一种针对分布式边缘学习中的模型聚合的分组优化方法
1.本发明涉及分布式边缘学习中模型性能优化技术领域,特别涉及一种针对分布式边缘学习中的模型聚合的分组优化方法。
背景技术:
2.随着移动计算和物联网设备的激增,大量的设备连接到互联网上并在网络边缘产生了大量的数据。然而,出于隐私和带宽限制将数据从边缘传输至中央训练机器学习模型是不切实际的。因此,将数据驱动的人工智能推向网络边缘从而释放边缘大数据的潜力已是大势所趋。为了满足这一需求,边缘智能作为一种新兴的范式,将人工智能从网络中心推向更接近物联网设备和数据源的网络边缘,已被广泛认为是一种很有前途的解决方案。从本质上说,与传统的基于云的计算范式相比,计算源和信息生成源之间的物理接近性有了一些好处,包括减少延迟、保护隐私、降低带宽消耗等。
3.然而,由于单台边缘设备的计算能力和数据存储能力无法满足利用庞大数据训练大型机器学习模型的要求,在边缘环境中使用并行度高的分布式计算机集群来协作学习已变得十分流行。目前大多数分布式机器学习框架为集中式的结构,其中边缘设备使用本地数据分别训练自己的模型,而位于云上的集中式主机迭代地协调边缘设备模型参数的聚合和更新,如联邦学习,但与云中现有的分布式机器学习相比,边缘环境中集中式的分布式机器学习面临着一些挑战。
①
设备数据非独立同分布。边缘计算中的数据源是从边缘和/或终端设备实时生成的。每个设备上的数据样本通常是非独立同分布(non-iid)的数据,而云中现有的分布式机器学习将数据源预先存储在云中。数据源被分配给大量计算节点进行数据并行处理,使得每个节点的数据样本都是独立同分布的。理论和实验表明,这种数据的异质性会显著影响全局模型的收敛时间和准确性。
②
巨大的通信开销。在边缘环境下的分布式机器学习中,边缘设备到云的网络带宽是有限的,大量的边缘设备通过带宽受限和间歇性无线网络与云连接,并将他们的本地模型迭代地传输到云,直到全局模型收敛为止。这往往需要需要数百到数千轮通信才能达到所需的模型精度。如果训练时间有限,长的传播延迟将降低全局模型的性能。而且若边缘服务器传输大型模型到云,例如r-cnn或u-net,这也将带来不可估量的通信开销。而在云中现有的分布式机器学习中,学习任务是在云簇中完成的,其中服务器具有强大的能力,连接服务器的网络具有保证和稳定的网络带宽。
③
骨干网饱和及单点故障。在边缘环境下的分布式机器学习中,成千上万的边缘设备发送自己的本地模型到云中聚合的范式会给骨干网带来沉重负担,且由于边缘环境中设备的不稳定性导致的单点故障使得全局模型面临聚合失败的风险。
4.近年来,一些工作针对分布式边缘学习中边缘设备数据非独立同分布、巨大的通信开销、骨干网饱和及单点故障的挑战都分别有许多深入的研究,但同时应对以上三种挑战的研究还不是很多。一些研究扩展两层的分布式边缘学习框架到三层架构,这些工作将边缘设备进行分组通过边缘设备与接近访问的组聚合节点的通信减少边缘设备到遥远的云服务器的通信,从而减少大规模分布式边缘学习中边缘设备和云的通信开销。并且,分组
通信将集中式的分布式学习的单点聚合模式扩展为多点聚合,在降低单点故障的危害的同时缓解了骨干网的负担。目前,已有的研究工作大多只考虑网络距离,试图将通信时延小的边缘设备划分在同一组。然而基于距离的分组,其组内边缘设备上的数据分布极大可能是相似的,组的数据分布相比全局依然是极度倾斜的。因此,这样的分组结构并不能有效的提高全局模型的收敛性能。最新的研究在中提出一种名为fedavg-ic的分组算法(jin-woo lee et al.accurate and fast federated learning via iid and communication-aware grouping.arxiv preprint arxiv:2012.04857,2020.),该算法虽然在分组时将边缘设备的数据分布考虑在内,但其基于k-means的方式进行分组,而基于k-means的方式需要人为的指定分组数k,这在真实的应用场景中是极度不灵活的,并且可能难以达到良好的聚类结果。更具体地说,这些方法需要执行多次不同的k才可能获得良好的聚类结果,从而缺乏泛化能力。此外,聚类结果在很大程度上受k的初始位置的影响。具体来说,k-means中的随机初始化很容易使聚类结果落入局部最优,可能无法获得良好的聚类结构,从而降低性能在聚类结构上训练的全局模型。
技术实现要素:
5.针对现有技术的缺点,本发明提供一种针对分布式边缘学习中的模型聚合的分组优化方法,本发明对分布式边缘学习中的模型聚合分组进行优化,通过考虑边缘设备的数据分布和设备间的网络距离,提出一种自动分组的方法,使得在不需要人为指定分组数的前提下,为分布式边缘学习获取一种高效的分组架构,该分组架构包括确定的分组数和各组组成员。使用我们的方法获取的分组架构可以实现全局模型收敛精度和收敛速度的提升。
6.本发明的目的至少通过如下技术方案之一实现。
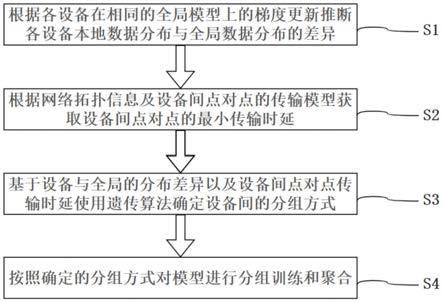
7.一种针对分布式边缘学习中的模型聚合的分组优化方法,包括以下步骤:
8.s1、根据各设备在相同的初始全局模型上使用其各自的本地数据集进行多轮训练得到的更新后的梯度与初始全局模型梯度的差异,来表示各设备的本地模型与初始全局模型的差异,从而根据设备的本地模型与初始全局模型的差异来量化各设备的本地数据分布与全局数据分布的差异;
9.s2、根据连接各个设备的网络拓扑信息获取各设备间点对点传输的连接关系和设备链路间的带宽资源,同时结合设备间点对点传输的模型大小,计算设备间点对点传输的最小传输时延;
10.s3、基于设备间点对点传输的最小传输时延以及各设备的本地数据分布与全局数据分布的差异,采用启发式的遗传算法编码网络中设备可能的分组方式,并通过遗传操作来自动的搜寻最优的分组结果,分组结果包括分组数和每组包括的成员设备,从而确定设备分组后模型分组聚合的方式;
11.s4、根据步骤s3中所确定的模型分组聚合的方式将网络中的设备划分为不同的组,并且设备按照获取的分组方式进行分组训练及分组模型聚合。
12.进一步地,每个设备都拥有多个数据样本,多个数据样本构成各个设备的本地数据集;并且每个设备在其本地数据集上进行基于梯度下降的模型训练,即可获取基于本地数据集训练得到的本地模型;
13.对于各个设备来说,设备间的数据分布往往是非独立同分布的,即各设备间本地数据分布不一致且不同于全局数据分布;
14.步骤s1中,为表示各设备分布与全局分布的差异,根据各设备在相同的初始全局模型上使用其各自的本地数据集进行多轮训练得到的更新后的梯度与初始全局模型梯度的差异量化设备的本地数据分布和全局数据分布间的差异,具体包括以下步骤:
15.s1.1、随机初始化一个全局模型并将该全局模型作为各设备统一的初始模型;所述全局模型为由本领域技术人员指定的机器学习模型,包括linear regression(lr)、multilayer perceptrons(mlp)或convolutional neural networks(cnn);
16.s1.2、在去中心化的分布式机器学习的框架下对各个设备进行多轮的本地更新和全局聚合,即各设备使用其完整的本地数据集在初始模型上进行一轮本地模型训练并获取其相应的本地模型后,所有设备按照其数据量对获取的本地模型进行加权平均得到一个全局聚合模型;
17.s1.3、将该全局聚合模型下发给各设备并作为各设备在下一轮本地模型训练的初始模型,返回步骤s1.2;
18.s1.4、步骤s1.2~步骤s1.3的本地模型训练和全局模型聚合的步骤在循环执行多轮后,使用当前获取的全局聚合模型作为度量本地模型与全局模型差异时的初始全局模型;
19.s1.5、在获取初始全局模型之后,各设备使用各自完整的本地数据集在初始全局模型上连续的执行多轮步骤s1.2中的本地模型训练,其中,对于每个本地设备来说,每一个本地模型训练轮都会遍历完所有的本地数据;并且在执行连续多轮的本地模型训练的过程中,各设备不会进行全局模型聚合的操作,即各设备使用其各自设备上的本地数据集对初始全局模型进行一轮本地模型训练,得到本地模型后,再循环多次对获取的本地模型进行一轮本地模型训练,循环多次得到本地模型,即可获取各设备在其本地数据集上进行本地模型训练得到的本地模型;
20.s1.6、通过模型梯度间的距离度量步骤s1.2~步骤s1.5中获取的初始全局模型的梯度和各设备的本地模型的梯度间的差异,模型梯度间距离的度量指标包括余弦距离、欧氏距离或曼哈顿距离;使用各设备的本地模型梯度与初始全局模型间梯度的差异表示各设备的本地数据分布和全局数据分布间的差异。
21.进一步地,步骤s2中,所述网络拓扑信息包括参与训练的设备、直连设备的链路以及各设备直连的链路的带宽资源,以参与训练的设备作为节点、以链路作为边以及以链路的带宽资源作为边的权值的形式将网络拓扑以有权无向图的数据结构进行存储。
22.进一步地,步骤s2包括以下步骤:
23.s2.1、通过广度优先搜索方法和深度优先搜索方法,根据网络拓扑结构以及各设备直连的链路的带宽资源首先计算得出使得设备间点对点传输带宽最大的传输路径,设备间点对点的传输路径由至少一条直连设备的链路构成;
24.s2.2、根据设备间点对点的传输路径上的带宽资源相加得到设备间点对点的传输路径可用的带宽资源,并根据该带宽资源和设备间点对点传输的模型的大小,即可通过将设备间点对点传输的模型大小除以设备间点对点传输路径可用的带宽资源得到设备间点对点传输的最小传输时延;
25.设备间点对点传输的模型的大小指模型的非0参数数量。
26.进一步地,步骤s3中,使用启发式遗传算法在不提前指定分组数的前提下根据网络中各设备的本地数据分布与全局数据分布的差异,以及设备间点对点传输的最小传输时延自动地搜索最优分组结果作为设备分组训练和聚合的方式,具体包括以下步骤:
27.s3.1、将编码网络中设备可能的分组方式作为遗传算法中个体的表示,并将多种分组方式即不同的个体组合成种群;
28.s3.2、确定评估方式,引入适应度函数来评判种群中每种分组方式(个体)的优良程度;
29.s3.3、确定种群中个体的选择方式,根据种群中各个个体评估的适应度数值从种群中选择适应度数值最高的个体直接加入下一代种群中参与下一轮迭代,其他个体进入下一代的概率为由个体适应度与群体适应度之比决定,群体适应度是所有个体适应度之和;
30.使用最优个体保存法为下一代种群选择个体,具体如下:
31.对于当前种群中的最优个体不进行交叉变异操作,而是直接保留当前种群中的最优个体进入下一代种群中,从而可以保留当前最优分组情况不被破坏,其他个体进入下一代的概率为由个体适应度与群体适应度之比决定,这样,种群中的好个体总是被选择而不是被破坏,这保证了种群不断朝着最好的方向进化,从而有利于人口的稳定收敛和提高搜索速度以获得更好的聚类结果从而稳定种群的收敛并提升种群寻优速度。
32.s3.4、确定交叉和变异的遗传操作,从选择的个体中按照当前种群的交叉率和变异率选择两个个体参与交叉和变异的遗传操作,从而产生适应度更高的后代加入下一代种群中参与下一轮迭代;
33.s3.5、重复执行步骤s3.3和步骤s3.4,直到迭代轮次达到预先设定的阈值为止,然后从最后的种群中选择适应度最高的个体作为最优的分组结果,并将其作为设备分组训练和聚合的方式。
34.进一步地,步骤s3.1具体包括以下步骤:
35.s3.1.1、初始化种群,编码种群中的个体:若网络中有n个设备,对网络中的n个设备从1到n进行编号,并将经过编号的设备进行随机排列,一种n的全排列方式则表示遗传算法中种群中的一个个体,种群包括随机生成的多个个体;
36.s3.1.2、对步骤s3.1.1中种群的其中一个个体,采用层次聚类机制首先将个体中每个设备初始化为不同的组;
37.s3.1.3、为每个组选择一个组聚合节点,选择当前组中使得组内设备间传输时延之和最小的的设备作为当前组的组聚合节点;
38.s3.1.4、从左到右依次遍历个体中的每个组,并比较当前组的组聚合节点与当前组左右两个组的组聚合节点之间的网络距离,将当前组与网络距离较小的组进行合并,设置一个合并阈值,若两个组的组聚合节点之间的网络距离超过合并阈值则两个组不予合并,合并结束后当前个体表示为一种分组方式;
39.s3.1.5、对种群中的所有个体都执行步骤s3.1.2~步骤3.1.4,直到所有的个体都表示为一种分组方式;
40.s3.1.6、对于步骤s3.1.5中每个个体的分组结果,重复执行步骤s3.1.3~步骤s3.1.4,直至每个个体中的分组都无法合并,每一次重复时均生成一次分组结果;
41.s3.1.7、将步骤s3.1.6中所有重复步骤中生成的分组结果进行适应度评估,评估后适应度最高的分组结果作为表示该个体表示的分组方式,此时每个个体表示一种分组方式,多个个体组合成遗传算法中的种群。
42.进一步地,步骤s3.2中,根据步骤s3.1中得到的每个个体的分组结果,计算每个分组结果中每个组的组聚合数据分布与全局数据分布的差异,以及每个组的组内各设备到组聚合节点的传输时延之和,最终将每个组的组聚合数据分布与全局数据分布的差异之和以及传输时延之和进行加权平均得到加权平均值,将该加权平均值作为当前分组方式所表示的分组花销;分组花销越大表示该个体表示的分组方式越差,对分组花销取倒数,作为最终的适应度,种群中的个体对应的适应度越大表示该个体的分组效果越好;
43.所述组聚合数据分布由该组内各设备的本地数据分布与全局数据分布的差异按该组内各设备上的数据量进行加权平均计算得到。
44.进一步地,步骤s3.4中,采用动态的交叉率和变异率为每一代的种群设置不同的交叉率和变异率,即根据当前种群的异质程度为种群选择交叉率和变异率,然后每代种群按照其各自的交叉率和变异率从种群中选择个体进行交叉和变异操作,从而进化出不同于当前种群中已存在的个体,具体包括如下步骤:
45.s3.4.1、表示种群的相似程度:计算当前种群中适应度数值最大的个体和种群中所有个体的平均适应度数值之差,将该差值按比例进行缩放至0到1之间,并使用缩放后的差值表示当前种群的异质程度;根据种群的异质程度值,使用1减去异质程度值即可表示种群的相似程度,则可理解,当缩放后的差值越小表明种群的相似程度越高;反之,则越低。
46.s3.4.2、根据当前种群的相似程度为种群设置动态的交叉率和变异率:在遗传算法开始时,根据本领域专家经验为当前种群选择初始交叉率和初始变异率,并且在每一轮种群进化的过程中,将初始交叉率和初始变异率乘以当前种群的相似程度得到当前种群的交叉率和变异率,为每一代种群按照其异质程度动态地获取交叉率和变异率,其中,种群的交叉率和变异率的范围为0到1;
47.s3.4.3、根据当前种群的交叉率和变异率从种群中选择个体进行交叉和变异操作:对于种群中的每个个体,为其随机的生成一个0到1的随机数,并将个体对应的随机数与当前种群的交叉率和变异率进行比较;若个体的随机数小于当前种群的交叉率,则该个体将被选择并进入交叉池等待参与个体的交叉操作;交叉池中的个体两两随机配对作为一组父代参与后续交叉操作;在上述交叉操作结束后,将会产生一组与交叉池中个体数相同的后代;同样,为交叉操作产生的后代随机生成不同的处于0到1之间的随机数,并比较后代表示的随机数与当前种群的变异率的大小,选择后代中随机数小于种群变异率的后代进入变异池等待参与个体的变异操作;
48.因此,动态改变种群进化过程中每一代的交叉率和变异可被理解。当当前种群的异质程度底时,即种群中每个个体的适应度趋于相同时,动态的提高种群的交叉率和变异率,以增加产生新个体的可能性,从而帮助种群跳出局部最优,避免早熟收敛,防止种群陷入局部最优解;当当前种群的异质程度高时,即种群中个体间的适应度相差较大时,动态的降低种群的交叉率和变异率,以减少产生新个体的可能性,从而使种群稳定快速地收敛;
49.s3.4.4、对交叉池和变异池中的个体进行交叉和变异操作,并产生新的个体:对步骤s3.4.3中处于交叉池中的已配对的一组父代,进行交叉和变异操作;在进行完交叉和变
异的操作后,将产生的新个体代替原来选中参与交叉和变异的旧个体,并与当前种群中未被选中的个体组成新一代的种群准备进行下一代的种群交叉和变异操作。
50.进一步地,步骤s3.4.4中,采用的交叉方式包括:两点交叉或多点交叉的交叉方式;
51.采用的变异方式为基本位变异的变异方式。
52.进一步地,步骤s4中,根据步骤s3中获取的最优的分组结果,根据步骤s3中获取的最优的分组结果划分网络中的设备,各设备分组后在其各自的组内进行模型训练并参与分组模型聚合,分组模型与服务器进行通信参与全局模型聚合;模型聚合和模型训练的方式按照一般的去中心化的分布式机器学习中的模型聚合和训练的方式实施。
53.与现有技术相比,本发明具有以下有益效果:
54.(1)本发明的一种针对分布式边缘学习中的模型聚合的分组优化方法,考虑到分布式边缘学习中大量边缘设备与中央服务器进行通信在有限的带宽资源条件下会导致的巨大的通信开销,将网络中的设备进行分组学习,并在分组时考虑设备间的网络距离,使得各组内的设备间的网络距离尽可能的小,从而使得分组后的设备只需与其位置靠近的组聚合设备进行通信,从而有效地减小传输设备模型的时延。
55.(2)本发明的一种针对分布式边缘学习中的模型聚合的分组优化方法,考虑到分布式边缘学习中设备上数据分布在非独立同分布情况下会导致全局模型训练性能差,将网络中的设备进行分组学习,并在分组时考虑设备间数据分布的差异,使得组数据分布与全局数据分布的差异尽可能的小,从而使得分组后的设备可以通过在与全局分布相似的组内多次与其组聚合节点进行短传输时延的通信来有效地提升全局模型的训练精度。
56.(3)现存的同时考虑数据分布和通信花销两个维度的分组算法大多基于k-means,该类算法需要人为的指定分组数量,且容易使得分组结果陷入局部最优。通过使用分层聚类机制结合启发式的遗传算法,本发明在不需要人为指定分组数的前提下可以根据设备的数据分布和设备间的网络距离自动的寻找最优的分组数和组成员,解决了目前技术现存的一些问题和缺陷。
附图说明
57.参考附图能够帮助理解本发明的实施例中技术特点与算法流程。
58.图1是本发明一个实施例中一种针对分布式边缘学习中的模型聚合的分组优化方法的整体流程示意图;
59.图2是本发明一个实施例中使用遗传算法进行分组方式搜索的流程图;
60.图3a和图3b为本发明一个实施例中层次聚类机制的示意图;
61.图4是本发明一个实施例中遗传算法个体两点交叉产生新后代的示意图;
62.图5是本发明一个实施例中遗传算法个体变异产生新后代的示意图;
63.图6是本发明一个实施例中遗传算法个体多点交叉产生新后代的示意图。
具体实施方式
64.下面将结合附图来详细描述本发明的实施例中的技术方案。应当理解,所描述的实施例仅仅是为了使本领域的技术人员能够更好地理解并实施本发明,而并非以任何方式
限制本发明的实施方式和范围。
65.实施例:
66.一种针对分布式边缘学习中的模型聚合的分组优化方法,如图1所示,包括以下步骤:
67.s1:根据各设备在相同的初始全局模型上使用其各自的本地数据集进行多轮训练得到的更新后的梯度与初始全局模型梯度的差异,来表示各设备的本地模型与初始全局模型的差异,从而根据设备的本地模型与初始全局模型的差异来量化各设备的本地数据分布与全局数据分布的差异;
68.每个设备都拥有多个数据样本,多个数据样本构成各个设备的本地数据集;并且每个设备在其本地数据集上进行基于梯度下降的模型训练,即可获取基于本地数据集训练得到的本地模型;
69.对于各个设备来说,设备间的数据分布往往是非独立同分布的,即各设备间本地数据分布不一致且不同于全局数据分布;
70.为表示各设备分布与全局分布的差异,根据各设备在相同的初始全局模型上使用其各自的本地数据集进行多轮训练得到的更新后的梯度与初始全局模型梯度的差异量化设备的本地数据分布和全局数据分布间的差异,本实施例中,具体包括以下步骤:
71.s1.1、随机初始化一个全局模型并将该全局模型作为各设备统一的初始模型;所述全局模型为由本领域技术人员指定的机器学习模型,本实施例中采用linear regression(lr);
72.在另一个实施例中,机器学习模型采用multilayer perceptrons(mlp);
73.在另一个实施例中,机器学习模型采用convolutional neural networks(cnn);
74.s1.2、在去中心化的分布式机器学习的框架下对各个设备进行10轮的本地更新和全局聚合,即各设备使用其完整的本地数据集在初始模型上进行一轮本地模型训练并获取其相应的本地模型后,所有设备按照其数据量对获取的本地模型进行加权平均得到一个全局聚合模型;
75.s1.3、将该全局聚合模型下发给各设备并作为各设备在下一轮本地模型训练的初始模型,返回步骤s1.2;
76.s1.4、步骤s1.2~步骤s1.3的本地模型训练和全局模型聚合的步骤在循环执行10轮后,使用当前获取的全局聚合模型作为度量本地模型与全局模型差异时的初始全局模型;
77.s1.5、在获取初始全局模型之后,各设备使用各自完整的本地数据集在初始全局模型上连续的执行3轮步骤s1.2中的本地模型训练,其中,对于每个本地设备来说,每一个本地模型训练轮都会遍历完所有的本地数据;并且在执行连续3轮的本地模型训练的过程中,各设备不会进行全局模型聚合的操作。即各设备使用其各自设备上的本地数据集对初始全局模型进行一轮本地模型训练,得到本地模型后,再循环2次对获取的本地模型进行一轮本地模型训练,循环2次得到本地模型,即可获取各设备在其本地数据集上进行本地模型训练得到的本地模型。
78.s1.6、通过模型梯度间的距离度量步骤s1.2~步骤s1.5中获取的初始全局模型的梯度和各设备的本地模型的梯度间的差异,本实施例中,模型梯度间差异的度量指标使用
余弦距离来度量模型间的差异,该差异值处于-1到1之间,越趋于-1则表示模型差异越小;反之,则越大。使用各设备的本地模型梯度与初始全局模型间梯度的余弦距离表示各设备的本地数据分布和全局数据分布间的差异。
79.s2:根据连接各个设备的网络拓扑结构获取各设备间点对点传输的连接关系、设备链路间的带宽资源以及设备间点对点传输的模型大小,计算设备间点对点传输的最小传输时延;
80.所述网络拓扑信息包括参与训练的设备、直连设备的链路以及各设备直连的链路的带宽资源,以参与训练的设备作为节点、以链路作为边以及以链路的带宽资源作为边的权值的形式将网络拓扑以有权无向图的数据结构进行存储。
81.步骤s2包括以下步骤:
82.s2.1、通过广度优先搜索方法以及贪心策略,根据网络拓扑结构以及各设备直连的链路的带宽资源首先计算得出使得设备间点对点传输带宽最大的传输路径,设备间点对点的传输路径由至少一条直连设备的链路构成;
83.本实施例中,具体方法是,若需要计算第一设备a到第二设备c的具有最大带宽资源的路由路径,首先将节点间边的权值取倒数,将寻求最大带宽资源的路径转换为最短路径问题。即从网络拓扑有权无向图的数据结构中第一设备a代表的节点开始基于贪心策略搜索,每次都选择与第一设备a距离最近的且尚未确认最短路径的第三设备b,认为当前第一设备a到第三设备b的距离就是最终第一设备a到第二设备c的最短路径,迭代的执行上述过程,直到到达目标终点第二设备c。将搜索过程中的所有设备按序组合即为最终第一设备a到第二设备c的带宽资源最大的路由路径。同时,由获取的设备间的传输路径,以及路径上的带宽资源,可以通过将设备间传输路径上的权值进行加和从而得到设备间点对点传输的最大带宽资源。
84.s2.2、根据设备间点对点的传输路径上的带宽资源相加得到设备间点对点的传输路径可用的带宽资源,通过将设备间点对点传输的模型大小除以设备间点对点传输路径可用的带宽资源,从而可以获取设备间传输的最小通信延迟,使用该延迟来定义设备间点对点传输的最小传输时延;同时,为了说明设备间点对点的网络距离,使用设备间点对点传输的最大带宽的倒数表示设备间点对点的网络距离;
85.设备间点对点传输的模型的大小指模型的非0参数数量。
86.s3:基于点对点传输的最小传输时延以及各设备的本地数据分布与全局数据分布的差异,采用启发式的遗传算法编码网络中设备可能的分组方式,并通过遗传操作来自动的搜寻最优的分组结果,分组结果包括分组数和每组包括的成员设备,从而确定设备分组后模型分组聚合的方式;
87.本领域的技术人员可以理解,遗传算法有几个关键流程,即初始化种群并为种群中的个体进行编码、为个体优良性评估设置合适的适应度函数、设计选择方式选择个体进入下一代、以及设计交叉和变异的方法进化种群。
88.使用启发式遗传算法在不提前指定分组数的前提下根据网络中各设备的本地数据分布与全局数据分布的差异,以及设备间点对点传输的最小传输时延自动地搜索最优分组结果作为设备分组训练和聚合的方式,如图2所示,具体包括以下步骤:
89.s3.1、将编码网络中设备可能的分组方式作为遗传算法中个体的表示,并将多种
分组方式即不同的个体组合成种群,具体包括以下步骤:
90.s3.1.1、初始化种群pop,编码种群中的个体:本实施例中,网络中有10个设备,对网络中的10个设备从0到9进行编号,并将经过编号的设备进行随机排列,一种0到9的全排列方式则表示遗传算法中种群中的一个初始个体,种群包括随机生成的多个个体;设置初始的种群大小为500,即初始种群中由500个个体组合而成;
91.图2中在步骤1初始化种群阶段所示的个体p1和p2分别表示10个设备的两种不同的全排列方式。
92.s3.1.2、如图2中的步骤2所示,对步骤s3.1.1中种群的其中一个个体,如图3a和图3b所示,采用层次聚类机制首先将个体中每个设备初始化为不同的组;
93.s3.1.3、为每个组选择一个组聚合节点,选择当前组中使得组内设备间传输时延之和最小的的设备作为当前组的组聚合节点如图3a的个体p所示;
94.p表示初始化的个体,网络中一共有10个设备,设备编号从0到9,其中每个设备(基因)表示一个分组,分组编号从0开始,网络中有多少个设备即在初始时有多少个分组,本实例中,网络分组集合从c0到c9;
95.当组内的设备只有一个时,组聚合节点即为当前设备,如对于p中的分组c0,其只包含一个设备则该组的组聚合节点为第二设备2;当组只有两个设备时,组聚合节点为第一个节点,如对于分组结果c0中的组c0,其组聚合节点为第二设备2;
96.s3.1.4、从左到右依次遍历个体中的每个组,并比较当前组的组聚合节点与当前组左右两个组的组聚合节点之间的网络距离,将当前组与网络距离较小的组进行合并,设置一个合并阈值α,若两个组的组聚合节点之间的网络距离超过合并阈值α则两个组不予合并,合并结束后当前个体表示为一种分组方式;
97.对于初始个体p,如图3a所示,从第一个分组c0开始遍历,c0中的聚合节点为第二设备2,该聚合节点与其右边分组c1的聚合节点进行比较,如两者的网络距离小于预设定的阈值α,则将分组c0和c1进行合并,合并后的分组下标为c0,后续分组的分组下标相应的进行修改,即在原始数值上将下标减小1即可。
98.值得注意的是,进行组的合并之后需要根据步骤s3.1.3的机制更新当前新生成的组的组聚合节点。
99.对于上述进行过一次合并操作的个体p,在此基础上继续进行同样的合并操作,顺序遍历分组c1,比较其与左右两边分组c0和c2的组聚合节点的网络距离,本实施例中,c1与其右边的分组c2的网络距离更小,则将分组c1和c2进行合并,同时,更新合并后新的分组的下标为c1,后续分组的分组下标相应的进行修改,即在原始数值上将下标减小1即可。同时,需要更新合并后的分组c1的组聚合节点。
100.对于上述进行过两次合并操作的个体p,在此基础上继续进行同样的合并操作,顺序遍历分组c2,比较其与左右两边分组c1和c3的组聚合节点的网络距离,本实施例中,c2与其左右两边分组的网络距离都超过了预先设定的允许合并的最大阈值α,则分组c2不进行合并操作,其余分组的下标无需更改,且各分组的组聚合节点无需更新。
101.s3.1.5、对种群中的所有个体都执行步骤s3.1.2~步骤3.1.4,直到所有的个体都表示为一种分组方式;
102.本实施例中,图3a中c0表示的就是初始种群中个体p对应的分组方式,其中个体p
最终通过迭代的步骤s3.1.2~步骤3.1.4从而将网络中的10个设备在不指定分组数的前提下划分为了6个分组。
103.s3.1.6、对于步骤s3.1.5中每个个体的分组结果,重复执行步骤s3.1.3~步骤s3.1.4,直至每个个体中的分组都无法合并,每一次重复时均生成一次分组结果;
104.图3b中,个体p经过步骤s3.1.5获取其所表示的初始分组方式c0,本实施例中将c0作为初始个体,该个体有6个分组,在该个体c0的基础上继续迭代的执行步骤s3.1.3~步骤s3.1.4,即本发明顺序的遍历6个分组,并且在遍历分组的过程中执行可能的合并操作,直到遍历完最后一个分组。本实施例中,在c0基础上经过合并遍历操作生成的分组形式为c1,分组c1包含4个分组。
105.图3b中,本发明以分组结果c1作为初始个体,在c1的基础上迭代的执行步骤s3.1.3~步骤s3.1.4所述的合并遍历操作,获取个体p表示的另一种可能的分组结果c2;
106.图3b中,本发明以分组结果c
m-1
作为初始个体,在c
m-1
的基础上迭代的执行步骤s3.1.3~步骤s3.1.4所述的合并遍历操作,本实例中遍历合并操作执行完成之后,分组结果c
m-1
合并成了一个分组,即以cm的形式表示,此时,停止合并操作。
107.值得注意的是,从个体p开始,通过迭代的执行合并遍历操作,最终生成了m+1个个体p可表示的分组结果。
108.s3.1.7、将步骤s3.1.6中所有重复步骤中生成的分组结果进行适应度评估,评估后适应度最高的分组结果作为表示该个体表示的分组方式,此时每个个体表示一种分组方式,多个个体组合成遗传算法中的种群;
109.由于生成分组的规则是一定的,且设备间的路由路径,即设备间的网路距离,是通过步骤s1通过一定的规则获取的。因此个体的一种全排列方式与其通过层次聚类机制生成的分组方式是一一对应的,即初始的设备的全排列方式即可表示为网络中的一种分组方式。
110.s3.2、确定评估方式,引入适应度函数来评判种群中每种分组方式(个体)的优良程度;
111.根据步骤s3.1中得到的每个个体表示的分组方式,计算每个分组方式中每个组m的组聚合数据分布与全局数据分布的差异以及每个组的组内各设备到其所在组的组聚合设备的传输时延d
cluster
,最终将每个组的组数据分布与全局数据分布的差异之和cos
global
及传输时延d
cluster
进行加权平均得到加权平均值v
p
=cos
global
+β*d
cluster
,将该加权平均值v
p
作为当前分组方式所表示的分组花销,β为每个组的组内各设备到组聚合节点的传输时延d
cluster
的权重值;分组花销越大表示该个体表示的分组方式越差,对分组花销取倒数,作为最终的适应度,种群中的个体对应的适应度越大表示该个体的分组效果越好;
112.所述组聚合数据分布由该组内各设备的本地数据分布与全局数据分布的差异按该组内各设备上的数据量进行加权平均计算得到。
113.本实施例中,分组m中的设备i的本地数据分布与全局数据分布的差异由本发明在s1中通过设备在其本地数据集上进行连续3轮的本地模型训练得到的模型表示,分组m的数据分布wm可由其组内设备的模型按本地数据量占组数据量dm加权平均获取,即
全局聚合模型w可由步骤s1中所有设备在去中心化的分布式机器学习的框架下进行10轮的本地更新和全局聚合并按照设备各自的数据量占全局数据量d进行加权平均获取。本实施例中,通过模型梯度间的余弦相似度来表示组聚合数据分布与全局的数据分布的差异cos
global
,其中分组m中的设备i到分组m的聚合设备的传输时延由步骤s1中计算的设备间的网络距离表示,而分组m内所有设备到分组m的组聚合设备的传输时延dm则通过该组内所有设备的传输时延按其数据量的加权平均值表示,即同时所有组的组内设备到其各自组的组聚合设备的传输时延由所有组的传输时延按其组数据量的加权平均值表示,即
114.对于遗传算法来说,通识是个体适应度越大表示该个体越好,为了迎合这个通识,对分组花销值取倒数,同时为了将该值缩放在一个可控的范围内,使用指数e作为底数。本实施例中,个体的适应度函数为作为最终的分组适应度。其中,v
p
越小表明个体的适应度越大,则该个体的分组效果越好。
115.s3.3、确定种群p(t)中个体的选择方式。根据当前种群中的个体的适应度数值从种群中选择适应度数值最高的个体直接加入下一代种群中参与下一轮迭代,其他个体进入下一代的概率为由个体适应度与群体适应度之比决定,群体适应度是所有个体适应度之和;
116.使用最优个体保存法为下一代种群p(t+1)选择个体,具体如下:
117.对于当前种群中的最优个体不进行交叉变异操作,而是直接保留当前种群中的最优个体进入下一代种群中,从而可以保留当前最优分组情况不被破坏。对于其他个体(非最优个体)进入下一代的概率为各个体的适应度f
p
(t)与群体适应度∑
p∈pfp
(t)之比决定,这样,种群中的好个体总是被选择而不是被破坏,这保证了种群不断朝着最好的方向进化,从而有利于人口的稳定收敛和提高搜索速度以获得更好的聚类结果从而稳定种群的收敛并提升种群寻优速度。
118.s3.4、确定交叉和变异的遗传操作,从选择的个体中按照当前种群的交叉率和变异率选择两个个体参与交叉和变异的遗传操作,从而产生适应度更高的后代加入下一代种群中参与下一轮迭代;
119.采用动态的交叉率和变异率为每一代的种群设置不同的交叉率和变异率,即根据当前种群的异质程度为种群选择交叉率和变异率,然后每代种群按照其各自的交叉率和变异率从种群中选择个体进行交叉和变异操作,从而进化出不同于当前种群中已存在的个体,具体包括如下步骤:
120.s3.4.1、表示种群的相似程度:计算当前种群中适应度数值最大的个体和种群中
所有个体的平均适应度数值之差,将该差值按比例进行缩放至0到1之间,并使用缩放后的差值表示当前种群的异质程度。根据种群的异质程度值,使用1减去异质程度值即可表示种群的相似程度,则可理解,当缩放后的差值越小表明种群的相似程度越高;反之,则越低。
121.s3.4.2、根据当前种群的相似程度为种群设置动态的交叉率和变异率:在遗传算法开始时,根据本领域专家经验为当前种群选择初始交叉率和初始变异率,并且在每一轮种群进化的过程中,将初始交叉率和初始变异率乘以当前种群的相似程度得到当前种群的交叉率和变异率,为每一代种群按照其异质程度动态地获取交叉率和变异率,其中,种群的交叉率和变异率的范围为0到1;
122.本实施例中,使用ψ
t
=1-f(t)来表示当前种群p(t)的相似程度,f(t)表示种群的异质程度。其中f(t)
max
表示种群p(t)中最大适应度的个体的适应度值,表示种群p(t)中个体的平均适应度值。也就是说,f(t)的值较小时,表示当前种群的异质程度较小,则交叉率和变异率应该相应的增加,从而可以提高种群的异质性,防止种群陷入局部最优。本实施例中,动态的交叉率cr
t
和变异率mr
t
如下所示,其中ini_cr和ini_mr分别表示初始的交叉和变异率,在此基础上对每一代种群的交叉和变异率进行以下所示的动态调整:
123.cr
t
=ψ
t
·
ini_cr;
124.mr
t
=ψ
t
·
ini_mr;
125.s3.4.3、根据当前种群的交叉率和变异率从种群中选择个体进行交叉和变异操作:对于种群中的每个个体,为其随机的生成一个0到1的随机数,并将个体对应的随机数与当前种群的交叉率和变异率进行比较,若个体的随机数小于当前种群的交叉率,则该个体将被选择并进入交叉池等待参与个体的交叉操作;交叉池中的个体两两随机配对作为一组父代参与后续交叉操作;在交叉操作结束后,将会产生一组与交叉池中个体数相同的后代;同样,为交叉操作产生的后代随机生成不同的处于0到1之间的随机数,并比较后代表示的随机数与当前种群的变异率的大小,选择后代中随机数小于种群变异率的后代进入变异池等待参与个体的变异操作;
126.因此,动态改变种群进化过程中每一代的交叉率和变异率可被理解。当当前种群的异质程度低时,即种群中每个个体的适应度趋于相同时,动态的提高种群的交叉率和变异率,以增加产生新个体的可能性,从而帮助种群跳出局部最优,避免早熟收敛,防止种群陷入局部最优解;当当前种群的异质程度高时,即种群中个体间的适应度相差较大时,动态的降低种群的交叉率和变异率,以减少产生新个体的可能性,从而使种群稳定快速地收敛;
127.s3.4.4、对交叉池和变异池中的个体进行交叉和变异操作,并产生新的个体:对步骤s3.4.3中处于交叉池中的已配对的一组父代,进行交叉和变异操作;本实施例中,如图4所示,采用的交叉方式为两点交叉的交叉方式,即以当前种群获取的交叉率随机选择两个个体作为父代,在两个个体中随机的生成两个交叉点,将这两个交叉点间的部分基因进行交换,从而产生两个新的后代,具体如下:
128.第一步,为交叉池中的一对待交叉个体第一父代1和第二父代2中随机的选择两个交叉点c1和c2,两个父代的交叉点被选中的位置是一致的;
129.第二步,在选择完相应的交叉点后,两个父代将c1和c2之间的基因进行一一对应的
交换;
130.第三步,在交换基因后需要对交换后的个体进行冲突检测,即根据交换的两组基因建立一个映射关系,如图4所示,以1-6-3这一映射关系为例,可以看到第二步,结果中子代1存在两个基因1,这时将其通过映射关系转变为基因3,以此类推直至没有冲突为止;
131.最后所有冲突的基因都会经过映射,保证形成的新一对子代基因无冲突。
132.本实施例中,采用的变异方式为基本位变异中的多点变异的变异方式,即在上一步产生的后代中以一定的变异率选择可变异个体进行变异操作。对于可变异个体,本示例随机选择两个变异点,并将两个变异的基因进行交换,从而产生由新的后代。
133.本实施例中展示了种群中个体的变异方式,这里产生变异的个体为上述的子代1,变异示意图如图5所示;
134.第一步,为变异池中子代1中随机选择两个变异点,本示例中选中的变异点为m1和m2;
135.第二步,在选择完相应的变异点后,将m1和m2位置的两个基因进行交换。
136.在进行完交叉和变异的操作后,将产生的新个体代替原来选中参与交叉和变异的旧个体,并与当前种群中未被选中的个体组成新一代的种群准备进行下一代的种群交叉和变异操作。
137.s3.5、如图2中的步骤3所示,重复执行步骤s3.3和步骤s3.4,直到迭代轮次达到预先设定阈值或直到种群收敛为止,然后从最后的种群中选择适应度最高的个体作为最优的分组结果作为设备分组训练和聚合的方式;
138.本实施例中,最大迭代轮次设置为1000轮,且种群收敛的意味着种群连续迭代100轮其最优个体都不变。接着,从最终的种群中选择适应度最高的个体作为最优的分组结果并返回,即如图2中的步骤4所示。
139.s4:根据步骤s3中确定的模型分组聚合的方式将网络中的设备划分为不同的组,并且设备按照获取的分组方式进行分组训练及分组模型聚合;
140.本实施例中,将按照步骤s3中获取的最优的分组结果对网络中的设备进行分组。在每一组中,组内设备只参与本地模型训练和与组聚合设备进行通信;组聚合设备则负责聚合其组内节点的模型并与服务器进行通信;服务器只聚合组聚合模型传输的模型并只与组聚合模型进行通信;本领域内相关技术人员可知,模型聚合和训练的方式将按照一般的去中心化的分布式机器学习中的模型聚合和训练的方式实施。
141.实施例2:
142.本实施例与实施例1不同之处在于,本实施例中的度量模型梯度间差异的度量标准采用的是欧式距离,即组聚合模型梯度wm与全局模型梯度w的差异可表示为:
143.实施例3:
144.本实施例与实施例1不同之处在于,本实施例中的交叉操作采用多点交叉的交叉方式,操作示意图如图6所示。具体步骤如下:
145.第一步,为交叉池中的一对待交叉个体第一父代1和第二父代2中随机的选择多个交叉点,本实施例中选择的交叉点个数为4。交叉点分别为c1、c2、c3和c4,并且两个父代的交叉点被选中的位置是一致的;
146.第二步,在选择完相应的交叉点后,生成第一子代1,并且保证子代被选中的交叉
点位置与父代相同,同时将父代交叉点处的基因赋值给第一子代1;
147.第三步,找出第一步在第一父代1中选中的交叉点的基因在第二父代2中的位置,并将其余不属于第一父代1的基因按顺序放入第二部生成的第一子代1中剩余的位置;
148.第四步,交换第一父代1和第二父代2的位置,同时保证被选中的交叉点与第一步中的一致,即可按步骤1~3生成第二子代2。
149.以上实施例仅适用于说明本发明,而并非对本发明的限制,有关技术领域的技术人员,在不脱离本公开的精神实质和原理的情况下对本发明所做的改变、修饰、替代、组合和简化均应为等效的置换方式,且都属于本发明的保护范畴,本发明的专利保护范围应由权利要求限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1