一种多老师监督下的多分支学生网络的知识蒸馏方法与流程
1.本发明涉及的是模型压缩技术领域,具体涉及一种多老师监督下的多分支学生网络的知识蒸馏方法。
背景技术:
2.通常我们训练出的神经网络模型都比较大,将大模型直接部署到线上的时候计算时长较长,将这些模型部署到例如手机、机器人等移动设备上时比较困难。模型压缩可以将大模型压缩成小模型,压缩后的小模型也能得到和大模型接近甚至更好的性能。模型压缩主要包括几种模型压缩方法:网络裁剪,知识蒸馏,参数量化和模型结构设计。
3.一般的知识蒸馏方法是先在训练集上从零训练一个大模型作为老师模型,然后使用一个老师模型监督一个学生模型在训练集上进行训练。
4.我们的方法是训练多个不同大小的大模型作为老师模型,多个老师模型在输出层维度上参与监督学生模型训练。使用多个不同大小老师模型的目的有两点,1.减少单个老师模型带偏学生网络的情况,2.多个老师网络的监督提供更加丰富的信息,提高学生网络多个分支结构的准确率,在训练过程中逐步降低大的老师模型监督信息的权重比例,随着训练不断进行,老师模型和学生模型之间存在的能力差距会逐渐影响多分支学生模型的收敛,通过降低参数量较大的老师网络对学生网络监督的损失比例,从而促进多分支学生网络进一步收敛提高多分支模型的准确率,通过小模型替代大模型从而实现降低模型大小实现模型压缩的目的。
技术实现要素:
5.针对现有技术上存在的不足,本发明目的是在于提供一种多老师监督下的多分支学生网络的知识蒸馏方法,充分吸收多个老师网络模型知识,能够实现更高的准确率。
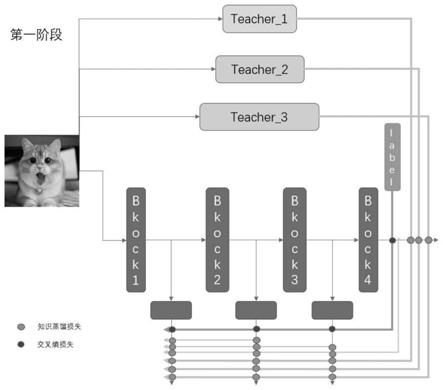
6.为了实现上述目的,本发明是通过如下的技术方案来实现:一种多老师监督下的多分支学生网络的知识蒸馏方法,包括以下步骤:
7.s1,训练多个参数量存在一定差异的老师模型。老师模型在数据集上面进行训练具有良好的泛化能力。但是老师模型参数量较大,推理时间过久,无法线上使用。学生模型线上推理时间短,但是精度较低。所以需要提高学生模型的准确率替代老师模型。
8.s2,第一阶段,多个参数量大小存在明显差异的老师模型加载训练好的权重,冻结权重,假设4个老师模型。
9.s3,假设多分支学生模型有3个分支出口,和一个最终的出口,多分支学生模型随机初始化。
10.s4,针对学生网络不同的分支结构采用不同的监督信息。常用的softmax公式如公式(1),软化概率分布如公式(2)所示。加入温度系数t是为了软化分布,提供更多的监督信息。
[0011][0012][0013]
s5,第一阶段损失函数由三部分组成,标签和分类预测概率之间的交叉熵,多分支结构之间构成的自监督知识蒸馏损失,老师网络与多分支学生网络结构构成的知识蒸馏损失。βi是不同的深层分类器与当前分类器的蒸馏损失权重。qi是不同的老师网络和学生网络某个分支分类器之间的知识蒸馏损失权重。loss
hard
是交叉熵损失,q和β是整体的loss比例,
[0014][0015][0016][0017]
s6,随着训练epoch的迭代,学生网络和老师网络之间的能力差异变得更加显著,按照老师模型参数量大小逐渐降低参数量最多的老师模型对学生网络损失的比例,防止带偏学生模型。
[0018]
s7,第二阶段从知识蒸馏到自蒸馏阶段。随着训练epoch迭代,仅使用学生网络的最深层分类器监督分支分类器的监督。loss
all
如图所示。
[0019][0020][0021]
s8,第三阶段是仅仅使用交叉熵对多分支学生网络进行训练,这是为了促进模型的进一步收敛。
[0022]
本发明具有以下有益效果:
[0023]
本发明的一种多老师监督下的多分支学生网络的知识蒸馏方法在图像分类和文本分类数据集上获得较高的准确率,继而体现出本发明的有效性;在神经网络模型广泛应用的今天,神经网络的推理时间和大小是限制神经网络应用场景的主要因素,基于此,本发明能明显能够有效降低模型大小,扩大神经网络应用领域,使神经网络能够应用到存储资源和计算资源受限的场景中。
附图说明
[0024]
下面结合附图和具体实施方式来详细说明本发明;
[0025]
图1为本发明实施例的第一阶段训练过程示意图;
[0026]
图2为本发明实施例的第二阶段训练过程示意图;
[0027]
图3为本发明实施例的第三阶段训练过程示意图。
具体实施方式
[0028]
为使本发明实现的技术手段、创作特征、达成目的与功效易于明白了解,下面结合具体实施方式,进一步阐述本发明。
[0029]
参照图1-3,本具体实施方式采用以下技术方案:一种多老师监督下的多分支学生网络的知识蒸馏方法,包括以下步骤:
[0030]
步骤1:训练多个参数量存在一定差异的老师模型。
[0031]
步骤2:第一阶段,多个参数量大小存在明显差异的老师模型加载训练好的权重,冻结权重。
[0032]
步骤3:假设多分支学生模型有3个分支出口,和一个最终的出口,多分支学生模型随机初始化。
[0033]
步骤4:针对学生网络不同的分支结构采用不同的监督信息。
[0034]
步骤5:第一阶段损失函数由三部分组成,标签和分类预测概率之间的交叉熵,多分支结构之间构成的自监督知识蒸馏损失,老师网络与多分支学生网络结构构成的知识蒸馏损失。随着训练epoch的迭代,学生网络和老师网络之间的能力差异变得更加显著,按照老师模型参数量大小逐渐降低参数量最多的老师模型对学生网络损失的比例,防止带偏学生模型。
[0035]
步骤6:第二阶段从知识蒸馏到自蒸馏阶段。随着训练epoch迭代,仅使用学生网络的最深层分类器监督分支分类器的监督。
[0036]
步骤7:第三阶段是仅仅使用交叉熵对多分支学生网络进行训练,这是为了促进模型的进一步收敛。
[0037]
一种多老师监督下的多分支学生网络的知识蒸馏系统,主要包括老师模型,学生模型,损失计算模块。
[0038]
所述的老师模型:不同参数量的老师模型在数据集上训练以后得到的模型,之后的模型权重不再更新;
[0039]
所述的学生模型:多分支学生模型,多分支模型一次训练多次部署,适用于不同的精度要求和size大小端侧场景。
[0040]
所述的损失计算模块:第一阶段损失函数由三部分组成,标签和分类预测概率之间的交叉熵,多分支结构之间构成的自监督知识蒸馏损失,老师网络与多分支学生网络结构构成的知识蒸馏损失。第二阶段从知识蒸馏到自蒸馏阶段。随着训练epoch迭代,仅使用学生网络的最深层分类器监督分支分类器的监督。第三阶段是仅仅使用交叉熵对多分支学生网络进行训练,这是为了促进模型的进一步收敛。
[0041]
本具体实施方式通过对多个老师模型中的知识进行充分挖掘,从多个老师模型的输出层挖掘老师模型中的知识。三阶段训练过程是为了使学生模型进一步收敛,从容量大小的角度使老师模型逐步退出对于学生模型的监督训练,减少因为老师模型和学生模型能力之间存在一定的差距导致过度学习的情况。多分支学生模型有效提高模型收敛速度,较少训练次数,实现一次训练多次部署的目的。
[0042]
实施例1:一种多老师监督下的多分支学生网络的知识蒸馏方法,以证件照真伪识别作为业务场景,使用本发明的方法大幅压缩模型大小,降低线上推理时间和难度,提高证件照真伪识别速度,具体的说,如图1,图2和图3所示,是按如下步骤进行:
[0043]
以图像领域中的经典神经网络模型resnet为例。
[0044]
resnet从上到下一共有四个模块,分别是block1,block2,block3,block4不同的模块。假设以resnet34,resnet50和resnet101作为老师模型。多分支resnet18作为学生模型。老师模型具有良好的泛化能力。但是模型较大,深度较深,block中卷积层数较多,线上推理时间比较长。
[0045]
该蒸馏方法将多个老师模型中的知识蒸馏到小模型中,进一步提高小模型的泛化能力。提高小模型的准确率。由于大模型与小模型之间存在能力上的gap,所以该方法将蒸馏过程分为三个阶段,从多个老师模型监督学生模型训练过渡到多分支模型自蒸馏,最后仅使用label监督训练促使小模型进一步收敛。
[0046]
s1.使用resnet34,resnet50和resnet101模型,在训练集上进行训练后保存,
[0047]
s2.训练的第一阶段,将resnet34,resnet50和resnet101模型初始化,并加载各自对应的权重,并冻结不参与权重更新。初始化多分支resnet18模型,
[0048]
s3.第一阶段,resnet34,resnet50和resnet101多个老师模型的输出概率分布监督多分支学生模型。
[0049]
s4.在训练过程中始终多次迭代模型,逐步减少resnet101模型的蒸馏损失比例,再接着逐步减少resnet50模型的蒸馏损失比例,最后逐步减少resnet34模型的蒸馏损失比例。
[0050]
s5.第二阶段,多分支resnet18模型进行自蒸馏使多分支resnet18进一步收敛。
[0051]
s6.第三阶段,仅仅使用交叉熵对多分支resnet18进行训练,这是为了促进模型的进一步收敛。
[0052]
本实施例通过训练过程中的多老师监督多个分支的知识蒸馏方法,从模型的输出层充分吸收多个老师模型中的知识,避免单个老师模型带偏学生模型。
[0053]
三阶段训练过程是为了使多分支学生模型进一步收敛,多老师模型逐步退出对于学生模型的监督训练,过渡到自蒸馏训练,可以有效提高模型的准确率,同时老师模型和学生模型能力之间存在一定的差距,过度学习并不能使模型收敛。
[0054]
本实施例的一种多老师监督下的多分支学生网络的知识蒸馏方法在开源数据集上获得很好的准确率,继而体现出本发明的有效性;基于此,本实施例能明显降低神经网络模型大小,提高模型的推理速度,同时达到一次训练多次部署的目的,从而为提高神经网络在多领域应用做出突出贡献。
[0055]
以上显示和描述了本发明的基本原理和主要特征和本发明的优点。本行业的技术人员应该了解,本发明不受上述实施例的限制,上述实施例和说明书中描述的只是说明本发明的原理,在不脱离本发明精神和范围的前提下,本发明还会有各种变化和改进,这些变化和改进都落入要求保护的本发明范围内。本发明要求保护范围由所附的权利要求书及其等效物界定。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1