史运行数据表所示:
[0048]
表1
[0049][0050]
归一化处理的公式为:
[0051]
y=a+q(x-x
min
)
[0052]
式中,y为归一化处理后的数据;a为归一化区间下限值;x为归一化处理前的数据;x
min
为样本数据中的最小值;q为归一化系数;
[0053]
归一化系数的公式为:
[0054]
q=(b-a)/(x
max-x
min
)
[0055]
式中,q为归一化系数;b、a分别为归一化区间上、下限值;x
max
、x
min
分别为样本数据中的最大、小值;
[0056]
根据处理后历史运行数据集,基于机器学习建立工程爆破岩性识别模型,包括如下步骤:
[0057]
将处理后历史运行数据集分为训练数据集和测试数据集;
[0058]
麻雀搜索算法ssa是一种基于觅食和反捕食行为的群智能优化算法,在麻雀觅食过程中,发现者为整个种群提供觅食区域和方向,加入者根据发现者提供的信息来获取食物,在反捕食过程中,当侦察者意识到有危险,会及时发出警报,整个种群会做出反捕食行为,在寻找最优方面,ssa算法比大部分人工智能算法具有更好的性能,提高了识别准确率;
[0059]
支持向量回归模型svr是在线性函数两侧制造了一个“间隔带”,间距为容忍偏差,对所有落入到间隔带内的样本不计算损失,也就是只有支持向量才会对其函数模型产生影响,最后通过总损失最小化和最大化间隔来得出优化后的模型,svr模型适合解决小样本问题,解决了训练数据样本缺乏的问题;
[0060]
将训练数据集输入ssa算法优化svr模型进行训练,得到初始的工程爆破岩性识别模型ssa算法优化svr模型,包括如下步骤:
[0061]
初始化ssa算法的种群参数,得到初始化种群,包括如下步骤:
[0062]
设定搜索空间为n
×
d维度,本实施例中采用81
×
6维;
[0063]
确定搜索空间食物为f=[f1,f2,...,fd]
t
和麻雀位置为x=[x
h1
,x
h2
,...,x
hd
]
t
;
[0064]
确定搜索空间上限为ub=[ub1,ub2,...,ubd]
t
,下限为lb=[lb1,lb2,...,lbd]
t
;
[0065]
根据搜索空间、搜索空间食物、麻雀位置以及搜索空间上下限,得到初始化种群;
[0066]
初始化种群的公式为:
[0067]
xn×d=rand(n
×
d)
×
(ub-lb)+lb
[0068]
式中,xn×d为初始化种群的位子;rand(*)为随机函数;n
×
d为搜索空间范围;n为种群规模;d为优化问题的维度;ub、lb分别为搜索空间上、下限;
[0069]
根据初始化种群,获取ssa算法的最优适应度函数值,包括如下步骤:
[0070]
根据适应度对当前种群进行排序,得到初始的发现者、加入者以及捕食者及其对应的位置信息;
[0071]
更新发现者、加入者以及捕食者的位置信息及其对应的适应度;
[0072]
发现者的更新公式为:
[0073][0074]
式中,分别为第t+1、t次迭代的第c个发现者麻雀位置;iter
max
为最大迭代次数阈值;ξ为0到1之间的随机数;q为正态分布随机数;l为1
×
d的矩阵,其元素全为1;r2为警戒值;st为安全阈值;
[0075]
加入者的更新公式为:
[0076][0077]
式中,分别为第t+1、t次迭代的第c个加入者麻雀位置;为暴露身份者占据的最佳位置;为当前最差位置;iter
max
为最大迭代次数阈值;ξ为0到1之间的随机数;l为1
×
d的矩阵,其元素全为1或者-1;c为麻雀指示量;h为麻雀总数;
[0078]
捕食者的更新公式为:
[0079][0080]
式中,分别为第t+1、t次迭代的第c个捕食者麻雀位置;δ为步长控制参数;k为0到1之间的随机数;为当前最佳位置;fc、fg、fw分别为麻雀的当前、最佳以及最差适应度;γ为最小常数,防止分母为0;
[0081]
若当前迭代次数大于次数阈值,本实施例中次数阈值为1000,则将当前的最佳适应度fg作为最优适应度函数值进行输出并结果当前获取方法,否则返回上一步骤;
[0082]
基于最优适应度函数值的ssa算法进行训练,得到svr模型的最优惩罚系数和最优高斯核函数宽度;
[0083]
原始的svr模型的公式为:
[0084][0085]
式中,f*(x)为原始的svr模型输出值;ω为权值向量;为非线性映射函数;b为偏置值;
[0086]
代价函数的公式为:
[0087][0088][0089]
式中,j为代价函数;c为惩罚系数;ζ
i+
、ζ
i-均为松弛系数;ε为最大误差系数;i为样本指示量;n为特征维度总数;xi为样本数据的特征值;yi为样本数据的真实值;
[0090]
将训练数据集输入设置有最优惩罚系数和最优高斯核函数宽度的svr模型进行训练,得到初始的工程爆破岩性识别模型;
[0091]
基于钻机参数,在小样本条件下,突破现有识别方法缺陷,通过ssa优化svr模型建立的工程爆破岩性识别模型,能够很好地预测岩层岩性,不仅能够提高预测精度、降低所需样本成本,而且能够做到在钻机钻进过程中实时反演岩性数据,践行精细爆破理念;
[0092]
优化后的权值向量的公式为:
[0093][0094]
式中,ω'为化后的权值向量;为分别位于边界下、边界上的拉格朗日系数;
[0095]
将测试数据集输入初始的工程爆破岩性识别模型进行优化,得到最优的工程爆破岩性识别模型;
[0096]
工程爆破岩性识别模型的公式为:
[0097][0098]
式中,f(x)为工程爆破岩性识别模型输出值;k(xi,xj)为高斯函数;xi,xj分别为第i,j个特征向值;为分别位于边界下、边界上的拉格朗日系数;b为偏置值;i为样本指示量;n为特征维度总数;
[0099]
高斯函数的公式为:
[0100]
k(xi,xj)=exp(-||x
i-xj||2/2g2)
[0101]
式中,k(xi,xj)为高斯函数;xi,xj分别为第i,j个特征向量;g为最优高斯核函数宽度;
[0102]
获取钻机实时运行数据,并对钻机实时运行数据进行行归一化处理,得到处理后实时运行数据;
[0103]
将处理后实时运行数据输入工程爆破岩性识别模型进行岩性识别,得到对应的岩性识别结果。
[0104]
本发明提供一种基于机器学习的岩性识别方法,根据钻机参数和人工智能方法相结合实时获取钻进过程中岩性参数,简化了识别步骤,减少了工作量,并且无需其它昂贵的硬件设备,降低了成本投入,并且机器学习的算法不仅提高了识别效率,也提高了识别的准确率,实现精细化钻孔装药、精细化爆破,还可以将岩性识别结果反馈给钻机,实现高效作业。
[0105]
本发明不局限于上述可选的实施方式,任何人在本发明的启示下都可得出其他各种形式的产品。上述具体实施方式不应理解成对本发明的保护范围的限制,本发明的保护范围应当以权利要求书中界定的为准,并且说明书可以用于解释权利要求书。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1