一种基于多变量时间序列多尺度特征提取的熔炼炉高铅渣成份预测方法
:
1.本发明涉及氧气底吹炼铅技术领域,具体涉及一种基于多变量时间序列多尺度特征提取的熔炼炉高铅渣成份预测方法。
背景技术:
2.氧气底吹炼铅技术具有原料适应性强、能量利用率高的特点,是实现含铅固废回收的重要方法。熔炼炉是氧气底吹炼铅过程的核心装置,其产物高铅渣的成份是生产过程的重要评价指标和生产配料调整的主要依据。建立高铅渣成份预测模型对于及时调整投料配比具有实际的指导作用。
3.目前,关于氧气底吹熔炼炉建模方法的研究主要集中在:基于熔炼过程物理化学反应的机理模型、基于生产数据的多元线性回归模型以及循环神经网络预测模型等。机理模型由于对生产过程的假设和简化,使得模型和实际存在一定误差。多元线性回归模型使用不同的权重来组合多个自变量共同预测目标变量,但无法对实际生产中变量间的非线性进行有效建模。循环神经网络模型可以很好地捕捉数据间的非线性关系以及变量的固定周期时序模式,但在氧气底吹炼铅过程中,熔炼炉的大容积效应会引起数据变量的周期性随时间发生变化,从而使得循环神经网络的预测出现偏差。
技术实现要素:
4.本发明针对上述问题,提供一种基于多变量时间序列多尺度特征提取的熔炼炉高铅渣成份预测方法,以提高熔炼炉高铅渣含铅量预测建模的精度和稳定性。
5.为了实现上述目的,本发明采取如下的技术方案:
6.一种基于多变量时间序列多尺度特征提取的熔炼炉高铅渣成份预测方法,其特征在于,所述方法包括:
7.利用卷积-自注意力组件获取熔炼炉数据中多变量时间序列的多尺度时序特征关系;利用线性自回归组件来提高模型对输入大小尺度变化的敏感性;独立训练线性自回归组件和卷积-自注意力组件:利用贝叶斯信息准则bic(bayesian information criterion,贝叶斯信息准则)确定线性自回归组件模型阶次,利用最小二乘估计确定各阶次参数;固定线性自回归组件参数,训练卷积-自注意力组件,并在验证集上使用网格搜索确定最优模型超参数,获得最终的基于多变量时间序列多尺度特征提取的熔炼炉高铅渣成份预测模型。
8.在采用上述技术方案的基础上,本发明可采用以下进一步的技术放哪,或对这些进一步的技术方案组合使用:
9.所述方法包括以下步骤:
10.步骤(1):数据采集;所述数据主要包括熔炼炉的投料量数据、投料成份数据以及产物高铅渣成份化验数据;
11.步骤(2):数据预处理;对数据中存在的异常值和缺失值进行删除和填充,并对数
据进行归一化;
12.步骤(3):数据划分;选取输入窗口长度为t、预测窗口长度为h进行数据划分;假设当前时刻t,模型基于历史时刻{t-t+1,t-t+2,
…
,t}的入料数据和历史高铅渣成份数据,预测未来的h个时间跨度{t+1,t+2,
…
,t+h}上的高铅渣成份百分比;取t=kt,则输入为:
13.dk={(x'
(k-1)t+1
,y'
(k-1)t+1
),(x'
(k-1)t+2
,y'
(k-1)t+2
),
…
,(x'
kt
,y'
kt
)}∈rd×
t
,
14.对应输出为:yk={y'
kt+1
,y'
kt+2
,
…
,y'
kt+h
}∈r1×h,k∈n
+
,且kt+h≤m.将归一化后的数据集滚动切分为{dk,yk}形式,并按时间顺序将切分后的数据分为训练集m
train
、验证集m
valid
和测试集m
test
;
15.步骤(4):模型构建;所述的高铅渣成份预测模型,包括卷积-自注意力组件和线性自回归组件;其中,卷积-自注意力组件包括多尺度卷积-池化层和自注意力层;多尺度卷积-池化层为n层金字塔结构:从下至上,第i层的一维卷积核个数为ki,卷积核长度为li,i∈[1,n];各层的每个卷积核沿变量维度对输入的数据dk中的每一个单变量时间序列进行卷积,第j个卷积核输出为:1≤l
i+1
《li≤t,1≤j≤ki.对hj进行一维最大池化,并将第i层的所有卷积-池化结果进行拼接得到特征矩阵具有较大长度卷积核的卷积层提取全局时序特征,具有较小卷积核的卷积层提取局部时序特征,mi中的每行可以看作是对单个变量在所有时间范围内提取的某一时间尺度的时序特征;自注意力层分n层结构,每层由n个独立自注意力子层堆叠而成,每个自注意力子层包含多头注意力子结构和前馈网络子结构两部分;第i层自注意力层输入为第i层卷积-池化层的多尺度时序特征矩阵mi,输出结果为矩阵ai;拼接所有层的计算结果ai,输入全连接层进行融合,计算结果为
[0016]
线性自回归组件建模预测目标序列历史值之间的自相关性,用来提高模型对输入大小尺度变化的敏感性,计算结果输出为模型最终输出模型最终输出ω为融合超参数;
[0017]
步骤(5):模型训练与保存;使用步骤(3)中划分的训练集和验证集对步骤(4)构建的模型进行训练,在测试集评估模型预测效果,并保存效果最好的模型;模型误差评价指标采用mse(mean square error,均方误差)
[0018][0019]
其中len
test
为测试样本总数;
[0020]
在训练集和验证集上使用bic准则确定线性自回归组件阶数p,使用最小二乘估计确定模型参数;固定线性自回归组件参数,选取合适的批次大小,使用小批量随机梯度下降法和adam对模型剩余部分进行训练;使用网格搜索方法在验证集上确定模型融合的超参数ω的取值,模型的最终输出为
[0021]
步骤(6):模型应用;设当前时刻为t,对现场生产数据进行步骤(2)所述的预处理,输入到步骤(5)保存的模型中,对未来h个时间步长{t+1,t+2,
…
,t+h}的高铅渣成份目标值进行预测。
[0022]
进一步地,步骤(1)的具体实现为:
[0023]
选取的生产数据包括:熔炼炉的投料量数据da、投料成份数据db以及产物高铅渣成份化验数据dc;其中,da包括球料处理量(t)、烟灰配入量(t)、氧气量(nm3)、氮气量(nm3)、铅膏(t)、焦粒(t)、石膏(t)、铅渣(t);db包括球料各成份(pb、zn、cu、fe、ca、si、s)的百分比含量、球料成份铁硅比、球料成份钙硅比等;dc为熔炼炉每炉产物高铅渣成份百分比时间序列。
[0024]
进一步地,步骤(2)的具体实现为:
[0025]
(1)异常值剔除:对于数据中的异常数据使用箱线图和q-q图(quantile-quantile plot,分位数图)统计方法判断出异常离群值后进行剔除;
[0026]
(2)缺失值填充:对于数据中的缺失数据,采用时间上相邻近的样本进行线性递推填充;
[0027]
(3)归一化:对数据进行归一化以消除不同变量量纲的影响;原始匹配后的数据为d={x,y}={(x1,y1),(x2,y2),
…
,(xm,ym)},d∈rd×m,其中d为变量维度(包括预测目标),m为序列的总的时间长度,xi=(x
i1
,x
i2
,
…
,x
i(d-1)
),yi∈r,i∈[1,m];对数据集d进行最大最小归一化最终数据集d'={x',y'}={x'i,y'i}∈rd×m,i∈[1,m]。
[0028]
进一步地,步骤(4)的具体实现为:
[0029]
(1)卷积-自注意力组件包括多尺度卷积-池化部分和自注意力部分,每个部分都为n层结构,且各层的卷积核个数统一设为k,即ki=k,i∈[1,n];
[0030]
(2)多尺度卷积-池化部分采取n层金字塔结构;第i层使用ki个长度为li的一维卷积核,沿变量维度对dk中的每一个特征变量的时间序列进行卷积,第j个卷积核输出为1≤l
i+1
《li≤t,1≤j≤ki;对hj进行一维最大池化,并将第i层所有卷积-池化结果进行拼接得到特征矩阵mi中的每行可以看作是对单个变量在所有时间范围内提取的某一时间尺度的时序特征;
[0031]
(3)自注意力部分为n层结构,每层由n个相同结构的独立自注意力子层堆叠而成,每个自注意力子层包含多头注意力子结构和前馈网络子结构两部分,并使用残差连接和层归一化来提高训练的稳定性;第i层自注意力层输入为第i层卷积-池化层的多尺度时序特征矩阵mi,输出结果为矩阵ai;拼接所有层的计算结果ai,输入全连接层进行融合,计算结果为
[0032]
(4)线性自回归组件;使用线性自回归模型,模型阶数为p阶,输入为预测目标{y1,y2,
…
,y
t
}单变量时间序列,输出为预测的未来炉次的高铅渣成份;模型最终输出为ω为融合超参数。
[0033]
进一步地,步骤(5)的具体实现为:
[0034]
(1)模型误差评价指标采用mse(mean square error,均方误差)
[0035][0036]
其中len
test
为测试样本总数;
[0037]
(2)在训练集和验证集上使用bic准则确定线性自回归组件阶数p,使用最小二乘估计确定模型参数;
[0038]
(3)线性自回归组件使用上述确定的参数,训练卷积-自注意力组件;选取合适的批次大小,使用小批量随机梯度下降法和adam进行模型训练;
[0039]
(4)使用网格搜索方法在验证集上确定模型融合的超参数ω的取值,模型的最终输出为
[0040]
(5)训练完成后,在测试集上测试模型效果,并保存预测效果最好的模型。
[0041]
进一步地,步骤(6)的具体实现为:
[0042]
每次预测后续h个时间步长的目标值,即假设当前时刻为t,则输入1,2,
…
,t的数据,模型返回t+1,
…
,t+h预测结果,并将预测结果作为下一步预测输入的一部分输入模型中,进行滚动预测。
[0043]
与现有技术相比,本发明的有益效果在于:
[0044]
(1)本发明针对熔炼炉过程数据的时序特点,提出采用基于卷积-自注意力的时间序列多尺度特征提取方法,有效填补了目前熔炼炉过程建模中对数据动态周期时序模式进行建模的空白;
[0045]
(2)本方法使用自注意力模块,可以有效综合不同变量时间序列的多尺度的相互依赖;
[0046]
(3)本发明融合线性自回归组件,提高了模型输出对输入大小尺度变化的敏感性。
附图说明:
[0047]
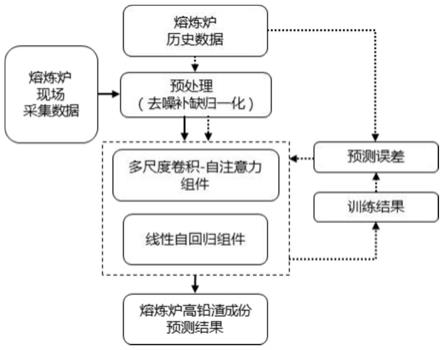
图1是本发明的模型训练预测流程图;
[0048]
图2是本发明的数据划分过程示意图;
[0049]
图3是本发明的模型结构示意图;
[0050]
图4是本发明的多尺度卷积-池化示意图。
具体实施方式:
[0051]
本发明提出了一种基于多变量时间序列多尺度特征提取的熔炼炉高铅渣成份预测方法,以下将结合附图和具体实施例对本发明作进一步详细描述,借此对本技术如何应用技术手段来解决技术问题并达成技术功效的实现过程能充分理解并据以实施。
[0052]
在本实施例中,采用现场氧气底吹熔炼炉的生产过程数据样本,实施本发明提出的基于多变量时间序列多尺度特征提取的熔炼炉高铅渣成份预测方法,模型训练预测流程图如图1所示,具体包括如下步骤:
[0053]
步骤(1):数据采集;通过现场生产记录设备获取熔炼炉历史生产的时序数据,包括熔炼炉每炉的投料量数据da、投料成份化验数据db和每批次放料时产物高铅渣成份化验数据dc,并整理成数据集d={x,y}={xi,yi}∈rd×m,i∈[1,m],其中d为变量维度(包括预测目标),m为序列的总的时间长度,xi=x
i1
,x
i2
,
…
,x
i(d-1)
}∈r1×
(d-1)
为输入特征变量,d-1为特征变量的个数,yi∈r为输出预测目标变量,即高铅渣成份;
[0054]
步骤(2):数据预处理;对数据集d进行预处理:使用箱线图和q-q图统计方法判断出异常离群值后进行剔除;采用时间上相邻近的样本的值进行线性递推以填充缺失数据;对每个变量分别统计其序列中的最大值和最小值,进行归一化,得到预处理后的数据集d'={x',y'}∈rd×m;
[0055]
步骤(3):数据划分;基于步骤(1)和步骤(2)得到的数据集d',选取合适的时间窗口t和预测长度h,设当前时刻为t,将{t-t+1,t-t+2,
…
,t}范围内的熔炼炉投料量数据、投料成份数据和高铅渣成份化验数据作为模型的一组输入,将当前时刻t之后的h个时间跨度{t+1,t+2,
…
,t+h}上的高铅渣成份化验数据作为对应的输出,对数据集进行切分,并按时间顺序将其划分为训练集、验证集和测试集;划分过程如图2所示;
[0056]
步骤(4):模型构建;实现卷积-自注意力组件包括多尺度卷积-池化部分和自注意力部分,实现线性自回归组件,组合成高铅渣成份预测模型,模型结构如图3和图4所示;
[0057]
步骤(5):模型训练和保存;将训练集和验证集用于步骤(4)构建模型的参数训练,使用网格搜索方法对模型中的超参数进行寻优,在测试集上测试模型预测效果,并保存最优的模型;
[0058]
步骤(6):模型应用;读取熔炼现场的实时生产数据,采用步骤(2)所述的预处理算法进行处理,按照步骤(3)进行数据切分,并输入到步骤(5)保存的模型中,得到模型的实际预测结果,以实现基于多变量时间序列多尺度特征提取的熔炼炉高铅渣成份预测方法。
[0059]
本发明中实现对熔炼炉产物高铅渣成份(铅含量)百分比的预测,具体实现过程如下:
[0060]
在步骤(1)中,通过现场生产记录设备获取熔炼炉历史生产的时序数据,包括熔炼炉每炉的投料量数据da、投料成份化验数据db和产物高铅渣成份化验数据dc;其中,da包括球料处理量(t)、烟灰配入量(t)、氧气量(nm3)、氮气量(nm3)、铅膏(t)、焦粒(t)、石膏(t)、铅渣(t);db包括球料各成份(pb、zn、cu、fe、ca、si、s)的百分比含量、球料成份铁硅比、球料成份钙硅比等;dc为熔炼炉每炉产物高铅渣成份(铅含量)百分比时间序列,整理成数据集d={x,y}={xi,yi}∈rd×m,i∈[1,m],其中m为样本个数,xi=x
i1
,x
i2
,
…
,x
i(n-1)
}∈r1×
(d-1)
为输入特征变量,d-1为特征变量的个数,yi∈r为输出预测目标变量,即高铅渣成份百分比。
[0061]
在步骤(2)中,对数据集d中存在的异常值和缺失值等无效数据进行清洗:对于异常数据,使用箱型图和q-q图统计方法判断出异常离群值后进行剔除;对于缺失数据,采用时间上相邻近的记录进行线性递推填充;预处理后的数据集利用公式
[0062][0063]
进行最大最小值归一化,其中zi是数据中的实际值,z
imax
是对应变量i序列中的最大值,z
imin
对应变量i序列中的最小值,最终数据集d'={x',y'}={x'i,y'i}∈rd×m,i∈[1,m]。
[0064]
在步骤(3)中,设置输入窗口长度t=32,预测窗口长度h=8,即输入历史32炉的生产数据,模型输出未来8炉高铅渣成份百分比的预测值;划分后第k组数据为{dk,yk},即
[0065]dk
={(x'
(k-1)t+1
,y'
(k-1)t+1
),(x'
(k-1)t+2
,y'
(k-1)t+2
),
…
,(x'
kt
,y'
kt
)}∈rd×
t
,
[0066]
模型输出yk={y'
kt+1
,y'
kt+2
,
…
,y'
kt+h
}∈r1×h,k∈n,以此类推,完成整个数据集d'的切分;按采样时间顺序将数据集划分为训练集、验证集和测试集,划分长度比例对应为m
train
:m
valid
:m
test
=6:2:2。
[0067]
在步骤(4)和步骤(5)中,构建预测模型并进行训练;使用mse作为误差评价指标;对线性自回归组件使用预测目标序列y={yi},i=1,
…
,n进行训练,使用bic准则确定模型阶次p=9,并使用最小二乘估计确定模型各阶次参数卷积-自注意力组件
中,选择卷积层数n=3,第一层卷积核长度l1=t-1,后续各层卷积核长度选取为前一层卷积核长度的取整,各层的卷积核个数ki=k=8;自注意力层堆叠层数n=3,融合超参数选取分为为ω={0.2,0.3,0.4,0.5,0.6,0.7,0.8};神经网络部分使用小批量随机梯度下降和adam进行训练,备选批次大小batch_size为{32,64,128};在验证集上使用网格搜索确定上述模型中的超参数,并保存效果最好的模型。
[0068]
在步骤(6)中,读取工业现场的实时生产数据,采用步骤(2)所述的数据预处理算法进行预处理,步骤(3)所述方法进行数据切分,之后将其送入步骤(4)训练得到的融合模型中,对高铅渣成份未来h个时间步长型中,对高铅渣成份未来h个时间步长进行预测。
[0069]
尽管已经示出和描述了本发明的实施例,本领域的技术人员可以理解:在不脱离本发明的原理和宗旨的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由权利要求及其等同物限定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1